

身体化された知能に関する Google の新しい研究: RT-2 よりも優れた RT-H が登場

GPT-4 などの大規模な言語モデルがロボット工学との統合が進むにつれて、人工知能は徐々に現実世界に移行しつつあります。したがって、身体化された知能に関連する研究もますます注目を集めています。数ある研究プロジェクトの中でも、Googleのロボット「RT」シリーズは常に最前線にあり、最近その傾向が加速し始めている(詳細は「大規模モデルがロボットを再構築、Google Deepmindが未来の身体的知能をどう定義するか」を参照)。

昨年 7 月、Google DeepMind は、視覚言語行動 (VLA) を制御できる世界初のロボットである RT-2 を発売しました。 . ) 相互作用モデル。会話形式で指示を与えるだけで、RT-2 は大量の写真からスウィフトを特定し、コーラの缶を彼女に届けることができます。
今、このロボットがまた進化しました。 RTロボットの最新バージョンは「RT-H」と呼ばれ、複雑なタスクを単純な言語命令に分解し、その命令をロボットの動作に変換することで、タスク実行の精度と学習効率を向上させることができます。たとえば、「ピスタチオの瓶に蓋をする」などのタスクとシーン画像が与えられると、RT-H は視覚言語モデル (VLM) を使用して、「腕を前に動かす」などの言語動作 (動作) を予測します。 「」「腕を右に回してください」といった言葉の行動をもとにロボットの行動を予測します。

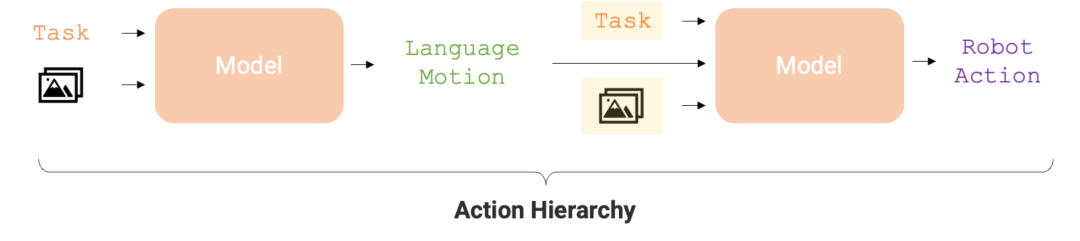
#アクション階層は、ロボット タスクの実行の精度と学習効率を最適化するために重要です。この階層構造により、RT-H はさまざまなロボット タスクにおいて RT-2 よりも大幅にパフォーマンスが向上し、ロボットにより効率的な実行パスが提供されます。

論文の詳細は次のとおりです。
論文の概要

- ##論文のタイトル: RT-H: 言語を使用したアクション階層
- 論文のリンク: https://arxiv.org/pdf/2403.01823.pdf
- プロジェクトリンク: https://rt-hierarchy.github.io/
- 言語は複雑な概念をより単純なコンポーネントに分解し、誤解を修正し、新しい文脈で概念を一般化することを可能にする人間の推論のエンジンです。近年、ロボットは、高レベルの概念を分解したり、言語の修正を行ったり、新しい環境での一般化を達成したりするために、言語の効率的で結合された構造を使用し始めています。
これらの研究は通常、共通のパラダイムに従います。つまり、言語で説明された高レベルのタスク (「コーラの缶を拾う」など) に直面して、観察とタスクを組み合わせる方法を学習します。言語での説明 ポリシーを低レベルのロボット アクションにマッピングします。これには大規模なマルチタスク データセットが必要です。これらのシナリオにおける言語の利点は、類似したタスク間で共有構造をエンコードすること (たとえば、「コーラの缶を拾う」と「リンゴを拾う」) ため、タスクからアクションへのマッピングを学習するために必要なデータが削減されることです。しかし、タスクがより多様になるにつれて、各タスクを説明するために使用される言語もより多様になり(例:「コーラの缶を拾う」と「水をグラスに注ぐ」)、異なるタスク間での学習は高級言語のみで行われるようになります。構造を共有することがより困難になる
