

ICLR 2024 スポットライト | 大きな言語モデルの重み、アクティベーション、オールラウンドな低ビット微細化が商用 APP に統合されました

モデル量子化は、モデルの圧縮と高速化における重要なテクノロジーであり、モデルの重みとアクティベーション値を低ビットに量子化し、モデルが占有するメモリ オーバーヘッドを減らし、推論を高速化できるようにします。膨大なパラメータを持つ大規模な言語モデルの場合、モデルの定量化がさらに重要になります。たとえば、GPT-3 モデルの 175B パラメータは、FP16 形式を使用してロードされると 350GB のメモリを消費し、少なくとも 5 つの 80GB A100 GPU が必要になります。
しかし、GPT-3 モデルの重みを 3 ビットに圧縮できる場合は、単一の A100-80GB を使用してすべてのモデルの重みをロードできます。
現時点で、既存の大規模言語モデルのトレーニング後の量子化アルゴリズムには明らかな課題があります。つまり、量子化パラメータの手動設定に依存しており、対応する最適化プロセスが欠如しています。このため、既存の方法では、低ビット量子化を実行するとパフォーマンスが低下することがよくあります。量子化対応トレーニングは最適な量子化構成を決定するのに効果的ですが、追加のトレーニング コストとデータ サポートが必要です。特に大規模な言語モデルでは、計算量自体がすでに膨大であるため、大規模な言語モデルの量子化における量子化を意識したトレーニングの適用はより困難になります。
ここで疑問が生じます:トレーニング後の量子化の時間とデータ効率を維持しながら、量子化を意識したトレーニングのパフォーマンスを達成できるでしょうか?
大規模言語モデルのポストトレーニング中の量子化パラメータの最適化の問題に対処するために、上海人工知能研究所、香港大学、香港中文大学の研究者グループが提案しました。 「OmniQuant: 大規模言語モデル向けの全方向的に調整された量子化」。このアルゴリズムは、大規模な言語モデルでの重みとアクティベーションの量子化をサポートするだけでなく、さまざまな異なる量子化ビット設定にも適応できます。

arXiv 論文アドレス: https://arxiv.org/abs/2308.13137
OpenReview 論文アドレス: https://openreview.net/forum? id=8Wuvhh0LYW
コードアドレス: https://github.com/OpenGVLab/OmniQuant
フレームワークメソッド

ブロック単位の量子化誤差最小化
OmniQuant は、ブロック単位の量子化誤差最小化を使用し、微分可能な方法を使用して追加の量子化パラメーターを最適化する新しい最適化プロセスを提案します。その中で、最適化目標は次のように定式化されます。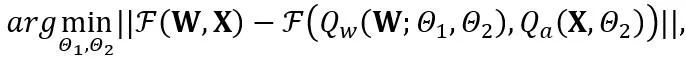
は重みと活性化量子化器を表します。 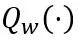 と
と 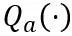 はそれぞれ、学習可能な重みクリッピング (LWC) と学習可能な等価変換 (LET) の量子化パラメーターです。 OmniQuant は、ブロック単位の量子化をインストールし、1 つの Transformer ブロック内のパラメーターを次のブロックに移動する前に順次量子化します。
はそれぞれ、学習可能な重みクリッピング (LWC) と学習可能な等価変換 (LET) の量子化パラメーターです。 OmniQuant は、ブロック単位の量子化をインストールし、1 つの Transformer ブロック内のパラメーターを次のブロックに移動する前に順次量子化します。 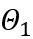
