

Linux ファイル システム (ファイル システム) アーキテクチャの簡単な分析


この記事では主に仮想ファイル システムについて説明します。 Linux ファイル システムのアーキテクチャには、特定のファイル システム (Ext2、Ext3、XFS など) とアプリケーション間の抽象化レイヤー、つまり仮想ファイル システム (VFS) が含まれています。 VFS を使用すると、アプリケーションは、基礎となるファイル システムの詳細を知らなくても、さまざまな種類のファイル システムと通信できます。 VFS を使用すると、ファイル システムの実装をアプリケーションから分離して切り離すことができるため、システムの柔軟性と保守性が向上します。また、VFS を使用すると、Linux カーネルが複数のファイル システム タイプをサポートできるようになり、アプリケーションがファイル システムにアクセスするための統一インターフェイスが提供されます。 VFS のフレームワークでは、標準のファイル システム操作インターフェイスを実装することで、さまざまなファイル システムがカーネルと通信できます。
上の図は、このアーキテクチャの中心が仮想ファイル システム VFS であることを示しています。 VFS はファイル システム フレームワークを提供し、ローカル ファイル システムは VFS に基づいて実装できます。主に次のタスクを実行します:
1) VFS は抽象化層として、アプリケーション層に統合インターフェイス (読み取り、書き込み、chmod など) を提供します。
2) i ノード キャッシュやページ キャッシュなど、いくつかの一般的な機能が VFS に実装されています。
3) 特定のファイル システムが実装する必要があるインターフェイスを標準化します。
上記の設定に基づいて、他の特定のファイル システムは、VFS の規則に従い、対応するインターフェイスと内部ロジックを実装し、システムに登録するだけで済みます。ユーザーはファイル システムをフォーマットしてマウントした後、ハードディスク リソースを使用してファイル システムに基づいた操作を実行できます。
Linux オペレーティング システムでは、ディスクをフォーマットした後、mount コマンドを使用して、システム ディレクトリ ツリー内のディレクトリにディスクをマウントする必要があります。このディレクトリはマウント ポイントと呼ばれます。マウントが完了すると、このファイル システムに基づいてフォーマットされたハードディスク領域を使用できるようになります。 Linux オペレーティング システムでは、マウント ポイントはほぼ任意のディレクトリにすることができますが、標準化のため、通常、マウント ポイントは mnt ディレクトリの下のサブディレクトリになります。
次に、比較的複雑なディレクトリ構造を示します。このディレクトリ構造では、ルート ディレクトリはハード ディスク sda 上にあり、mnt ディレクトリの下には ext4、xfs、nfs という 3 つのサブディレクトリがあり、それぞれ Ext4 ファイル システム (sdb ハード ディスク上に構築) とXFS ファイル システム (sdc ハード ドライブ上に構築) および NFS ファイル システム (ネットワーク経由でマウント)。
###写真###ディレクトリ ツリー内の複数のファイル システム間の関係は、カーネル内のいくつかのデータ構造によって表されます。ファイルシステムをマウントすると、ファイルシステム間の関係が確立され、特定のファイルシステムの API が登録されます。ユーザー モードが API を呼び出してファイルを開くと、対応するファイル システム API が検索され、それがファイル関連の構造 (ファイルや i ノードなど) に関連付けられます。
上記の説明は比較的概略的なものですが、それでも少し混乱するかもしれません。ただし、心配しないでください。次に、コードに基づいて VFS と複数のファイル システムをサポートする方法について詳しく説明します。
1. ファイル システム API から VFS、そして特定のファイル システムへ
Linux の VFS は最初から利用できませんでした。Linux の最初にリリースされたバージョンには VFS がありませんでした。さらに、VFS は Linux で発明されたものではなく、1985 年に Sun によって SunOS2.0 で最初に開発されました。 VFS を開発する主な目的は、ローカル ファイル システムと NFS ファイル システムを適合させることです。
VFS は、一連のパブリック API とデータ構造を通じて特定のファイル システムの抽象化を実装します。ユーザーがオペレーティング システムが提供するファイル システム API を呼び出すと、カーネル VFS によって実装された関数がソフト割り込みを通じて呼び出されます。次の表は、いくつかのファイル API とカーネル VFS 関数の対応を示しています。
|
カーネル関数 |
