

Tian Yuandong らによる新作: メモリのボトルネックを突破し、4090 で事前トレーニングされた 7B 大型モデルを可能にする

Meta FAIR Tian Yuandong が参加した研究プロジェクトは、先月広く称賛されました。彼らの論文「MobileLLM: Optimizing Subbillion Parameter Language Models for On-Device Use Cases」では、モバイル デバイス上で大規模な言語モデルを実行するという目標を達成することを目的として、10 億未満のパラメータを持つ小規模なモデルを最適化する方法の検討を開始しました。 。
3 月 6 日、Tian Yuandong のチームは最新の研究結果を発表しました。今回は LLM メモリの効率向上に焦点を当てました。研究チームには、Tian Yuandong氏自身に加えて、カリフォルニア工科大学、テキサス大学オースティン校、CMUの研究者も含まれています。この研究は、LLM メモリのパフォーマンスをさらに最適化し、将来の技術開発へのサポートと指針を提供することを目的としています。
彼らは共同で、完全なパラメータ学習を可能にする GaLore (Gradient Low-Rank Projection) と呼ばれるトレーニング戦略を提案しました。LoRA、適応法、GaLore などの一般的な低ランク自動手法と比較メモリ効率が高くなります。
この調査では、モデルの並列処理を使用せずに、NVIDIA RTX 4090 などの 24 GB のメモリを備えたコンシューマ GPU で 7B モデルを正常に事前トレーニングできることが初めて示されました (Checkpoint)またはオフロード戦略。

論文アドレス: https://arxiv.org/abs/2403.03507
論文タイトル: GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
次に、記事の主要な内容を見てみましょう。
現在、大規模言語モデル (LLM) は多くの分野で優れた可能性を示していますが、現実的な問題にも直面する必要があります。それは、LLM の事前トレーニングと微調整だけではありません。大量のコンピューティング リソースが必要です。また、大量のメモリ サポートも必要です。
LLM のメモリ要件には、数十億のパラメータだけでなく、勾配やオプティマイザ状態 (Adam の勾配の勢いや分散など) も含まれており、ストレージ自体よりも大きくなる可能性があります。たとえば、単一のバッチ サイズを使用して最初から事前トレーニングされた LLaMA 7B には、少なくとも 58 GB のメモリが必要です (トレーニング可能なパラメータに 14 GB、Adam Optimizer の状態と重み勾配に 42 GB、アクティベーションに 2 GB)。そのため、24 GB のメモリを搭載した NVIDIA RTX 4090 などのコンシューマー グレードの GPU では、LLM のトレーニングを実行できなくなります。
