

普及モデルはどのようにして新世代の意思決定主体を構築するのでしょうか?自己回帰を超えて、長いシーケンス計画軌道を同時に生成

あなたが部屋に立ってドアに向かって歩く準備をしているときに、自己回帰による経路を徐々に計画していると想像してみてください。実際には、パス全体が一度に生成されます。
最新の研究では、拡散モデルを使用した計画モジュールは、人間の意思決定方法により沿った長いシーケンス軌道計画を同時に生成できることが指摘されています。さらに、拡散モデルは、ポリシー表現とデータ合成の観点から、既存の意思決定インテリジェンス アルゴリズムに対して、より最適化されたソリューションを提供することもできます。
上海交通大学のチームによって書かれた総説論文「強化学習のための拡散モデル: 調査」は、関連分野における拡散モデルの応用を組み合わせたものです。強化学習。このレビューでは、既存の強化学習アルゴリズムが長期シーケンス計画におけるエラーの蓄積、制限されたポリシー表現機能、不十分なインタラクティブデータなどの課題に直面している一方、拡散モデルは強化学習の問題を解決し、長期的な計画に対処するための新しいアイデアをもたらす利点を実証していると指摘しています。 - 前述の立ち向かう課題。 論文リンク: https://arxiv.org/abs/2311.01223

このレビューでは、強化学習における拡散モデルの役割を分類し、さまざまな強化学習シナリオにおける拡散モデルの成功事例を要約します。最後に、このレビューでは、拡散モデルを使用して強化学習の問題を解決するという将来の開発の方向性を展望しています。
図は、従来のエージェント、環境、エクスペリエンスの再生プール サイクルにおける拡散モデルの役割を示しています。従来のソリューションと比較して、普及モデルはシステムに新しい要素を導入し、より包括的な情報のやり取りと学習の機会を提供します。このようにして、エージェントは環境の変化によりよく適応し、意思決定を最適化できます
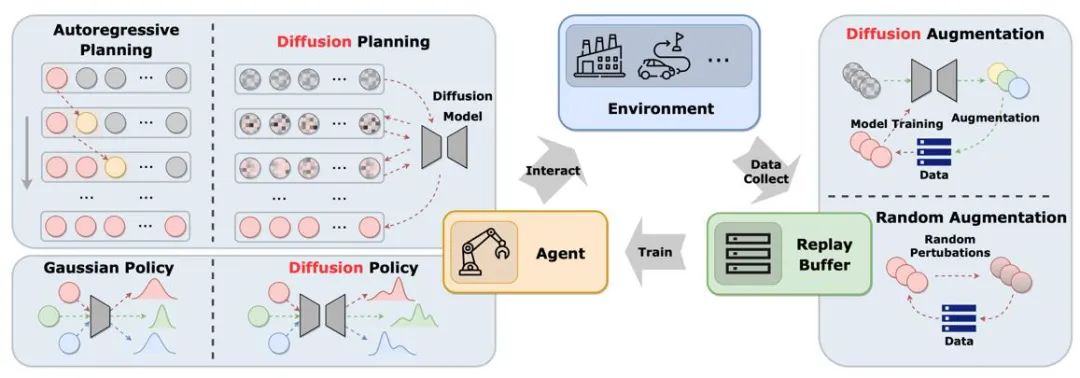 ##強化学習における拡散モデルの役割
##強化学習における拡散モデルの役割
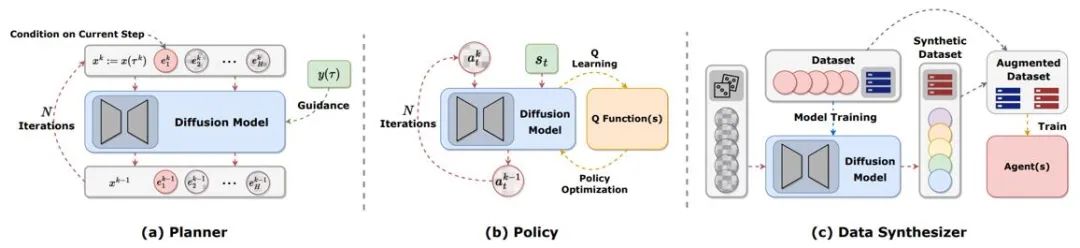
この記事では、強化学習において拡散モデルが果たすさまざまな役割に基づいて、拡散モデルの適用方法と特性を分類および比較します。
