

Java での効率的な XML 処理: パフォーマンスを向上させるためのヒント


Java での効率的な XML 処理は常に開発者の焦点であり、この問題に対応して、PHP Editor Banana はパフォーマンスを向上させるためのいくつかのテクニックをまとめました。パーサーの適切な選択、コード ロジックの最適化、大量のデータの適切な処理により、XML 処理の効率が効果的に向上し、開発作業がより効率的かつスムーズになります。次に、開発者が XML 処理の課題にうまく対処できるようにするためのこれらのテクニックについて詳しく説明します。
SAX パーサーを使用する: SAX (Simple api for XML) は、大規模な XML ドキュメントを処理する場合に非常に効率的なイベント駆動型パーサーです。 SAX パーサーは XML 要素を 1 つずつ解析し、解析に必要な最小限の情報のみを保存するため、メモリ消費と処理時間を最小限に抑えます。
リーリーDOM4J パーサーを使用します: DOM4J は、XML ドキュメント全体をメモリにロードするメモリ常駐パーサーです。これは、XML の複雑な処理や頻繁なナビゲーションを必要とするアプリケーションには便利ですが、特に大きな XML ドキュメントを処理する場合には、大量のメモリを消費する可能性があります。
リーリーStAX パーサーの使用: StAX (Streaming API for XML) は、SAX に似たイベントベースのパーサーですが、より高速な処理とより小さいメモリ使用量を提供することに重点を置いています。 StAX パーサーを使用すると、開発者は XML ドキュメントをストリーミングできるため、ドキュメント全体をメモリにロードする必要がなくなります。
リーリーメモリ使用量の最適化: 大規模な XML ドキュメントを操作する場合、メモリの最適化は重要です。 SAX または StAX パーサーを使用すると、ドキュメント全体をメモリにロードしないため、メモリ消費を大幅に削減できます。さらに、メモリ プールを使用してオブジェクトを再利用できるため、メモリ使用量がさらに最適化されます。
同時実行性の活用: マルチコア システムでは、同時実行を利用すると、XML 処理のパフォーマンスを向上させることができます。 Java の同時実行 API (ThreadPoolExecutor など) を使用して スレッド プールを作成し、複数の スレッドを使用して XML ドキュメントのさまざまな部分を並列処理できます。
その他のヒント:
- キャッシュ頻繁にアクセスされる XML フラグメント
- XPath または XQuery を使用して XML ドキュメント内の特定の情報を検索する
- Apache Xerces や oracle XML パーサーなどのサードパーティ XML ライブラリの使用を検討してください。 XML 処理コードのベンチマーク
- テストとパフォーマンス分析 ######結論は:### SAX、DOM4J、または StAX パーサーを使用し、メモリ使用量を最適化し、同時実行性を利用し、その他の技術を採用することにより、Java 開発者は XML 処理のパフォーマンスを大幅に向上させることができます。これらの手法は、大規模または複雑な XML ドキュメントを操作する場合でも、アプリケーションをスムーズで効率的に行うのに役立ちます。
を継続的に監視し、変化するアプリケーションのニーズに合わせて XML 処理フローを調整することが重要です。
以上がJava での効率的な XML 処理: パフォーマンスを向上させるためのヒントの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7486
7486
 15
1377
52
77
11
19
38
15
1377
52
77
11
19
38

