

Stable Video 3D が衝撃的なデビューを果たします。単一の画像から死角のない 3D ビデオが生成され、モデルの重みがオープンになります。

Stability AI の優れたモデル ファミリーに新しいメンバーが加わりました。
昨日、Stable Diffusion と Stable Video Diffusion をリリースした後、Stability AI は大規模な 3D ビデオ生成モデル「Stable Video 3D」(SV3D) をコミュニティに導入しました。
モデルは安定したビデオ拡散に基づいて構築されており、その主な利点は 3D 生成の品質とマルチビューの一貫性が大幅に向上することです。 Stability AI によって発売された以前の Stable Zero123 および共同オープンソース Zero123-XL と比較して、このモデルの効果はさらに優れています。
現在、Stable Video 3D は、Stability AI メンバーシップ (メンバーシップ) への参加が必要な商用利用と、ユーザーが Hugging Face でモデル ウェイトをダウンロードできる非商用利用の両方をサポートしています。

#Stability AI は、SV3D_u と SV3D_p という 2 つのモデル バリアントを提供します。 SV3D_u は、カメラ調整を必要とせずに単一の画像入力に基づいて軌道ビデオを生成します。一方、SV3D_p は、単一の画像と軌道遠近を適応させることで生成機能をさらに拡張し、ユーザーが指定されたカメラ パスに沿って 3D ビデオを作成できるようにします。
現在、Stable Video 3D に関する研究論文が公開されており、中心著者は 3 人です。

- #論文アドレス: https://stability.ai/s/SV3D_report.pdf
- ブログ アドレス: https://stability.ai/news/introducing-stable-video-3d
- Huggingface アドレス: https:// hackgingface.co/stabilityai/sv3d
Stable Video 3D は、3D 生成、特にノベル ビューにおいて大幅な進歩をもたらします。合成(NVS)。
以前のアプローチでは、限られた視野角や一貫性のない入力の問題を解決する傾向がありましたが、Stable Video 3D は、任意の角度から一貫したビューを提供し、適切に一般化することができます。その結果、このモデルはポーズの制御性を向上させるだけでなく、複数のビューにわたって一貫したオブジェクトの外観を保証し、リアルで正確な 3D 生成に影響を与える重要な問題をさらに改善します。
