

Googleが「Vlogger」モデルをリリース:1枚の写真から10秒の動画が生成される

Google は新しいビデオ フレームワークをリリースしました:
必要なのはあなたの写真とスピーチの録音だけです。 私のスピーチの本物のようなビデオ。 ビデオの長さは可変で、現在の例では最大 10 秒です。
口の形にしても表情
にしても、とても自然であることがわかります。 入力画像が上半身全体をカバーしている場合は、豊富なジェスチャと一致させることもできます。:
ネチズンはそれを終えた後、次のように言いました:
これにより、将来的にはオンラインビデオ会議のために髪を整えたり服を着たりする必要がなくなります。 
まあ、ポートレートを撮って音声を録音してください
(手動の犬の頭)音声コントロールを使用します。ビデオの生成
このフレームワークは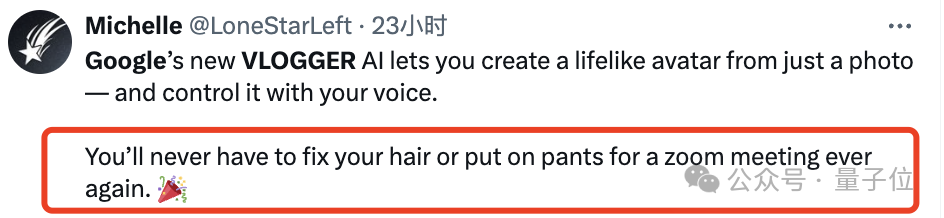 VLOGGER
VLOGGER
と呼ばれます。
これは主に拡散モデルに基づいており、2 つの部分で構成されています。 1 つはランダムな人間から 3D へのモーション (人間から 3D へのモーション) ディフュージョンモデル 。
もう 1 つは、テキストから画像へのモデルを強化するための新しい拡散アーキテクチャです。
このうち、前者はオーディオ波形を入力として使用して、目、表情やジェスチャー、全体的な身体の姿勢などを含むキャラクターの身体制御アクションを生成します。 後者は、大規模な画像拡散モデルを拡張し、予測されたアクションを使用して対応するフレームを生成するために使用される時間次元の画像間モデルです。
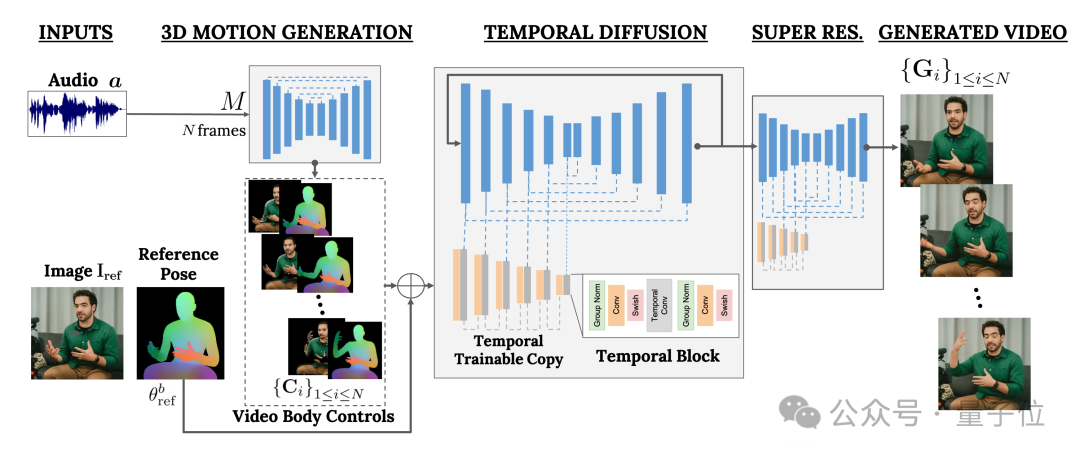 結果を特定のキャラクター画像に適合させるために、VLOGGER はパラメータ画像の姿勢図も入力として受け取ります。
結果を特定のキャラクター画像に適合させるために、VLOGGER はパラメータ画像の姿勢図も入力として受け取ります。
VLOGGER のトレーニングは、非常に大規模なデータセット
(MENTOR という名前)上で完了します。 ######それはどれくらい大きいですか?
全長 2,200 時間、合計 800,000 文字のビデオが含まれています
。 その中で、テスト セットのビデオの長さも 120 時間、合計 4,000 文字です。
Google によると、VLOGGER の最も優れたパフォーマンスはその多様性です。 下の図に示すように、最終的なピクセル画像の色は暗くなります (赤) を表すとアクションが豊かになります。
業界のこれまでの同様の手法と比較した場合、VLOGGER の最大の利点は、各個人のトレーニングが必要なく、顔検出やトリミングに依存しないことです。生成されたビデオは非常に完全です(顔と唇の両方、体の動きを含む) など。

