

OccFusion: Occ 用のシンプルで効果的なマルチセンサー フュージョン フレームワーク (パフォーマンス SOTA)

自動運転では 3D シーンを包括的に理解することが重要であり、最近の 3D セマンティック占有予測モデルは、さまざまな形状やカテゴリを持つ現実世界のオブジェクトを記述するという課題にうまく対処しています。ただし、既存の 3D 占有予測方法はパノラマ カメラ画像に大きく依存しているため、照明や気象条件の変化の影響を受けやすくなっています。 LIDAR やサラウンドビュー レーダーなどの追加センサーの機能を統合することで、当社のフレームワークは占有予測の精度と堅牢性を向上させ、nuScenes ベンチマークで最高のパフォーマンスを実現します。さらに、困難な夜間や雨のシーンを含む nuScene データセットに関する広範な実験により、さまざまなセンシング範囲にわたるセンサー フュージョン戦略の優れたパフォーマンスが確認されました。
論文リンク: https://arxiv.org/pdf/2403.01644.pdf
論文名: OccFusion: 3D 占有予測のための簡単で効果的なマルチセンサー フュージョン フレームワーク
この論文の主な貢献は次のように要約されます:
- カメラ、ライダー、レーダー情報を統合して 3D セマンティック占有予測タスクを実行するマルチセンサー フュージョン フレームワークが提案されています。
- 3D セマンティック占有予測タスクでは、マルチセンサー フュージョンの利点を実証するために、私たちの方法が他の最先端 (SOTA) アルゴリズムと比較されます。
- 夜間や雨などの厳しい照明条件や気象条件下で、さまざまなセンサーの組み合わせによって達成されるパフォーマンスの向上を評価するために、徹底したアブレーション研究が実施されました。
- さまざまなセンサーの組み合わせと困難なシナリオを考慮して、3D セマンティック占有予測タスクにおけるフレームワークのパフォーマンスに対する知覚距離要因の影響を分析するための包括的な調査が実施されました。
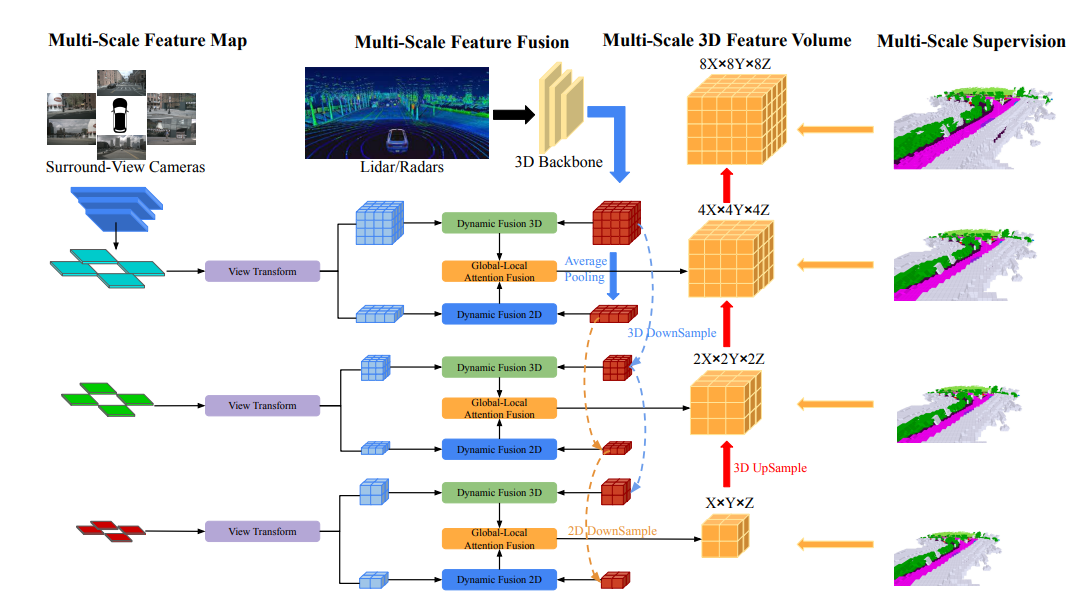
ネットワーク構造の概要
OccFusion の全体的なアーキテクチャは次のとおりです。まず、サラウンド ビュー画像が 2D バックボーンに入力され、マルチスケールの特徴が抽出されます。続いて、各スケールでビュー変換が実行され、各レベルでのグローバル BEV 特徴とローカル 3D 特徴ボリュームが取得されます。 LIDAR とサラウンド レーダーによって生成された 3D 点群も 3D バックボーンに入力され、マルチスケールのローカル 3D 特徴量とグローバル BEV 特徴が生成されます。