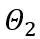
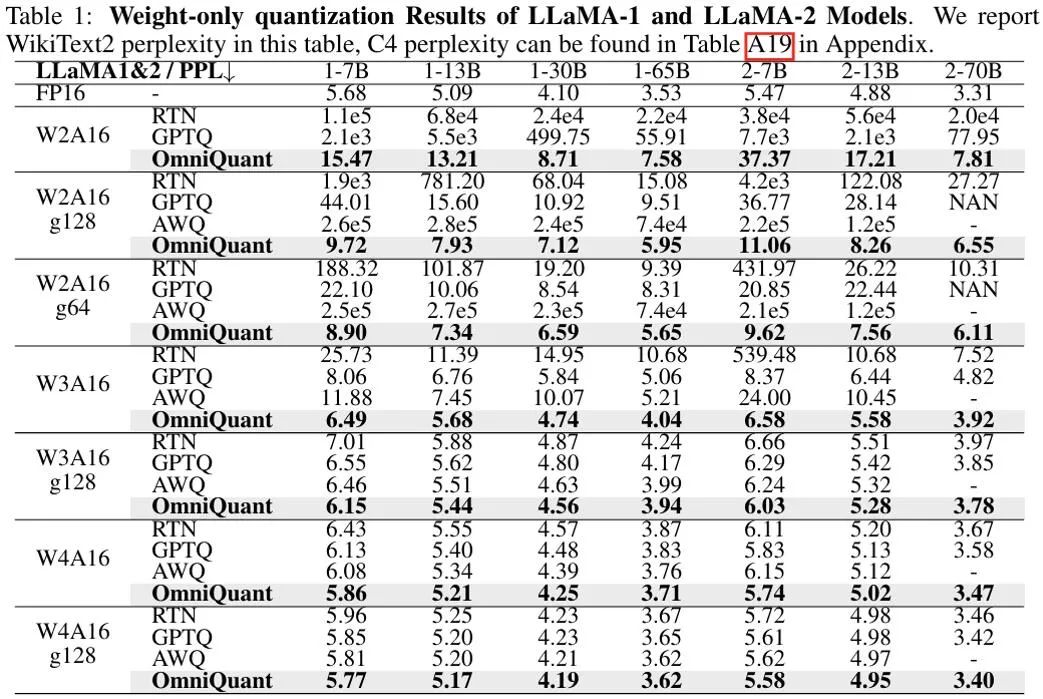
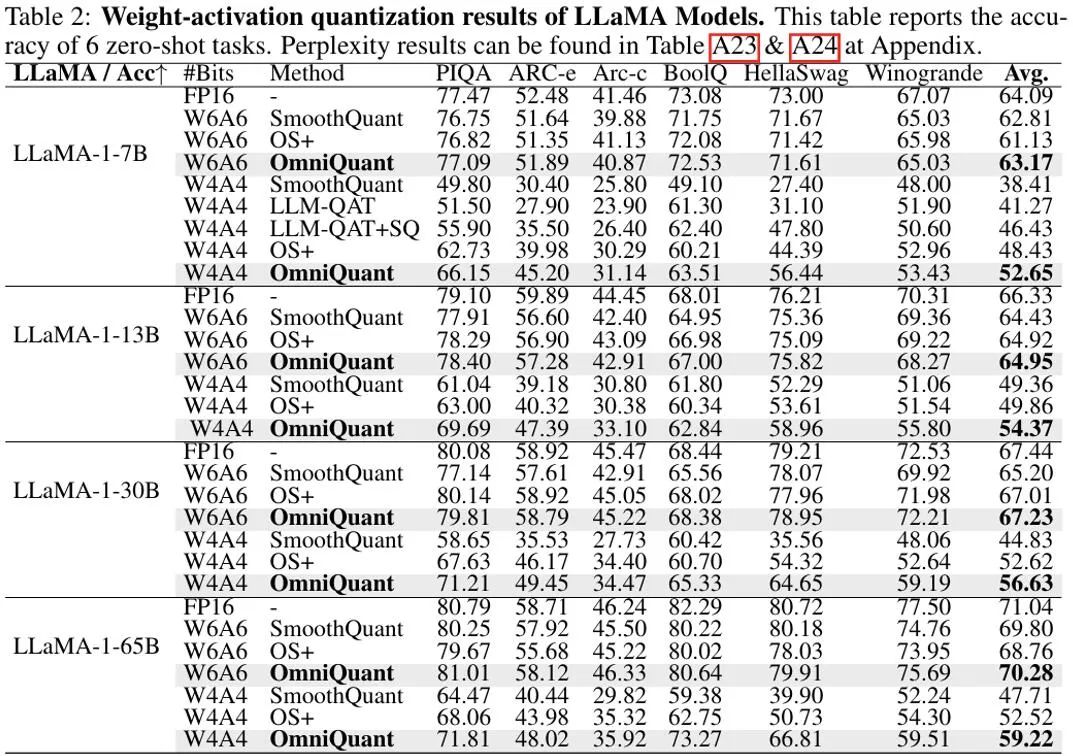
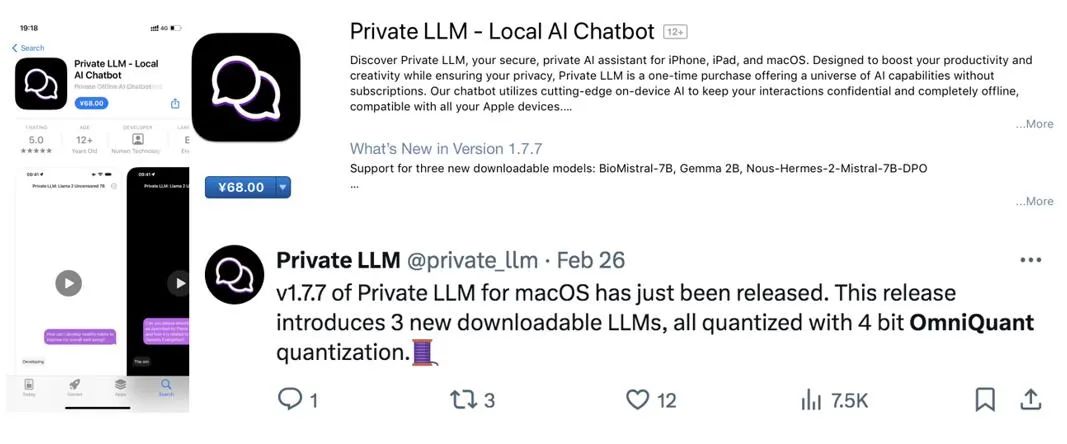
等価変換は、モデルの重みとアクティベーション値の間で大きさの移行を実行します。 OmniQuant が採用する学習可能な等価変換により、パラメーター最適化プロセス中のトレーニングに応じてモデルの重みの分布が継続的に変化します。重みクリッピングしきい値を直接学習する以前の方法 [1、2] は、重み分布が大幅に変化しない場合にのみ適しています。そうでない場合は、収束することが困難になります。この問題に基づいて、重みクリッピングしきい値を直接学習する以前の方法とは異なり、LWC は次の方法でクリッピング強度を最適化します。 ここで、⌊⋅⌉ は丸め演算を表します。 N は目標桁数です。 学習可能な等価変換 (LET) クリッピングしきい値を最適化し、量子化により適した重みで LWC を実現することに加えて、OmniQuant は LET を通じてアクティベーションの難易度をさらに軽減します。価値を数値化すること。 LLM アクティベーション値の外れ値が特定のチャネルに存在することを考慮して、SmoothQuant [3]、Outlier Supression [4] などの以前の方法では、量子化の困難さを数学的に等価な変換を通じてアクティベーション値から重みに移します。 ただし、手動選択または貪欲な検索によって取得された同等の変換パラメーターは、量子化モデルのパフォーマンスを制限します。ブロック単位の量子化誤差最小化の導入により、OmniQuant の LET は微分可能な方法で最適な等価変換パラメータを決定できます。 Outlier Suppression ~\citep {outlier-plus} からインスピレーションを受け、チャネル レベルのスケーリングとチャネル レベルのシフトを使用してアクティベーション分布を操作し、アクティベーション値の外れ値の問題に対する効果的な解決策を提供します。具体的には、OmniQuant は線形レイヤーとアテンション操作における同等の変換を調査します。 線形層での等価変換: 線形層は入力トークン シーケンス Y は出力を表し、 ここで、Q_a は通常の MinMax 量子化器、Q_w は学習可能な重みクリッピングを備えた量子化器 (つまり、提案された LWC の MinMax 量子化器) です。 )。 アテンション演算における等価変換: 線形層に加えて、アテンション演算も LLM の計算の大部分を占めます。さらに、LLM の自己回帰推論モードでは、トークンごとにキー/値 (KV) キャッシュを保存する必要があるため、長いシーケンスでは膨大なメモリが必要になります。したがって、OmniQuant では、自律力計算における Q/K/V 行列を低ビットに量子化することも考慮しています。具体的には、セルフアテンション行列の学習可能な等価変換は次のように記述できます。 ここで、 擬似コード OmniQuant の擬似アルゴリズムを上の図に示します。 LWC と LET によって導入された余分なパラメーターは、モデルが量子化された後に削除できることに注意してください。つまり、OmniQuant は量子化モデルに追加のオーバーヘッドを導入しないため、既存の量子化展開ツールに直接適用できます。 実験パフォーマンス 上の図は、LLaMA モデルでの OmniQuant の実験結果を示しています。重み量子化の結果のみが示されており、さらに OPT が追加されています。モデル 詳細な結果については、原文を参照してください。