下の図に示すように、Stable Zero123 および Zero-XL と比較して、Stable Video 3D は、より強力なディテール、より入力画像に忠実な新しいマルチビューを生成できます。一貫した多視点。

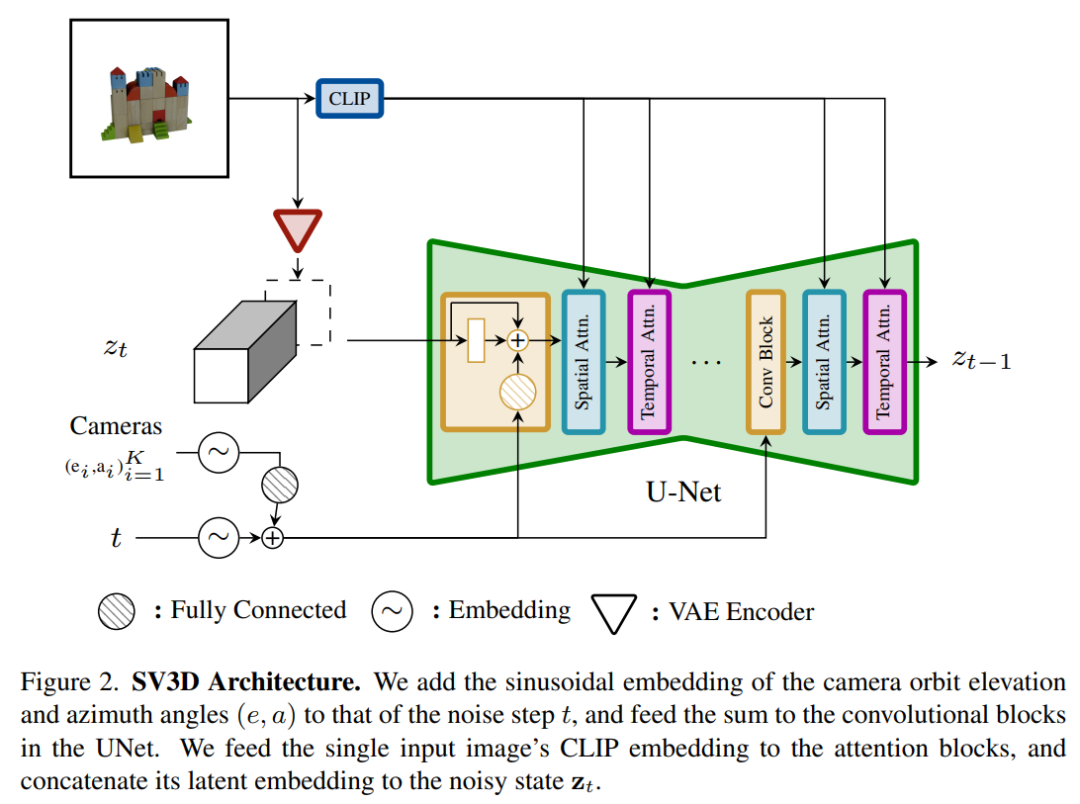
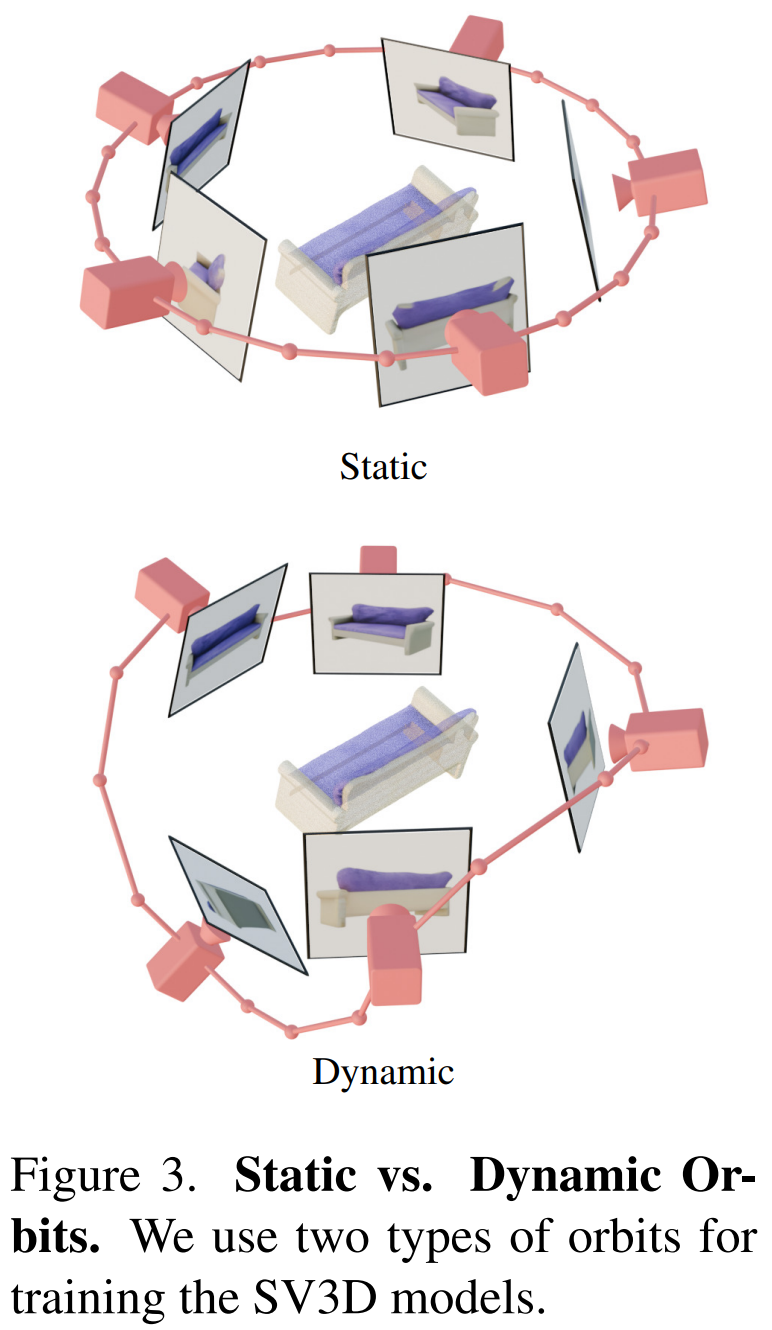
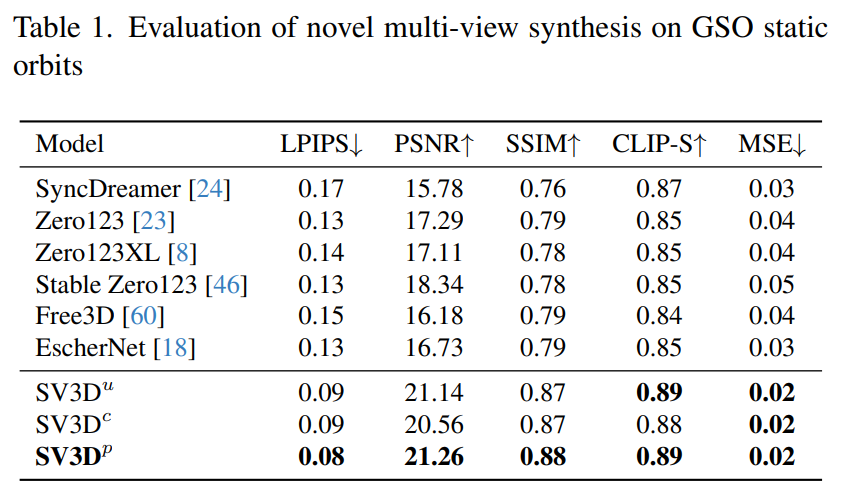
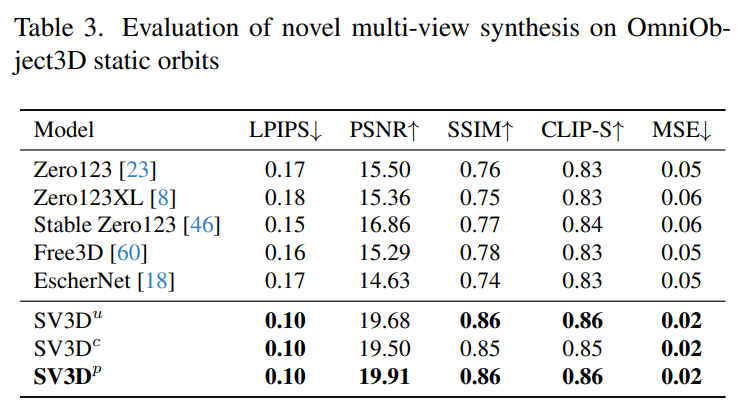
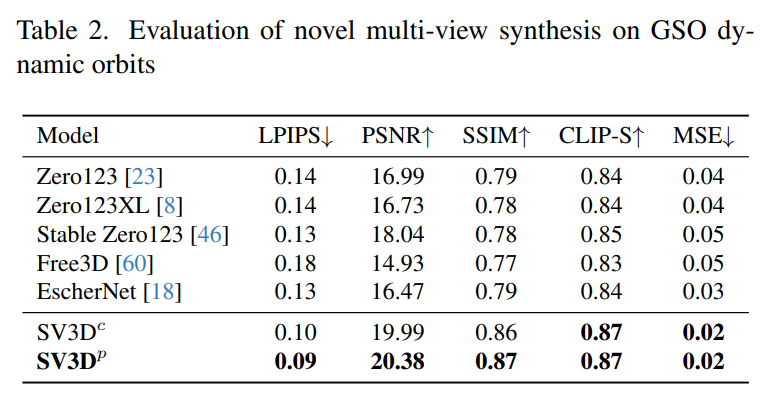
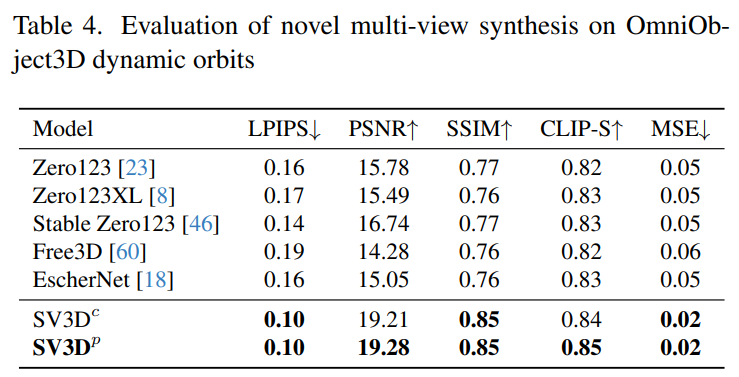
この目的を達成するために、Stability AI は、予測ビュー内の目に見えない領域の 3D 品質をさらに向上させる、マスクされた分別蒸留サンプリング損失を設計しました。また、ベイクされたライティングの問題を軽減するために、Stable Video 3D は 3D 形状とテクスチャで最適化された分離されたライティング モデルを使用します。 下の画像は、Stable Video 3D モデルとその出力を使用した場合の 3D 最適化による改善された 3D メッシュ生成の例を示しています。 次の図は、Stable Video 3D を使用して生成された 3D メッシュ結果と、EscherNet および Stable Zero123 によって生成された 3D メッシュ結果の比較を示しています。 # アーキテクチャの詳細 Stable Video 3D モデルのアーキテクチャは次のとおりです。図 2 に示すように、これは Stable Video Diffusion アーキテクチャに基づいて構築されており、複数のレイヤーを備えた UNet が含まれており、各レイヤーには Conv3D レイヤーを備えた残差ブロック シーケンスと、アテンション レイヤー (空間および時間) トランスフォーマーを備えた 2 つが含まれています。ブロック。 具体的な処理は次のとおりです。 (i) 「fps id」と「」を削除します。