

Python Pandas のスキルを解放し、データ処理ツールをマスターしましょう!


python pandas ライブラリは、Python# 用の強力なデータ操作および分析 ツール ##プログラミング言語は、強力なデータ処理機能を提供します。 Pandas スキルを習得することで、開発者はさまざまな形式のデータを効率的に処理および分析し、その価値をロック解除して、データ主導の意思決定を行うことができます。
インストールとインポート
Pandas の使用を開始するには、まず pip コマンドを使用してインストールする必要があります:pip でパンダをインストールします
パンダを pd としてインポート
######データ構造######
データ構造を使用します:
シリーズ: 1 次元
配列- 、各要素にはラベル (
- index) があります。 DataFrame: 行と列で構成される 2 次元テーブル。行はインデックスによって識別され、列は列名によって識別されます。
- データ構造の作成
CSV ファイルのインポート:
- df = pd.read_csv("data.csv")
- s = pd.Series(["Python", "Pandas", "データ"])
- df = pd.DataFrame({"名前": ["ジョン", "ジェーン"], "年齢": [25, 30]}) データ操作
スライス:
場所またはラベルによってデータを選択します。
- フィルタリング: 条件に基づいてデータを選択します。
- 並べ替え: データ を 1 つ以上のキー で並べ替えます。
- グループ化: データを 1 つ以上のキーでグループ化します。
- マージ: 2 つ以上のデータ構造を結合します。 ######データ分析######
- Pandas は、次のようなさまざまな分析機能も提供します。
平均、中央値、標準偏差などの統計を計算します。
相関分析:変数間の相関を決定します。
- 回帰分析: データ間の線形または非線形関係を確立します。 ######視覚化######
- Pandas は、次のような直感的な 視覚化 機能を提供します。
- 折れ線グラフ: 時系列データを描画します。
散布図: 2 つの変数間の関係を示します。
ヒストグラム: データの分布を表示します。
- 円グラフ:
- カテゴリまたはグループの相対的なサイズを示します。
- パフォーマンスの最適化 Pandas 操作のパフォーマンスを向上させるために、次のテクニックを使用できます:
-
- NumPy バックエンドを使用する: NumPy は、より高速な配列処理機能を提供します。
- ベクトル化操作: ループの代わりに Pandas の組み込みベクトル化関数を使用します。
- マルチスレッドを使用する: 大規模なデータ セットの場合、操作を並行して実行できます。
Python Pandas スキルを習得することは、開発者がデータを効果的に処理および分析し、データを使用して意思決定を行うことができるようにするために重要です。データ構造、データ操作、データ分析、視覚化機能を理解することで、開発者は Pandas データ処理の可能性を最大限に引き出し、データ駆動型アプリケーションのパフォーマンスを向上させることができます。
以上がPython Pandas のスキルを解放し、データ処理ツールをマスターしましょう!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7469
7469
 15
1376
52
77
11
19
29
15
1376
52
77
11
19
29

