


ペーパーアドレス: https://arxiv.org/abs/2307.09283
コードアドレス: https:/ /github.com/THU-MIG/RepViT
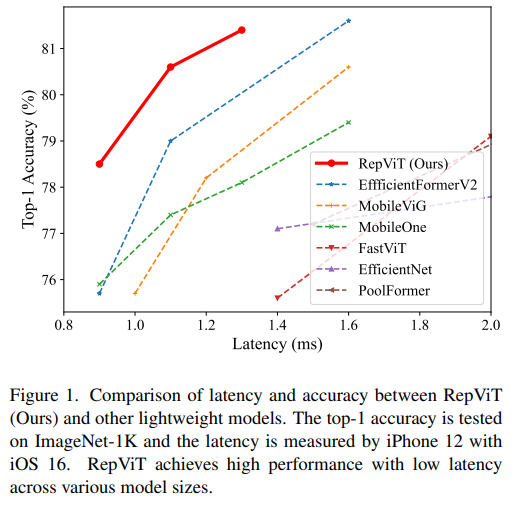
RepViT はモバイル ViT アーキテクチャで優れたパフォーマンスを発揮し、大きな利点を示します。次に、この研究の貢献を検討します。
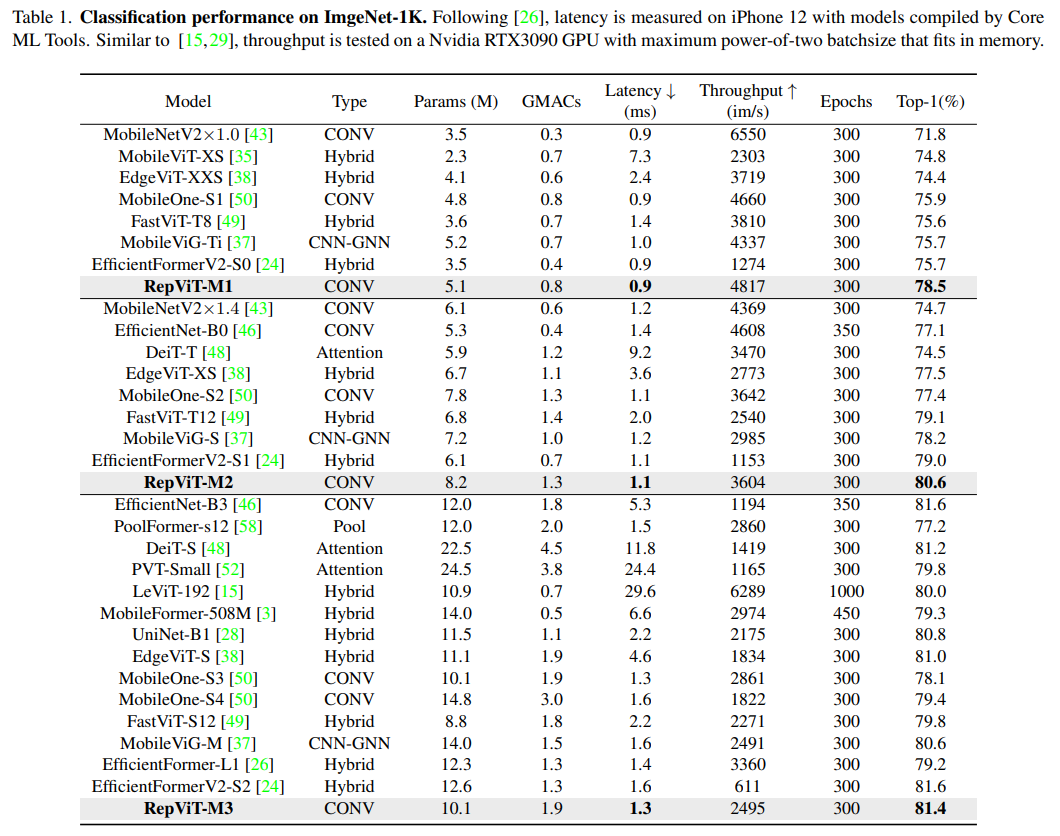
MSHA) により、 グローバル表現を学習するためのモデル。ただし、軽量 ViT と軽量 CNN のアーキテクチャの違いは十分に研究されていません。 MobileNetV3) のモバイル フレンドリー性を徐々に改善しています。 RepViT という軽量 CNN ファミリーです。RepViT は MetaFormer 構造を持っていますが、完全に畳み込みで構成されていることは注目に値します。RepViT## であることが示されています。 # 既存の最先端の軽量 ViT を上回り、ImageNet 分類、COCO-2017 でのオブジェクト検出とインスタンスのセグメンテーション、セマンティックなどのさまざまな視覚タスクにおいて、既存の最先端の軽量 ViT よりも優れたパフォーマンスと効率を示します。 ADE20k でのセグメンテーション。特に ImageNet では、RepViT が iPhone 12 で最高のパフォーマンスを達成し、遅延は 1ms 近く、トップ 1 精度以上を達成しました。 80%、これは軽量モデルにとって最初のブレークスルーです。
どのようにモデル をこのような低レイテンシで設計できるのか、しかし、高い精度が出るのでしょうか?