ご覧のとおり、OmniQuant は、さまざまな LLM モデル (OPT、LLaMA-1、LLaMA-2) および多様な量子化構成 (W2A16、W2A16g128、W2A16g64、W3A16、W3A16g128、W4A16、および W4A16g128 を含む) において、以前のモデルを常に上回っています。LLM は重みの定量化です。メソッドのみ。同時に、これらの実験は、OmniQuant の多用途性と、さまざまな定量化構成に適応する能力を実証しています。たとえば、AWQ [5] はグループ量子化で特に効果的ですが、OmniQuant はチャネルレベルとグループレベルの量子化の両方で優れたパフォーマンスを示します。さらに、量子化ビット数が減少すると、OmniQuant のパフォーマンス上の利点がさらに明らかになります。 重みとアクティベーションの両方が量子化される設定では、実験の主な焦点は W6A6 と W4A4 の量子化です。以前の SmoothQuant は完全精度モデルと比較してほぼロスレスの W8A8 モデル量子化を達成したため、W8A8 量子化は実験設定から除外されました。上図は、LLaMA モデル上で OmniQuant がウェイト アクティベーション値を定量化した実験結果を示しています。特に、OmniQuant は、W4A4 定量化のさまざまなモデルにわたる平均精度を 4.99% から 11.80% まで大幅に向上させます。特に LLaMA-7B モデルでは、OmniQuant は、最近の量子化対応トレーニング手法である LLM-QAT [6] を 6.22% という大幅な差で上回っています。この改善は、量子化を意識したトレーニングで使用されるグローバルな重み調整よりも有益な、追加の学習可能なパラメータを導入することの有効性を示しています。 一方、OmniQuant を使用して定量化されたモデルは、MLC-LLM [7] にシームレスに展開できます。上の図は、NVIDIA A100-80G での LLaMA シリーズ量子化モデルのメモリ要件と推論速度を示しています。 ウェイト メモリ (WM) は量子化されたウェイト ストレージを表し、ランニング メモリ (RM) は推論中のメモリを表します。後者は特定のアクティベーション値が保持されるため、より高くなります。推論速度は、512 個のトークンを生成することで測定されます。量子化モデルでは、16 ビットの全精度モデルと比較してメモリ使用量が大幅に削減されることは明らかです。さらに、W4A16g128 および W2A16g128 の量子化により、推論速度がほぼ 2 倍になります。 MLC-LLM [7] は、Android フォンや IOS フォンなど、他のプラットフォームでの OmniQuant 定量化モデルの展開もサポートしていることは注目に値します。上の図に示すように、最近のアプリケーション Private LLM は OmniQuant アルゴリズムを使用して、iPhone、iPad、macOS などの複数のプラットフォーム上でメモリ効率の高い LLM の展開を完了します。 概要 OmniQuant は、量子化を低ビット形式に進める高度な大規模言語モデルの量子化アルゴリズムです。 OmniQuant の中心原理は、学習可能な量子化パラメータを追加しながら、元の完全精度の重みを保持することです。学習可能な重み接続と等価変換を利用して、重みとアクティベーション値の量子化互換性を最適化します。 OmniQuant は勾配更新を組み込みながら、既存の PTQ 手法と同等のトレーニング時間効率とデータ効率を維持します。さらに、OmniQuant は、追加のトレーニング可能なパラメーターを追加のオーバーヘッドなしで元のモデルに組み込むことができるため、ハードウェアの互換性を保証します。 