
 テクノロジー周辺機器
AI
ヤン・シュイチェン/チェン・ミンミンの新作! Sora のコアコンポーネントである DiT トレーニングは 10 倍高速化され、Masked Diffusion Transformer V2 はオープンソースです
テクノロジー周辺機器
AI
ヤン・シュイチェン/チェン・ミンミンの新作! Sora のコアコンポーネントである DiT トレーニングは 10 倍高速化され、Masked Diffusion Transformer V2 はオープンソースです
ヤン・シュイチェン/チェン・ミンミンの新作! Sora のコアコンポーネントである DiT トレーニングは 10 倍高速化され、Masked Diffusion Transformer V2 はオープンソースです

Sora の魅力的なコア テクノロジーの 1 つとして、DiT は拡散トランスフォーマーを利用して生成モデルを大規模に拡張し、優れた画像生成効果を実現します。
ただし、モデルのサイズが大きくなると、トレーニングのコストが急増します。
南開大学Sea AI LabのYan Shuicheng氏とCheng Mingming氏の研究チーム、およびKunlun Wanwei 2050 Research Instituteは、ICCV 2023カンファレンスでマスク拡散トランスと呼ばれる新しいモデルを提案しました。このモデルは、マスク モデリング技術を使用して、意味表現情報を学習することで拡散トランスフォーマーのトレーニングを高速化し、画像生成分野で SoTA 効果を実現します。このイノベーションは、画像生成モデルの開発に新たなブレークスルーをもたらし、研究者により効率的なトレーニング方法を提供します。研究チームは、さまざまな分野の専門知識とテクノロジーを組み合わせることで、トレーニング速度を向上させ、生成結果を向上させるソリューションを提案することに成功しました。彼らの研究は、人工知能分野の発展に重要な革新的なアイデアに貢献し、将来の研究と実践に有益なインスピレーションを提供しました
 写真
写真
論文アドレス: https://arxiv.org/abs/2303.14389