各レベルのダイナミック フュージョン 3D/2D モジュールは、カメラと LIDAR/レーダーの機能を組み合わせます。この後、マージされたグローバル BEV フィーチャと各レベルのローカル 3D フィーチャ ボリュームがグローバル-ローカル アテンション フュージョンに供給されて、各スケールで最終的な 3D ボリュームが生成されます。最後に、各レベルの 3D ボリュームがアップサンプリングされ、マルチスケール監視メカニズムによってスキップ接続されます。
実験的比較分析
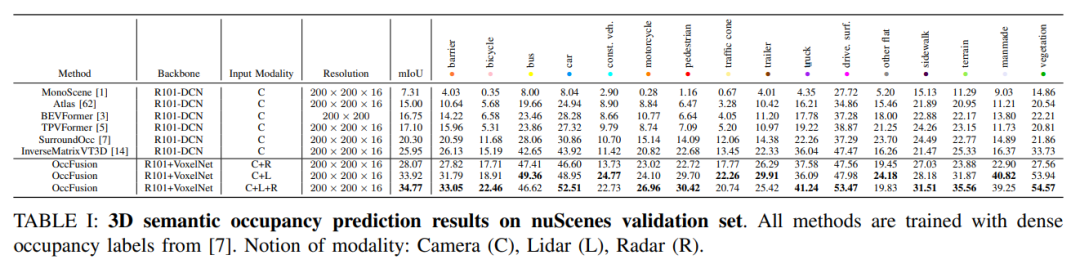
nuScenes 検証セットでは、高密度占有ラベル トレーニングに基づくさまざまな方法が 3D セマンティクスで実証されています。占有率予測で。これらの方法には、カメラ (C)、ライダー (L)、レーダー (R) などのさまざまなモーダル概念が含まれます。
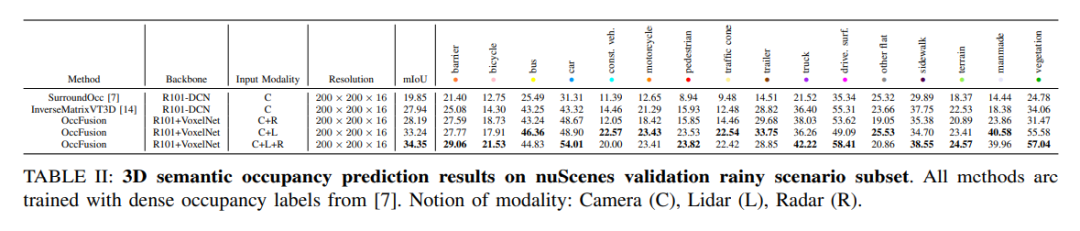
nuScenes データセットの雨のシーンのサブセットで、3D セマンティック占有を予測し、トレーニングに高密度占有ラベルを使用します。この実験では、カメラ (C)、ライダー (L)、レーダー (R) などのさまざまなモダリティからのデータを考慮しました。これらのモードを融合することで、雨のシーンをよりよく理解して予測することができ、自動運転システムの開発に重要な参考資料となります。
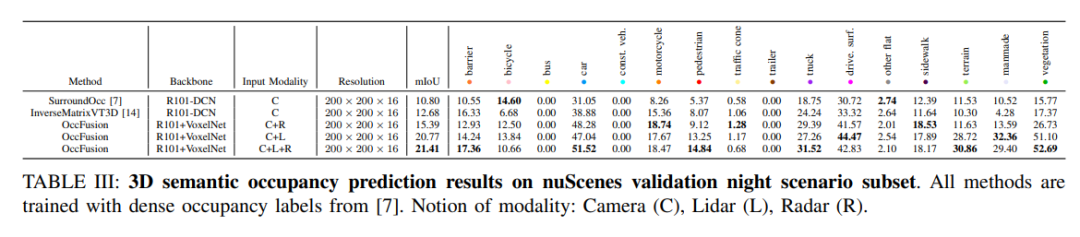
#nuScenes は、夜間シーンのサブセットに対する 3D セマンティック占有予測結果を検証します。すべてのメソッドは、高密度の占有ラベルを使用してトレーニングされます。モーダルコンセプト: カメラ (C)、ライダー (L)、レーダー (R)。
パフォーマンスの変化傾向。 (a) nuScenes 検証セット全体のパフォーマンス変化傾向、(b) nuScenes 検証夜景サブセット、(c) 雨シーン サブセットの nuScenes 検証パフォーマンス変化傾向。
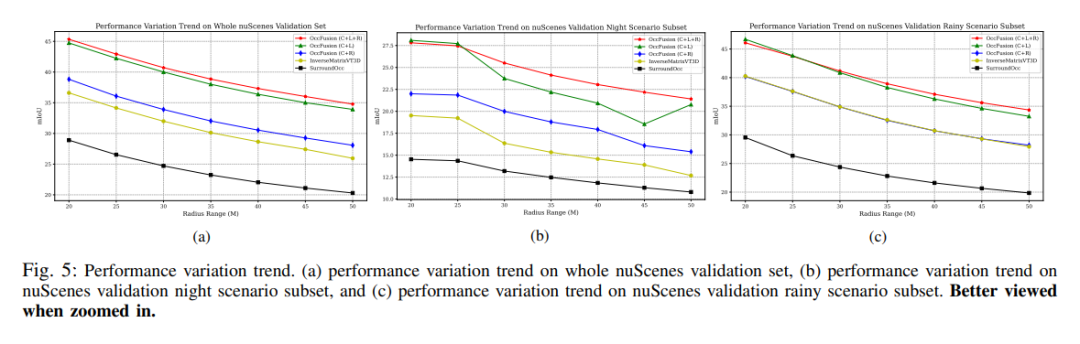
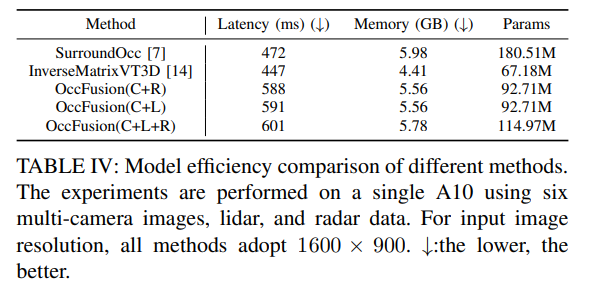
表 4: さまざまな方法のモデル効率の比較。実験は、6 台のマルチカメラ画像、ライダー、レーダー データを使用して A10 で実施されました。入力画像の解像度は、すべての方式で 1600×900 が使用されます。 ↓:低いほど良い。
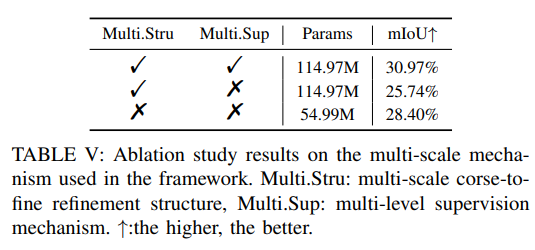
その他のアブレーション実験:


以上がOccFusion: Occ 用のシンプルで効果的なマルチセンサー フュージョン フレームワーク (パフォーマンス SOTA)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7530
7530
 15
1379
52
82
11
21
76
15
1379
52
82
11
21
76

 うわ〜すごい! Samsung Galaxy Ring体験:2999元の本物のスマートリング
Jul 19, 2024 pm 02:31 PM
うわ〜すごい! Samsung Galaxy Ring体験:2999元の本物のスマートリング
Jul 19, 2024 pm 02:31 PM
サムスンは7月17日にSamsung Galaxy Ringの国内版を正式にリリースし、価格は2,999元となった。 Galaxy Ring の実際の電話は、まさに「WowAwesome、これは私だけの特別な瞬間です」の 2024 年バージョンです。 AppleのVision Proを除けば、近年で最も新鮮さを感じさせる(フラグっぽいですが)電子製品です。 (写真では左右のリングがGalaxy Ring↑) Samsung Galaxy Ringの仕様(データは中国銀行公式サイトより):ZephyrRTOSシステム、8MBストレージ、10ATM防水+IP68、バッテリー容量18mAh~23.5 mAh (さまざまなサイズ
 フルスクリーンにアップグレードしてください! iPhone SE4は9月に進みました
Jul 24, 2024 pm 12:56 PM
フルスクリーンにアップグレードしてください! iPhone SE4は9月に進みました
Jul 24, 2024 pm 12:56 PM
最近、iPhone SE4に関する新しいニュースがWeiboで明らかになりました。iPhone SE4の背面カバーのプロセスはiPhone 16の標準バージョンとまったく同じであると言われています。つまり、iPhone SE4はガラスの背面パネルとストレートスクリーン&ストレートエッジデザイン。 iPhone SE4は今年9月に前倒しして発売されると報じられており、iPhone 16と同時に発表される可能性が高い。 1. 公開されたレンダリングによると、iPhone SE4の前面デザインはiPhone 13と似ており、ノッチスクリーンに前面カメラとFaceIDセンサーが搭載されています。背面はiPhoneXrと同様のレイアウトを採用していますが、カメラは1つだけで、全体的なカメラモジュールはありません。
 Xiaomi 15シリーズの完全なコードネームが明らかに:Dada、Haotian、Xuanyuan
Aug 22, 2024 pm 06:47 PM
Xiaomi 15シリーズの完全なコードネームが明らかに:Dada、Haotian、Xuanyuan
Aug 22, 2024 pm 06:47 PM