 Deepseekをローカルで微調整する方法
Feb 19, 2025 pm 05:21 PM
Deepseekをローカルで微調整する方法
Feb 19, 2025 pm 05:21 PM
Deepseekクラスモデルのローカル微調整は、コンピューティングリソースと専門知識が不十分であるという課題に直面しています。これらの課題に対処するために、次の戦略を採用できます。モデルの量子化:モデルパラメーターを低精度の整数に変換し、メモリフットプリントを削減します。小さなモデルを使用してください。ローカルの微調整を容易にするために、より小さなパラメーターを備えた前提型モデルを選択します。データの選択と前処理:高品質のデータを選択し、適切な前処理を実行して、モデルの有効性に影響を与えるデータ品質の低下を回避します。バッチトレーニング:大規模なデータセットの場合、メモリオーバーフローを回避するためにトレーニングのためにバッチにデータをロードします。 GPUでの加速:独立したグラフィックカードを使用して、トレーニングプロセスを加速し、トレーニング時間を短縮します。
 PHPでHTML/XMLを解析および処理するにはどうすればよいですか?
Feb 07, 2025 am 11:57 AM
PHPでHTML/XMLを解析および処理するにはどうすればよいですか?
Feb 07, 2025 am 11:57 AM
このチュートリアルでは、PHPを使用してXMLドキュメントを効率的に処理する方法を示しています。 XML(拡張可能なマークアップ言語)は、人間の読みやすさとマシン解析の両方に合わせて設計された多用途のテキストベースのマークアップ言語です。一般的にデータストレージに使用されます
 Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8は、Stream APIを導入し、データ収集を処理する強力で表現力のある方法を提供します。ただし、ストリームを使用する際の一般的な質問は次のとおりです。 従来のループにより、早期の中断やリターンが可能になりますが、StreamのForeachメソッドはこの方法を直接サポートしていません。この記事では、理由を説明し、ストリーム処理システムに早期終了を実装するための代替方法を調査します。 さらに読み取り:JavaストリームAPIの改善 ストリームを理解してください Foreachメソッドは、ストリーム内の各要素で1つの操作を実行する端末操作です。その設計意図はです
 カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルは3次元の幾何学的図形で、両端にシリンダーと半球で構成されています。カプセルの体積は、シリンダーの体積と両端に半球の体積を追加することで計算できます。このチュートリアルでは、さまざまな方法を使用して、Javaの特定のカプセルの体積を計算する方法について説明します。 カプセルボリュームフォーミュラ カプセルボリュームの式は次のとおりです。 カプセル体積=円筒形の体積2つの半球体積 で、 R:半球の半径。 H:シリンダーの高さ(半球を除く)。 例1 入力 RADIUS = 5ユニット 高さ= 10単位 出力 ボリューム= 1570.8立方ユニット 説明する 式を使用してボリュームを計算します。 ボリューム=π×R2×H(4
 Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Bootは、Java開発に革命をもたらす堅牢でスケーラブルな、生産対応のJavaアプリケーションの作成を簡素化します。 スプリングエコシステムに固有の「構成に関する慣習」アプローチは、手動のセットアップを最小化します。
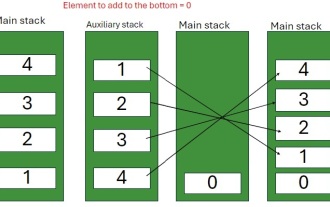 スタックの下部に要素を挿入するJavaプログラム
Feb 07, 2025 am 11:59 AM
スタックの下部に要素を挿入するJavaプログラム
Feb 07, 2025 am 11:59 AM
スタックは、LIFO(最後の、最初のアウト)の原則に従うデータ構造です。言い換えれば、スタックに最後に追加する要素は、削除される最初の要素です。要素をスタックに追加(またはプッシュ)すると、それらは上に配置されます。つまり、とりわけ
 CSウィーク3
Apr 04, 2025 am 06:06 AM
CSウィーク3
Apr 04, 2025 am 06:06 AM
アルゴリズムは、問題を解決するための一連の指示であり、その実行速度とメモリの使用量はさまざまです。プログラミングでは、多くのアルゴリズムがデータ検索とソートに基づいています。この記事では、いくつかのデータ取得およびソートアルゴリズムを紹介します。線形検索では、配列[20,500,10,5,100,1,50]があることを前提としており、数50を見つける必要があります。線形検索アルゴリズムは、ターゲット値が見つかるまで、または完全な配列が見られるまで配列の各要素を1つずつチェックします。アルゴリズムのフローチャートは次のとおりです。線形検索の擬似コードは次のとおりです。各要素を確認します:ターゲット値が見つかった場合:return true return false c言語実装:#include#includeintmain(void){i
 Intellijで最初のスプリングブートアプリケーションを実行する方法は?
Feb 07, 2025 am 11:40 AM
Intellijで最初のスプリングブートアプリケーションを実行する方法は?
Feb 07, 2025 am 11:40 AM
Intellijのアイデアは、Spring Boot開発を簡素化し、Java開発者の間でお気に入りになります。 その慣習と構成アプローチは、ボイラープレートコードを最小限に抑え、開発者がビジネスロジックに集中できるようにします。このチュートリアルでは、2つのメトーを示しています