イラスト |
###開ける### |
|
| ファイルを開く
|
###近い###
| ksys_close
|
ファイルを閉じる |
###読む### |
ksys_read/vfs_read |
|
|
###書く###
| ksys_write/vfs_write
###データ入力### |
|
###マウント###
| do_mount
| ファイルシステムのマウント
|
以上がLinux ファイル システム (ファイル システム) アーキテクチャの簡単な分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7720
7720
 15
1642
14
1396
52
1289
25
1233
29
15
1642
14
1396
52
1289
25
1233
29

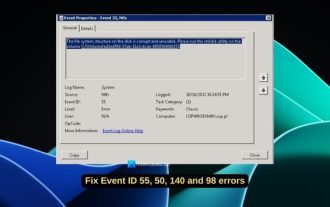 イベント ビューアでのイベント ID 55、50、98、140 のディスク エラーを修正
Mar 19, 2024 am 09:43 AM
イベント ビューアでのイベント ID 55、50、98、140 のディスク エラーを修正
Mar 19, 2024 am 09:43 AM
Windows 11/10 のイベント ビューアーでイベント ID 55、50、140、または 98 が表示された場合、またはディスク ファイル システム構造が破損しているため使用できないというエラーが発生した場合は、次のガイドに従って問題を解決してください。イベント 55、ディスク上のファイル システム構造が壊れていて使用できないとはどういう意味ですか?セッション 55 では、Ntfs ディスク上のファイル システム構造が破損しており、使用できません。ボリューム上で chkMSK ユーティリティを実行してください。NTFS がトランザクション ログにデータを書き込むことができない場合、イベント ID 55 のエラーがトリガーされ、NTFS はトランザクション データを書き込むことができず操作を完了できません。このエラーは通常、ディスク上に不良セクタが存在するか、ディスク サブシステムのファイル システムが不十分なために、ファイル システムが破損した場合に発生します。
 システムの安定性の問題を解決するために Kali Linux ソフトウェアをアンインストールするための完全ガイド
Mar 23, 2024 am 10:50 AM
システムの安定性の問題を解決するために Kali Linux ソフトウェアをアンインストールするための完全ガイド
Mar 23, 2024 am 10:50 AM
この研究は、KaliLinux の侵入テストおよびセキュリティ監査プロセス中に発生する可能性のあるソフトウェアのアンインストール問題の包括的かつ詳細な分析を提供し、システムの安定性と信頼性を確保するためのソリューションに貢献します。 1. ソフトウェアのインストール方法を理解する kalilinux からソフトウェアをアンインストールする前に、まずインストール パスを決定することが重要な手順です。次に、選択されたパスに基づいて、適切なオフロード ソリューションが選択されます。一般的なインストール方法には、apt-get、dpkg、ソース コード コンパイル、その他の形式が含まれます。各戦略には独自の特徴とそれに対応するオフロード手段があります。 2. apt-get コマンドを使用してソフトウェアをアンインストールする KaliLinux システムでは、ソフトウェア パッケージを効率的かつ便利に実行するために、apt-get 機能コンポーネントが広く使用されています。
 15分で完了する国産オペレーティングシステムKirin Linuxのインストール完全ガイド
Mar 21, 2024 pm 02:36 PM
15分で完了する国産オペレーティングシステムKirin Linuxのインストール完全ガイド
Mar 21, 2024 pm 02:36 PM
最近、国産オペレーティングシステム「Kirin Linux」が注目を集めていますが、上級コンピュータエンジニアとして技術革新に強い関心を持っている私が、このシステムの導入プロセスを実際に体験してきましたので、その体験をお話しします。インストール手順を実行する前に、関連する手順の準備を十分に整えました。最初のタスクは、最新の Kirin Linux オペレーティング システム イメージをダウンロードして USB フラッシュ ドライブにコピーすることです。次に、64 ビット Linux の場合は、潜在的なインストールの問題に対処するために個人デバイス内の重要なデータがバックアップされていることを確認し、最後に終了します。コンピューターの電源を切り、USB フラッシュドライブを挿入します。インストール インターフェイスに入り、コンピュータを再起動した後、すぐに F12 ファンクション キーを押し、システム ブート メニューに入り、USB 優先ブート オプションを選択します。美しくシンプルな起動画面が目の前に現れます