研究者は、多様なタスクを学習するために、これらのタスク間の類似点をより正確に把握することを目指しています。
彼らは、言語は高レベルのタスクを説明するだけでなく、そのタスクを完了する方法を詳細に説明できることを発見しました。この種の表現はより繊細で、特定のアクションに近いものになります。たとえば、「コーラの缶を拾う」という作業は、一連のより詳細なステップ、つまり「言語動作」に分解できます。最初に「腕を前に伸ばす」、次に「缶を掴む」、そして最後に「持ち上げる」です。腕を上に上げます。」研究者らの核となる洞察は、高レベルのタスク記述と低レベルのアクションを接続する中間層として言語アクションを使用することで、言語アクションを通じて形成されるアクション階層を構築するために使用できるということです。
このレベルのアクションを確立すると、いくつかの利点があります:
- これにより、異なるタスク間で言語アクション レベルでのデータの共有が向上し、言語アクションの組み合わせとマルチタスク データ セットの一般化が強化されます。たとえば、「コップに水を注ぐ」と「コーラの缶を拾う」は意味的には異なりますが、それらの言語動作は、オブジェクトを拾うために実行されるまではまったく同じです。
- 言語アクションは、単に固定されたプリミティブではなく、現在のタスクとシーンの詳細に基づいた指示と視覚的観察を通じて学習されます。たとえば、「腕を前に伸ばす」という言葉は、移動の速度や方向を指定するものではなく、特定のタスクや観察に依存します。学習された言語動作のコンテキスト依存性と柔軟性により、戦略が 100% 成功しない場合でも言語動作を変更できるという新しい機能が提供されます (図 1 のオレンジ色の領域を参照)。さらに、ロボットはこうした人間の修正から学習することもできます。たとえば、「コーラの缶を拾う」というタスクを実行するときに、ロボットが事前にグリッパーを閉じている場合は、「アームを前方に長く伸ばしたままにする」ようにロボットに指示できますが、特定のシナリオでのこの種の微調整は必要ありません。人間の誘導だけが容易であり、ロボットにとっては学習が容易です。

言語アクションの上記の利点を考慮して、Google DeepMind の研究者はエンドツーエンドのフレームワーク - RT-H を設計しました。 ( アクション階層を備えたロボット トランスフォーマー、つまりアクション レベルを使用するロボット トランスフォーマーは、このタイプのアクション レベルの学習に焦点を当てています。 RT-H は、観察と高レベルのタスクの説明を分析して現在の口頭行動指示を予測することで、詳細レベルでタスクを実行する方法を理解します。次に、これらの観察、タスク、および推定された言語アクションを使用して、RT-H は各ステップに対応するアクションを予測します。言語アクションは、特定のアクションをより正確に予測するのに役立つ追加のコンテキストをプロセスに提供します (図 1 の紫色の領域)。
さらに、彼らはロボットの固有受容から単純化された言語アクション セットを抽出する自動化手法を開発し、手動でラベルを付けることなく 2,500 を超える言語アクションの豊富なデータベースを構築しました。
