

LoRA コードを最初から作成する方法、チュートリアルはこちら

LoRA (低ランク適応) は、大規模言語モデル (LLM) を微調整するために設計された一般的な手法です。このテクノロジはもともと Microsoft の研究者によって提案され、論文「LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS」に含まれていました。 LoRA は、ニューラル ネットワークのすべてのパラメーターを調整するのではなく、少数の低ランク行列の更新に重点を置き、モデルのトレーニングに必要な計算量を大幅に削減するという点で他の手法と異なります。
LoRA の微調整品質はフルモデルの微調整に匹敵するため、多くの人がこの方法を微調整アーティファクトと呼んでいます。そのリリース以来、多くの人がこのテクノロジーに興味を持ち、研究をより深く理解するためにコードを作成したいと考えてきました。これまでは、適切なドキュメントが存在しないことが問題でしたが、現在は役立つチュートリアルが用意されています。
このチュートリアルの著者は、機械学習と AI の著名な研究者である Sebastian Raschka 氏で、さまざまな効果的な LLM 微調整手法の中で、依然として LoRA が第一の選択肢であると述べています。この目的のために、Sebastian は LoRA をゼロから構築するブログ「Code LoRA From Scratch」を書きました。
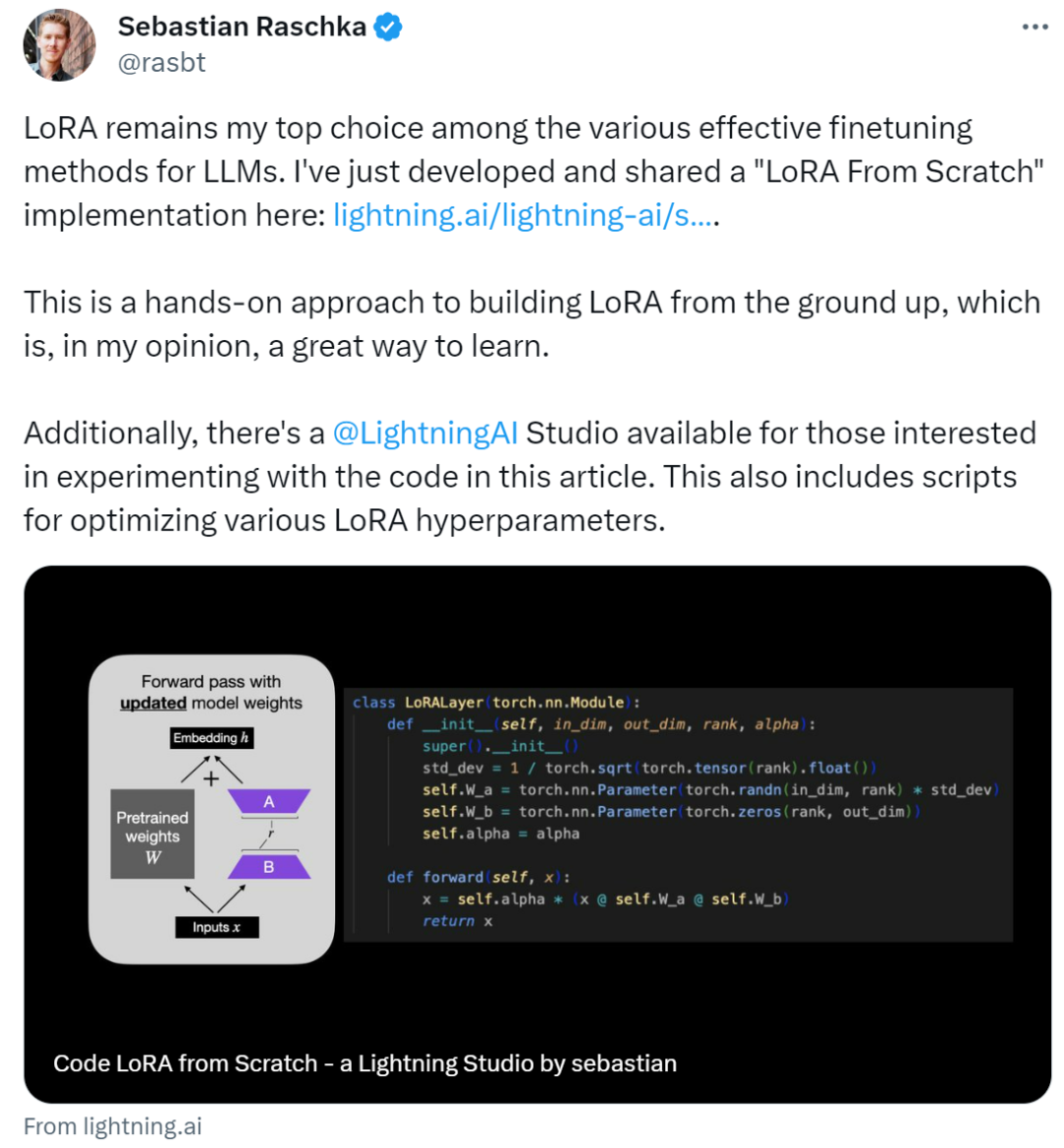
この記事では、コードを最初から作成して低ランク適応 (LoRA) を紹介します。Sebastian は実験で DistilBERT モデルを微調整して使用しました。分類タスクに適用されます。