参考 [1] Pact: 量子化ニューラルネットワークのパラメータ化されたクリッピングアクティベーション。 [2] LSQ: 学習されたステップ サイズの量子化。 [3] Smoothquant: 大規模な言語モデルの正確かつ効率的なトレーニング後の量子化。 [4] 異常値の抑制 : 同等かつ最適なシフトとスケーリングによる大規模な言語モデルの正確な量子化。 [5] Awq: llm 圧縮とアクティベーションを意識した重み量子化 [6] Llm-qat: 大規模言語モデル向けのデータフリーの量子化対応トレーニング。 [7] MLC-LLM :https://github.com/mlc-ai/mlc-llm
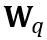 と W は、それぞれ量子化された重みと完全精度の重みを表します。 h は重みの正規化係数、z はゼロ点の値です。クランプ操作は、量子化された値を N ビット整数の範囲、つまり
と W は、それぞれ量子化された重みと完全精度の重みを表します。 h は重みの正規化係数、z はゼロ点の値です。クランプ操作は、量子化された値を N ビット整数の範囲、つまり 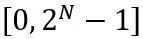 に制限します。上の式で、
に制限します。上の式で、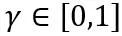 と
と 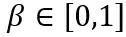 はそれぞれ重みの上限と下限の学習可能なクリッピング強度です。したがって、最適化目的関数では
はそれぞれ重みの上限と下限の学習可能なクリッピング強度です。したがって、最適化目的関数では 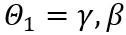 となります。
となります。 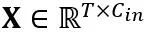 を受け入れます。ここで、T はトークンの長さであり、重み行列
を受け入れます。ここで、T はトークンの長さであり、重み行列 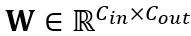 とバイアス ベクトル
とバイアス ベクトル 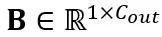 の積です。数学的に等価な線形層式は次のとおりです:
の積です。数学的に等価な線形層式は次のとおりです: 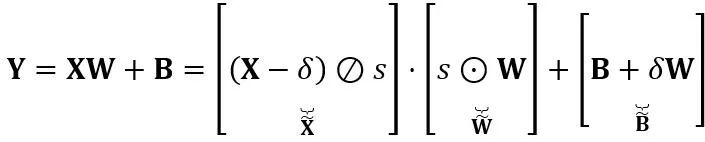
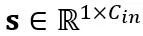 と
と 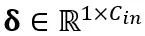 はそれぞれチャネル レベルのスケーリングおよびシフト パラメータです。
はそれぞれチャネル レベルのスケーリングおよびシフト パラメータです。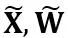 と
と 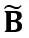 はそれぞれ同等のアクティベーション、重み、バイアスです。⊘ と ⊙ は要素レベルの除算を表しますそして乗算。上式を等価変換することで、重みの数値化が困難になる代わりに、活性化値を数値化しやすい形に変換します。この意味で、LWC は重みの定量化を容易にするため、LET によって達成されるモデルの量子化パフォーマンスを向上させることができます。最後に、OmniQuant は、変換されたアクティベーションと重みを次のように量子化します。
はそれぞれ同等のアクティベーション、重み、バイアスです。⊘ と ⊙ は要素レベルの除算を表しますそして乗算。上式を等価変換することで、重みの数値化が困難になる代わりに、活性化値を数値化しやすい形に変換します。この意味で、LWC は重みの定量化を容易にするため、LET によって達成されるモデルの量子化パフォーマンスを向上させることができます。最後に、OmniQuant は、変換されたアクティベーションと重みを次のように量子化します。