上記の問題を解決するために、研究者は、事前トレーニングおよび微調整中のメモリ使用量を削減するためのさまざまな最適化手法の開発を続けています。
この方法では、オプティマイザー状態でメモリ使用量を 65.5% 削減しながら、LLaMA 1B および 7B アーキテクチャ上の最大 197 億トークンを使用した C4 データセットでの事前トレーニングの効率とパフォーマンスを維持します。 GLUE タスクでの RoBERTa の効率とパフォーマンスを微調整します。 BF16 ベースラインと比較して、8 ビット GaLore はオプティマイザー メモリを 82.5%、合計トレーニング メモリを 63.3% 削減します。
この調査を見たネチズンは、「クラウドや HPC のことは忘れる時が来ました。GaLore を使えば、すべての AI4Science は 2,000 ドルの消費者向け GPU で完了します。」
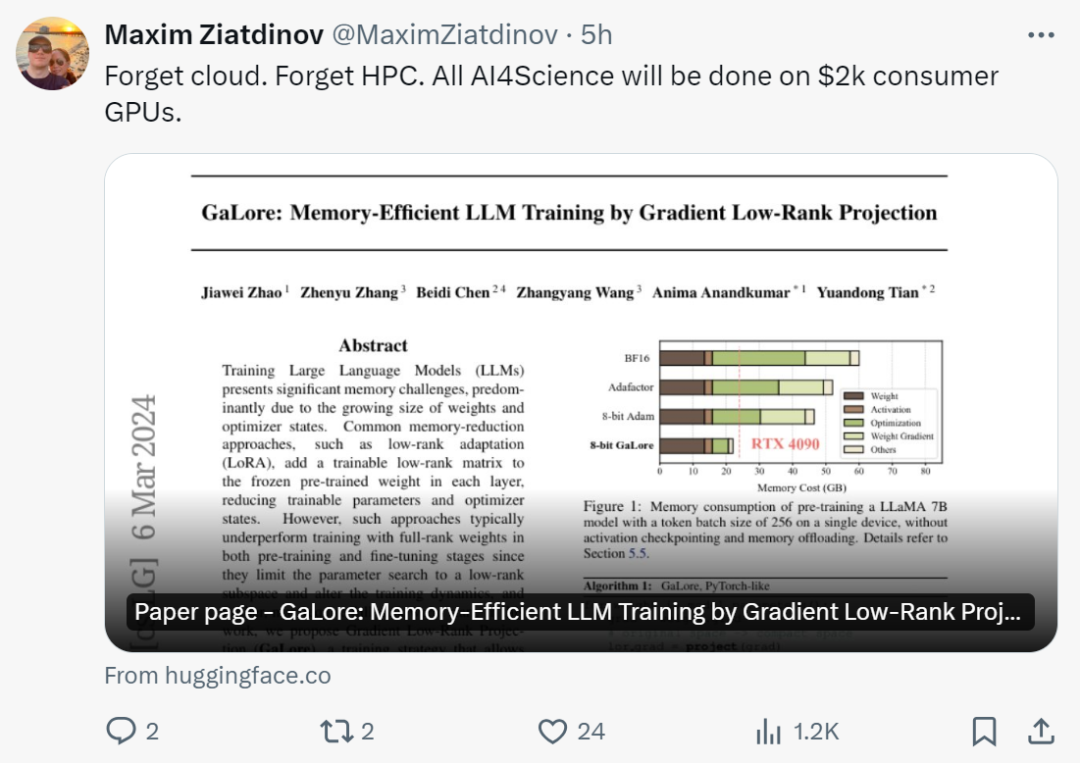
Tian Yuandong 氏は次のように述べています。「GaLore を使用すると、24G メモリを搭載した NVidia RTX 4090 で 7B モデルを事前トレーニングできるようになりました。
LoRA のような低ランクの重み構造を仮定する代わりに、重み勾配が自然に低ランクであるため、(変化する) 低次元空間に投影できることを示します。勾配、アダムの運動量、分散用のメモリを節約します。
したがって、LoRA とは異なり、GaLore はトレーニングのダイナミクスを変更せず、メモリなしで 7B モデルを最初から事前トレーニングするために使用できます。 GaLore は微調整にも使用でき、LoRA に匹敵する結果をもたらします。」
メソッドの紹介
前述したように、GaLore は完全なパラメータ学習戦略を可能にするトレーニングです。ただし、LoRA などの一般的な低ランク適応手法よりもメモリ効率が高くなります。 GaLore の重要なアイデアは、重み行列を直接低ランク形式に近似しようとするのではなく、重み行列 W の勾配 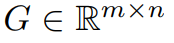 のゆっくりと変化する低ランク構造を利用することです。 。
のゆっくりと変化する低ランク構造を利用することです。 。
この記事では、勾配行列 G がトレーニング プロセス中に低ランクになることを理論的に初めて証明します。理論に基づいて、この記事では GaLore を使用して 2 つの射影行列 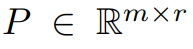 と を計算します。