モーション バケット ID」(これらは Stable Video 3D とは関係がないため); (ii) 条件付き画像は、Stable Video Diffusion の VAE エンコーダを通じて潜在空間に埋め込まれます。次に、タイム ステップ t における UNet のノイズ潜在状態入力 zt に渡され、ノイズ潜在状態入力 zt に接続されます; #(iii) 条件付き画像の CLIPembedding 行列が提供されます各トランスフォーマー ブロックのクロスアテンション層にキーと値として機能し、クエリは対応する層の特徴になります; (iv) カメラの軌跡がフィードされます。拡散ノイズの時間ステップに沿った残差ブロック。カメラのポーズ角度 ei と ai およびノイズ時間ステップ t は、最初に正弦波位置埋め込みに埋め込まれ、次にカメラ ポーズの埋め込みが線形変換のために連結され、ノイズ時間ステップの埋め込みに追加され、最後に各残差ブロックに供給され、ブロックの入力特徴量に追加されます。 さらに、Stability AI は、以下の図 3 に示すように、カメラのポーズ調整の影響を研究するために静的軌道と動的軌道を設計しました。 #静的軌道上では、カメラは条件画像と同じ仰角を使用して等距離方位角でオブジェクトの周りを回転します。この欠点は、調整された仰角に基づいて、オブジェクトの上部または下部に関する情報が得られない可能性があることです。動的軌道では、方位角が等しくない場合があり、各ビューの仰角も異なる場合があります。 動的軌道を構築するために、Stability AI は静的軌道をサンプリングし、その方位角に小さなランダム ノイズを追加し、その仰角に異なる周波数の正弦波のランダムに重み付けされた組み合わせを追加します。そうすることで時間的な滑らかさが提供され、カメラの軌道が条件画像と同じ方位角と仰角のループに沿って終了することが保証されます。 安定性 AI は、目に見えない GSO および OmniObject3D データセット上の静的および動的軌道上で安定したビデオを評価し、3D 複合マルチビュー効果を評価しました。以下の表 1 ~ 4 に示す結果は、Stable Video 3D が新しいマルチビュー合成において最先端のパフォーマンスを達成していることを示しています。 表 1 と 3 は、静的軌道上の Stable Video 3D とその他のモデルの結果を示しており、ポーズ調整を行わないモデル SV3D_u でも、以前のすべての方法よりも優れたパフォーマンスを示しています。 アブレーション解析の結果は、SV3D_c と SV3D_p が静的軌道の生成において SV3D_u よりも優れていることを示していますが、後者は静的軌道のみでトレーニングされています。 以下の表 2 および表 4 は、姿勢調整モデル SV3D_c および SV3D_p を含む動的軌道の生成結果を示しています。 、すべてのメトリクスで SOTA を達成します。