図 2: 強化学習において拡散モデルが果たすさまざまな役割。
 軌道計画
軌道計画
強化学習における計画とは、動的モデルを使用して想像力で意思決定を行い、選択することを指します。累積報酬を最大化するための適切なアクション。計画のプロセスでは、意思決定の長期的な有効性を向上させるために、一連のアクションと状態を検討することがよくあります。モデルベースの強化学習 (MBRL) フレームワークでは、計画シーケンスが自己回帰的な方法でシミュレートされることが多く、その結果、エラーが蓄積されます。拡散モデルは、複数ステップの計画シーケンスを同時に生成できます。既存の記事が拡散モデルを使って生成するターゲットは、(s,a,r)、(s,a)、sのみ、aのみなど非常に多様です。オンライン評価中に高い報酬の軌跡を生成するために、多くの作品では、分類子の有無にかかわらず、ガイド付きサンプリング手法が使用されています。
#ポリシー表現
#拡散プランナーは、従来の強化学習における MBRL によく似ています。普及計画者は、ポリシーとしてのモデルはモデルフリーの強化学習に似ています。 Diffusion-QL は、まず、普及戦略と Q ラーニング フレームワークを組み合わせます。拡散モデルは従来のモデルよりもはるかに多峰性分布に適合する能力が高いため、拡散戦略は複数の行動戦略によってサンプリングされた多峰性データセットで良好に機能します。拡散戦略は通常の戦略と同じであり、通常は状態を条件として使用し、Q (s,a) 関数の最大化を考慮しながらアクションを生成します。 Diffusion-QL などの手法では、拡散モデルのトレーニング時に重み付けされた値関数項が追加されますが、CEP ではエネルギーの観点から重み付けされた回帰ターゲットが構築され、その値関数が拡散モデルによって学習されたアクション分布を調整する係数として使用されます。
データ合成
拡散モデルは、オフラインまたはオンライン強化におけるデータ不足を軽減するデータ合成装置として使用できます。学習 問題。従来の強化学習データ強化手法では通常、元のデータをわずかに混乱させるだけですが、拡散モデルの強力な分布フィッティング機能により、データセット全体の分布を直接学習して、新しい高品質データをサンプリングできます。
その他のタイプ
