


Meta は最近、次期 Llama 3 を含む次世代の生成 AI モデルのトレーニングをサポートする 2 つの強力な GPU クラスターを発表しました。
どちらのデータセンターも最大 24,576 個の GPU を搭載しており、以前にリリースされたものよりも大規模で複雑な生成 AI モデルをサポートするように設計されていると報告されています。
人気のオープンソース アルゴリズム モデルとして、Meta の Llama は OpenAI の GPT や Google の Gemini に匹敵します。
Geek.com によると、これら 2 つの GPU クラスターには、Meta が以前に発表した大規模クラスターよりも大きい、NVIDIA の最も強力な H100 GPU が搭載されています。 。以前、Meta のクラスターには約 16,000 個の Nvidia A100 GPU がありました。
レポートによると、Meta は数万台の Nvidia の最新 GPU を購入しました。市場調査会社オムディアは最新のレポートで、メタ社がエヌビディア社の最も重要な顧客の一つになったと指摘した。
Meta エンジニアは、新しい GPU クラスターを使用して既存の AI システムを微調整し、Llama 3 を含む、より新しく強力な AI システムをトレーニングする計画であると発表しました。
エンジニアは、Llama 3の開発が現在「進行中」であると指摘したが、いつリリースされるかは明らかにしなかった。
Meta の長期的な目標は、汎用人工知能 (AGI) システムを開発することです。AGI は創造性の点で人間に近く、既存の生成 AI モデルとは大きく異なるためです。
新しい GPU クラスターは、Meta がこれらの目標を達成するのに役立ちます。さらに、同社はより多くの GPU をサポートするために PyTorch AI フレームワークを改善しています。
2 つのクラスターはまったく同じ数の GPU を備えており、400 GB/秒のエンドポイントで相互に接続できますが、さまざまなアーキテクチャ。
その中で、GPU クラスターは、Wedge400 および Minipack2 OCP ラック スイッチを備えた Arista Networks の Arista 7800 を使用して構築されたコンバージド イーサネット ネットワーク ファブリックを介して、ダイレクト メモリまたは RDMA にリモート アクセスできます。もう 1 つの GPU クラスターは、Nvidia の Quantum2 InfiniBand ネットワーク ファブリック テクノロジーを使用して構築されています。
両方のクラスターは、大規模な AI ワークロードをサポートするように設計された Meta のオープン GPU ハードウェア プラットフォームである Grand Teton を使用します。 Grand Teton は、前世代の Zion-EX プラットフォームに比べてホストから GPU までの帯域幅が 4 倍、Zion-EX の 2 倍のコンピューティング能力、帯域幅、パワーを提供します。
Meta 氏によると、2 つのクラスターには、データセンター設計の柔軟性を高めるために設計された最新のオープン ラック電源とラック インフラストラクチャが搭載されています。 Open Rack v3 を使用すると、パワー ラックをバスバーに固定するのではなく、ラック内のどこにでも取り付けることができるため、より柔軟な構成が可能になります。
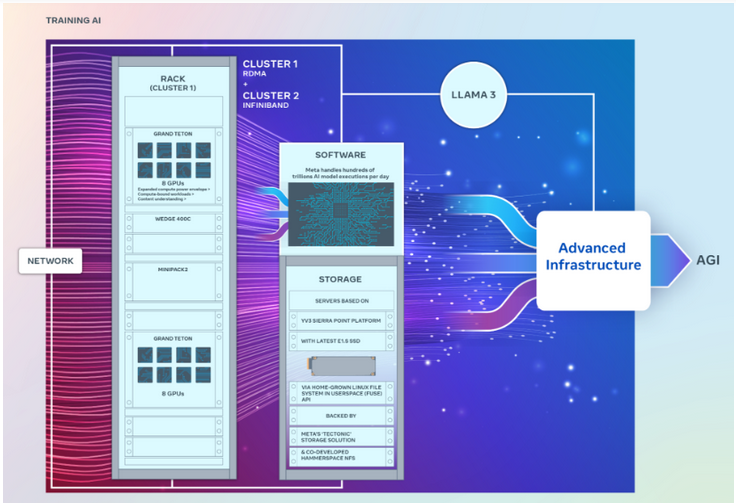
さらに、ラックあたりのサーバーの数はカスタマイズ可能であり、各サーバーのスループット容量をより効率的にバランスさせることができます。
ストレージに関しては、これら 2 つの GPU クラスターは YV3 Sierra Point サーバー プラットフォームに基づいており、最先端の E1.S ソリッド ステート ドライブを使用しています。
メタ エンジニアは記事の中で、同社が AI ハードウェア スタックのオープン イノベーションに取り組んでいることを強調しました。 「将来に目を向けると、以前または現在機能していたものでは将来のニーズを満たすには不十分である可能性があることを認識しています。そのため、私たちはインフラストラクチャを常に評価し、改善しています。」
Meta は最近設立された AI A です。同盟のメンバー。この提携は、AI 開発における透明性と信頼性を高め、誰もがそのイノベーションの恩恵を受けられるようにするオープンなエコシステムを構築することを目指しています。
Meta は、引き続き Nvidia H100 GPU を購入し続け、今年末までに 350,000 個以上の GPU を導入する予定であることも明らかにしました。これらの GPU は、AI インフラストラクチャの構築を継続するために使用されます。これは、将来的にはさらに強力な GPU クラスターが利用可能になることを意味します。
以上がMeta は、2 つの新しい 10,000 カード クラスターを追加し、約 50,000 個の Nvidia H100 GPU を投資しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