RT-H のモデル アーキテクチャは、インターネット スケールの視覚データと言語データで共同トレーニングされた大規模視覚言語モデル (VLM) である RT-2 を利用しており、戦略学習の有効性。 RT-H は単一のモデルを使用して言語アクションとアクション クエリの両方を処理し、インターネット規模の広範な知識を活用してアクション階層のあらゆるレベルを強化します。
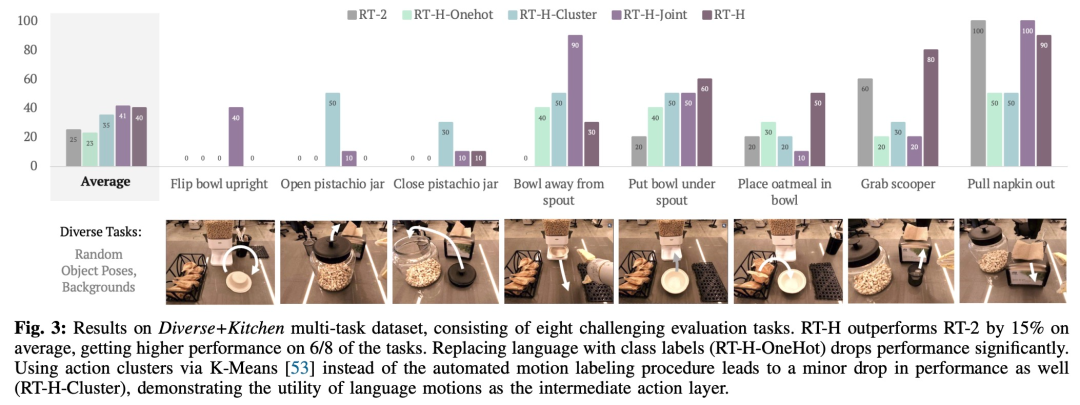
研究者らは実験で、言語アクション階層を使用すると、さまざまなタスクで RT-2 と比較して、多様なマルチタスク データセットの処理が大幅に向上することを発見しました。パフォーマンスは 15 向上しました。 %。彼らはまた、音声動作を変更すると、同じタスクでほぼ完璧な成功率が得られることを発見し、学習された音声動作の柔軟性と状況適応性を実証しました。さらに、言語アクション介入のモデルを微調整することにより、そのパフォーマンスは SOTA 対話型模倣学習手法 (IWR など) を 50% 上回ります。最終的に、RT-H の言語アクションがシーンやオブジェクトの変化によりよく適応できることが証明され、RT-2 よりも優れた汎化パフォーマンスが示されました。
#RT-H アーキテクチャの詳細な説明
#マルチタスク データセット全体の共有構造を効果的にキャプチャするために (高度なデータセットでは表現されません)レベルのタスクの説明)、RT-H はアクション レベルの戦略を明示的に活用する方法を学ぶことを目的としています。
具体的には、研究チームは中間言語アクション予測層をポリシー学習に導入しました。ロボットのきめ細かい動作を記述する言語アクションにより、マルチタスク データセットから有用な情報を取得し、高パフォーマンスのポリシーを生成できます。学習したポリシーを実行するのが難しい場合には、言葉によるアクションが再び機能することがあります。これらは、特定のシナリオに関連するオンラインの人的修正のための直感的なインターフェイスを提供します。音声アクションに基づいてトレーニングされたポリシーは、人間による低レベルの修正に自然に追従し、修正データが与えられたタスクを正常に完了できます。さらに、この戦略は言語修正されたデータでトレーニングすることもでき、そのパフォーマンスをさらに向上させることができます。
#図 2 に示すように、RT-H には 2 つの主要な段階があります。まず、タスクの説明と視覚的観察に基づいて言語アクションを予測し、次に、予測された言語アクションに基づいて言語アクションを予測します。具体的なタスクや観察結果から、正確なアクションを推測します。
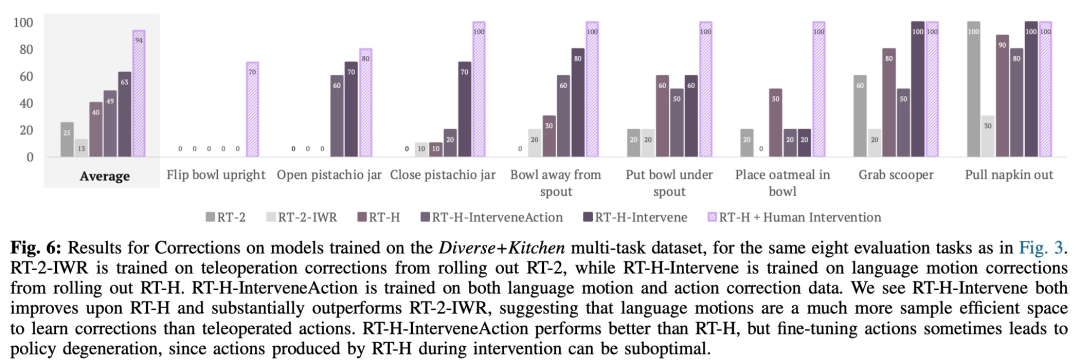
RT-H は VLM バックボーン ネットワークを使用し、RT-2 のトレーニング手順に従ってインスタンス化します。 RT-2 と同様に、RT-H は共同トレーニングを通じてインターネット規模のデータからの自然言語と画像処理に関する広範な事前知識を活用します。この事前知識をアクション階層のすべてのレベルに組み込むために、単一のモデルが言語アクションとアクション クエリの両方を同時に学習します。 RT-H のパフォーマンスを包括的に評価するために、研究チームは 4 つの重要な実験質問を設定しました。 #データセットに関して、この研究では、ランダムなオブジェクトのポーズと背景を持つ 100,000 個のデモンストレーション サンプルを含む大規模なマルチタスク データ セットを使用します。