上記のカテゴリに加えて、他の方法で拡散モデルを使用した作品もいくつか点在しています。たとえば、DVF は拡散モデルを使用して価値関数を推定します。 LDCQ は、まず軌道を潜在空間にエンコードし、次に潜在空間に拡散モデルを適用します。 PolyGRAD は拡散モデルを使用して学習環境を動的に転送し、ポリシーとモデルの相互作用を可能にしてポリシーの学習効率を向上させます。
#さまざまな強化学習関連の問題への応用
##オフライン強化学習
拡散モデルの導入により、オフライン強化学習戦略がマルチモーダルなデータ分布に適合し、戦略の表現能力が拡張されます。 Diffuser は、分類子ガイダンスに基づいた高報酬軌道生成アルゴリズムを最初に提案し、その後の多くの研究に影響を与えました。同時に、拡散モデルはマルチタスクおよびマルチエージェントの強化学習シナリオにも適用できます。
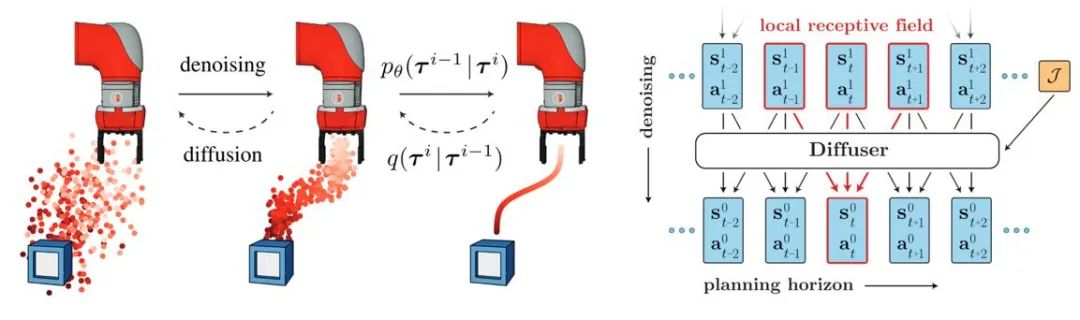 #図 3: ディフューザー軌道生成プロセスとモデル図
#図 3: ディフューザー軌道生成プロセスとモデル図
オンライン強化学習
#研究者らは、拡散モデルにはオンライン強化学習における価値関数と戦略を最適化する機能もあることを証明しました。たとえば、DIPO はアクション データのラベルを変更し、拡散モデル トレーニングを使用して、価値に基づくトレーニングの不安定性を回避しています。CPQL は、戦略としてのシングル ステップ サンプリング拡散モデルがインタラクション中の探索と利用のバランスを取れることを検証しました。
#模倣学習
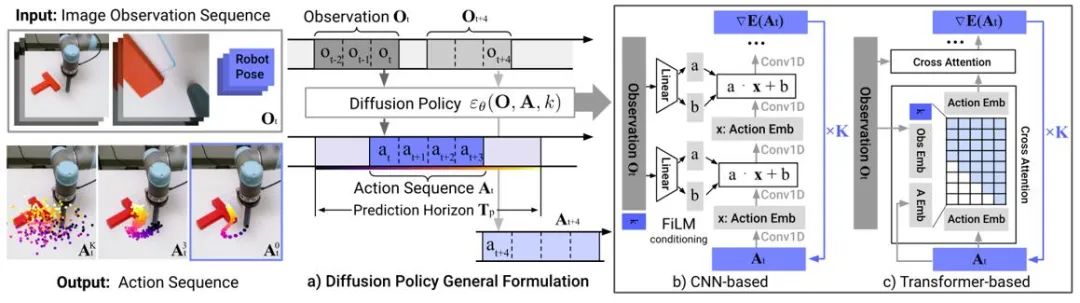
模倣学習は、専門家のデモンストレーション データから学習することによって専門家の行動を再構築します。普及モデルの適用は、政策表現能力を向上させ、多様なタスクスキルを学習するのに役立ちます。ロボット制御の分野では、拡散モデルが時間的安定性を維持しながら閉ループ動作シーケンスを予測できることが研究でわかっています。 Diffusion Policy は、画像入力の拡散モデルを使用してロボットのアクション シーケンスを生成します。実験では、拡散モデルがタイミングの一貫性を確保しながら効果的な閉ループ アクション シーケンスを生成できることが示されています。
#図 4: 拡散政策モデル図
軌道生成
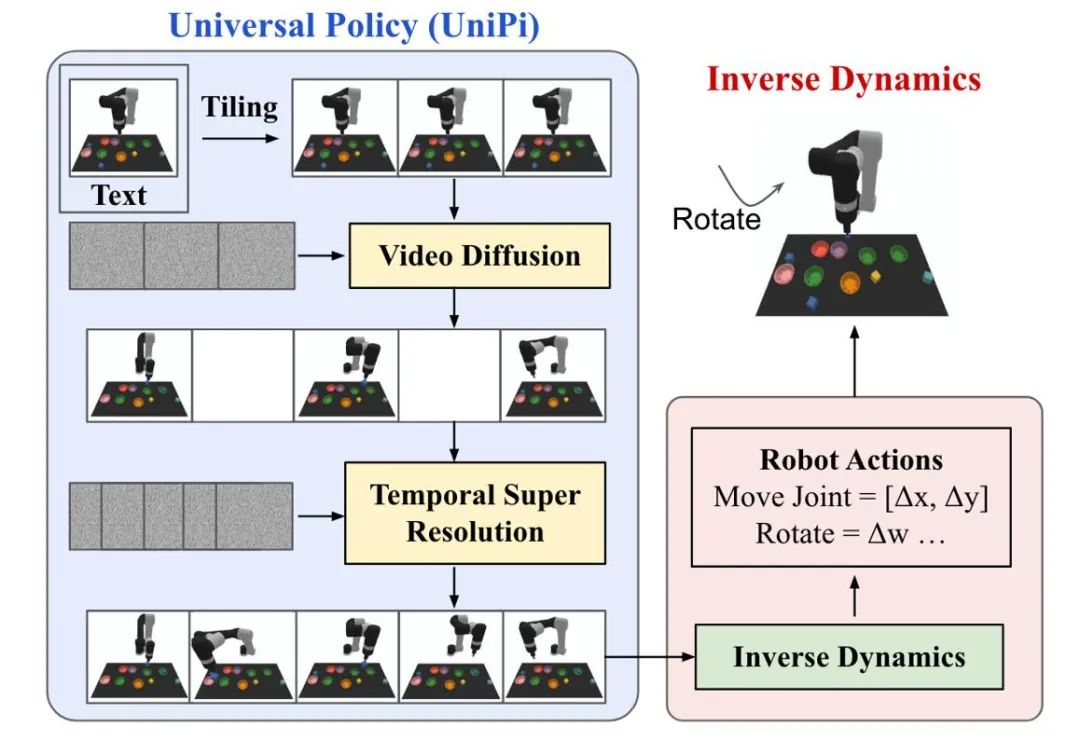