と を計算します。 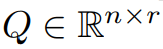 勾配行列 G を低ランク形式 P^⊤GQ に射影します。この場合、コンポーネントの勾配統計に依存するオプティマイザ状態のメモリ コストを大幅に削減できます。表 1 に示すように、GaLore は LoRA よりもメモリ効率が高くなります。実際、これにより、LoRA と比較して、事前トレーニング中のメモリが最大 30% 削減されます。
勾配行列 G を低ランク形式 P^⊤GQ に射影します。この場合、コンポーネントの勾配統計に依存するオプティマイザ状態のメモリ コストを大幅に削減できます。表 1 に示すように、GaLore は LoRA よりもメモリ効率が高くなります。実際、これにより、LoRA と比較して、事前トレーニング中のメモリが最大 30% 削減されます。

この記事は、GaLore が事前トレーニングと微調整で優れたパフォーマンスを発揮することを証明します。 C4 データセットで LLaMA 7B を事前トレーニングする場合、8 ビット GaLore は 8 ビット オプティマイザーとレイヤーごとの重み更新テクノロジーを組み合わせて、オプティマイザー状態のメモリ コストが 10% 未満で、フル ランクに匹敵するパフォーマンスを実現します。
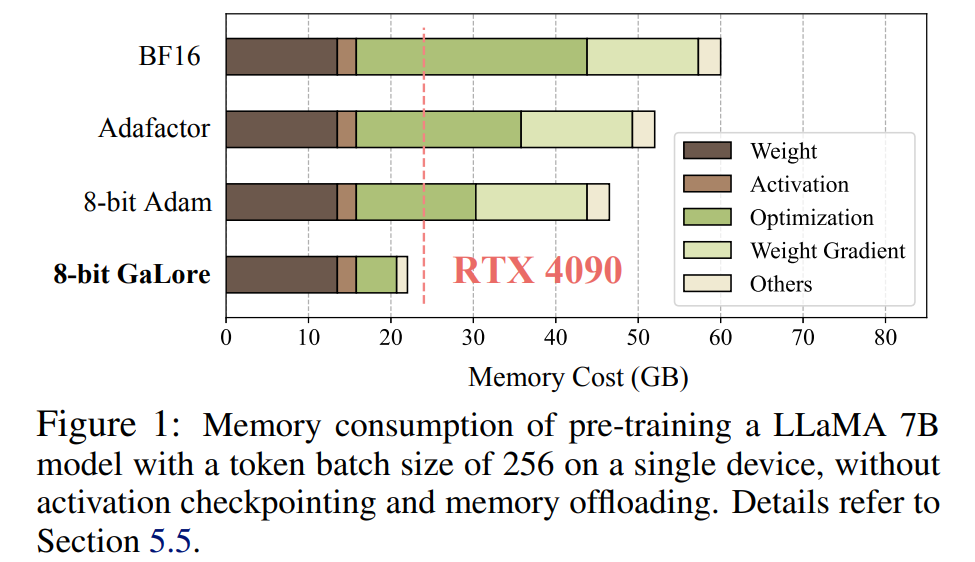
注目に値するのは、事前トレーニングの場合、GaLore は ReLoRA のようなフルランクのトレーニングを必要とせず、トレーニング プロセス全体を通じて低メモリを維持するということです。 GaLore のメモリ効率のおかげで、LLaMA 7B は初めて、高価なメモリ オフロード技術を使用せずに、24 GB のメモリを備えた単一の GPU (NVIDIA RTX 4090 など) で最初からトレーニングできるようになりました (図 1)。
勾配投影法として、GaLore はオプティマイザーの選択に依存せず、わずか 2 行のコードで既存のオプティマイザーに簡単に組み込むことができます。 . アルゴリズム 1 に示すとおり。

次の図は、GaLore を Adam に適用するためのアルゴリズムを示しています。

実験と結果
研究者らは、GaLore の事前トレーニングと LLM の微調整を評価しました。すべての実験は NVIDIA A100 GPU で実行されました。
そのパフォーマンスを評価するために、研究者らは GaLore を適用して、C4 データセット上の LLaMA に基づく大規模な言語モデルをトレーニングしました。 C4 データセットは、Common Crawl Web クローリング コーパスの巨大なサニタイズされたバージョンであり、主に言語モデルと単語表現を事前トレーニングするために使用されます。実際の事前トレーニング シナリオを最適にシミュレートするために、研究者らはデータを複製することなく、モデル サイズが最大 70 億パラメーターに及ぶ十分な量のデータでトレーニングしました。