メソッド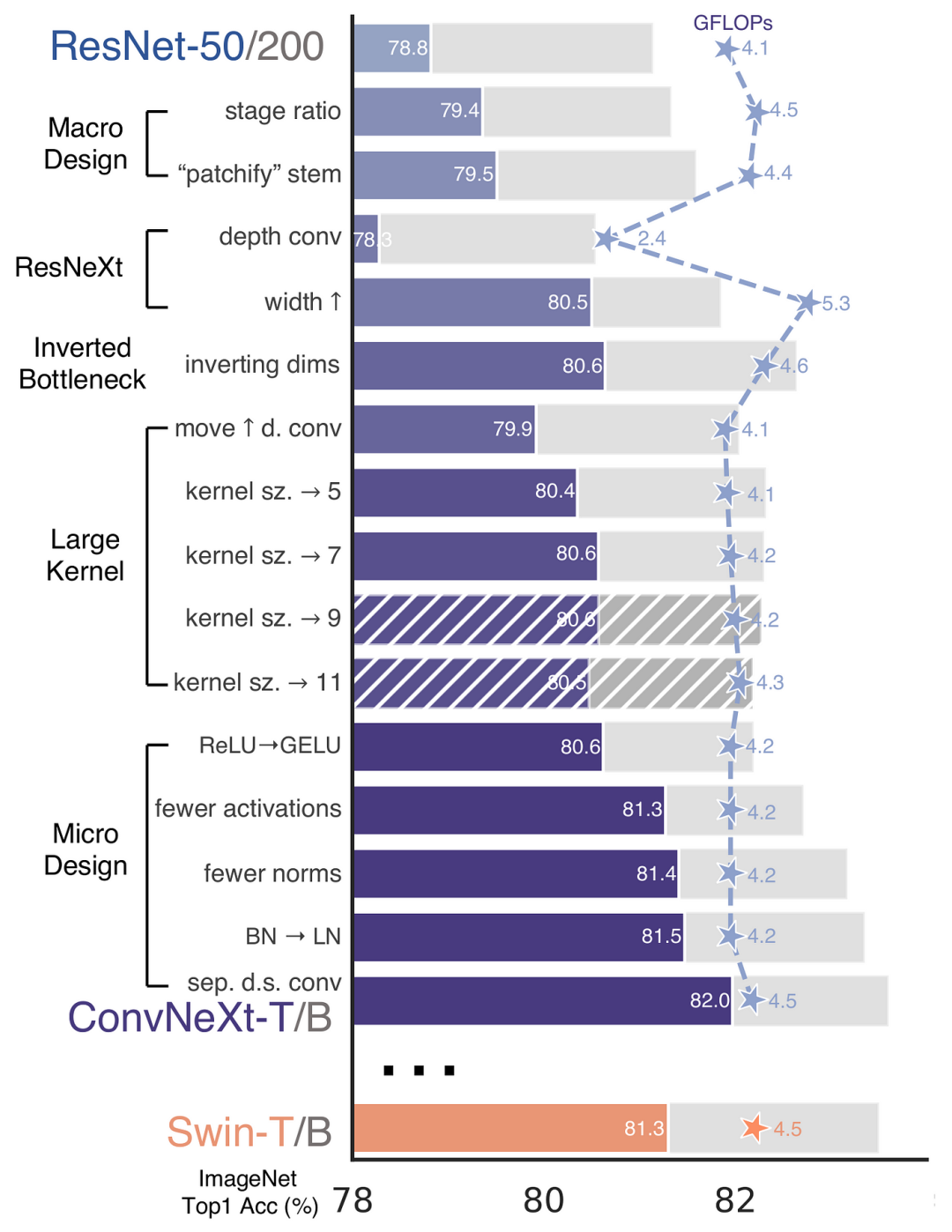
、作者は厳密な ResNet50 アーキテクチャに基づいています。理論的および実験的な分析を経て、最終的に Swin-Transformer に匹敵する非常に優れた純粋な畳み込みニューラル ネットワーク アーキテクチャを設計しました。同様に、RepViT も、軽量 ViT のアーキテクチャ設計を段階的に統合することにより、主にターゲットを絞った変換を実行します。標準軽量 CNN、すなわち MobileNetV3-L (マジック修正) このプロセスでは、作成者はさまざまな粒度レベルで設計要素を検討し、一連のステップを通じて最適化目標を達成しました。
この論文では、モバイル デバイスのレイテンシーを測定するための新しい指標が導入されており、トレーニング戦略が現在一般的な軽量のトレーニング戦略と一致していることを確認します。レベル ViT は一貫したままです。この取り組みの目的は、モデル トレーニングの一貫性を確保することであり、これには遅延測定とトレーニング戦略の調整という 2 つの重要な概念が含まれます。
遅延測定インデックス
実際のモバイル デバイスでのモデルのパフォーマンスをより正確に測定するために、著者は、実際のモバイル デバイスでのモデルの実際の遅延を直接測定することを選択しました。デバイスのベースライン測定として。このメトリクスは、主に FLOPs やモデル サイズなどのメトリクスを通じてモデルの推論速度を最適化する以前の研究とは異なります。これらのメトリクスは、モバイル アプリケーションの実際のレイテンシを必ずしも適切に反映するとは限りません。
トレーニング戦略の調整
ここでは、MobileNetV3-L のトレーニング戦略が、他の軽量 ViTs モデルと調整されるように調整されています。これには、AdamW オプティマイザー [ViTs モデルに必須のオプティマイザー] の使用、5 エポックのウォームアップ トレーニング、およびコサイン アニーリング学習率スケジューリングを使用した 300 エポックのトレーニングが含まれます。この調整によりモデルの精度は若干低下しますが、公平性は保証されます。