このデータセットは、次のデータセットを組み合わせています: 研究では、この結合データセットを Diverse Kitchen (DK) データセットと呼び、自動プログラムを使用して言語アクションのラベルを付けました。完全な Diverse Kitchen データセットでトレーニングされた RT-H のパフォーマンスを評価するために、研究では次の 8 つの特定のタスクを評価しました。 1) ボウルをカウンターの上に直立して置きます。 3) ピスタチオの瓶を閉じる 4 ) ボウルを移動しますシリアルディスペンサーから離してください 5) ボウルをシリアルディスペンサーの下に置きます 6) オートミールをボウルに置きます 中 8) ディスペンサーからナプキンを取り出します
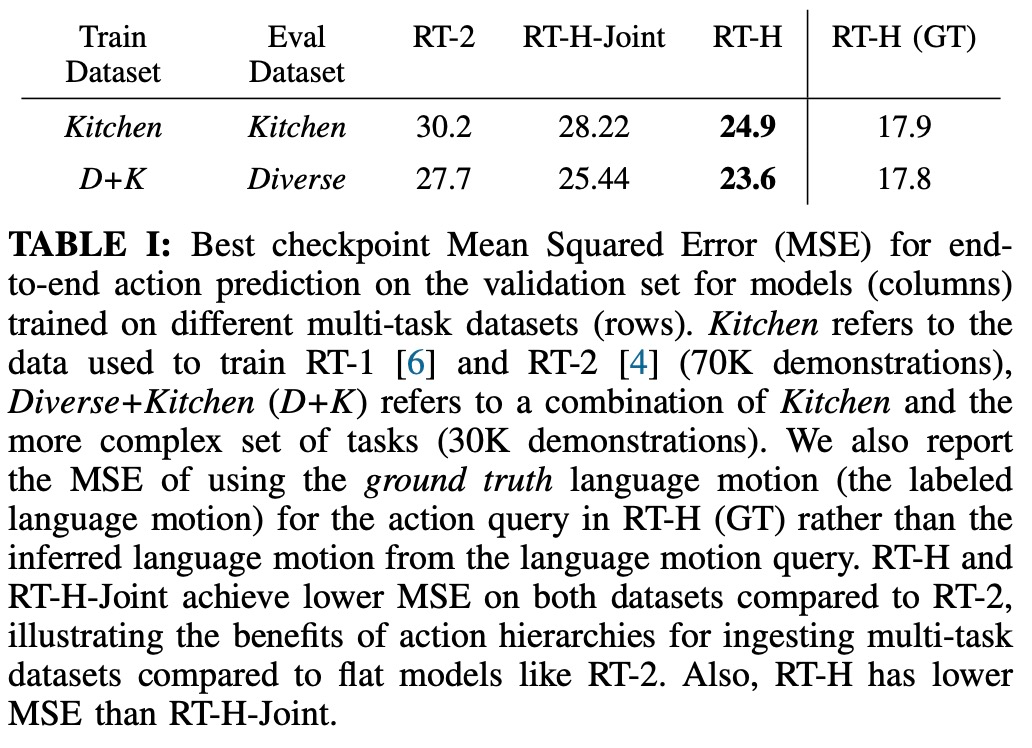
#この研究では、補正の効果を分析するために比較実験も使用しました。結果は、以下の図 6 に示されています。 ##図 7 に示すように、RT-H および RT-H-Joint はシーンの変更に対して大幅に堅牢です。 実際には、一見異なるタスク間には共有構造があります。たとえば、これらのタスクのそれぞれでは、タスクを開始するためにいくつかのピッキング動作が必要ですが、異なるタスクにわたる言語アクションの共有構造を学習することで、RT - H は修正を行わずにピックアップ フェーズを完了します。 RT-H が発話動作の予測を一般化できなくなった場合でも、通常は発話動作の修正により一般化できるため、いくつかの修正を行うだけで済みます。仕事はうまくいきます。これは、新しいタスクに関するデータ収集を拡大する口頭行動の可能性を示しています。 興味のある読者は、論文の原文を読んで研究内容をさらに詳しく知ることができます。 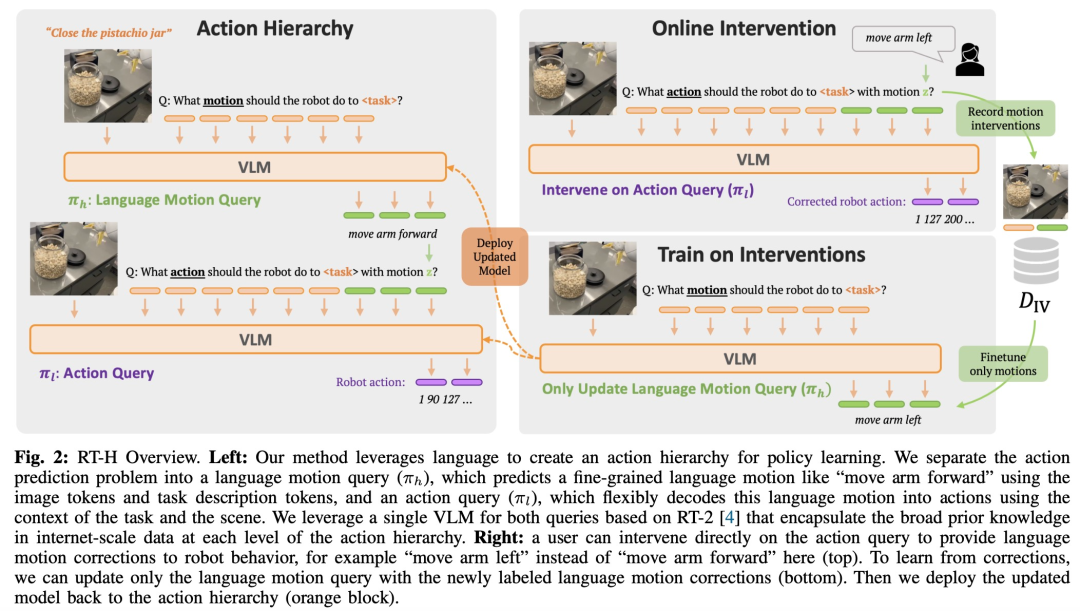
実験結果
 # 図 4 は、RT-H オンライン評価から得られた状況に応じたアクションの例をいくつか示しています。見てわかるように、同じ言語動作でも、より高いレベルの言語動作を尊重しながら、タスクを達成するために動作が微妙に変化することがよくあります。
# 図 4 は、RT-H オンライン評価から得られた状況に応じたアクションの例をいくつか示しています。見てわかるように、同じ言語動作でも、より高いレベルの言語動作を尊重しながら、タスクを達成するために動作が微妙に変化することがよくあります。  図 5 に示すように、研究チームは、RT-H の言語動作にオンラインで介入することで、RT-H の柔軟性を実証しました。
図 5 に示すように、研究チームは、RT-H の言語動作にオンラインで介入することで、RT-H の柔軟性を実証しました。 

以上が身体化された知能に関する Google の新しい研究: RT-2 よりも優れた RT-H が登場の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1659
1659
 14
1415
52
1310
25
1258
29
1232
24
14
1415
52
1310
25
1258
29
1232
24

 セサミオープンドアエクスチェンジウェブページログイン最新バージョンgateio公式ウェブサイトの入り口
Mar 04, 2025 pm 11:48 PM
セサミオープンドアエクスチェンジウェブページログイン最新バージョンgateio公式ウェブサイトの入り口