この論文は、RMSNorm と SwiGLU アクティベーションを備えた LLaMA3 ベースのアーキテクチャを使用した、Lialin らの実験セットアップに従います。学習率を除く各モデル サイズについて、同じハイパーパラメーター セットを使用し、すべての実験を BF16 形式で実行して、同じ計算量で各メソッドの学習率を調整しながらメモリ使用量を削減し、最適なパフォーマンスを報告しました。
さらに、研究者らは、GaLore と LoRA のメモリ効率の高い微調整のベンチマークとして GLUE タスクを使用しました。 GLUE は、感情分析、質問応答、テキストの関連付けなど、さまざまなタスクにおける NLP モデルのパフォーマンスを評価するためのベンチマークです。
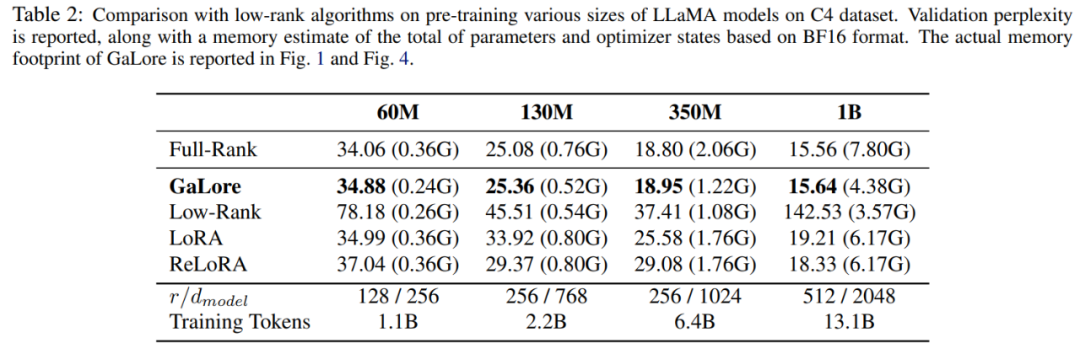
この論文では、まず Adam オプティマイザーを使用して GaLore と既存の低ランク手法を比較します。その結果を表 2 に示します。
研究者らは、GaLore をさまざまな学習アルゴリズム、特にメモリ効率の高いオプティマイザーに適用してメモリ使用量をさらに削減できることを証明しました。研究者らは、GaLore を AdamW、8 ビット Adam、および Adafactor オプティマイザーに適用しました。パフォーマンスの低下を避けるために、一次統計的 Adafactor を採用しています。
実験では、LLaMA 1B アーキテクチャ上で 10,000 のトレーニング ステップを使用して評価し、各設定の学習率を調整し、最高のパフォーマンスを報告しました。図 3 に示すように、以下のグラフは、GaLore が AdamW、8 ビット Adam、Adafactor などの一般的なオプティマイザーで動作することを示しています。さらに、ごく少数のハイパーパラメータを導入しても、GaLore のパフォーマンスには影響しません。
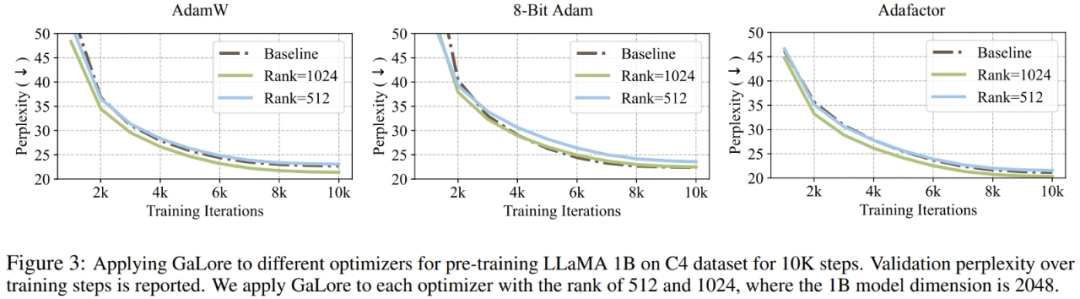
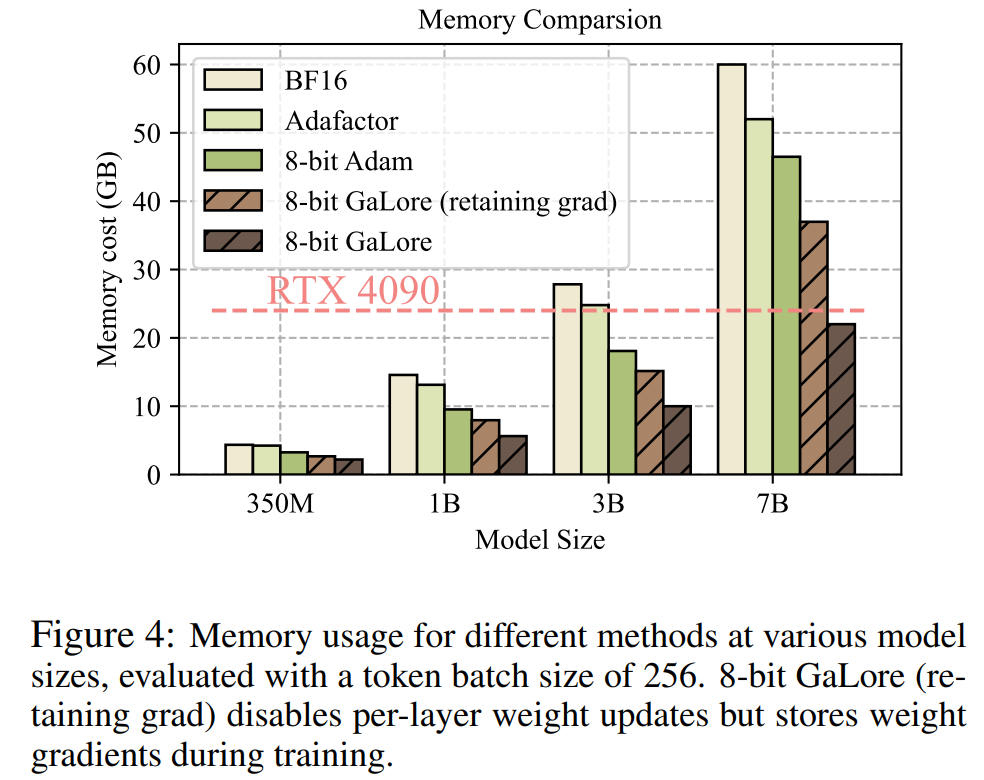
表 4 に示すように、GaLore は、ほとんどのタスクで少ないメモリ使用量で LoRA よりも高いパフォーマンスを達成できます。これは、GaLore が LLM の事前トレーニングと微調整のためのフルスタックのメモリ効率の高いトレーニング戦略として使用できることを示しています。
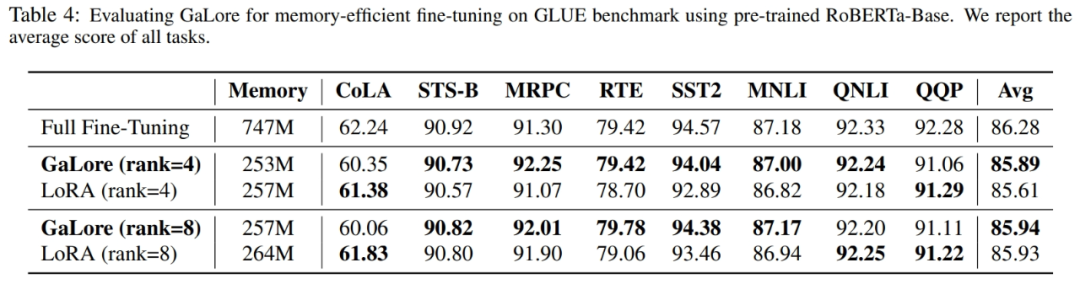
図 4 に示すように、8 ビット GaLore は、BF16 ベンチマークや 8 ビット Adam と比較して、はるかに少ないメモリを必要とします。事前トレーニング LLaMA 7B のみ22.0G のメモリが必要で、GPU あたりのトークン バッチ サイズは小さい (最大 500 トークン)。