次に、著者らは一貫したトレーニング設定に基づいて最適なブロック設計を検討しました。ブロック設計は CNN アーキテクチャの重要なコンポーネントであり、ブロック設計の最適化はネットワークのパフォーマンスの向上に役立ちます。
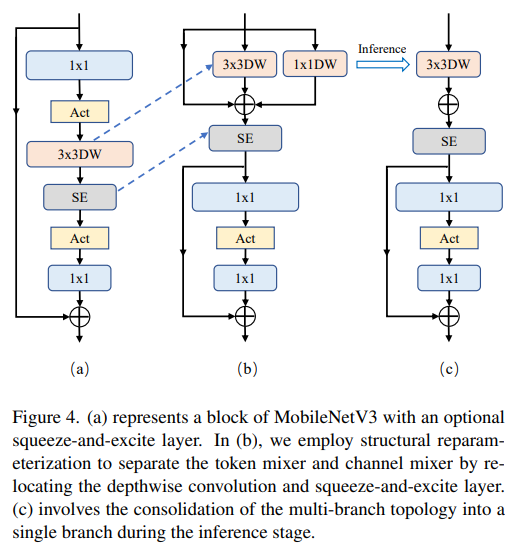
トークン ミキサーとチャネル ミキサーを分離
これは主に MobileNetV3-L 用です。ブロック構造は次のとおりです。トークンミキサーとチャネルミキサーを分離するように改良されました。元の MobileNetV3 ブロック構造は、1x1 拡張畳み込み、その後に深さ方向の畳み込みと 1x1 投影層で構成され、残差接続を介して入力と出力を接続します。これに基づいて、RepViT は深さの畳み込みを進めて、チャネル ミキサーとトークン ミキサーを分離できるようにします。パフォーマンスを向上させるために、トレーニング中にディープ フィルターにマルチブランチ トポロジを導入する 構造再パラメータ化 も導入されています。最後に、著者らは MobileNetV3 ブロック内のトークン ミキサーとチャネル ミキサーを分離することに成功し、そのようなブロックを RepViT ブロックと名付けました。
拡張率を下げて幅を増やす
チャネル ミキサーでは、元の拡張率は 4 です。これは、MLP ブロックの隠れ次元が 4 であることを意味します。これは、大量のコンピューティング リソースを消費し、推論時間に大きな影響を与えます。この問題を軽減するには、拡張率を 2 に減らすことでパラメータの冗長性と遅延を削減し、MobileNetV3-L の遅延を 0.65 ミリ秒まで下げることができます。その後、ネットワークの幅を増やす、つまり各ステージのチャネル数を増やすことによって、Top-1 の精度は 73.5% に増加しましたが、遅延は 0.89 ミリ秒に増加しただけでした。
