

清華 NLP グループが InfLLM をリリースしました: 追加のトレーニングは不要、「1024K の超長コンテキスト」100% 再現率!

大規模モデルは限られたコンテキストしか記憶して理解することができず、これが実際のアプリケーションでは大きな制限となっています。たとえば、会話型 AI システムは、前日の会話の内容を永続的に記憶できないことが多く、その結果、大規模なモデルを使用して構築されたエージェントは一貫性のない動作と記憶を示します。
大規模なモデルがより長いコンテキストをより適切に処理できるようにするために、研究者らは InfLLM と呼ばれる新しい方法を提案しました。この方法は、清華大学、マサチューセッツ工科大学、人民大学の研究者によって共同提案されたもので、大規模言語モデル (LLM) が追加のトレーニングなしで非常に長いテキストを処理できるようになります。 InfLLM は、少量のコンピューティング リソースとグラフィックス メモリのオーバーヘッドを利用して、非常に長いテキストの効率的な処理を実現します。

論文アドレス: https://arxiv.org/abs/2402.04617
コード ウェアハウス: https://github.com/thunlp/InfLLM
実験結果は、InfLLM が Mistral と LLaMA のコンテキスト処理ウィンドウを効果的に拡張し、ニードルを見つけるタスクを実行できることを示しています。 1024K のコンテキストの干し草の山。100% の再現率を達成します。
研究の背景
大規模な事前トレーニング済み言語モデル (LLM) は、近年多くのタスクにおいて画期的な進歩を遂げ、多くのアプリケーションの基本モデルとなっています。 。
これらの実際的なアプリケーションは、LLM が長いシーケンスを処理する能力に対して、より高い課題をもたらします。たとえば、LLM 駆動のエージェントは、外部環境から受信した情報を継続的に処理する必要があるため、より強力なメモリ機能が必要になります。同時に、会話型 AI は、よりパーソナライズされた応答を生成するために、ユーザーとの会話の内容をよりよく記憶する必要があります。
ただし、現在の大規模モデルは通常、数千のトークンを含むシーケンスでしか事前トレーニングされていないため、非常に長いテキストに適用する場合に 2 つの大きな課題が生じます。
1. 配布範囲外の長さ: LLM を長いテキストに直接適用するには、多くの場合、学習範囲を超える位置エンコーディングを LLM で処理する必要があります。したがって、配布外の問題が発生し、一般化することができません;