LoRA 手法と従来の微調整手法の比較結果は、LoRA 手法が 92.39% のテスト精度を達成し、最後の数層のみを微調整するよりも優れていることを示しています。モデルの (テスト精度の 86.22%) は、より優れたパフォーマンスを示しています。これは、LoRA 手法にはモデルのパフォーマンスの最適化において明らかな利点があり、モデルの汎化能力と予測精度をより向上させることができることを示しています。この結果は、より良いパフォーマンスと結果を得るために、モデルのトレーニングとチューニング中に高度な技術と方法を採用することの重要性を強調しています。
#セバスチャンがそれを達成する方法を比較することで、私たちは引き続き下を向いていきます。
#LoRA を最初から書く
LoRA レイヤーをコードで表現すると次のようになります:
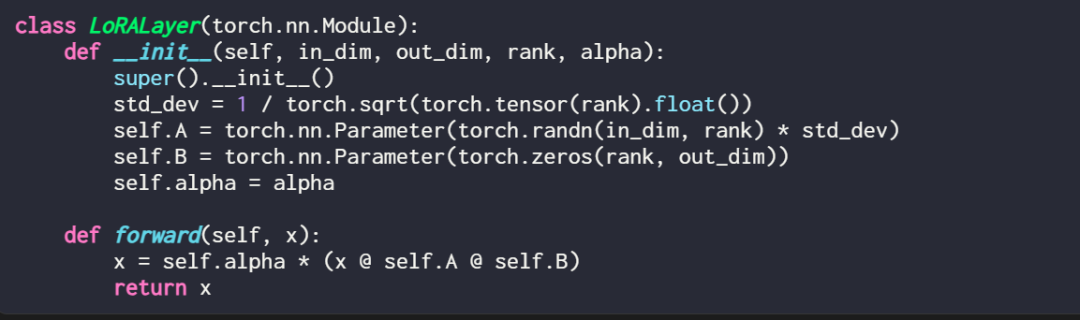
このうち、in_dim は LoRA を使用して変更するレイヤーの入力ディメンションであり、対応する out_dim はレイヤーの出力ディメンションです。ハイパーパラメータ (スケーリング係数アルファ) もコードに追加されます。アルファ値が高いほどモデルの動作が大きく調整されることを意味し、値が低いほどその逆を意味します。さらに、この記事では、行列 A をランダム分布からのより小さい値で初期化し、行列 B をゼロで初期化します。
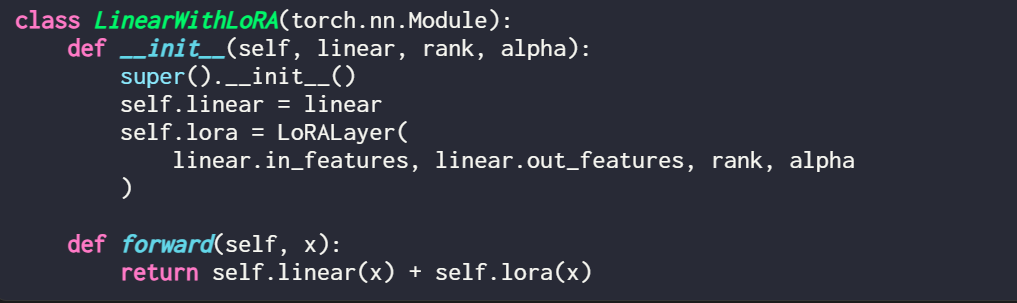
LoRA が関与するのは通常、ニューラル ネットワークの線形 (フィードフォワード) 層であることは言及する価値があります。たとえば、2 つの線形層を持つ単純な PyTorch モデルまたはモジュール (たとえば、これは Transformer ブロックのフィードフォワード モジュールである可能性があります) の場合、forward メソッドは次のように表現できます。