具体的には、次の表に示すとおりです。
顔の再現方法では、オーディオやテキストを使用してビデオ生成を制御することはできません。
Audio-to-motion では、音声を 3D の顔の動きにエンコードすることで音声を生成できますが、生成される効果は十分に現実的ではありません。
リップシンクはさまざまなテーマのビデオを処理できますが、シミュレートできるのは口の動きだけです。
比較すると、後者の 2 つの方法である SadTaker と Styletalk は Google VLOGGER に最も近いパフォーマンスを示しますが、本体を制御したりビデオをさらに編集したりできないという点でも劣っています。

ビデオ編集といえば、下図に示すように、VLOGGER モデルのアプリケーションの 1 つがこれです。ワンクリックで左目を閉じるだけです。または、ずっと目を開けたままにしてください:

#別のアプリケーションはビデオ翻訳です:
たとえば、次のように変更します。元のビデオの英語の音声を、同じ口の形でスペイン語に変換します。
ネチズンからの苦情
ついに、「古いルール」に従って、Googleはモデルをリリースせず、今私たちが目にできるのは、より多くの効果と論文だけです。
そうですね、多くの不満があります:
モデルの画質、口の形が正しくない、依然としてロボットのように見えるなど。
したがって、否定的なレビューを躊躇せずに残す人もいます:
これが Google のレベルですか?

「VLOGGER」という名前がちょっと残念です。

#——OpenAI の Sora と比較すると、このネチズンの発言は確かに不合理ではありません。 。 ######どう思いますか?
#その他の効果:
https://enriccorona.github.io/vlogger/全文:
https://enriccorona.github.io/vlogger/paper.pdf
以上がGoogleが「Vlogger」モデルをリリース:1枚の写真から10秒の動画が生成されるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7489
7489
 15
1377
52
77
11
19
40
15
1377
52
77
11
19
40