GitHub アドレス: https://github.com/sail-sg/MDT
##最近、Masked Diffusion Transformer V2 が再び SoTA を更新し、DiT と比較してトレーニング速度が 10 倍以上向上し、ImageNet ベンチマークで 1.58 の FID スコアを達成しました。 論文とコードの最新バージョンはオープンソースです。 背景 DiT に代表される拡散モデルは画像生成の分野で大きな成功を収めてきましたが、研究者らは、拡散モデルは多くの場合、画像内のオブジェクトの部分間の意味的関係を効率的に学習することは困難であり、この制限がトレーニング プロセスの収束効率の低下につながります。 図
図
 写真
写真
推論プロセス中、MDT は標準の拡散生成プロセスを維持します。 MDT の設計により、Difffusion Transformer は、マスク モデリング表現の学習によってもたらされる意味情報表現能力と、画像の詳細を生成する拡散モデルの能力の両方を得ることができます。
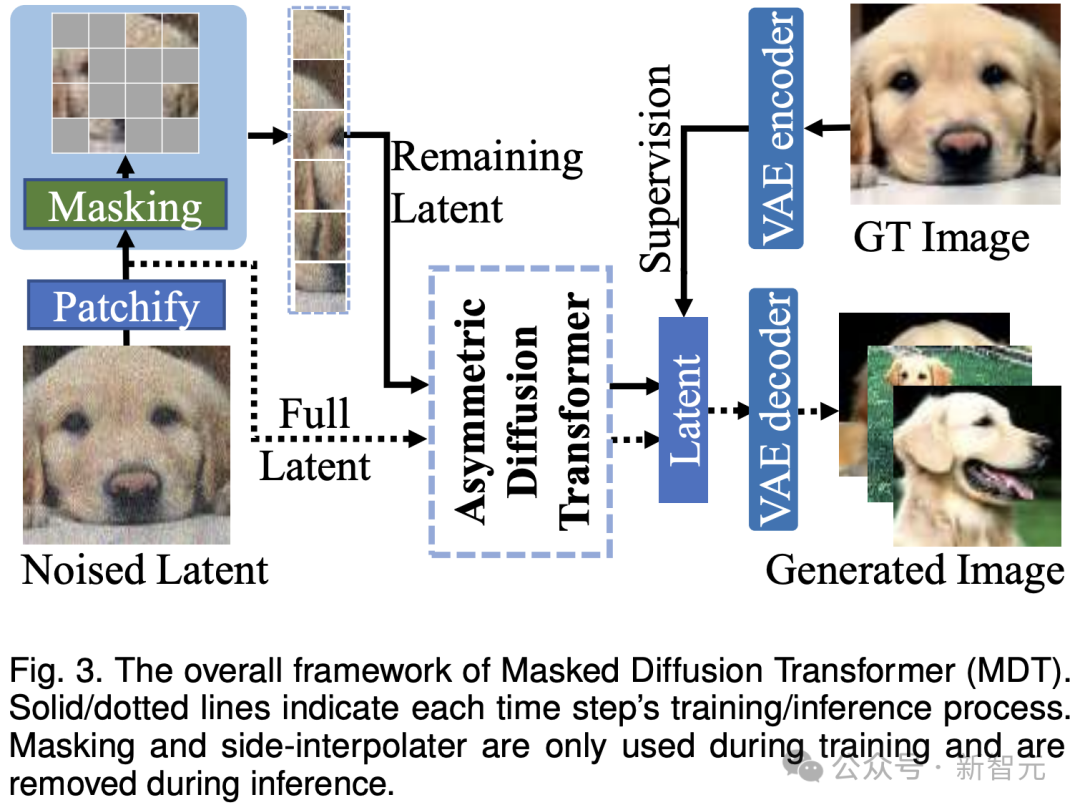
具体的には、MDT は VAE エンコーダーを通じて画像を潜在空間にマッピングし、それらを潜在空間で処理してコンピューティング コストを節約します。
トレーニング プロセス中、MDT はまずノイズが追加された画像トークンの一部をマスクし、残りのトークンを非対称拡散変換器に送信して、ノイズ除去後のすべての画像トークンを予測します。
#非対称拡散トランス アーキテクチャ##写真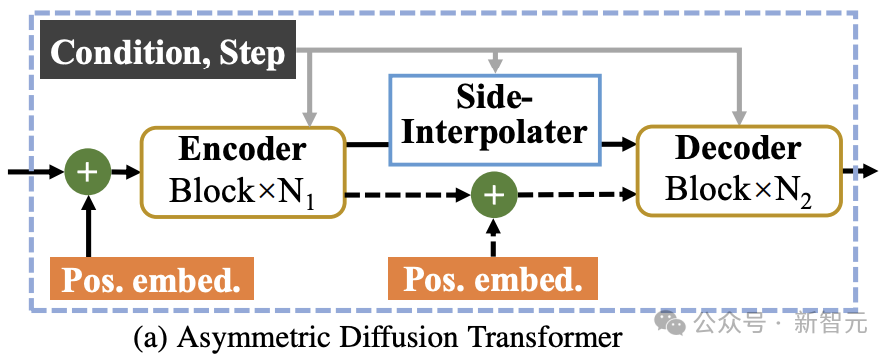
として上の図に示されているように、非対称拡散トランスのアーキテクチャには、エンコーダ、サイド補間器 (補助補間器)、およびデコーダが含まれています。
図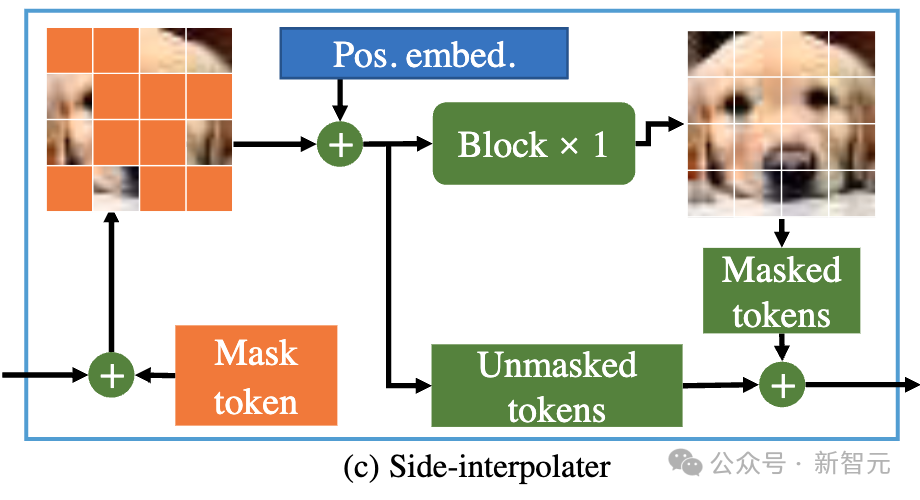
トレーニング プロセス中、Encoder はマスクされていないトークンのみを処理します。推論では、マスク ステップがないため、すべてのトークンが処理されます。