実験結果

以上がStable Video 3D が衝撃的なデビューを果たします。単一の画像から死角のない 3D ビデオが生成され、モデルの重みがオープンになります。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7492
7492
 15
1377
52
77
11
19
41
15
1377
52
77
11
19
41

 Oracleデータベースの作成方法Oracleデータベースの作成方法
Apr 11, 2025 pm 02:36 PM
Oracleデータベースの作成方法Oracleデータベースの作成方法
Apr 11, 2025 pm 02:36 PM
Oracleデータベースを作成するには、一般的な方法はDBCAグラフィカルツールを使用することです。手順は次のとおりです。1。DBCAツールを使用してDBNAMEを設定してデータベース名を指定します。 2. SyspasswordとSystemPassWordを強力なパスワードに設定します。 3.文字セットとNationalCharactersetをAL32UTF8に設定します。 4.実際のニーズに応じて調整するようにMemorySizeとTableSpacesizeを設定します。 5. logfileパスを指定します。 高度な方法は、SQLコマンドを使用して手動で作成されますが、より複雑でエラーが発生しやすいです。 パスワードの強度、キャラクターセットの選択、表空間サイズ、メモリに注意してください
 Oracleデータベースの作成方法Oracleデータベースを作成する方法
Apr 11, 2025 pm 02:33 PM
Oracleデータベースの作成方法Oracleデータベースを作成する方法
Apr 11, 2025 pm 02:33 PM