Mar 04, 2025 pm 11:48 PM
ログインステップやパスワード回復プロセスなど、セサミオープンエクスチェンジWebバージョンのログイン操作の詳細な紹介も、ログイン障害、ページを開くことができず、プラットフォームにスムーズにログインするのに役立つ検証コードを受信できません。
 セサミオープンドア交換Webページ登録リンクゲートトレーディングアプリ登録Webサイト最新
Feb 28, 2025 am 11:06 AM
セサミオープンドア交換Webページ登録リンクゲートトレーディングアプリ登録Webサイト最新
Feb 28, 2025 am 11:06 AM
この記事では、SESAME Open Exchange(gate.io)Webバージョンの登録プロセスとGate Tradingアプリを詳細に紹介します。 Web登録であろうとアプリの登録であろうと、公式Webサイトまたはアプリストアにアクセスして、本物のアプリをダウンロードし、ユーザー名、パスワード、電子メール、携帯電話番号、その他の情報を入力し、電子メールまたは携帯電話の確認を完了する必要があります。
 Crypto Digital Asset Trading App(2025グローバルランキング)に推奨されるトップ10
Mar 18, 2025 pm 12:15 PM
Crypto Digital Asset Trading App(2025グローバルランキング)に推奨されるトップ10
Mar 18, 2025 pm 12:15 PM
この記事では、Binance、Okx、Gate.io、Bitflyer、Kucoin、Bybit、Coinbase Pro、Kraken、Bydfi、Xbit分散化された交換など、注意を払う価値のある上位10の暗号通貨取引プラットフォームを推奨しています。これらのプラットフォームには、トランザクションの数量、トランザクションの種類、セキュリティ、コンプライアンス、特別な機能の点で独自の利点があります。適切なプラットフォームを選択するには、あなた自身の取引体験、リスク許容度、投資の好みに基づいて包括的な検討が必要です。 この記事があなたがあなた自身に最適なスーツを見つけるのに役立つことを願っています
 OUYI OKEXアカウントを登録、使用、キャンセルする方法に関するチュートリアル
Mar 31, 2025 pm 04:21 PM
OUYI OKEXアカウントを登録、使用、キャンセルする方法に関するチュートリアル
Mar 31, 2025 pm 04:21 PM
この記事では、OUYI OKEXアカウントの登録、使用、キャンセル手順を詳細に紹介します。登録するには、アプリをダウンロードし、携帯電話番号または電子メールアドレスを入力して登録する必要があります。使用法は、ログイン、リチャージ、引き出し、取引、セキュリティ設定などの操作手順をカバーします。アカウントをキャンセルするには、OUYI Okexカスタマーサービスに連絡し、必要な情報を提供し、処理を待つ必要があり、最後にアカウントキャンセルの確認を取得する必要があります。 この記事を通じて、ユーザーはOUYI OKEXアカウントの完全なライフサイクル管理を簡単に習得し、デジタルアセットトランザクションを安全かつ便利に実施できます。
 セサミオープンドアトレーディングプラットフォームダウンロードモバイルバージョンgateioトレーディングプラットフォームのダウンロードアドレス