したがって、デコーダーがトレーニングまたは推論フェーズ中に常にすべてのトークンを処理できるようにするために、研究者らは解決策を提案しました。トレーニング プロセス中に、以下で構成される DiT ブロックを使用するというものです。補助補間器 (上の図に示す) は、エンコーダーの出力からマスクされたトークンを補間および予測し、推論のオーバーヘッドを追加することなく推論段階でそれを削除します。
MDT のエンコーダとデコーダは、グローバルおよびローカル位置エンコード情報を標準 DiT ブロックに挿入して、マスク部分のトークンの予測を支援します。
#非対称拡散トランス V2##写真
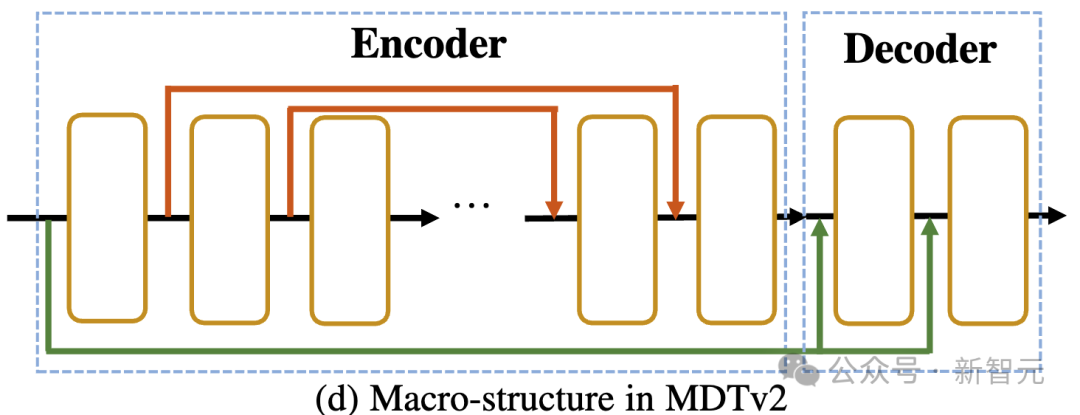 として上の図に示すように、MDTv2 は、マスク拡散プロセス用に設計されたより効率的なマクロ ネットワーク構造を導入することにより、拡散とマスク モデリングの学習プロセスをさらに最適化します。
として上の図に示すように、MDTv2 は、マスク拡散プロセス用に設計されたより効率的なマクロ ネットワーク構造を導入することにより、拡散とマスク モデリングの学習プロセスをさらに最適化します。
これには、エンコーダでの U-Net スタイルのロング ショートカットとデコーダでの高密度入力ショートカットの統合が含まれます。
このうち、dense input-shortcut は、マスクされたトークンにノイズを追加してデコーダーに送信し、マスクされたトークンに対応するノイズ情報を保持するため、拡散のトレーニングが容易になります。プロセス。 。
さらに、MDT は、より高速な Adan オプティマイザー、タイムステップ関連の損失重み、拡散モデルのマスクされたトレーニング プロセスをさらに加速する拡張マスク比など、より優れたトレーニング戦略も導入しました。 。
#実験結果ImageNet 256 ベンチマーク生成の品質比較 Image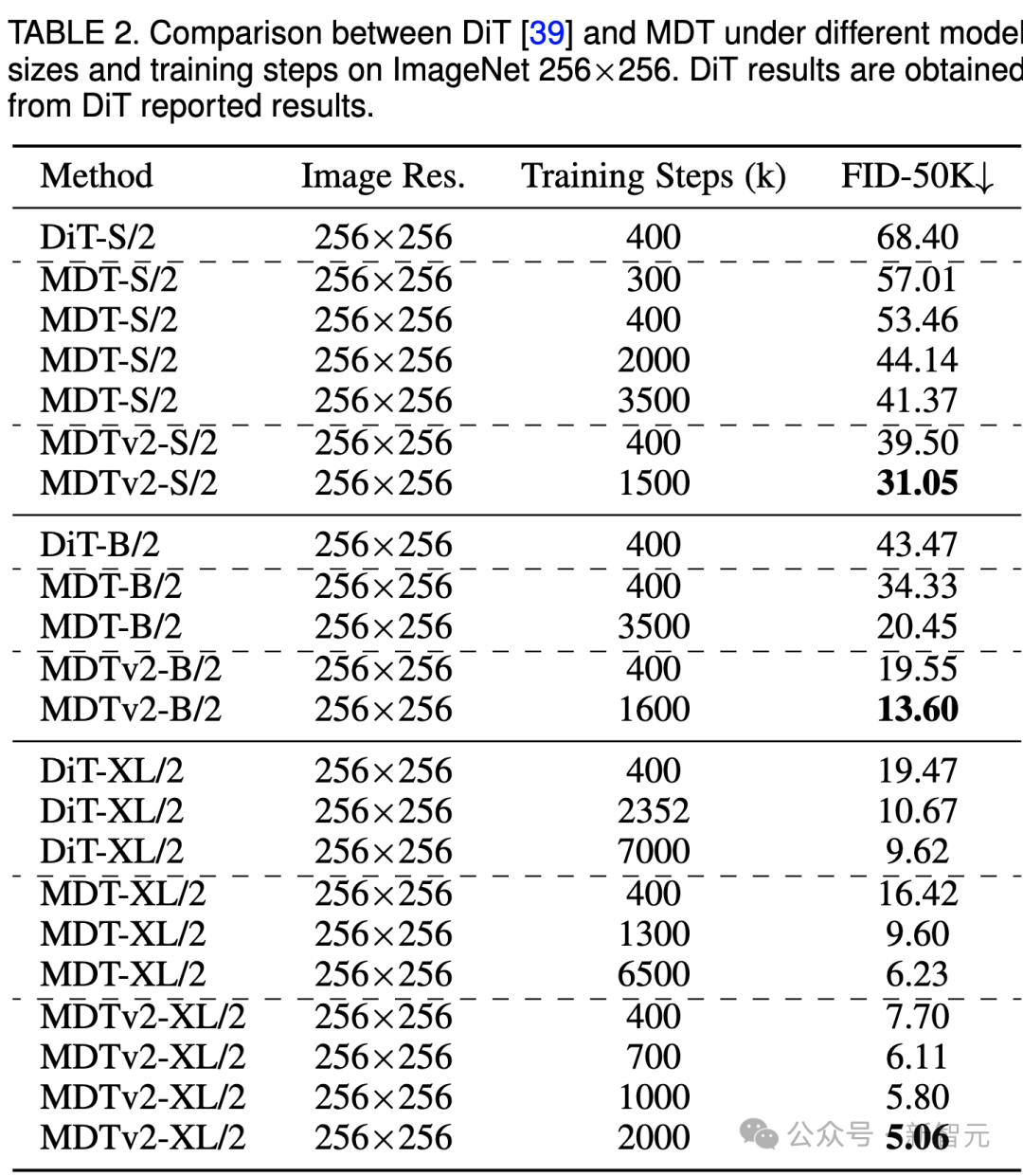 #上の表は、ImageNet 256 ベンチマークにおけるさまざまなモデル サイズでの MDT と DiT のパフォーマンスを比較しています。