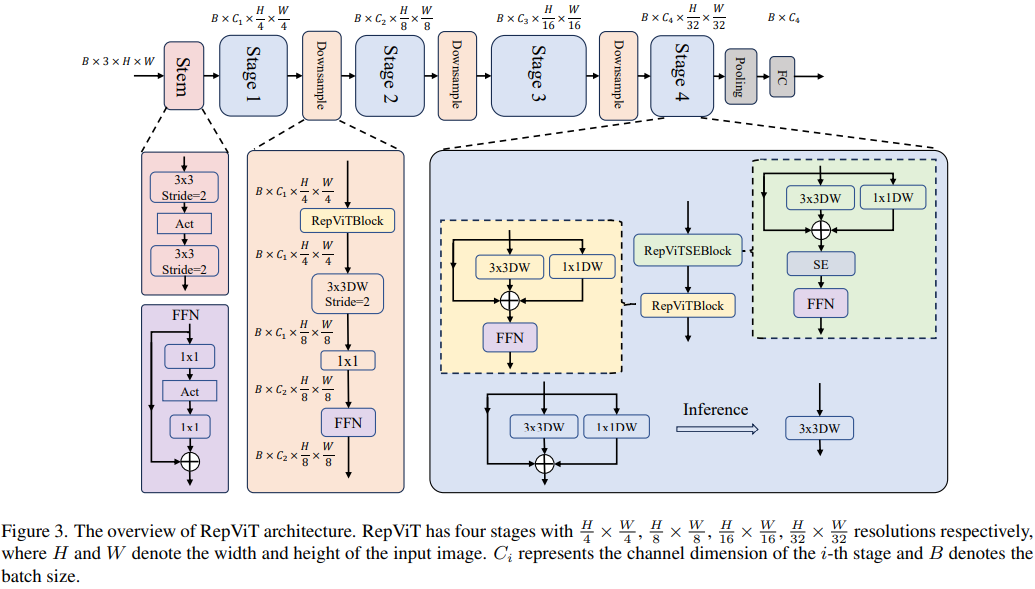
このステップでは、この記事では、主にステム、ダウンサンプリング レイヤーなどのマクロ アーキテクチャ要素から始めて、モバイル デバイス上の MobileNetV3-L のパフォーマンスをさらに最適化します。 、分類子およびステージ全体の比率。これらのマクロアーキテクチャ要素を最適化することで、モデルのパフォーマンスを大幅に向上させることができます。
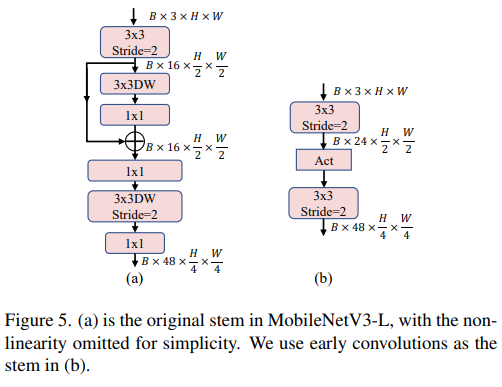
畳み込み抽出器を使用した浅いネットワーク
 写真
写真
ViT は通常、入力イメージをステムとして重複しないパッチに分割する「パッチ化」操作を使用します。ただし、このアプローチにはトレーニングの最適化とトレーニング レシピに対する感度に問題があります。したがって、著者らは代わりに、多くの軽量 ViT で採用されているアプローチである早期畳み込みを採用しました。対照的に、MobileNetV3-L は 4 倍のダウンサンプリングにさらに複雑なステムを使用します。このようにして、フィルターの初期数は 24 に増加しますが、総遅延は 0.86 ミリ秒に減少し、トップ 1 の精度は 73.9% に増加します。
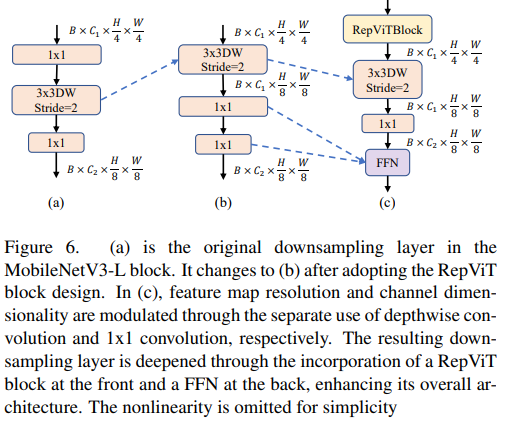
ViT では、通常、空間ダウンサンプリングは別のパッチ マージ レイヤーを通じて実装されます。したがって、ここでは、個別のより深いダウンサンプリング層を採用して、ネットワークの深さを増やし、解像度の低下による情報損失を減らすことができます。具体的には、著者らはまず 1x1 畳み込みを使用してチャネル次元を調整し、次に残差を介して 2 つの 1x1 畳み込みの入力と出力を接続してフィードフォワード ネットワークを形成しました。さらに、ダウンサンプリング層をさらに深くするために、前面に RepViT ブロックを追加しました。これにより、トップ 1 の精度が 0.96 ミリ秒のレイテンシで 75.4% に向上しました。