2. 注意の干渉:過度に長いコンテキストにより、モデルが作成されなくなります。注意が無関係な情報に過度に分割され、コンテキスト内での長期的な意味の依存関係を効果的にモデル化できなくなります。
メソッドの紹介
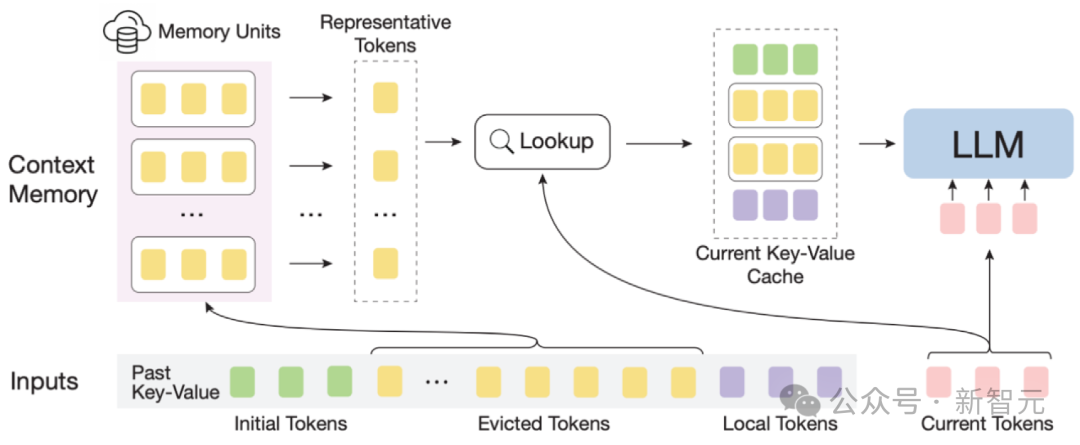
InfLLM 図
大規模なモデルを効率的に実装するには長さの汎化能力を利用して、著者らは、非常に長いシーケンスのストリーミング処理用に、トレーニング不要のメモリ強化手法である InfLLM を提案しています。
InfLLM は、限られた計算コストで超長いコンテキストにおける長距離の意味依存関係を捕捉する LLM の本質的な能力を刺激し、それによって効率的な長いテキストの理解を可能にすることを目的としています。
全体的なフレームワーク: 長いテキストの注目がまばらであることを考慮すると、各トークンの処理には通常、そのコンテキストのごく一部のみが必要です。
著者は、超長いコンテキスト情報を保存する外部メモリ モジュールを構築しました。スライディング ウィンドウ メカニズムを使用して、各計算ステップで、次の値に近いトークン (ローカル トークン) のみが存在します。現在のトークン 外部メモリ モジュール内の少量の関連情報がアテンション レイヤの計算に関与しますが、その他の無関係なノイズは無視されます。
したがって、LLM は、限られたウィンドウ サイズを使用して、長いシーケンス全体を理解し、ノイズの導入を回避できます。
しかし、超長いシーケンス内の大量のコンテキストは、メモリ モジュール内の関連情報の効果的な配置とメモリ検索の効率に重大な課題をもたらします。
これらの課題に対処するために、コンテキスト メモリ モジュールの各メモリ ユニットはセマンティック ブロックで構成され、セマンティック ブロックはいくつかの連続するトークンで構成されます。
具体的には、(1) 関連するメモリユニットを効果的に見つけるために、各セマンティックブロックの一貫したセマンティクスは、断片化されたトークンよりも関連情報クエリのニーズをより効果的に満たすことができます。
さらに、作成者は、各セマンティック ブロックから意味的に最も重要なトークン、つまり、最も高い注意スコアを受け取るトークンを、セマンティック ブロックの表現として選択します。相関計算における重要でないトークンの干渉を避けるために役立ちます。
(2) 効率的なメモリ検索のために、セマンティック ブロック レベルのメモリ ユニットは、トークンごとおよびアテンションごとの相関計算を回避し、計算の複雑さを軽減します。