#上の表は、ImageNet 256 ベンチマークにおけるさまざまなモデル サイズでの MDT と DiT のパフォーマンスを比較しています。
小規模モデルの場合、MDTv2-S/2 は、大幅に少ないトレーニング ステップで、DiT-S/2 よりも大幅に優れたパフォーマンスを実現します。たとえば、400k ステップの同じトレーニングでは、MDTv2 の FID インデックスは 39.50 で、これは DiT の FID インデックス 68.40 を大幅に上回っています。
さらに重要なのは、この結果は、400k トレーニング ステップでのより大きなモデル DiT-B/2 のパフォーマンスも上回っていることです (39.50 対 43.47)。
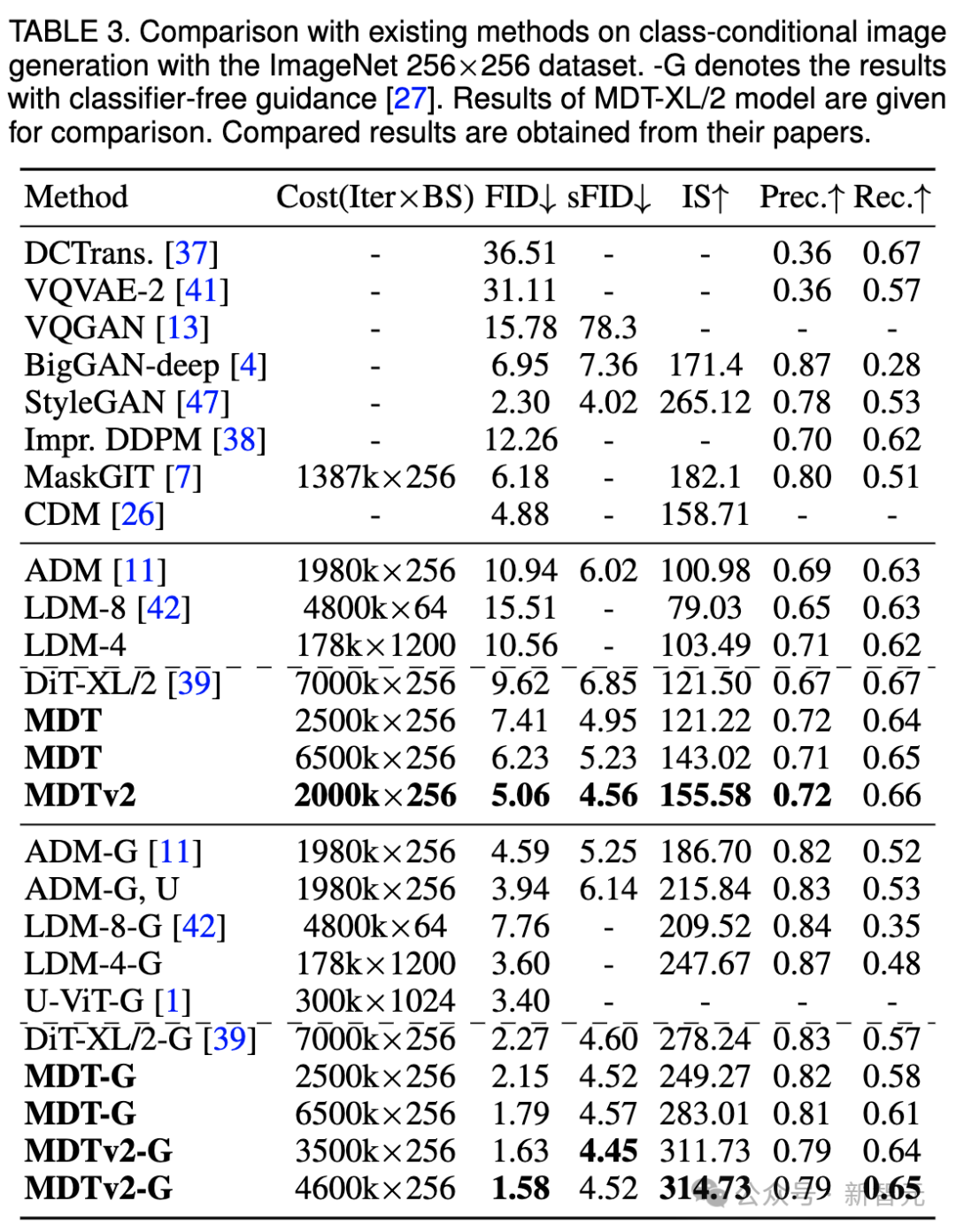
ImageNet 256 ベンチマーク CFG 生成の品質比較
 Image
Image
我々はまだ上の表は、分類子を使用しないガイダンスの下で、MDT と既存の方法の画像生成パフォーマンスを比較しています。
MDT は、FID スコア 1.79 で、以前の SOTA DiT や他の手法を上回ります。 MDTv2 はパフォーマンスをさらに向上させ、少ないトレーニング ステップで画像生成の SOTA FID スコアを新たな最低値の 1.58 に押し上げます。
DiT と同様に、トレーニングを継続しても、トレーニング中にモデルの FID スコアの飽和は観察されませんでした。
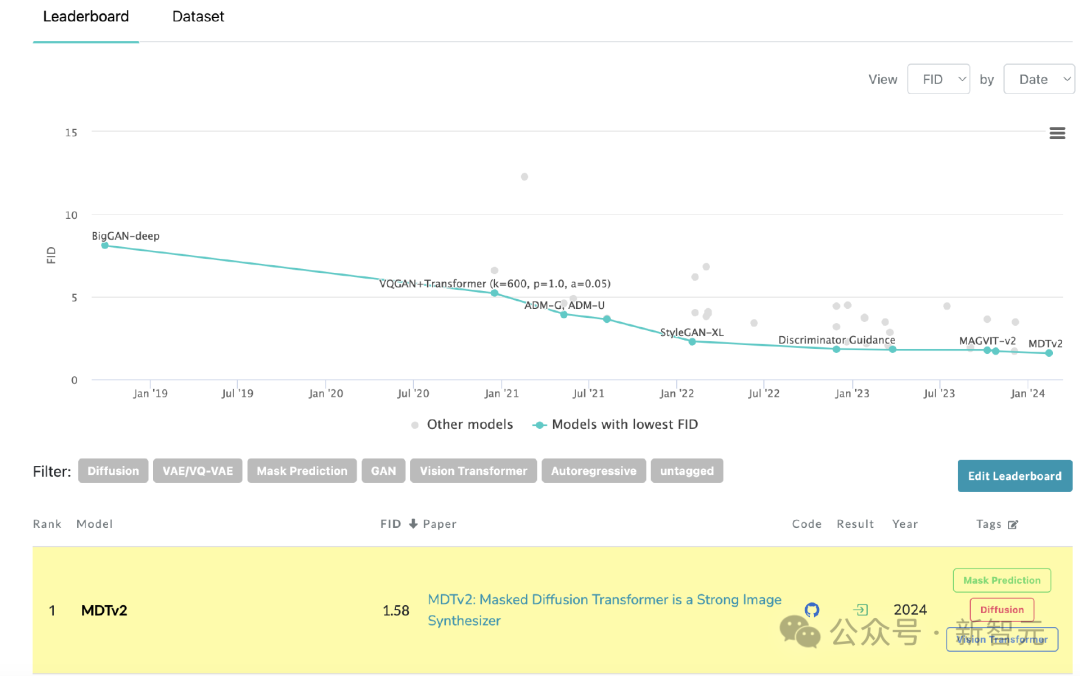 #MDT が PaperWithCode のリーダーボードで SoTA を更新
#MDT が PaperWithCode のリーダーボードで SoTA を更新
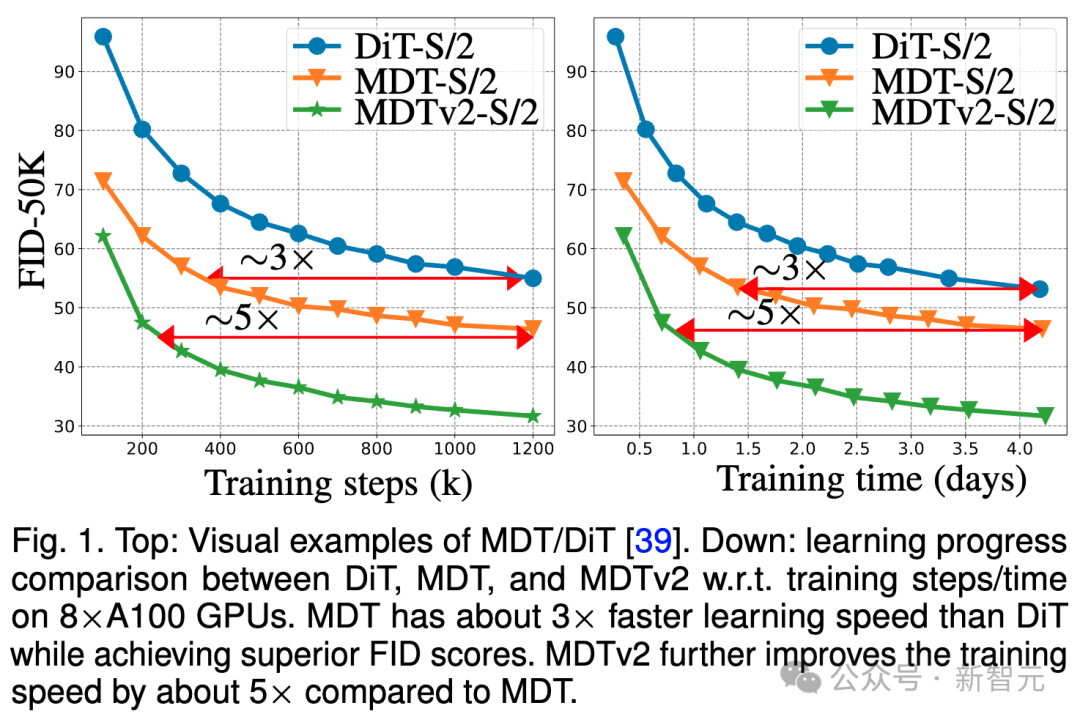 図
図
以上がヤン・シュイチェン/チェン・ミンミンの新作! Sora のコアコンポーネントである DiT トレーニングは 10 倍高速化され、Masked Diffusion Transformer V2 はオープンソースですの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 joiplayシミュレーターの使い方を紹介