技術的な詳細については、元の論文をお読みください。
以上がTian Yuandong らによる新作: メモリのボトルネックを突破し、4090 で事前トレーニングされた 7B 大型モデルを可能にするの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7564
7564
 15
1386
52
87
11
28
101
15
1386
52
87
11
28
101

 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 Deepseekをローカルで微調整する方法
Feb 19, 2025 pm 05:21 PM
Deepseekをローカルで微調整する方法
Feb 19, 2025 pm 05:21 PM
Deepseekクラスモデルのローカル微調整は、コンピューティングリソースと専門知識が不十分であるという課題に直面しています。これらの課題に対処するために、次の戦略を採用できます。モデルの量子化:モデルパラメーターを低精度の整数に変換し、メモリフットプリントを削減します。小さなモデルを使用してください。ローカルの微調整を容易にするために、より小さなパラメーターを備えた前提型モデルを選択します。データの選択と前処理:高品質のデータを選択し、適切な前処理を実行して、モデルの有効性に影響を与えるデータ品質の低下を回避します。バッチトレーニング:大規模なデータセットの場合、メモリオーバーフローを回避するためにトレーニングのためにバッチにデータをロードします。 GPUでの加速:独立したグラフィックカードを使用して、トレーニングプロセスを加速し、トレーニング時間を短縮します。
 Edge ブラウザがメモリを大量に消費する場合の対処方法 Edge ブラウザがメモリを大量に消費する場合の対処方法
May 09, 2024 am 11:10 AM
Edge ブラウザがメモリを大量に消費する場合の対処方法 Edge ブラウザがメモリを大量に消費する場合の対処方法
May 09, 2024 am 11:10 AM
1. まず、Edge ブラウザに入り、右上隅にある 3 つの点をクリックします。 2. 次に、タスクバーの[拡張機能]を選択します。 3. 次に、不要なプラグインを閉じるかアンインストールします。
 総合的にDPOを超える:Chen Danqi氏のチームはシンプルなプリファレンス最適化SimPOを提案し、最強の8Bオープンソースモデルも洗練させた
Jun 01, 2024 pm 04:41 PM
総合的にDPOを超える:Chen Danqi氏のチームはシンプルなプリファレンス最適化SimPOを提案し、最強の8Bオープンソースモデルも洗練させた