LoRA を使用する場合、通常、LoRA 更新はこれらの線形レイヤーの出力に追加され、コードは次のとおりです。

# #既存の PyTorch モデルを変更して LoRA を実装したい場合、簡単な方法は、各線形レイヤーを LinearWithLoRA レイヤーに置き換えることです。
A上記の概念の概要を以下の図に示します。
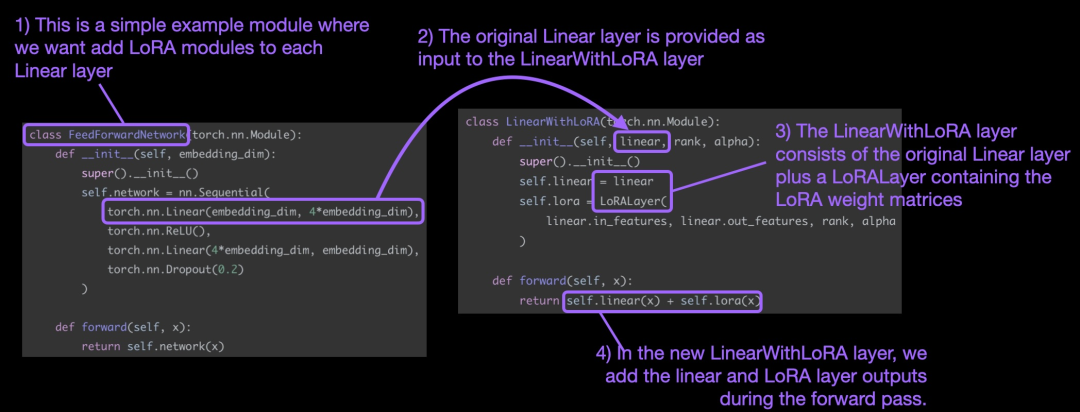
LoRA を適用するために、この記事ではニューラル ネットワーク内の既存の線形層を置き換えます。オリジナルの線形レイヤーと LoRALayer の LinearWithLoRA レイヤーを組み合わせたものです。
LoRA を使用して微調整を開始する方法
LoRA は、GPT や画像生成などのモデルに使用できます。説明を簡単にするために、この記事ではテキスト分類に小規模な BERT (DistilBERT) モデルを使用します。

 ##次に、print (model) を使用してモデルの構造を確認します。
##次に、print (model) を使用してモデルの構造を確認します。
出力から、モデルが線形層を含む 6 つのトランス層で構成されていることがわかります。 さらに、モデルには 2 つの線形出力層があります:

次の割り当て関数を定義することで、これらの線形層に対して LoRA を選択的に有効にすることができます。およびループ:

##
上でわかるように、Linear レイヤーは LinearWithLoRA レイヤーに正常に置き換えられました。
上記のデフォルトのハイパーパラメータを使用してモデルをトレーニングすると、IMDb 映画レビュー分類データセットで次のパフォーマンスが得られます:
- トレーニング精度: 92.15%
- 検証精度: 89.98%
- ##テスト精度: 89.44%
次のセクションでは、このホワイト ペーパーでは、これらの LoRA 微調整結果と従来の微調整結果を比較します。
従来の微調整方法との比較
前のセクションでは、LoRA はデフォルト設定で 89.44% のテスト精度を達成しました。これは従来の微調整方法と比較しますか?
比較のために、この記事では DistilBERT モデルのトレーニングを例として別の実験を実施しましたが、トレーニング中に更新されたのは最後の 2 層のみでした。研究者らは、すべてのモデルの重みをフリーズし、次に 2 つの線形出力層をフリーズ解除することでこれを達成しました。
最後の 2 つの層のみをトレーニングすることで得られる分類パフォーマンス
- トレーニング精度: 86.68%
- 検証精度: 87.26%
- テスト精度: 86.22%
結果は、LoRA が最後の 2 つのレイヤーを微調整する従来の方法よりもパフォーマンスが優れていることを示していますが、使用するパラメーターは 4 分の 1 です。すべてのレイヤーを微調整するには、LoRA セットアップの 450 倍のパラメーターを更新する必要がありましたが、テスト精度は 2% しか向上しませんでした。
LoRA 構成の最適化
上記の結果はすべてデフォルト設定で LoRA によって実行され、ハイパーパラメーターは次のとおりです。