Xiaomi Mi 15シリーズは10月に正式リリースされる予定で、その全シリーズのコードネームが海外メディアのMiCodeコードベースで公開されている。その中でもフラッグシップモデルであるXiaomi Mi 15 Ultraのコードネームは「Xuanyuan」(「玄源」の意味)です。この名前は中国神話に登場する高貴さを象徴する黄帝に由来しています。 Xiaomi 15のコードネームは「Dada」、Xiaomi 15Proのコード名は「Haotian」(「好天」の意味)です。 Xiaomi Mi 15S Proの内部コード名は「dijun」で、「山と海の古典」の創造神である淳皇帝を暗示しています。 Xiaomi 15Ultra シリーズのカバー
 iPhone 18はサムスンのセンサーを使用していることが明らかに
Jul 25, 2024 pm 10:42 PM
iPhone 18はサムスンのセンサーを使用していることが明らかに
Jul 25, 2024 pm 10:42 PM
Appleの次期iPhone 18シリーズはSamsung製のイメージセンサーを使用する予定であると報じられており、この変更によりAppleのサプライチェーンにおけるソニーの独占が打破されると予想されている。 1. 報道によると、Samsung は Apple の要件を満たすための専門チームを設立しました。サムスンは2026年から48メガピクセル、1/2.6インチの超広角イメージセンサーをアップルに提供する予定で、これはアップルがもはやソニーのセンサー供給に完全に依存していないことを示している。 Apple には約 1,000 のサプライヤーがおり、そのサプライチェーン管理戦略は柔軟で変更可能です。 Apple は通常、サプライヤーの競争を促進し、より良い価格を得るために、コンポーネントごとに少なくとも 2 つのサプライヤーを割り当てます。サムスンをセンサーサプライヤーとして導入することでアップルのコスト構造が最適化され、ソニーの市場での地位に影響を与える可能性がある。サムスンのイメージセンサー技術の能力
 Java フレームワークの商用サポートの費用対効果を評価する方法
Jun 05, 2024 pm 05:25 PM
Java フレームワークの商用サポートの費用対効果を評価する方法
Jun 05, 2024 pm 05:25 PM
Java フレームワークの商用サポートのコスト/パフォーマンスを評価するには、次の手順が必要です。 必要な保証レベルとサービス レベル アグリーメント (SLA) 保証を決定します。研究サポートチームの経験と専門知識。アップグレード、トラブルシューティング、パフォーマンスの最適化などの追加サービスを検討してください。ビジネス サポートのコストと、リスクの軽減と効率の向上を比較検討します。