より単純な分類子
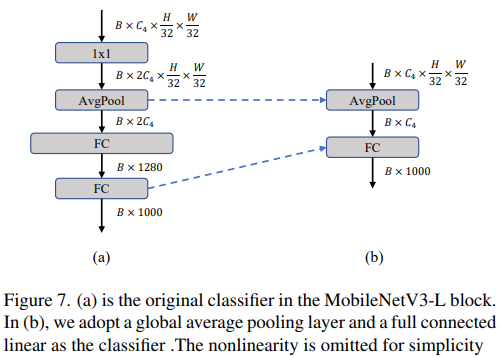
軽量 ViT では、通常、分類子の後に線形層で構成されるグローバル平均プーリング層が続きます。対照的に、MobileNetV3-L はより複雑な分類子を使用します。最終ステージにはさらに多くのチャネルがあるため、著者らはそれを単純な分類子、グローバル平均プーリング層、および線形層に置き換えました。このステップにより、トップ 1 の精度を保ちながらレイテンシーが 0.77 ミリ秒に減少しました。その率は 74.8% です。
全体的なステージの割合
ステージの割合は、さまざまなステージのブロック数の割合を表し、各ステージでの計算の分布を示します。この論文では、より最適なステージ比 1:1:7:1 を選択し、ネットワークの深さを 2:2:14:2 に増やすことで、より深いレイアウトを実現しています。このステップにより、トップ 1 の精度が 1.02 ミリ秒のレイテンシで 76.9% に向上します。
次に、RepViT は層ごとのマイクロ設計を通じて軽量 CNN を調整します。これには、適切なコンボリューション カーネル サイズの選択やスクイーズ励起 (スクイーズと-励起、SEと呼ばれる)層の位置。どちらの方法でもモデルのパフォーマンスが大幅に向上します。
コンボリューション カーネル サイズの選択
CNN のパフォーマンスとレイテンシは通常、コンボリューション カーネルのサイズに影響されることはよく知られています。たとえば、MHSA のような長距離のコンテキスト依存関係をモデル化するために、ConvNeXt は大規模な畳み込みカーネルを使用し、その結果、パフォーマンスが大幅に向上します。ただし、大規模なコンボリューション カーネルは、計算の複雑さとメモリ アクセス コストのため、モバイルに適していません。 MobileNetV3-L は主に 3x3 畳み込みを使用し、一部のブロックでは 5x5 畳み込みが使用されます。著者らはこれらを 3x3 畳み込みに置き換えた結果、76.9% のトップ 1 の精度を維持しながらレイテンシが 1.00 ミリ秒に短縮されました。