Jun 01, 2024 pm 04:41 PM
大規模言語モデル (LLM) を人間の価値観や意図に合わせるには、人間のフィードバックを学習して、それが有用で、正直で、無害であることを確認することが重要です。 LLM を調整するという点では、ヒューマン フィードバックに基づく強化学習 (RLHF) が効果的な方法です。 RLHF 法の結果は優れていますが、最適化にはいくつかの課題があります。これには、報酬モデルをトレーニングし、その報酬を最大化するためにポリシー モデルを最適化することが含まれます。最近、一部の研究者はより単純なオフライン アルゴリズムを研究しており、その 1 つが直接優先最適化 (DPO) です。 DPO は、RLHF の報酬関数をパラメータ化することで、選好データに基づいてポリシー モデルを直接学習するため、明示的な報酬モデルの必要性がなくなります。この方法は簡単で安定しています
 OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
ソフトウェア テクノロジの最前線に立つ UIUC Zhang Lingming のグループは、BigCode 組織の研究者とともに、最近 StarCoder2-15B-Instruct 大規模コード モデルを発表しました。この革新的な成果により、コード生成タスクにおいて大きな進歩が達成され、CodeLlama-70B-Instruct を上回り、コード生成パフォーマンス リストのトップに到達しました。 StarCoder2-15B-Instruct のユニークな特徴は、その純粋な自己調整戦略であり、トレーニング プロセス全体がオープンで透過的で、完全に自律的で制御可能です。このモデルは、高価な手動アノテーションに頼ることなく、StarCoder-15B 基本モデルの微調整に応じて、StarCoder2-15B を介して数千の命令を生成します。
 AI スタートアップ企業は一斉に OpenAI に転職し、イリヤが去った後にセキュリティ チームが再編成されました。
Jun 08, 2024 pm 01:00 PM
AI スタートアップ企業は一斉に OpenAI に転職し、イリヤが去った後にセキュリティ チームが再編成されました。
Jun 08, 2024 pm 01:00 PM
先週、社内の辞任と社外からの批判が相次ぐ中、OpenAIは内外のトラブルに見舞われた。 - 未亡人姉妹への侵害が世界中で白熱した議論を巻き起こした - 「覇権条項」に署名した従業員が次々と暴露 - ネットユーザーがウルトラマンの「」をリストアップ噂の払拭: Vox が入手した漏洩情報と文書によると、アルトマンを含む OpenAI の上級幹部はこれらの株式回収条項をよく認識しており、承認しました。さらに、OpenAI には、AI セキュリティという深刻かつ緊急の課題が直面しています。最近、最も著名な従業員2名を含むセキュリティ関連従業員5名が退職し、「Super Alignment」チームが解散したことで、OpenAIのセキュリティ問題が再び注目を集めている。フォーチュン誌は OpenA を報じた。