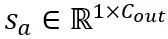 はスケーリング係数です。自己注意計算における定量的な計算は
はスケーリング係数です。自己注意計算における定量的な計算は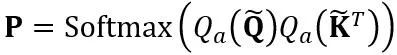 で表されます。ここで、OmniQuant は、
で表されます。ここで、OmniQuant は、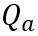 行列を量子化するために、MinMax 量子化スキームを
行列を量子化するために、MinMax 量子化スキームを 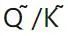 として使用します。したがって、目的関数の
として使用します。したがって、目的関数の 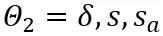 が最終的に最適化されます。
が最終的に最適化されます。 

以上がICLR 2024 スポットライト | 大きな言語モデルの重み、アクティベーション、オールラウンドな低ビット微細化が商用 APP に統合されましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7549
7549
 15
1382
52
83
11
22
90
15
1382
52
83
11
22
90

 新しいカメラ、A18 Pro SoC、大きな画面を備えた iPhone 16 Pro および iPhone 16 Pro Max 公式
Sep 10, 2024 am 06:50 AM
新しいカメラ、A18 Pro SoC、大きな画面を備えた iPhone 16 Pro および iPhone 16 Pro Max 公式
Sep 10, 2024 am 06:50 AM
Apple はついに、新しいハイエンド iPhone モデルのカバーを外しました。 iPhone 16 Pro と iPhone 16 Pro Max には、前世代のものと比較して大きな画面が搭載されています (Pro では 6.3 インチ、Pro Max では 6.9 インチ)。強化された Apple A1 を入手
 iPhone の部品アクティベーション ロックが iOS 18 RC で発見 — ユーザー保護を装って販売された修理権利に対する Apple の最新の打撃となる可能性がある
Sep 14, 2024 am 06:29 AM
iPhone の部品アクティベーション ロックが iOS 18 RC で発見 — ユーザー保護を装って販売された修理権利に対する Apple の最新の打撃となる可能性がある
Sep 14, 2024 am 06:29 AM
今年初め、Apple はアクティベーション ロック機能を iPhone コンポーネントにも拡張すると発表しました。これにより、バッテリー、ディスプレイ、FaceID アセンブリ、カメラ ハードウェアなどの個々の iPhone コンポーネントが iCloud アカウントに効果的にリンクされます。
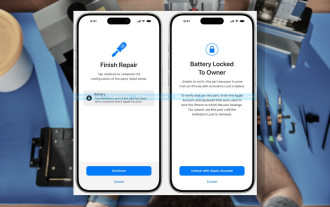 iPhoneの部品アクティベーションロックは、ユーザー保護を装って販売されたAppleの修理権に対する最新の打撃となる可能性がある
Sep 13, 2024 pm 06:17 PM
iPhoneの部品アクティベーションロックは、ユーザー保護を装って販売されたAppleの修理権に対する最新の打撃となる可能性がある
Sep 13, 2024 pm 06:17 PM