強化学習における拡散モデルの軌道生成は、人間の行動生成とロボット制御の 2 種類のタスクに主に焦点を当てています。拡散モデルによって生成されたアクション データまたはビデオ データは、シミュレーション シミュレーターの構築または下流の意思決定モデルのトレーニングに使用されます。 UniPi は、一般的な戦略としてビデオ生成拡散モデルをトレーニングし、さまざまな逆動力学モデルにアクセスして基礎となる制御コマンドを取得することにより、クロスボディ ロボット制御を実現します。
図 5: UniPi の意思決定プロセスの概略図。
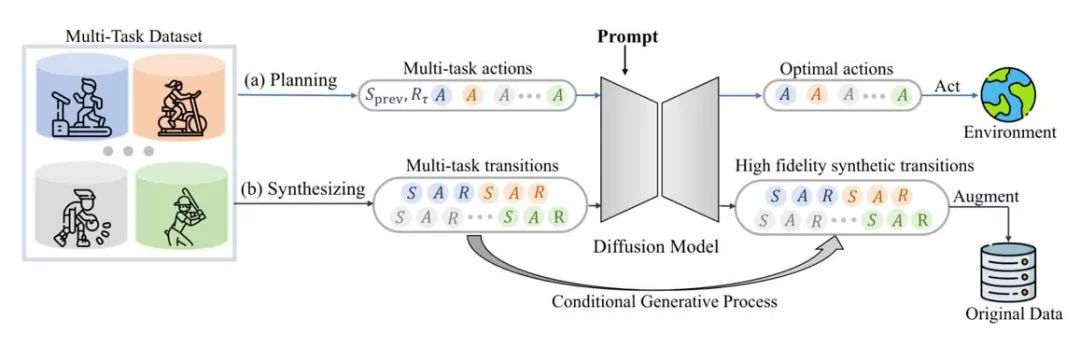
データ強化
拡散モデルは、信頼性を維持しながら、元のデータ分布に直接適合させることもできます。動的に拡張されたデータ。たとえば、SynthER と MTDiff-s は、拡散モデルを通じてトレーニング タスクの完全な環境伝達情報を生成し、政策改善に適用します。その結果、生成されたデータの多様性と精度が従来の方法より優れていることが示されています。
図 6: マルチタスクの計画とデータ強化のための MTDiff の概略図
生成シミュレーション環境
図 1 に示すように、既存の研究では主に拡散モデルを使用して問題を解決しています。エクスペリエンス再生プールの制限により、拡散モデルを使用してシミュレーション環境を強化することに関する研究は比較的少数です。 Gen2Sim は、ヴィンセント グラフ拡散モデルを使用して、シミュレーション環境で多様な操作可能なオブジェクトを生成し、精密なロボット操作の汎化能力を向上させます。拡散モデルには、シミュレーション環境におけるマルチエージェント相互作用における状態遷移関数、報酬関数、または敵対者の行動を生成する可能性もあります。
#セキュリティ制約の追加
安全制約をモデルのサンプリング条件として使用することにより、拡散モデルに基づくエージェントは特定の制約を満たす意思決定を行うことができます。拡散モデルのガイド付きサンプリングにより、元のモデルのパラメーターは変更されずに、追加の分類器を学習することで新しいセキュリティ制約を継続的に追加できるため、追加のトレーニング オーバーヘッドが節約されます。
検索拡張生成
