

AIに多くの物理知識を与えるにはどうすればよいでしょうか? EITと北京大学のチームが「ルールの重要性」という概念を提案


編集者 | ScienceAI
ディープ ラーニング モデルは、大量のデータから潜在的な関係を学習できるため、科学研究の分野に大きな影響を与えてきました。ただし、純粋にデータに依存するモデルでは、データへの過度の依存、汎化機能の制限、現実の物理世界との一貫性の問題など、その限界が徐々に明らかになります。これらの問題により、研究者はデータ駆動型モデルの欠点を補うために、より解釈可能で説明可能なモデルを模索するようになりました。したがって、ドメイン知識とデータ駆動型手法を組み合わせて、より解釈可能性と一般化機能を備えたモデルを構築することが、現在の科学研究における重要な方向性となっています。この
たとえば、アメリカの企業 OpenAI によって開発されたテキストからビデオへのモデル Sora は、その優れた画像生成機能が高く評価されており、人工知能の分野における重要な進歩と考えられています。 Sora はリアルな画像やビデオを生成できるにもかかわらず、重力や物体の断片化などの物理法則に対処するという点でまだ課題がいくつかあります。 Sora は現実のシナリオのシミュレーションにおいて大幅な進歩を遂げましたが、物理法則の理解と正確なシミュレーションにおいてはまだ改善の余地があります。 AI テクノロジーの開発には、現実世界のさまざまな状況によりよく適応できるようにモデルの包括性と精度を向上させるための継続的な努力が依然として必要です。
この問題を解決する可能性のある方法の 1 つは、人間の知識を深層学習モデルに組み込むことです。事前の知識とデータを組み合わせることでモデルの一般化能力が強化され、物理法則を理解できる「インフォームド機械学習」モデルが実現します。このアプローチにより、モデルのパフォーマンスと精度が向上し、現実世界の複雑な問題にうまく対処できるようになると期待されています。人間の専門家の経験と洞察を機械学習アルゴリズムに統合することで、よりインテリジェントで効率的なシステムを構築でき、それによって人工知能技術の開発と応用を促進できます。
現時点では、ディープラーニングにおける知識の正確な価値についての詳細な調査はまだ不足しています。どのような事前知識を「事前学習」のモデルに効果的に組み込むことができるかを決定することには緊急の問題があります。同時に、複数のルールをやみくもに統合するとモデルの失敗につながる可能性があり、これにも注意が必要です。これらの制限は、データと知識の関係を深く探求する際に課題をもたらします。
この問題に対応して、東方工科大学(EIT)と北京大学の研究チームは「ルールの重要性」という概念を提案し、各ルールが予測に与える影響を正確に計算できるフレームワークを開発しました。モデルの精度に貢献します。このフレームワークは、データと知識の間の複雑な相互作用を明らかにし、知識の埋め込みに関する理論的なガイダンスを提供するだけでなく、トレーニング プロセス中に知識とデータの影響のバランスを取るのにも役立ちます。さらに、この方法は不適切なアプリオリなルールを特定するためにも使用でき、学際的な分野での研究と応用に幅広い展望をもたらします。
「ディープラーニングに対する事前知識の影響」と題されたこの研究は、2024 年 3 月 8 日に Cell Press 傘下の学際ジャーナル「Nexus」に掲載されました。この研究は、AAAS (米国科学振興協会) と EurekAlert! から注目されました。

子供たちにパズルを教えるときは、試行錯誤を通じて答えを見つけさせたり、基本的なルールやテクニックを教えたりすることができます。同様に、物理法則などのルールやテクニックを AI トレーニングに組み込むことで、AI トレーニングをより現実的かつ効率的にすることができます。しかし、人工知能におけるこれらのルールの価値をどのように評価するかは、常に研究者を悩ませてきた問題です。
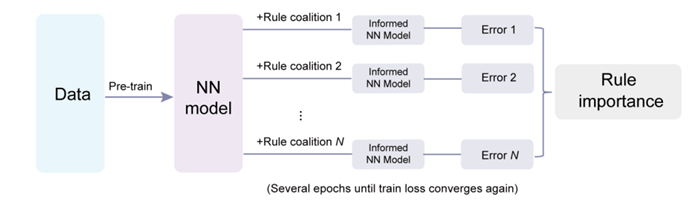
事前知識の多様性が豊富であることを考慮すると、事前知識を深層学習モデルに統合することは、複雑な多目的最適化タスクです。研究チームは、深層学習モデルの改善におけるさまざまな事前知識の役割を定量化するフレームワークを革新的に提案しています。彼らはこのプロセスを協力と競争に満ちたゲームと見なし、モデル予測へのわずかな貢献を評価することでルールの重要性を定義します。まず、考えられるすべてのルールの組み合わせ (つまり、「連合」) が生成され、各組み合わせに対してモデルが構築され、平均二乗誤差が計算されます。