Oracleデータベースを作成するのは簡単ではありません。根本的なメカニズムを理解する必要があります。 1.データベースとOracle DBMSの概念を理解する必要があります。 2。SID、CDB(コンテナデータベース)、PDB(プラグ可能なデータベース)などのコアコンセプトをマスターします。 3。SQL*Plusを使用してCDBを作成し、PDBを作成するには、サイズ、データファイルの数、パスなどのパラメーターを指定する必要があります。 4.高度なアプリケーションは、文字セット、メモリ、その他のパラメーターを調整し、パフォーマンスチューニングを実行する必要があります。 5.ディスクスペース、アクセス許可、パラメーター設定に注意し、データベースのパフォーマンスを継続的に監視および最適化します。 それを巧みに習得することによってのみ、継続的な練習が必要であることは、Oracleデータベースの作成と管理を本当に理解できます。
 Oracleデータベースステートメントの作成方法
Apr 11, 2025 pm 02:42 PM
Oracleデータベースステートメントの作成方法
Apr 11, 2025 pm 02:42 PM
Oracle SQLステートメントのコアは、さまざまな条項の柔軟なアプリケーションと同様に、選択、挿入、更新、削除です。インデックスの最適化など、ステートメントの背後にある実行メカニズムを理解することが重要です。高度な使用法には、サブクエリ、接続クエリ、分析関数、およびPL/SQLが含まれます。一般的なエラーには、構文エラー、パフォーマンスの問題、およびデータの一貫性の問題が含まれます。パフォーマンス最適化のベストプラクティスには、適切なインデックスの使用、Select *の回避、条項の最適化、およびバインドされた変数の使用が含まれます。 Oracle SQLの習得には、コードライティング、デバッグ、思考、基礎となるメカニズムの理解など、練習が必要です。
 mysqlデータテーブルフィールド操作ガイドの追加、変更、削除方法ガイド
Apr 11, 2025 pm 05:42 PM
mysqlデータテーブルフィールド操作ガイドの追加、変更、削除方法ガイド
Apr 11, 2025 pm 05:42 PM
MySQLのフィールド操作ガイド:フィールドを追加、変更、削除します。フィールドを追加:table table_nameを変更するcolumn_name data_type [not null] [default default_value] [プライマリキー] [auto_increment]フィールドの変更:column_name data_typeを変更するcolumn_name data_type [not null] [default default_value] [プライマリキー]
 Oracleデータベーステーブルの整合性の制約は何ですか?