今年初め、Apple はアクティベーション ロック機能を iPhone コンポーネントにも拡張すると発表しました。これにより、バッテリー、ディスプレイ、FaceID アセンブリ、カメラ ハードウェアなどの個々の iPhone コンポーネントが iCloud アカウントに効果的にリンクされます。
 gate.ioトレーディングプラットフォーム公式アプリのダウンロードとインストールアドレス
Feb 13, 2025 pm 07:33 PM
gate.ioトレーディングプラットフォーム公式アプリのダウンロードとインストールアドレス
Feb 13, 2025 pm 07:33 PM
この記事では、gate.ioの公式Webサイトに最新のアプリを登録およびダウンロードする手順について詳しく説明しています。まず、登録情報の記入、電子メール/携帯電話番号の確認、登録の完了など、登録プロセスが導入されます。第二に、iOSデバイスとAndroidデバイスでgate.ioアプリをダウンロードする方法について説明します。最後に、公式ウェブサイトの信頼性を検証し、2段階の検証を可能にすること、ユーザーアカウントと資産の安全性を確保するためのリスクのフィッシングに注意を払うなど、セキュリティのヒントが強調されています。
 複数のiPhone 16 Proユーザーがタッチスクリーンのフリーズ問題を報告、おそらくパームリジェクションの感度に関連している
Sep 23, 2024 pm 06:18 PM
複数のiPhone 16 Proユーザーがタッチスクリーンのフリーズ問題を報告、おそらくパームリジェクションの感度に関連している
Sep 23, 2024 pm 06:18 PM
Apple の iPhone 16 ラインナップのデバイス (具体的には 16 Pro/Pro Max) をすでに入手している場合は、最近タッチスクリーンに関する何らかの問題に直面している可能性があります。希望の光は、あなたは一人ではないということです - レポート
 ANBIアプリの公式ダウンロードv2.96.2最新バージョンインストールANBI公式Androidバージョン
Mar 04, 2025 pm 01:06 PM
ANBIアプリの公式ダウンロードv2.96.2最新バージョンインストールANBI公式Androidバージョン
Mar 04, 2025 pm 01:06 PM
Binance Appの公式インストール手順:Androidは、ダウンロードリンクを見つけるために公式Webサイトにアクセスする必要があります。すべては、公式チャネルを通じて契約に注意を払う必要があります。
 PHPを使用してAlipay EasySDKを呼び出すときの「未定義の配列キー」「サイン」「エラー」の問題を解決する方法は?
Mar 31, 2025 pm 11:51 PM
PHPを使用してAlipay EasySDKを呼び出すときの「未定義の配列キー」「サイン」「エラー」の問題を解決する方法は?
Mar 31, 2025 pm 11:51 PM
問題の説明公式コードに従ってパラメーターを記入した後、PHPを使用してAlipay EasySDKを呼び出すとき、操作中にエラーメッセージが報告されました。
 Beats が電話ケースをラインナップに追加:iPhone 16 シリーズ用の MagSafe ケースを発表
Sep 11, 2024 pm 03:33 PM
Beats が電話ケースをラインナップに追加:iPhone 16 シリーズ用の MagSafe ケースを発表
Sep 11, 2024 pm 03:33 PM
Beats は Bluetooth スピーカーやヘッドフォンなどのオーディオ製品を発売することで知られていますが、驚きと形容するのが最も適切なことで、Apple 所有の会社は iPhone 16 シリーズを皮切りに電話ケースの製造に進出しました。ビートiPhone