計算コストを削減するために、彼らは摂動に基づく効率的なアルゴリズムを採用しました。まず完全にデータベースのニューラル ネットワークをベースライン モデルとしてトレーニングし、次に追加のトレーニングのために各ルールの組み合わせを 1 つずつ追加します。最後にテストデータでモデルのパフォーマンスを評価します。ルールがある場合とない場合のすべての連合におけるモデルのパフォーマンスを比較することで、そのルールの限界寄与度、つまりルールの重要性を計算できます。
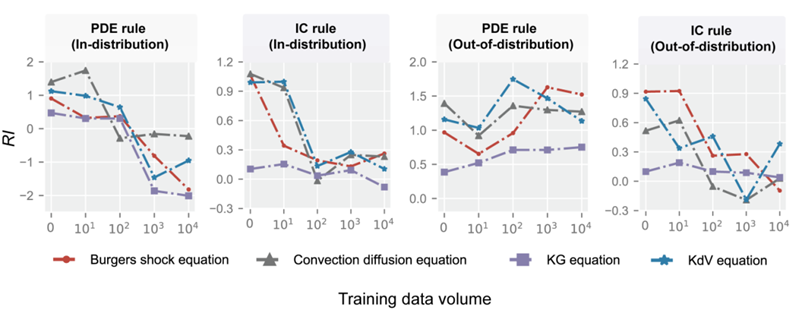
研究者は、流体力学の例を通じて、データとルールの間の複雑な関係を調査しました。彼らは、データと以前のルールが異なるタスクでまったく異なる役割を果たすことを発見しました。テストデータとトレーニングデータの分布が類似している場合(つまり、分散内)、データ量の増加によりルールの効果が弱まります。
ただし、テストデータとトレーニングデータの分布の類似性が低い場合(分布外)には、グローバルルールの重要性が強調され、ローカルルールの影響が弱まります。これら 2 種類のルールの違いは、グローバル ルール (支配方程式など) はドメイン全体に影響を与えるのに対し、ローカル ルール (境界条件など) は特定の領域にのみ作用することです。
研究チームは数値実験を通じて、知識における次のことを発見しました。 embedding では、ルール間の相互作用効果には、依存効果、相乗効果、代替効果の 3 種類があります。
依存効果は、一部のルールが有効であるために他のルールに依存する必要があることを意味します。相乗効果は、複数のルールが連携して動作する効果が、それぞれの独立した効果の合計を超えることを示します。置換効果は、ルールの機能を示します。データまたは他のルール置換の影響を受ける可能性があります。
これら 3 つの効果は同時に存在し、データ量の影響を受けます。ルールの重要度を計算することで、これらの効果を明確に実証でき、知識の埋め込みに重要な指針を提供します。
研究チームは、アプリケーション レベルで、知識埋め込みプロセスの中核問題、つまりデータとルールの役割のバランスをとり、埋め込み効率を向上させ、不適切な事前知識を排除する方法を解決しようとしました。モデルのトレーニング プロセス中に、チームはルールの重みを動的に調整する戦略を提案しました。
具体的には、トレーニングの反復ステップが増加するにつれて、正の重要性ルールの重みが徐々に増加し、負の重要性ルールの重みが減少します。この戦略では、最適化プロセスのニーズに応じて、さまざまなルールに対するモデルの注意をリアルタイムで調整できるため、より効率的で正確な知識の埋め込みが実現します。
さらに、AI モデルに物理法則を教えることで、AI モデルが「現実世界との関連性が高まり、科学や工学においてより大きな役割を果たす」ことができます。したがって、このフレームワークは、工学、物理学、化学の分野で広範囲に実際に応用できます。研究者らは、多変量方程式を解くために機械学習モデルを最適化しただけでなく、薄層クロマトグラフィー分析の予測モデルのパフォーマンスを向上させるルールを正確に特定しました。
実験結果は、これらの効果的なルールを組み込むことによってモデルのパフォーマンスが大幅に向上し、テスト データセットの平均二乗誤差が 0.052 から 0.036 に減少する (30.8% の減少) ことを示しています。これは、フレームワークが経験的な洞察を構造化された知識に変換できることを意味し、それによってモデルのパフォーマンスが大幅に向上します。
全体として、知識の価値を正確に評価することは、より現実的な AI モデルを構築し、安全性と信頼性を向上させるのに役立ちます。これはディープラーニングの開発にとって非常に重要です。

次に、研究チームはフレームワークをプラグイン ツールに開発する予定です。人工知能の開発者。彼らの最終的な目標は、データから知識とルールを直接抽出して自らを改善できるモデルを開発し、それによって知識の発見から知識の埋め込みまでの閉ループ システムを作成し、モデルを真の人工知能科学者にすることです。
論文リンク: https://www.cell.com/nexus/fulltext/S2950-1601(24)00001-9
以上がAIに多くの物理知識を与えるにはどうすればよいでしょうか? EITと北京大学のチームが「ルールの重要性」という概念を提案の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7643
7643
 15
1392
52
91
11
33
151
15
1392
52
91
11
33
151

 「Defect Spectrum」は、従来の欠陥検出の限界を打ち破り、超高精度かつ豊富なセマンティックな産業用欠陥検出を初めて実現します。
Jul 26, 2024 pm 05:38 PM
「Defect Spectrum」は、従来の欠陥検出の限界を打ち破り、超高精度かつ豊富なセマンティックな産業用欠陥検出を初めて実現します。