May 04, 2024 pm 06:40 PM
joiplayシミュレーターの使い方を紹介
May 04, 2024 pm 06:40 PM
jojplay シミュレータは、非常に使いやすい携帯電話シミュレータです。携帯電話で実行できるコンピュータ ゲームをサポートしており、一部のプレイヤーはその使い方を知りません。以下のエディタでその使い方を紹介します。 。 Joiplay シミュレーターの使用方法 1. まず、Joiplay 本体と RPGM プラグインをダウンロードする必要があります。本体、プラグインの順にインストールするのが最適です。apk パッケージは、Joiplay バー (クリック) で入手できます。 >>>)を取得します。 2. Android が完成したら、左下隅にゲームを追加できます。 3. 適当に名前を入力し、実行ファイルの選択を押してゲームの game.exe ファイルを選択します。 4. アイコンは空白のままにすることも、お気に入りの画像を選択することもできます。
 MSIマザーボードでvtを有効にする方法
May 01, 2024 am 09:28 AM
MSIマザーボードでvtを有効にする方法
May 01, 2024 am 09:28 AM
MSI マザーボードで VT を有効にするにはどうすればよいですか?どのような方法がありますか?このサイトは、大多数のユーザー向けに MSI マザーボード VT 有効化方法を注意深くまとめています。読んで共有することを歓迎します。最初のステップは、コンピューターを再起動して BIOS に入ることであり、起動速度が速すぎて BIOS に入ることができない場合はどうすればよいですか?画面が点灯したら、「Del」を押し続けて BIOS ページに入ります。2 番目のステップは、コンピューターのモデルによって BIOS インターフェイスと VT の名前が異なります。 : 1. BIOS ページに入ったら、「OC (またはオーバークロック)」-「CPU 機能」-「SVMMode (または Intel Virtualization Technology)」オプションを見つけて、「無効」に変更します。