 puppylinux インストール USB ディスク
Mar 18, 2024 pm 06:31 PM
puppylinux インストール USB ディスク
Mar 18, 2024 pm 06:31 PM
実際、コンピュータを長期間使用すると、全体的なパフォーマンスは低下傾向を示し、Windows システムへの適応性は低下し続けます。コンピューター自体の理由に加えて、Windows システムは強化および拡張され続けており、ハードウェア要件もますます高くなっています。したがって、Windowsシステムをインストールした後に古いコンピューターに遅延が発生するのは驚くべきことではありません。以前は、多くの友人がバックグラウンドでシステムの遅れについて、古いコンピューターをどうすればよいか尋ねていました。古いコンピューターに新しい Windows 10 システムをインストールすると遅延や操作上の問題が発生する場合は、Linux への切り替えを検討することをお勧めします。 Dabaicai は、古いコンピュータに適した 5 つのマイクロ Linux システムをコンパイルしました。これらは、CPU 使用率を効果的に削減し、
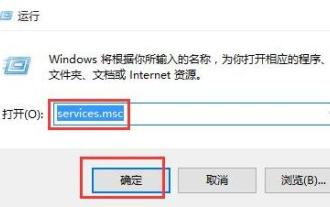 WIN10でファイルシステムエラー2147416359を処理する方法
Mar 27, 2024 am 11:31 AM
WIN10でファイルシステムエラー2147416359を処理する方法
Mar 27, 2024 am 11:31 AM
1. win+r を押して実行ウィンドウに入り、「services.msc」と入力して Enter を押します。 2. サービス ウィンドウで [Windows ライセンス マネージャー サービス] を見つけ、ダブルクリックして開きます。 3. インターフェースでスタートアップの種類を [自動] に変更し、[適用 → OK] をクリックします。 4. 上記の設定を完了し、コンピュータを再起動します。
 Spring Data JPA のアーキテクチャと動作原理は何ですか?
Apr 17, 2024 pm 02:48 PM
Spring Data JPA のアーキテクチャと動作原理は何ですか?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA は JPA アーキテクチャに基づいており、マッピング、ORM、トランザクション管理を通じてデータベースと対話します。そのリポジトリは CRUD 操作を提供し、派生クエリによりデータベース アクセスが簡素化されます。さらに、遅延読み込みを使用して必要な場合にのみデータを取得するため、パフォーマンスが向上します。
 Linuxのコマンドラインで文字化けが表示される問題の解決方法
Mar 21, 2024 am 08:30 AM
Linuxのコマンドラインで文字化けが表示される問題の解決方法
Mar 21, 2024 am 08:30 AM
Linux のコマンド ラインで文字化けが表示される問題を解決する方法 Linux オペレーティング システムでは、コマンド ライン インターフェイスの使用時に文字化けが表示されることがあり、コマンドの出力結果やファイルの通常の表示と理解に影響を及ぼします。コンテンツ。文字化けの原因としては、システムの文字セット設定が間違っている、ターミナルソフトウェアが特定の文字セットの表示をサポートしていない、ファイルのエンコード形式が一致していないなどが考えられます。この記事では、Linux コマンド ラインで表示される文字化けの問題を解決するいくつかの方法を紹介し、読者が同様の問題を解決するのに役立つ具体的なコード例を示します。
 Linux システム管理者が明かす: Red Hat Linux バージョン分析の完全ガイド
Mar 29, 2024 am 09:16 AM
Linux システム管理者が明かす: Red Hat Linux バージョン分析の完全ガイド
Mar 29, 2024 am 09:16 AM
私は上級 Linux システム管理者として、RedHat バージョンの Linux システムの分析、診断、治療に関して深い知識ベースと独自の視点をすでに持っています。この記事では、Linux システムの RedHat バージョンのあらゆる側面について詳細な分析を提供します。これには、バージョン特性の特定、バージョン番号のデコード、テスト バージョンの更新を送信するための実際の手順などが含まれます。 RedHat オペレーティング システムの機能を完全に把握し、効率的に活用します。 1. RedHat について理解する RedHat は、米国で最も市場価値の高いインターネット企業の 1 つであり、オープンソース技術の枠組みの下で開発されたオペレーティング システム製品を通じて、世界のソフトウェア市場で主導的な地位を獲得しています。その Linux ディストリビューション RedHat EnterpriseLinux (以下、