検索拡張生成テクノロジは、大規模な言語で外部データ セットにアクセスすることでモデルの機能を強化できます。このモデルは広く使用されています。これらの状態における拡散ベースの意思決定モデルのパフォーマンスは、エージェントの現在の状態に関連する軌跡を取得し、それをモデルに入力することによっても改善される可能性があります。検索データセットが常に更新されている場合、エージェントは再トレーニングせずに新しい動作を示す可能性があります。
複数のスキルの組み合わせ
拡散モデルは、分類子ガイダンスと組み合わせるか、分類子ガイダンスなしで組み合わせることができます。さまざまなシンプルなスキル複雑なタスクを完了するために。オフライン強化学習の初期の結果は、拡散モデルが異なるスキル間で知識を共有できることを示唆しており、異なるスキルを組み合わせることによってゼロショット転送や継続学習を実現できるようになります。
#表
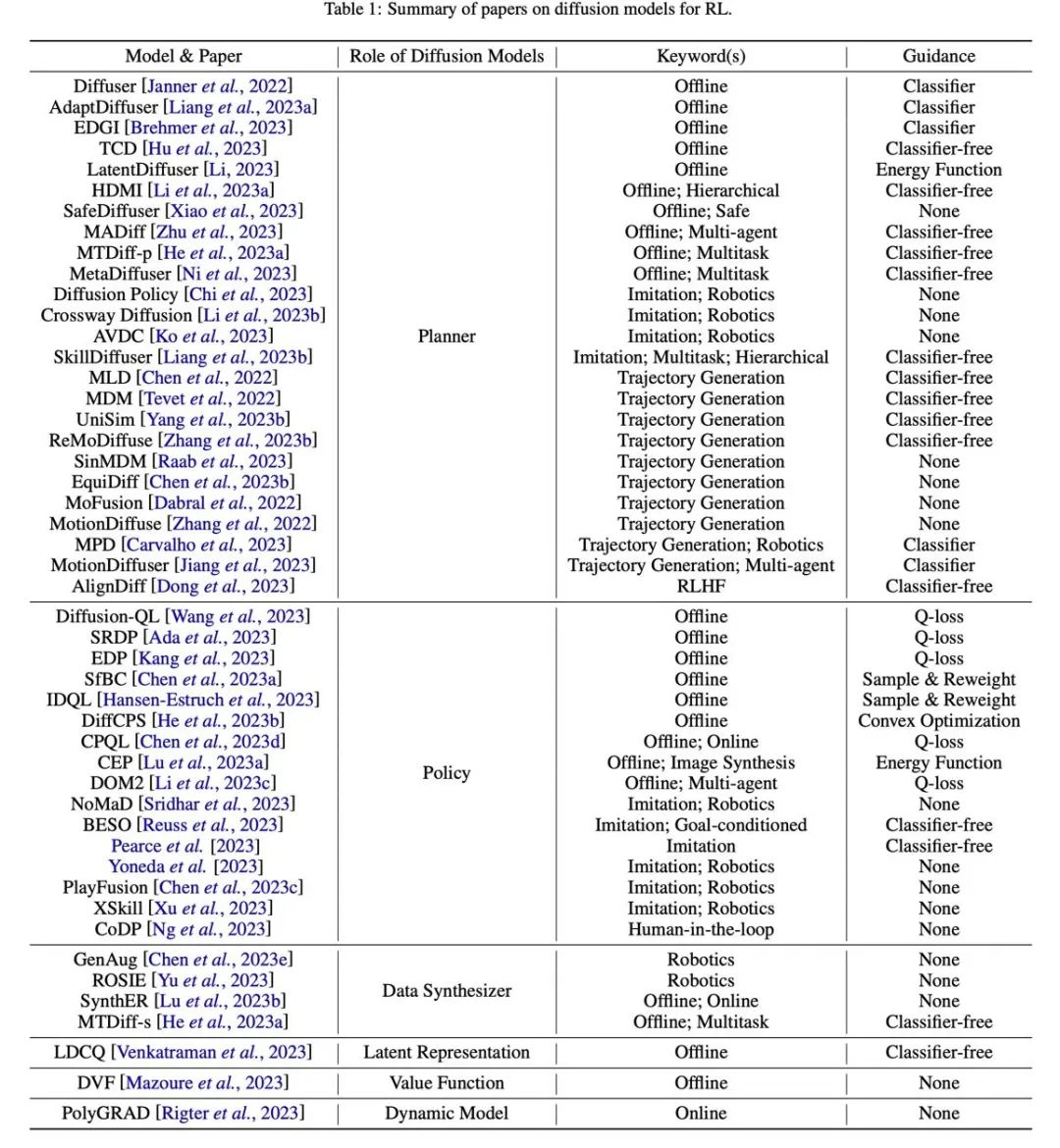
図 7: 関連論文の概要と分類表。
以上が普及モデルはどのようにして新世代の意思決定主体を構築するのでしょうか?自己回帰を超えて、長いシーケンス計画軌道を同時に生成の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7532
7532
 15
1379
52
82
11
21
82
15
1379
52
82
11
21
82

 joiplayシミュレーターの使い方を紹介
May 04, 2024 pm 06:40 PM
joiplayシミュレーターの使い方を紹介
May 04, 2024 pm 06:40 PM
jojplay シミュレータは、非常に使いやすい携帯電話シミュレータです。携帯電話で実行できるコンピュータ ゲームをサポートしており、一部のプレイヤーはその使い方を知りません。以下のエディタでその使い方を紹介します。 。 Joiplay シミュレーターの使用方法 1. まず、Joiplay 本体と RPGM プラグインをダウンロードする必要があります。本体、プラグインの順にインストールするのが最適です。apk パッケージは、Joiplay バー (クリック) で入手できます。 >>>)を取得します。 2. Android が完成したら、左下隅にゲームを追加できます。 3. 適当に名前を入力し、実行ファイルの選択を押してゲームの game.exe ファイルを選択します。 4. アイコンは空白のままにすることも、お気に入りの画像を選択することもできます。
