

大規模な言語モデルを微調整するための技術的な課題と最適化戦略を理解するための 1 つの記事

皆さんこんにちは、私の名前はルガです。今日は、人工知能エコシステムのテクノロジー、特に LLM Fine-Tuning について引き続き調査していきます。この記事では、LLM Fine-Tuning テクノロジーを引き続き徹底的に分析し、誰もがその実装メカニズムをよりよく理解し、市場開発やその他の分野に適用できるようにしていきます。

LLM (Large Language Model) は、人工知能テクノロジーの新しい波をリードしています。この高度な AI は、統計モデルを使用して大量のデータを分析し、単語やフレーズ間の複雑なパターンを学習することで、人間の認知能力と言語能力をシミュレートします。 LLM の強力な機能は、多くの大手企業やテクノロジー愛好家から強い関心を集めており、業務効率の向上、作業負担の軽減、コスト支出の削減、そして最終的にはインスピレーションを与えることを目的として、人工知能による革新的なソリューションの導入を急いでいます。ビジネス価値を生み出す、より革新的なアイデア。
しかし、LLM の可能性を真に発揮するには、「カスタマイズ」が鍵となります。つまり、企業が特定の最適化戦略を通じて、一般的な事前トレーニング済みモデルを、自社固有のビジネス ニーズやユースケース シナリオを満たす専用のモデルにどのように変換できるかということです。さまざまな企業とアプリケーション シナリオの違いを考慮すると、適切な LLM 統合方法を選択することが特に重要です。したがって、特定のユースケースの要件を正確に評価し、さまざまな統合オプション間の微妙な違いとトレードオフを理解することは、企業が情報に基づいた意思決定を行うのに役立ちます。
ファインチューニングとは何ですか?
今日の知識の普及の時代において、AI と LLM に関する情報や意見を入手するのはかつてないほど簡単になっています。ただし、実践的で状況に応じた専門的な答えを見つけることは依然として課題です。私たちの日常生活では、このようなよくある誤解に遭遇することがよくあります。一般に、ファインチューニング (微調整) モデルが、LLM が新しい知識を取得するための唯一 (またはおそらく最良の) 方法であると信じられています。実際、インテリジェントな協調アシスタントを製品に追加する場合でも、LLM を使用してクラウドに保存されている大量の非構造化データを分析する場合でも、実際のデータとビジネス環境は、適切な LLM アプローチを選択するための重要な要素です。
多くの場合、従来の微調整方法よりも、操作がそれほど複雑でなく、頻繁に変更されるデータセットに対してより堅牢で、より信頼性が高く正確な結果を生成する代替戦略を採用することが有益です。より効果的に。微調整は、特定のデータセットの事前トレーニング済みモデルに対して追加のトレーニングを実行して、特定のタスクまたはドメインに適合させる一般的な LLM カスタマイズ手法ですが、いくつかの重要なトレードオフと制限もあります。
それでは、ファインチューニングとは何でしょうか?