 OPPO Phoneで画面ビデオを録画する方法(簡単な操作)
May 07, 2024 pm 06:22 PM
OPPO Phoneで画面ビデオを録画する方法(簡単な操作)
May 07, 2024 pm 06:22 PM
ゲームのスキルや指導のデモンストレーションなど、日常生活では、操作手順を示すために携帯電話を使用して画面ビデオを録画する必要がよくあります。画面録画機能も非常に優れており、OPPO携帯電話は強力なスマートフォンです。録画タスクを簡単かつ迅速に完了できるように、この記事では、OPPO 携帯電話を使用して画面ビデオを録画する方法を詳しく紹介します。準備 - 録音の目標を決定する 開始する前に、録音の目標を明確にする必要があります。ステップバイステップのデモビデオを録画したいですか?それともゲームの素晴らしい瞬間を記録したいですか?それとも教育ビデオを録画したいですか?録音プロセスをより適切に調整し、明確な目標を設定することによってのみ可能です。 OPPO 携帯電話の画面録画機能を開き、ショートカット パネルで見つけます。 画面録画機能はショートカット パネルにあります。
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 Adobe After Effects cs6 (Ae cs6) で言語を切り替える方法 Ae cs6 で中国語と英語を切り替える詳細な手順 - ZOL ダウンロード
May 09, 2024 pm 02:00 PM
Adobe After Effects cs6 (Ae cs6) で言語を切り替える方法 Ae cs6 で中国語と英語を切り替える詳細な手順 - ZOL ダウンロード
May 09, 2024 pm 02:00 PM
1. まず、AMTLanguages フォルダーを見つけます。 AMTLanguages フォルダーにいくつかのドキュメントが見つかりました。簡体字中国語をインストールすると、zh_CN.txt テキスト ドキュメントが作成されます (テキストの内容は zh_CN)。英語でインストールした場合は、テキスト ドキュメント en_US.txt が作成されます (テキストの内容は en_US)。 3. したがって、中国語に切り替えたい場合は、AdobeAfterEffectsCCSupportFilesAMTLanguages パスの下に zh_CN.txt (テキストの内容: zh_CN) の新しいテキストドキュメントを作成する必要があります。 4. 逆に、英語に切り替えたい場合は、
 Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
何?ズートピアは国産AIによって実現するのか?ビデオとともに公開されたのは、「Keling」と呼ばれる新しい大規模な国産ビデオ生成モデルです。 Sora も同様の技術的ルートを使用し、自社開発の技術革新を多数組み合わせて、大きく合理的な動きをするだけでなく、物理世界の特性をシミュレートし、強力な概念的結合能力と想像力を備えたビデオを制作します。データによると、Keling は、最大 1080p の解像度で 30fps で最大 2 分の超長時間ビデオの生成をサポートし、複数のアスペクト比をサポートします。もう 1 つの重要な点は、Keling は研究所が公開したデモやビデオ結果のデモンストレーションではなく、ショートビデオ分野のリーダーである Kuaishou が立ち上げた製品レベルのアプリケーションであるということです。さらに、主な焦点は実用的であり、白紙小切手を書かず、リリースされたらすぐにオンラインに移行することです。Ke Ling の大型モデルは Kuaiying でリリースされました。
 アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
最近、軍事界は、米軍戦闘機が AI を使用して完全自動空戦を完了できるようになったというニュースに圧倒されました。そう、つい最近、米軍のAI戦闘機が初めて公開され、その謎が明らかになりました。この戦闘機の正式名称は可変安定性飛行シミュレーター試験機(VISTA)で、アメリカ空軍長官が自ら飛行させ、一対一の空戦をシミュレートした。 5 月 2 日、フランク ケンダル米国空軍長官は X-62AVISTA でエドワーズ空軍基地を離陸しました。1 時間の飛行中、すべての飛行動作が AI によって自律的に完了されたことに注目してください。ケンダル氏は「過去数十年にわたり、私たちは自律型空対空戦闘の無限の可能性について考えてきたが、それは常に手の届かないものだと思われてきた」と語った。しかし今では、
 OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
ソフトウェア テクノロジの最前線に立つ UIUC Zhang Lingming のグループは、BigCode 組織の研究者とともに、最近 StarCoder2-15B-Instruct 大規模コード モデルを発表しました。この革新的な成果により、コード生成タスクにおいて大きな進歩が達成され、CodeLlama-70B-Instruct を上回り、コード生成パフォーマンス リストのトップに到達しました。 StarCoder2-15B-Instruct のユニークな特徴は、その純粋な自己調整戦略であり、トレーニング プロセス全体がオープンで透過的で、完全に自律的で制御可能です。このモデルは、高価な手動アノテーションに頼ることなく、StarCoder-15B 基本モデルの微調整に応じて、StarCoder2-15B を介して数千の命令を生成します。
 総合的にDPOを超える:Chen Danqi氏のチームはシンプルなプリファレンス最適化SimPOを提案し、最強の8Bオープンソースモデルも洗練させた
Jun 01, 2024 pm 04:41 PM
総合的にDPOを超える:Chen Danqi氏のチームはシンプルなプリファレンス最適化SimPOを提案し、最強の8Bオープンソースモデルも洗練させた
Jun 01, 2024 pm 04:41 PM
大規模言語モデル (LLM) を人間の価値観や意図に合わせるには、人間のフィードバックを学習して、それが有用で、正直で、無害であることを確認することが重要です。 LLM を調整するという点では、ヒューマン フィードバックに基づく強化学習 (RLHF) が効果的な方法です。 RLHF 法の結果は優れていますが、最適化にはいくつかの課題があります。これには、報酬モデルをトレーニングし、その報酬を最大化するためにポリシー モデルを最適化することが含まれます。最近、一部の研究者はより単純なオフライン アルゴリズムを研究しており、その 1 つが直接優先最適化 (DPO) です。 DPO は、RLHF の報酬関数をパラメータ化することで、選好データに基づいてポリシー モデルを直接学習するため、明示的な報酬モデルの必要性がなくなります。この方法は簡単で安定しています
 TikTokで動画を撮影するにはどうすればよいですか?ビデオ撮影時にマイクをオンにするにはどうすればよいですか?
May 09, 2024 pm 02:40 PM
TikTokで動画を撮影するにはどうすればよいですか?ビデオ撮影時にマイクをオンにするにはどうすればよいですか?
May 09, 2024 pm 02:40 PM
現在最も人気のあるショートビデオ プラットフォームの 1 つである Douyin のビデオの品質と効果は、ユーザーの視聴エクスペリエンスに直接影響します。では、TikTokで高品質のビデオを撮影するにはどうすればよいでしょうか? 1.Douyinでビデオを撮影するにはどうすればよいですか? 1. Douyin APPを開き、下部中央の「+」ボタンをクリックしてビデオ撮影ページに入ります。 2. Douyin は、通常撮影、スローモーション、ショートビデオなどのさまざまな撮影モードを提供します。ニーズに応じて適切な撮影モードを選択してください。 3. 撮影ページで、画面下部の「フィルター」ボタンをクリックしてさまざまなフィルター効果を選択し、ビデオをよりカスタマイズします。 4. 露出やコントラストなどのパラメータを調整する必要がある場合は、画面の左下隅にある「パラメータ」ボタンをクリックして設定できます。 5. 撮影中に、画面左側の をクリックします。