 ASRock マザーボードで vt を有効にする方法
May 01, 2024 am 08:49 AM
ASRock マザーボードで vt を有効にする方法
May 01, 2024 am 08:49 AM
ASRock マザーボードで VT を有効にする方法、その方法と操作方法は何ですか。この Web サイトでは、ユーザーが読んで共有できるように ASRock マザーボード vt 有効化方法をまとめました。最初のステップは、画面が点灯した後、「F2」キーを押し続けて BIOS ページに入ります。起動速度が速すぎて BIOS に入ることができない場合はどうすればよいですか? 2 番目のステップは、メニューで VT オプションを見つけてオンにすることです。マザーボードのモデルによって BIOS インターフェイスと VT の名前が異なります。1. BIOS ページに入ったら、[詳細] - [CPU 構成 (CPU)] を見つけます。構成)」 - 「SVMMOD (仮想化テクノロジ)」オプションで、「無効」を「有効」に変更します。
 よりスムーズなおすすめの Android エミュレータ (使用したい Android エミュレータを選択してください)
Apr 21, 2024 pm 06:01 PM
よりスムーズなおすすめの Android エミュレータ (使用したい Android エミュレータを選択してください)
Apr 21, 2024 pm 06:01 PM
ユーザーにより良いゲーム体験と使用体験を提供できます Android エミュレータは、コンピュータ上で Android システムの実行をシミュレートできるソフトウェアです。市場にはさまざまな種類の Android エミュレータがあり、その品質も異なります。読者が自分に合ったエミュレータを選択できるように、この記事ではいくつかのスムーズで使いやすい Android エミュレータに焦点を当てます。 1. BlueStacks: 高速な実行速度 優れた実行速度とスムーズなユーザー エクスペリエンスを備えた BlueStacks は、人気のある Android エミュレーターです。