さらに、セマンティック ブロック レベルのメモリ ユニットにより、継続的なメモリ アクセスが保証され、メモリ読み込みコストが削減されます。
これのおかげで、作者はコンテキスト メモリ モジュールの効率的なオフロード メカニズム (オフロード) を設計しました。
ほとんどのメモリ ユニットが頻繁に使用されないことを考慮して、InfLLM はすべてのメモリ ユニットを CPU メモリにアンロードし、頻繁に使用されるメモリ ユニットを GPU メモリに動的に保持することで、ビデオ メモリの使用量を大幅に削減します。
InfLLM は、 のように要約できます:
1。スライディング ウィンドウに基づいて、リモート コンテキスト メモリ モジュールが追加されます。
2. 歴史的コンテキストを意味ブロックに分割して、コンテキスト メモリ モジュール内のメモリ ユニットを形成します。各メモリ ユニットは、メモリ ユニットの表現として、以前のアテンション計算におけるアテンション スコアを通じて代表トークンを決定します。これにより、コンテキスト内のノイズ干渉が回避され、メモリ クエリの複雑さが軽減されます。
実験分析著者は、Mistral-7b-Inst-v0.2 (32K) に取り組んでいます。 Vicuna InfLLM は、それぞれ 4K と 2K のローカル ウィンドウ サイズを使用して、-7b-v1.5 (4K) モデルに適用されます。
元のモデル、位置コーディング補間、Infinite-LM および StreamingLLM と比較して、長いテキスト データ Infinite-Bench および Longbench で大幅なパフォーマンスの向上が達成されました。
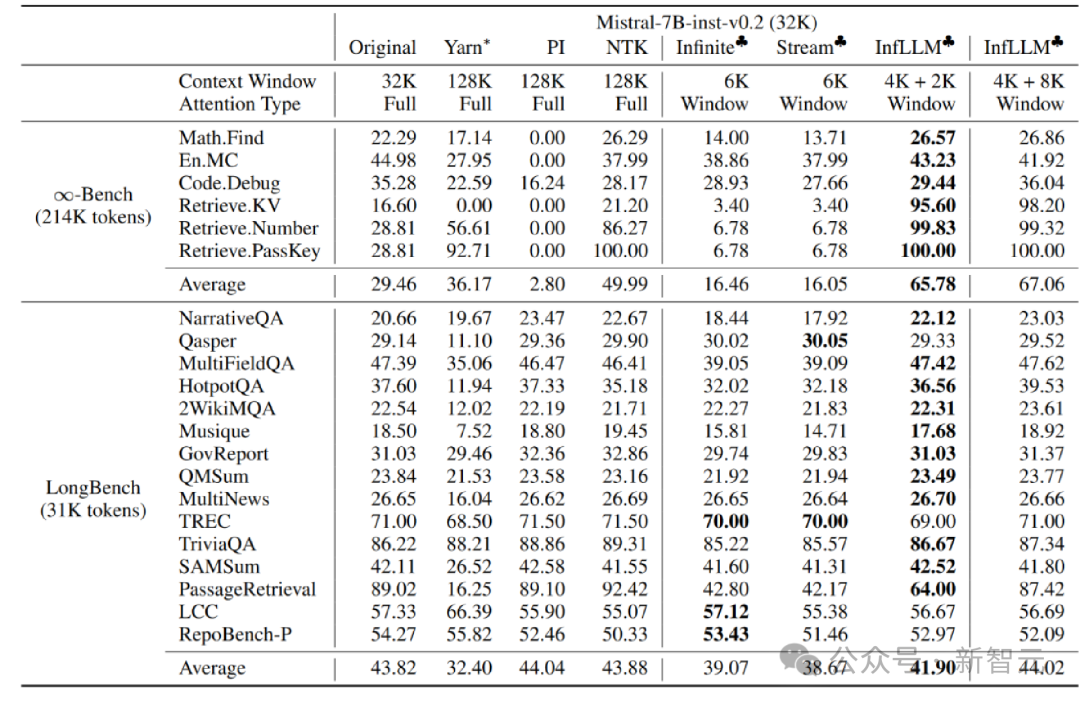
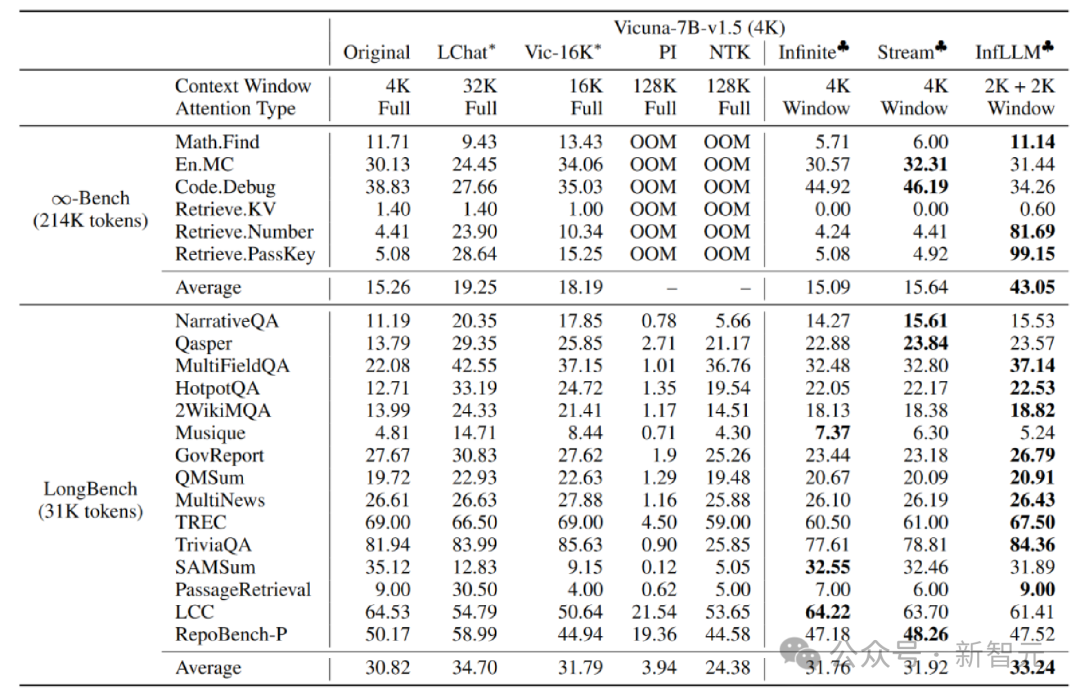
超長いテキストの実験
さらに、著者は長いテキストに対する InfLLM の汎化能力の探索を続けており、長さ 1024K の「干し草の山の中の針」タスクでも 100% の再現率を維持できています。
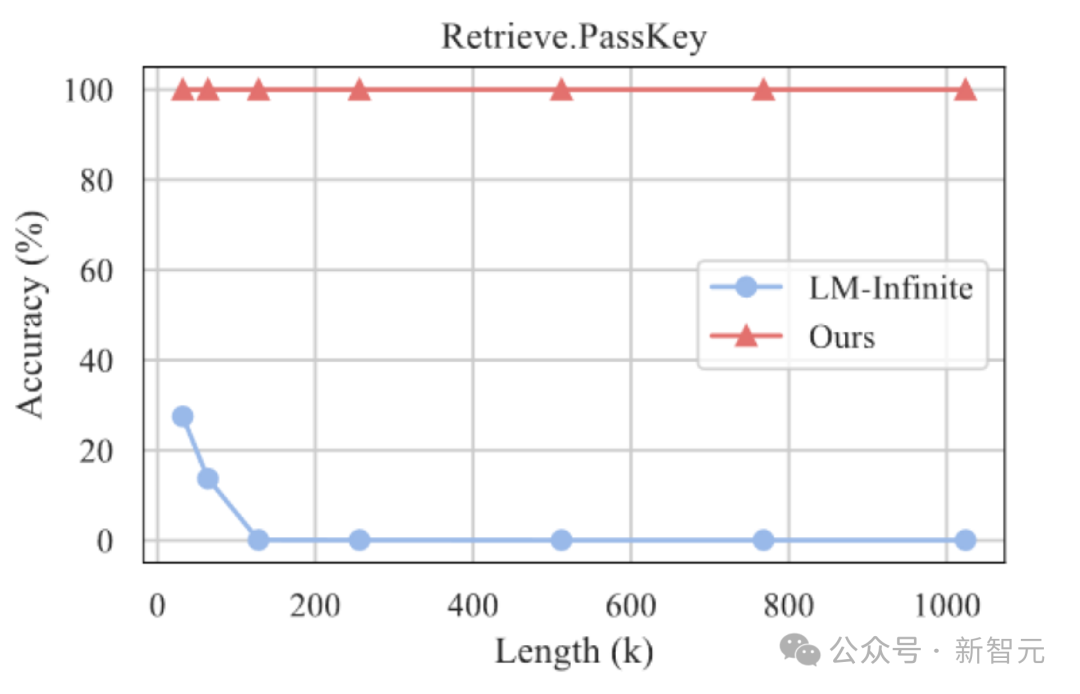
干し草の山に針を刺す実験結果
概要
この記事では、チーム InfLLM が提案されています。これは、トレーニングなしで超長テキスト処理用の LLM の拡張を実現でき、長距離の意味情報を取得できます。
InfLLM は、スライディング ウィンドウに基づいて、長距離コンテキスト情報を含むメモリ モジュールを追加し、キャッシュとオフロード メカニズムを使用して、少量の計算とメモリでストリーミング長いテキスト推論を実装します。消費。 。