Apr 11, 2025 pm 03:42 PM
Oracleデータベーステーブルの整合性の制約は何ですか?
Apr 11, 2025 pm 03:42 PM
Oracleデータベースの整合性の制約により、以下を含むデータの精度を確保できます。NULL:NULL値は禁止されています。一意:単一のヌル値を許可する一意性を保証します。一次キー:一次キーの制約、一意を強化し、ヌル値を禁止します。外部キー:テーブル間の関係を維持する、外部キーはプライマリテーブルのプライマリキーを参照します。チェック:条件に応じて列の値を制限します。
 MySQLデータベースのネストされたクエリインスタンスの詳細な説明
Apr 11, 2025 pm 05:48 PM
MySQLデータベースのネストされたクエリインスタンスの詳細な説明
Apr 11, 2025 pm 05:48 PM
ネストされたクエリは、1つのクエリに別のクエリを含める方法です。これらは主に、複雑な条件を満たし、複数のテーブルを関連付け、要約値または統計情報を計算するデータを取得するために使用されます。例には、平均賃金を超える従業員を見つけること、特定のカテゴリの注文を見つけること、各製品の総注文量の計算が含まれます。ネストされたクエリを書くときは、サブ征服を書き、結果を外側のクエリ(エイリアスまたは条項として参照)に書き込み、クエリパフォーマンスを最適化する必要があります(インデックスを使用)。
 オラクルは何をしますか
Apr 11, 2025 pm 06:06 PM
オラクルは何をしますか
Apr 11, 2025 pm 06:06 PM
Oracleは、世界最大のデータベース管理システム(DBMS)ソフトウェア会社です。その主な製品には、次の機能が含まれます。リレーショナルデータベース管理システム(Oracle Database)開発ツール(Oracle Apex、Oracle Visual Builder)ミドルウェア(Oracle Weblogic Server、Oracle SOA Suite)Cloud Service(Oracle Cloud Infrastructure)Cloud ServiceおよびBusiness Intelligence(Oracle Analytics Cloud、Oracle Essbase)Blockchain(Oracle Blockchain Pla
 Debian Apacheログ形式の構成方法
Apr 12, 2025 pm 11:30 PM
Debian Apacheログ形式の構成方法
Apr 12, 2025 pm 11:30 PM
この記事では、Debian SystemsでApacheのログ形式をカスタマイズする方法について説明します。次の手順では、構成プロセスをガイドします。ステップ1:Apache構成ファイルにアクセスするDebianシステムのメインApache構成ファイルは、/etc/apache2/apache2.confまたは/etc/apache2/httpd.confにあります。次のコマンドを使用してルートアクセス許可を使用して構成ファイルを開きます。sudonano/etc/apache2/apache2.confまたはsudonano/etc/apache2/httpd.confステップ2:検索または検索または