- 検証精度: 92.96%
- テスト精度: 92.39%
元のリンク: https://lightning.ai/lightning-ai/studios/code-lora-from-scratch?cnotallow=f5fc72b1f6eeeaf74b648b2aa8aaf8b6
##
以上がLoRA コードを最初から作成する方法、チュートリアルはこちらの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7478
7478
 15
1377
52
77
11
19
33
15
1377
52
77
11
19
33

 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
データベース酸属性の詳細な説明酸属性は、データベーストランザクションの信頼性と一貫性を確保するための一連のルールです。データベースシステムがトランザクションを処理する方法を定義し、システムのクラッシュ、停電、または複数のユーザーの同時アクセスの場合でも、データの整合性と精度を確保します。酸属性の概要原子性:トランザクションは不可分な単位と見なされます。どの部分も失敗し、トランザクション全体がロールバックされ、データベースは変更を保持しません。たとえば、銀行の譲渡が1つのアカウントから控除されているが別のアカウントに増加しない場合、操作全体が取り消されます。 TRANSACTION; updateaccountssetbalance = balance-100wh
 mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
MySQLはJSONデータを返すことができます。 json_extract関数はフィールド値を抽出します。複雑なクエリについては、Where句を使用してJSONデータをフィルタリングすることを検討できますが、そのパフォーマンスへの影響に注意してください。 JSONに対するMySQLのサポートは絶えず増加しており、最新バージョンと機能に注意を払うことをお勧めします。
 マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
sqllimit句:クエリ結果の行数を制御します。 SQLの制限条項は、クエリによって返される行数を制限するために使用されます。これは、大規模なデータセット、パジネートされたディスプレイ、テストデータを処理する場合に非常に便利であり、クエリ効率を効果的に改善することができます。構文の基本的な構文:SelectColumn1、column2、... FromTable_nameLimitnumber_of_rows; number_of_rows:返された行の数を指定します。オフセットの構文:SelectColumn1、column2、... FromTable_nameLimitoffset、number_of_rows; offset:skip
 高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
MySQLデータベースパフォーマンス最適化ガイドリソース集約型アプリケーションでは、MySQLデータベースが重要な役割を果たし、大規模なトランザクションの管理を担当しています。ただし、アプリケーションのスケールが拡大すると、データベースパフォーマンスのボトルネックが制約になることがよくあります。この記事では、一連の効果的なMySQLパフォーマンス最適化戦略を検討して、アプリケーションが高負荷の下で効率的で応答性の高いままであることを保証します。実際のケースを組み合わせて、インデックス作成、クエリ最適化、データベース設計、キャッシュなどの詳細な主要なテクノロジーを説明します。 1.データベースアーキテクチャの設計と最適化されたデータベースアーキテクチャは、MySQLパフォーマンスの最適化の基礎です。いくつかのコア原則は次のとおりです。適切なデータ型を選択し、ニーズを満たす最小のデータ型を選択すると、ストレージスペースを節約するだけでなく、データ処理速度を向上させることもできます。
 Prometheus MySQL ExporterでMySQLおよびMariadb液滴を監視します
Apr 08, 2025 pm 02:42 PM
Prometheus MySQL ExporterでMySQLおよびMariadb液滴を監視します
Apr 08, 2025 pm 02:42 PM
MySQLおよびMariaDBデータベースの効果的な監視は、最適なパフォーマンスを維持し、潜在的なボトルネックを特定し、システム全体の信頼性を確保するために重要です。 Prometheus MySQL Exporterは、プロアクティブな管理とトラブルシューティングに重要なデータベースメトリックに関する詳細な洞察を提供する強力なツールです。
 MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLプライマリキーは、データベース内の各行を一意に識別するキー属性であるため、空にすることはできません。主キーが空になる可能性がある場合、レコードを一意に識別することはできません。これにより、データの混乱が発生します。一次キーとして自己挿入整数列またはUUIDを使用する場合、効率やスペース占有などの要因を考慮し、適切なソリューションを選択する必要があります。
 MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
MongoDBデータベースパスワードを表示するNAVICATの方法
Apr 08, 2025 pm 09:39 PM
Hash値として保存されているため、Navicatを介してMongoDBパスワードを直接表示することは不可能です。紛失したパスワードを取得する方法:1。パスワードのリセット。 2。構成ファイルを確認します(ハッシュ値が含まれる場合があります)。 3.コードを確認します(パスワードをハードコードできます)。