ユーザーがさまざまなモバイル ゲームやアプリケーションをプレイできるようにし、非常に高いパフォーマンスでコンピュータ上で Android システムをシミュレートできます。 2. NoxPlayer: 複数のオープニングをサポートし、ゲームをより楽しくプレイできます。複数のエミュレーターで同時に異なるゲームを実行できます。
 タブレットコンピュータにWindowsシステムをインストールする方法
May 03, 2024 pm 01:04 PM
タブレットコンピュータにWindowsシステムをインストールする方法
May 03, 2024 pm 01:04 PM
BBK タブレットで Windows システムをフラッシュするにはどうすればよいですか? 最初の方法は、システムをハードディスクにインストールすることです。コンピュータ システムがクラッシュしない限り、システムに入ってダウンロードしたり、コンピュータのハード ドライブを使用してシステムをインストールしたりできます。方法は次のとおりです。 コンピュータの構成に応じて、WIN7 オペレーティング システムをインストールできます。 Xiaobaiのワンクリック再インストールシステムをvivopadにダウンロードしてインストールすることを選択します。まず、お使いのコンピュータに適したシステムバージョンを選択し、「このシステムをインストールする」をクリックして次のステップに進みます。次に、インストール リソースがダウンロードされるまで辛抱強く待ち、環境がデプロイされて再起動されるまで待ちます。 vivopad に win11 をインストールする手順は次のとおりです。まず、ソフトウェアを使用して win11 がインストールできるかどうかを確認します。システム検出に合格したら、システム設定を入力します。そこで「更新とセキュリティ」オプションを選択します。クリック
 ライフ リスタート シミュレーター ガイド
May 07, 2024 pm 05:28 PM
ライフ リスタート シミュレーター ガイド
May 07, 2024 pm 05:28 PM