以上が清華 NLP グループが InfLLM をリリースしました: 追加のトレーニングは不要、「1024K の超長コンテキスト」100% 再現率!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7555
7555
 15
1382
52
83
11
28
96
15
1382
52
83
11
28
96

 Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centos Shutdownコマンドはシャットダウンし、構文はシャットダウン[オプション]時間[情報]です。オプションは次のとおりです。-hシステムをすぐに停止します。 -pシャットダウン後に電源をオフにします。 -r再起動; -t待機時間。時間は、即時(現在)、数分(分)、または特定の時間(HH:mm)として指定できます。追加の情報をシステムメッセージに表示できます。
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosシステムの下でのGitlabのバックアップと回復ポリシーデータセキュリティと回復可能性を確保するために、Gitlab on Centosはさまざまなバックアップ方法を提供します。この記事では、いくつかの一般的なバックアップ方法、構成パラメーター、リカバリプロセスを詳細に紹介し、完全なGitLabバックアップと回復戦略を確立するのに役立ちます。 1.手動バックアップGitlab-RakeGitlabを使用:バックアップ:コマンドを作成して、マニュアルバックアップを実行します。このコマンドは、gitlabリポジトリ、データベース、ユーザー、ユーザーグループ、キー、アクセスなどのキー情報をバックアップします。デフォルトのバックアップファイルは、/var/opt/gitlab/backupsディレクトリに保存されます。 /etc /gitlabを変更できます
 CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CENTOSシステムでHDFS構成をチェックするための完全なガイドこの記事では、CENTOSシステム上のHDFSの構成と実行ステータスを効果的に確認する方法をガイドします。次の手順は、HDFSのセットアップと操作を完全に理解するのに役立ちます。 Hadoop環境変数を確認します。最初に、Hadoop環境変数が正しく設定されていることを確認してください。端末では、次のコマンドを実行して、Hadoopが正しくインストールおよび構成されていることを確認します。HDFS構成をチェックするHDFSファイル:HDFSのコア構成ファイルは/etc/hadoop/conf/ディレクトリにあります。使用