Jul 26, 2024 pm 05:38 PM
現代の製造において、正確な欠陥検出は製品の品質を確保するための鍵であるだけでなく、生産効率を向上させるための核心でもあります。ただし、既存の欠陥検出データセットには、実際のアプリケーションに必要な精度や意味論的な豊富さが欠けていることが多く、その結果、モデルが特定の欠陥カテゴリや位置を識別できなくなります。この問題を解決するために、広州香港科技大学と Simou Technology で構成されるトップの研究チームは、産業欠陥に関する詳細かつ意味的に豊富な大規模なアノテーションを提供する「DefectSpectrum」データセットを革新的に開発しました。表 1 に示すように、他の産業データ セットと比較して、「DefectSpectrum」データ セットは最も多くの欠陥注釈 (5438 個の欠陥サンプル) と最も詳細な欠陥分類 (125 個の欠陥カテゴリ) を提供します。
 NVIDIA 対話モデル ChatQA はバージョン 2.0 に進化し、コンテキストの長さは 128K と記載されています
Jul 26, 2024 am 08:40 AM
NVIDIA 対話モデル ChatQA はバージョン 2.0 に進化し、コンテキストの長さは 128K と記載されています
Jul 26, 2024 am 08:40 AM
オープンな LLM コミュニティは百花繚乱の時代です Llama-3-70B-Instruct、QWen2-72B-Instruct、Nemotron-4-340B-Instruct、Mixtral-8x22BInstruct-v0.1 などがご覧いただけます。優秀なパフォーマーモデル。しかし、GPT-4-Turboに代表される独自の大型モデルと比較すると、オープンモデルには依然として多くの分野で大きなギャップがあります。一般的なモデルに加えて、プログラミングと数学用の DeepSeek-Coder-V2 や視覚言語タスク用の InternVL など、主要な領域に特化したいくつかのオープン モデルが開発されています。
 結晶相問題を解決するための数百万の結晶データを使用したトレーニング、深層学習手法 PhAI が Science 誌に掲載
Aug 08, 2024 pm 09:22 PM
結晶相問題を解決するための数百万の結晶データを使用したトレーニング、深層学習手法 PhAI が Science 誌に掲載
Aug 08, 2024 pm 09:22 PM
編集者 |KX 今日に至るまで、単純な金属から大きな膜タンパク質に至るまで、結晶学によって決定される構造の詳細と精度は、他のどの方法にも匹敵しません。しかし、最大の課題、いわゆる位相問題は、実験的に決定された振幅から位相情報を取得することのままです。デンマークのコペンハーゲン大学の研究者らは、結晶相の問題を解決するための PhAI と呼ばれる深層学習手法を開発しました。数百万の人工結晶構造とそれに対応する合成回折データを使用して訓練された深層学習ニューラル ネットワークは、正確な電子密度マップを生成できます。この研究では、この深層学習ベースの非経験的構造解法は、従来の非経験的計算法とは異なり、わずか 2 オングストロームの解像度で位相問題を解決できることが示されています。これは、原子解像度で利用可能なデータのわずか 10% ~ 20% に相当します。
 Google AI が IMO 数学オリンピック銀メダルを獲得、数理推論モデル AlphaProof が発売、強化学習が復活
Jul 26, 2024 pm 02:40 PM
Google AI が IMO 数学オリンピック銀メダルを獲得、数理推論モデル AlphaProof が発売、強化学習が復活
Jul 26, 2024 pm 02:40 PM
AI にとって、数学オリンピックはもはや問題ではありません。木曜日、Google DeepMind の人工知能は、AI を使用して今年の国際数学オリンピック IMO の本当の問題を解決するという偉業を達成し、金メダル獲得まであと一歩のところまで迫りました。先週終了したばかりの IMO コンテストでは、代数、組合せ論、幾何学、数論を含む 6 つの問題が出題されました。 Googleが提案したハイブリッドAIシステムは4問正解で28点を獲得し、銀メダルレベルに達した。今月初め、UCLA 終身教授のテレンス・タオ氏が、100 万ドルの賞金をかけて AI 数学オリンピック (AIMO Progress Award) を宣伝したばかりだったが、予想外なことに、AI の問題解決のレベルは 7 月以前にこのレベルまで向上していた。 IMO に関する質問を同時に行うのが最も難しいのは、最も歴史が長く、規模が最も大きく、最も否定的な IMO です。
 自然の視点: 医療における人工知能のテストは混乱に陥っています。何をすべきでしょうか?