 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 ライフ リスタート シミュレーター ガイド
May 07, 2024 pm 05:28 PM
ライフ リスタート シミュレーター ガイド
May 07, 2024 pm 05:28 PM
Life Restart Simulator は非常に興味深いシミュレーション ゲームです。このゲームにはさまざまな方法があります。以下に、Life Restart Simulator の完全なガイドを示します。戦略はあるのか?ライフ リスタート シミュレーター ガイド ガイド ライフ リスタート シミュレーターの特徴 プレイヤーが自由な発想で遊べる、非常にクリエイティブなゲームです。毎日完了すべきタスクがたくさんあり、この仮想世界で新しい生活を楽しむことができます。ゲーム内にはたくさんの曲があり、さまざまな人生があなたを待っています。ライフ リスタート シミュレーター ゲーム内容 才能カード抽選: 才能: 不滅になるためには、神秘的な小箱を選択する必要があります。途中で死んでしまうことを避けるために、さまざまな小さなカプセルが用意されています。クトゥルフは選ぶかもしれない
 joiplayシミュレーターのフォント設定方法の紹介
May 09, 2024 am 08:31 AM
joiplayシミュレーターのフォント設定方法の紹介
May 09, 2024 am 08:31 AM
jojplay シミュレーターは実際にゲームのフォントをカスタマイズすることができ、テキスト内の文字抜けや囲み文字の問題を解決できます。おそらく、多くのプレイヤーは操作方法を知らないと思います。次のエディターは、その設定方法を提供します。 jojplayシミュレータのフォントを紹介します。 joiplay シミュレーターのフォントを設定する方法 1. まず、joiplay シミュレーターを開き、右上隅にある設定 (3 つの点) をクリックして見つけます。 2. [RPGMSettings] 列で、3 行目の CustomFont カスタム フォントをクリックして選択します。 3. フォント ファイルを選択し、[OK] をクリックします。右下隅の [保存] アイコンをクリックしないように注意してください。クリックしないと、デフォルト設定が復元されます。 4. 創始者および準元の簡体字中国語文字が推奨されます (ゲーム Fuxing および Rebirth のフォルダにすでに入っています)。攘夷