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
 Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
CentOSにMySQLをインストールするには、次の手順が含まれます。適切なMySQL Yumソースの追加。 yumを実行して、mysql-serverコマンドをインストールして、mysqlサーバーをインストールします。ルートユーザーパスワードの設定など、MySQL_SECURE_INSTALLATIONコマンドを使用して、セキュリティ設定を作成します。必要に応じてMySQL構成ファイルをカスタマイズします。 MySQLパラメーターを調整し、パフォーマンスのためにデータベースを最適化します。
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Centos8はsshを再起動します
Apr 14, 2025 pm 09:00 PM
Centos8はsshを再起動します
Apr 14, 2025 pm 09:00 PM
SSHサービスを再起動するコマンドは次のとおりです。SystemCTL再起動SSHD。詳細な手順:1。端子にアクセスし、サーバーに接続します。 2。コマンドを入力します:SystemCtl RestArt SSHD; 3.サービスステータスの確認:SystemCTLステータスSSHD。
 CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
Pytorchの分散トレーニングでは、Centosシステムでトレーニングには次の手順が必要です。Pytorchのインストール:PythonとPipがCentosシステムにインストールされていることです。 CUDAバージョンに応じて、Pytorchの公式Webサイトから適切なインストールコマンドを入手してください。 CPUのみのトレーニングには、次のコマンドを使用できます。PipinstalltorchtorchtorchvisionTorchaudioGPUサポートが必要な場合は、CUDAとCUDNNの対応するバージョンがインストールされ、インストールに対応するPytorchバージョンを使用してください。分散環境構成:分散トレーニングには、通常、複数のマシンまたは単一マシンの複数GPUが必要です。場所