Life Restart Simulator は非常に興味深いシミュレーション ゲームです。このゲームにはさまざまな方法があります。以下に、Life Restart Simulator の完全なガイドを示します。戦略はあるのか?ライフ リスタート シミュレーター ガイド ガイド ライフ リスタート シミュレーターの特徴 プレイヤーが自由な発想で遊べる、非常にクリエイティブなゲームです。毎日完了すべきタスクがたくさんあり、この仮想世界で新しい生活を楽しむことができます。ゲーム内にはたくさんの曲があり、さまざまな人生があなたを待っています。ライフ リスタート シミュレーター ゲーム内容 才能カード抽選: 才能: 不滅になるためには、神秘的な小箱を選択する必要があります。途中で死んでしまうことを避けるために、さまざまな小さなカプセルが用意されています。クトゥルフは選ぶかもしれない
 Telnetコマンドを開く方法
Apr 17, 2024 am 04:48 AM
Telnetコマンドを開く方法
Apr 17, 2024 am 04:48 AM
コマンド ラインまたは他のソフトウェア (PuTTY、Putty for Android、iTerm2 など) を使用して Telnet コマンドを開くことができます。コマンド ラインで「telnet」と入力し、Enter キーを押して開き、「telnet [ホスト名または IP アドレス] [ポート]」を使用してリモート デバイスに接続します。接続に成功すると、リモートのコマンド プロンプトが表示されます。デバイス。
 pycharmをapkにパッケージ化する方法
Apr 18, 2024 am 05:57 AM
pycharmをapkにパッケージ化する方法
Apr 18, 2024 am 05:57 AM
PyCharm を使用して Android アプリを APK としてパッケージ化するにはどうすればよいですか?プロジェクトが Android デバイスまたはエミュレータに接続されていることを確認してください。ビルド タイプを構成する: ビルド タイプを追加し、[署名された APK を生成する] にチェックを入れます。ビルド ツールバーの [APK のビルド] をクリックし、ビルド タイプを選択してビルドを開始します。