 LLMはすべて完了しました! OmniDrive: 3D 認識と推論プランニングの統合 (NVIDIA の最新)
May 09, 2024 pm 04:55 PM
LLMはすべて完了しました! OmniDrive: 3D 認識と推論プランニングの統合 (NVIDIA の最新)
May 09, 2024 pm 04:55 PM
上記と著者の個人的な理解: この論文は、自動運転アプリケーションにおける現在のマルチモーダル大規模言語モデル (MLLM) の主要な課題、つまり MLLM を 2D 理解から 3D 空間に拡張する問題の解決に特化しています。自動運転車 (AV) は 3D 環境について正確な決定を下す必要があるため、この拡張は特に重要です。 3D 空間の理解は、情報に基づいて意思決定を行い、将来の状態を予測し、環境と安全に対話する車両の能力に直接影響を与えるため、AV にとって重要です。現在のマルチモーダル大規模言語モデル (LLaVA-1.5 など) は、ビジュアル エンコーダーの解像度制限や LLM シーケンス長の制限により、低解像度の画像入力しか処理できないことがよくあります。ただし、自動運転アプリケーションには次の要件が必要です。
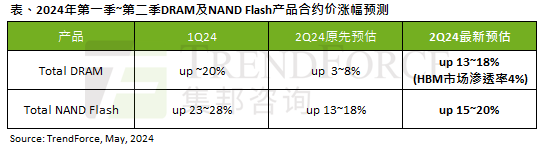 AIの波の影響は明らかで、トレンドフォースは今四半期のDRAMメモリとNANDフラッシュメモリの契約価格の上昇予測を上方修正した。
May 07, 2024 pm 09:58 PM
AIの波の影響は明らかで、トレンドフォースは今四半期のDRAMメモリとNANDフラッシュメモリの契約価格の上昇予測を上方修正した。
May 07, 2024 pm 09:58 PM
TrendForceの調査レポートによると、AIの波はDRAMメモリとNANDフラッシュメモリ市場に大きな影響を与えています。 5 月 7 日のこのサイトのニュースで、TrendForce は本日の最新調査レポートの中で、同庁が今四半期 2 種類のストレージ製品の契約価格の値上げを拡大したと述べました。具体的には、TrendForce は当初、2024 年第 2 四半期の DRAM メモリの契約価格が 3 ~ 8% 上昇すると予測していましたが、現在は NAND フラッシュ メモリに関しては 13 ~ 18% 上昇すると予測しています。 18%、新しい推定値は 15% ~ 20% ですが、eMMC/UFS のみが 10% 増加しています。 ▲画像出典 TrendForce TrendForce は、同庁は当初、今後も継続することを期待していたと述べた。