Aug 22, 2024 pm 04:37 PM
自然の視点: 医療における人工知能のテストは混乱に陥っています。何をすべきでしょうか?
Aug 22, 2024 pm 04:37 PM
編集者 | ScienceAI 限られた臨床データに基づいて、何百もの医療アルゴリズムが承認されています。科学者たちは、誰がツールをテストすべきか、そしてどのようにテストするのが最善かについて議論しています。デビン シン氏は、救急治療室で小児患者が治療を長時間待っている間に心停止に陥るのを目撃し、待ち時間を短縮するための AI の応用を模索するようになりました。 SickKids 緊急治療室からのトリアージ データを使用して、Singh 氏らは潜在的な診断を提供し、検査を推奨する一連の AI モデルを構築しました。ある研究では、これらのモデルにより医師の診察が 22.3% 短縮され、医療検査が必要な患者 1 人あたりの結果の処理が 3 時間近く高速化できることが示されました。ただし、研究における人工知能アルゴリズムの成功は、これを証明するだけです。
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 PRO | なぜ MoE に基づく大規模モデルがより注目に値するのでしょうか?
Aug 07, 2024 pm 07:08 PM
PRO | なぜ MoE に基づく大規模モデルがより注目に値するのでしょうか?
Aug 07, 2024 pm 07:08 PM
2023 年には、AI のほぼすべての分野が前例のない速度で進化しています。同時に、AI は身体化されたインテリジェンスや自動運転などの主要な分野の技術的限界を押し広げています。マルチモーダルの流れのもと、AI大型モデルの主流アーキテクチャとしてのTransformerの状況は揺るがされるだろうか? MoE (専門家混合) アーキテクチャに基づく大規模モデルの検討が業界の新しいトレンドになっているのはなぜですか?ラージ ビジョン モデル (LVM) は、一般的な視覚における新たなブレークスルーとなる可能性がありますか? ...過去 6 か月間にリリースされたこのサイトの 2023 PRO メンバー ニュースレターから、上記の分野の技術トレンドと業界の変化を詳細に分析し、新しい分野での目標を達成するのに役立つ 10 の特別な解釈を選択しました。準備してください。この解釈は 2023 年の Week50 からのものです
 Transformer に基づく浙江大学の化学逆合成予測モデルは、Nature サブジャーナルで 60.8% に達しました。
Aug 06, 2024 pm 07:34 PM
Transformer に基づく浙江大学の化学逆合成予測モデルは、Nature サブジャーナルで 60.8% に達しました。
Aug 06, 2024 pm 07:34 PM
編集者 | KX 逆合成は創薬や有機合成において重要なタスクであり、そのプロセスを高速化するために AI の使用が増えています。既存の AI 手法はパフォーマンスが不十分で、多様性が限られています。実際には、化学反応は多くの場合、反応物と生成物の間にかなりの重複を伴う局所的な分子変化を引き起こします。これに触発されて、浙江大学のHou Tingjun氏のチームは、単一ステップの逆合成予測を分子列編集タスクとして再定義し、標的分子列を反復的に改良して前駆体化合物を生成することを提案した。そして、高品質かつ多様な予測を実現できる編集ベースの逆合成モデルEditRetroを提案する。広範な実験により、このモデルが標準ベンチマーク データ セット USPTO-50 K で優れたパフォーマンスを達成し、トップ 1 の精度が 60.8% であることが示されました。