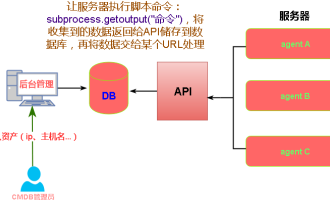 crontab のスケジュールされたタスクが実行されない理由をご存知ですか?
Mar 09, 2024 am 09:49 AM
crontab のスケジュールされたタスクが実行されない理由をご存知ですか?
Mar 09, 2024 am 09:49 AM
crontab のスケジュールされたタスクが実行されない原因まとめ 更新日時: 2019年1月9日 09:34:57 作成者: Hope on the field. この記事では主に、crontab のスケジュールされたタスクが実行されない原因をいくつかまとめて紹介します。考えられるトリガーごとに解決策が示されており、この問題に遭遇した同僚にとって一定の参照と学習価値があります。必要な学生はエディターに従って一緒に学習できます。序文: 最近仕事でいくつかの問題に遭遇しました。crontab のスケジュール設定タスクが実行されませんでした後、インターネットで検索したところ、インターネットでは主に次の 5 つのインセンティブについて言及されていることがわかりました: 1. crond サービスが開始されていない Crontab は Linux カーネルの機能ではなく、cron に依存しています。
 Orange3 の探索: データ マイニングと機械学習の新しい世界を切り開きます!
Mar 04, 2024 pm 08:16 PM
Orange3 の探索: データ マイニングと機械学習の新しい世界を切り開きます!
Mar 04, 2024 pm 08:16 PM
Orange3 は、強力なオープンソース データ視覚化および機械学習ツールであり、豊富なデータ処理、分析、モデリング機能を備えており、ユーザーにシンプルかつ高速なデータ マイニングおよび機械学習ソリューションを提供します。この記事では、Orange3 の基本的な機能と使用法を簡単に紹介し、実際のアプリケーション シナリオや Python コードのケースと組み合わせて、読者が Orange3 の使用スキルをよりよく習得できるようにします。 Orange3 の基本機能には、データのロード、データの前処理、特徴の選択、モデルの確立と評価などが含まれます。ユーザーは直感的なインターフェイスを使用してコンポーネントをドラッグ アンド ドロップし、データ プロセスを簡単に構築できます。同時に、より複雑なデータ処理やモデリングのタスクも Python スクリプトを通じて実行できます。以下、実践的な内容を見ていきます
 python_python の繰り返し文字列チュートリアルで文字列を繰り返す方法
Apr 02, 2024 pm 03:58 PM
python_python の繰り返し文字列チュートリアルで文字列を繰り返す方法
Apr 02, 2024 pm 03:58 PM
1. まず pycharm を開いて、pycharm ホームページに入ります。 2. 次に、新しい Python スクリプトを作成し、右クリックして [新規] をクリックし、[Pythonfile] をクリックします。 3. 文字列、コード: s="-" を入力します。 4. 次に、文字列内のシンボルを 20 回繰り返す必要があります (コード: s1=s*20)。 5. 印刷出力コード、コード: print(s1) を入力します。 6. 最後にスクリプトを実行すると、下部に戻り値が表示されます。 - 20 回繰り返しました。
 pycharmでExcelデータを読み取る方法
Apr 03, 2024 pm 08:42 PM
pycharmでExcelデータを読み取る方法
Apr 03, 2024 pm 08:42 PM
PyCharmを使用してExcelデータを読み取るにはどうすればよいですか?手順は次のとおりです: openpyxl ライブラリのインストール、openpyxl ライブラリのインポート、Excel ワークブックのロード、特定のワークシートへのアクセス、ワークシート内のセルへのアクセス、行と列の走査。
 Python ORM パフォーマンス ベンチマーク: さまざまな ORM フレームワークの比較
Mar 18, 2024 am 09:10 AM
Python ORM パフォーマンス ベンチマーク: さまざまな ORM フレームワークの比較
Mar 18, 2024 am 09:10 AM
オブジェクト リレーショナル マッピング (ORM) フレームワークは、Python 開発において重要な役割を果たします。オブジェクト データベースとリレーショナル データベースの間にブリッジを構築することで、データ アクセスと管理を簡素化します。さまざまな ORM フレームワークのパフォーマンスを評価するために、この記事では次の一般的なフレームワークに対してベンチマークを実行します。 sqlAlchemyPeeweeDjangoORMPonyORMTortoiseORM テスト方法 ベンチマークでは、100 万レコードを含む SQLite データベースを使用します。テストでは、データベースに対して次の操作を実行しました。 挿入: テーブルに 10,000 件の新しいレコードを挿入します。 読み取り: テーブル内のすべてのレコードを読み取ります。 更新: テーブル内のすべてのレコードの 1 つのフィールドを更新します。 削除: テーブル内のすべてのレコードを削除します。 各操作
 Web サイトのサブドメイン クエリ ツールとは何ですか?
Mar 07, 2024 am 09:49 AM
Web サイトのサブドメイン クエリ ツールとは何ですか?
Mar 07, 2024 am 09:49 AM
Web サイトのサブドメイン クエリ ツールには次のものが含まれます: 1. Whois Lookup: サブドメイン名を含むドメイン名の登録情報をクエリできます; 2. Sublist3r: 検索エンジンやその他のツールを利用してドメイン名のサブドメイン名を自動的にスキャンできます; 3 . DNSdumpster: ドメイン名のサブドメイン名、IP アドレス、DNS レコードなどの情報を照会できます; 4. Fierce: DNS サーバーを通じてドメイン名のサブドメイン名情報を照会できます: 5. Nmap; 6. Recon- NG; 7. Google ハッキング。
 ビッグデータ プロジェクトにおける Python ORM の適用
Mar 18, 2024 am 09:19 AM
ビッグデータ プロジェクトにおける Python ORM の適用
Mar 18, 2024 am 09:19 AM
オブジェクト リレーショナル マッピング (ORM) は、開発者が SQL クエリを直接記述せずにオブジェクト プログラミング言語を使用してデータベースを操作できるようにするプログラミング テクノロジです。 Python の ORM ツール (SQLAlchemy、Peeweee、DjangoORM など) は、ビッグ データ プロジェクトのデータベース操作を簡素化します。利点 コードの単純さ: ORM により、長い SQL クエリを作成する必要がなくなり、コードの単純さと読みやすさが向上します。データの抽象化: ORM は、アプリケーション コードをデータベース実装の詳細から分離する抽象化レイヤーを提供し、柔軟性を向上させます。パフォーマンスの最適化: ORM は多くの場合、キャッシュとバッチ操作を使用してデータベース クエリを最適化し、それによってパフォーマンスを向上させます。移植性: ORM により、開発者は次のことが可能になります。
 Python ワークフロー エンジン フレームワークを呼び出す方法
Mar 02, 2024 am 09:00 AM
Python ワークフロー エンジン フレームワークを呼び出す方法
Mar 02, 2024 am 09:00 AM
Python ワークフロー エンジン フレームワークを呼び出すには、以下の手順に従う必要があります。 ワークフロー エンジン フレームワークをインストールします。まず、必要なワークフロー エンジン フレームワークを Python 環境にインストールする必要があります。一般的な Python ワークフロー エンジン フレームワークには、Celery、airflow、Luigi などが含まれます。 pip コマンドを使用して、必要なフレームワークをインストールできます。例: pipinstallcelery ワークフロー エンジン フレームワークのインポート: Python スクリプトでは、使用するワークフロー エンジン フレームワークをインポートする必要があります。 import ステートメントを使用して、フレームワークをスクリプトにインポートします。例: importcelery ワークフロー タスクの定義: 次に、ワークフロー タスクを定義する必要があります。ワークフロータスクは、