SE 層の位置
畳み込みに対するセルフアテンション モジュールの利点の 1 つは、データ駆動型プロパティと呼ばれる、入力に基づいて重みを調整できることです。 。チャネル アテンション モジュールとして、SE レイヤーはデータ駆動型プロパティの欠如における畳み込みの制限を補うことができるため、パフォーマンスの向上につながります。 MobileNetV3-L は、主に最後の 2 つのステージに焦点を当てて、いくつかのブロックに SE レイヤーを追加します。ただし、低解像度ステージでは、高解像度ステージよりも SE によって提供されるグローバル平均プーリング操作から得られる精度の向上が小さくなります。著者らは、最小限の遅延増分で精度向上を最大化するために、すべての段階でブロック間で SE 層を使用する戦略を設計しました。このステップにより、トップ 1 精度が 77.4% に向上し、遅延が 0.87 ミリ秒に減少しました。 [実際、Baidu はこの点についてすでに実験と比較を行っており、かなり前にこの結論に達しました。SE 層は深層の近くに配置するとより効果的です]
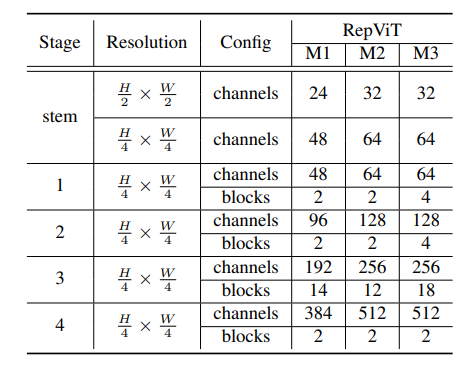
最後に、上記の改善戦略を統合することにより、RepViT-M1/ などの複数のバリアントを持つモデル RepViT の全体的なアーキテクチャが得られました。 M2/M3。同様に、さまざまなバリエーションは主にステージごとのチャネル数とブロック数によって区別されます。
 ##検出とセグメンテーション
##検出とセグメンテーション
#概要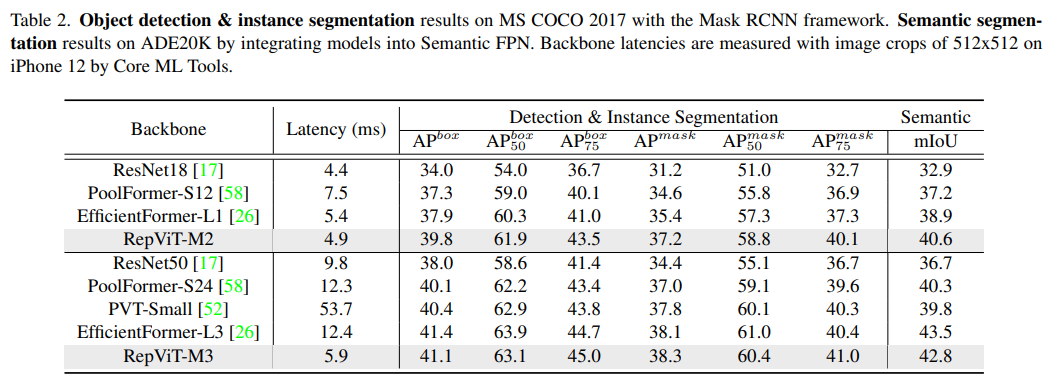
以上が1.3ミリ秒には1.3ミリ秒かかります。清華社の最新オープンソース モバイル ニューラル ネットワーク アーキテクチャ RepViTの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