 OPPO Find X7は傑作です!あらゆる瞬間を画像で捉えましょう
Aug 07, 2024 pm 07:19 PM
OPPO Find X7は傑作です!あらゆる瞬間を画像で捉えましょう
Aug 07, 2024 pm 07:19 PM
このペースの速い時代において、OPPO Find X7 はその画像処理能力を利用して、人生のあらゆる美しい瞬間を味わうことができます。雄大な山、川、湖、海、温かい家族の集まり、街での出会いや驚きなど、あらゆる場面を「比類のない」画質で記録できます。 Find Itのカメラデコデザインは外観から見ても一目瞭然で高級感があります。基本的なハードウェア構成をはじめ、内部もユニークです。 FindX7 は以前の状態を維持します
 Xiaomiの100元携帯電話Redmi 14Cのデザイン仕様が明らかに、8月31日に発売される
Aug 23, 2024 pm 09:31 PM
Xiaomiの100元携帯電話Redmi 14Cのデザイン仕様が明らかに、8月31日に発売される
Aug 23, 2024 pm 09:31 PM
Xiaomi の Redmi ブランドは、ポートフォリオにもう 1 つの低価格携帯電話、Redmi 14C を追加する準備を進めています。このデバイスはベトナムで8月31日に発売されることが確認されています。しかし、発売に先立ち、ベトナムの小売店を通じて携帯電話の仕様が明らかになった。 Redmi14CR Redmiは新しいシリーズに新しいデザインをもたらすことが多く、Redmi14Cも例外ではありません。この携帯電話の背面には大きな円形のカメラモジュールがあり、前世代のデザインとはまったく異なります。ブルーカラーバージョンでは、グラデーションデザインを採用し、より高級感を演出しています。しかし、Redmi14Cは実際には経済的な携帯電話です。カメラ モジュールは 4 つのリングで構成され、1 つはメインの 50 メガピクセル センサーを収容し、もう 1 つは深度情報用のカメラを収容します。
 PHP フレームワークの学習曲線は他の言語フレームワークと比較してどうですか?
Jun 06, 2024 pm 12:41 PM
PHP フレームワークの学習曲線は他の言語フレームワークと比較してどうですか?
Jun 06, 2024 pm 12:41 PM
PHP フレームワークの学習曲線は、言語熟練度、フレームワークの複雑さ、ドキュメントの品質、コミュニティのサポートによって異なります。 PHP フレームワークの学習曲線は、Python フレームワークと比較すると高く、Ruby フレームワークと比較すると低くなります。 Java フレームワークと比較すると、PHP フレームワークの学習曲線は中程度ですが、開始までの時間は短くなります。