 雷と稲妻シミュレーターのアプリケーションを削除するにはどうすればよいですか? -Thunderbolt Simulator でアプリケーションを削除するにはどうすればよいですか?
May 08, 2024 pm 02:40 PM
雷と稲妻シミュレーターのアプリケーションを削除するにはどうすればよいですか? -Thunderbolt Simulator でアプリケーションを削除するにはどうすればよいですか?
May 08, 2024 pm 02:40 PM
Thunderbolt Simulator の公式バージョンは、非常に専門的な Android エミュレータ ツールです。では、雷と稲妻のシミュレータアプリケーションを削除するにはどうすればよいでしょうか? Thunderbolt シミュレーターでアプリケーションを削除するにはどうすればよいですか?雷と稲妻のシミュレータ アプリケーションを削除する方法を編集者に教えてください。 1. 削除するアプリのアイコンをクリックしたままにします。 2. アプリをアンインストールまたは削除するオプションが表示されるまで、しばらく待ちます。 3. アプリをアンインストール オプションにドラッグします。 4. ポップアップ表示される確認ウィンドウで、「OK」をクリックしてアプリケーションの削除を完了します。
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
最近、軍事界は、米軍戦闘機が AI を使用して完全自動空戦を完了できるようになったというニュースに圧倒されました。そう、つい最近、米軍のAI戦闘機が初めて公開され、その謎が明らかになりました。この戦闘機の正式名称は可変安定性飛行シミュレーター試験機(VISTA)で、アメリカ空軍長官が自ら飛行させ、一対一の空戦をシミュレートした。 5 月 2 日、フランク ケンダル米国空軍長官は X-62AVISTA でエドワーズ空軍基地を離陸しました。1 時間の飛行中、すべての飛行動作が AI によって自律的に完了されたことに注目してください。ケンダル氏は「過去数十年にわたり、私たちは自律型空対空戦闘の無限の可能性について考えてきたが、それは常に手の届かないものだと思われてきた」と語った。しかし今では、