Feb 28, 2025 am 10:51 AM
セサミオープンドアトレーディングプラットフォームダウンロードモバイルバージョンgateioトレーディングプラットフォームのダウンロードアドレス
Feb 28, 2025 am 10:51 AM
アプリをダウンロードしてアカウントの安全を確保するために、正式なチャネルを選択することが重要です。
 Bitget公式Webサイトで最新のアプリを登録およびダウンロードする方法
Mar 05, 2025 am 07:54 AM
Bitget公式Webサイトで最新のアプリを登録およびダウンロードする方法
Mar 05, 2025 am 07:54 AM
このガイドは、AndroidおよびiOSシステムに適した公式Bitget Exchangeアプリの詳細なダウンロードとインストール手順を提供します。このガイドは、公式ウェブサイト、App Store、Google Playなど、複数の権威ある情報源からの情報を統合し、ダウンロードおよびアカウント管理中の考慮事項を強調しています。ユーザーは、App Store、公式WebサイトAPKダウンロード、公式Webサイトジャンプ、完全な登録、ID検証、セキュリティ設定など、公式チャネルからアプリをダウンロードできます。さらに、ガイドはよくある質問や考慮事項をカバーします。
 なぜビテンサーはAIトラックの「ビットコイン」と言われているのですか?
Mar 04, 2025 pm 04:06 PM
なぜビテンサーはAIトラックの「ビットコイン」と言われているのですか?
Mar 04, 2025 pm 04:06 PM
元のタイトル:Bittensor = Aibitcoin:S4MMYETH、分散型AI研究元の翻訳:Zhouzhou、BlockBeats編集者注:この記事では、Bockchain Technologyを通じて中央集権的なAI企業の独占を破り、オープンおよび共同AI Ecosemsytemを促進することを望んでいます。 Bittensorは、さまざまなAIソリューションの出現を可能にし、Tao Tokensを通じてイノベーションを刺激するサブネットモデルを採用しています。 AI市場は成熟していますが、両節は競争リスクに直面し、他のオープンソースの対象となる場合があります
 Binanceの登録方法に関する詳細なチュートリアル(2025初心者ガイド)
Mar 18, 2025 pm 01:57 PM
Binanceの登録方法に関する詳細なチュートリアル(2025初心者ガイド)
Mar 18, 2025 pm 01:57 PM
この記事では、ビナンスの登録とセキュリティ設定の完全なガイドを提供し、事前登録の準備(機器、電子メール、携帯電話番号、IDドキュメントの準備を含む)をカバーし、公式ウェブサイトとアプリに2つの登録方法、およびさまざまなレベルのID検証(KYC)プロセスを紹介します。さらに、この記事では、ファンドパスワードの設定、2要素検証(Google AuthenticatorおよびSMS検証を含む2FA)の有効化、アンチフィッシングコードのセットアップなどの主要なセキュリティ手順にも焦点を当て、ユーザーが暗号通貨トランザクションのBinance Binanceプラットフォームを安全かつ便利に登録および使用するのに役立ちます。 取引する前に、関連する法律や規制、市場のリスクを必ず理解してください。