LLM (Large Language Model) ファインチューニングは、NLP (自然言語処理) の分野で注目を集めている技術の 1 つです。近年。すでにトレーニングされたモデルに対して追加のトレーニングを実行することで、モデルを特定のドメインまたはタスクにさらに適応させることができます。この方法により、モデルは特定のドメインに関連するより多くの知識を学習できるため、このドメインまたはタスクでのパフォーマンスが向上します。 LLM 微調整の利点は、事前トレーニングされたモデルが学習した一般的な知識を利用し、特定のドメインでさらに微調整して、特定のタスクでより高い精度とパフォーマンスを達成できることです。この手法はさまざまな NLP タスクで広く使用されており、顕著な成果を上げています。
LLM 微調整の主な概念は、事前トレーニングされたモデルのパラメーターを新しいタスクの基礎として使用することであり、少量の特定のドメインまたはタスク データを微調整することで、モデルを迅速に適応させることができます。新しいタスクまたはデータセット。この方法では、新しいタスクでのモデルのパフォーマンスを向上させながら、トレーニング時間とリソースを大幅に節約できます。 LLM 微調整の柔軟性と効率性により、LLM 微調整は多くの自然言語処理タスクで推奨される方法の 1 つとなっています。事前トレーニングされたモデルに基づいて微調整することで、モデルは新しいタスクの機能とパターンをより速く学習できるため、全体的なパフォーマンスが向上します。
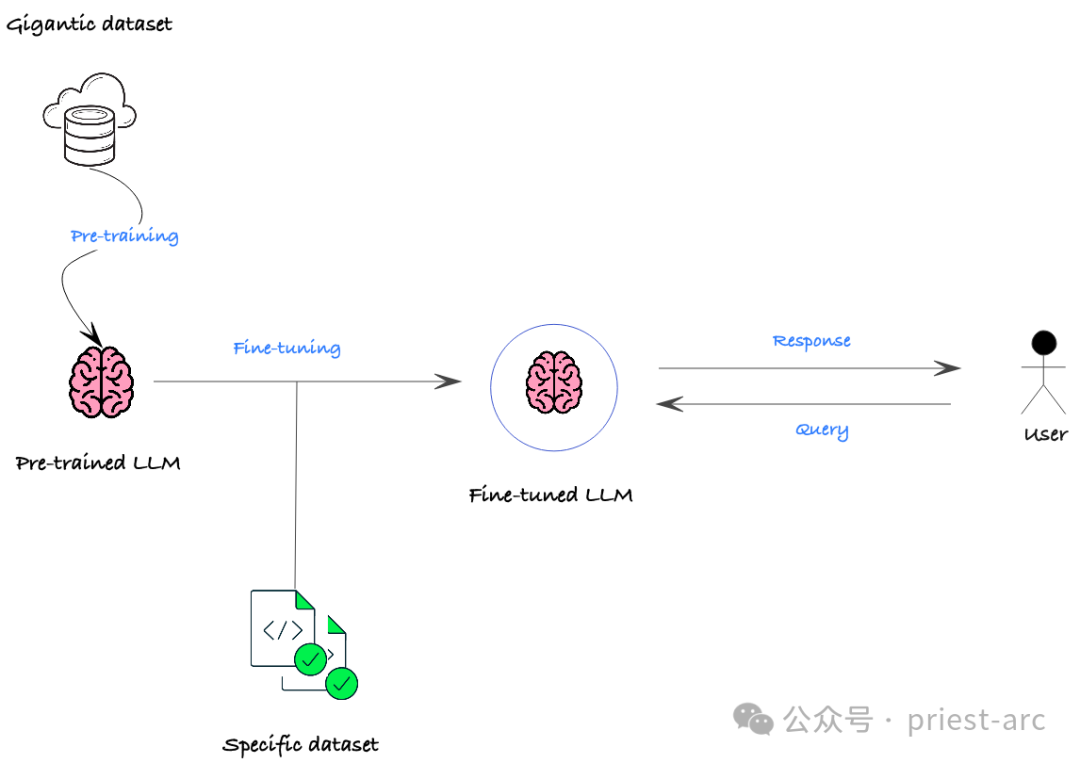
- 壊滅的な忘却: 微調整は「壊滅的な忘却」につながる可能性があります。つまり、モデルが事前トレーニング中に学習した常識の一部を忘れてしまいます。これは、ナッジ データが具体的すぎる場合、または主に狭い領域に焦点を当てている場合に発生する可能性があります。
- データ要件: 微調整に必要なデータは、最初からトレーニングするよりも少なくなりますが、特定のタスクには高品質で関連性の高いデータが必要です。データが不十分または不適切にラベル付けされていると、パフォーマンスの低下につながる可能性があります。
- 計算リソース: 微調整プロセスは、特に複雑なモデルや大規模なデータ セットの場合、依然として計算コストが高くなります。小規模な組織やリソースが限られている組織にとって、これは障壁となる可能性があります。
- 必要な専門知識: 微調整には、多くの場合、機械学習、NLP、当面の特定のタスクなどの分野に関する専門知識が必要です。適切な事前トレーニング済みモデルの選択、ハイパーパラメーターの構成、結果の評価は、必要な知識がない人にとっては複雑になる可能性があります。
潜在的な問題:
- バイアス増幅: 事前トレーニングされたモデルは、トレーニング データからバイアスを継承する可能性があります。ナッジされたデータが同様のバイアスを反映している場合、ナッジによってこれらのバイアスが誤って増幅される可能性があります。これは不公平または差別的な結果につながる可能性があります。
- 解釈可能性の課題: 微調整されたモデルは、事前トレーニングされたモデルよりも解釈が困難です。モデルがどのように結果に到達するかを理解するのは難しい場合があり、デバッグやモデルの出力の信頼性が妨げられます。
- セキュリティ リスク: 微調整されたモデルは、悪意のある攻撃者が入力データを操作し、モデルが不正な出力を生成する敵対的攻撃に対して脆弱になる可能性があります。
ファインチューニングは他のカスタマイズ方法とどのように比較できますか?
一般的に言えば、ファインチューニングはモデル出力をカスタマイズしたり、カスタム データを統合したりする唯一の方法ではありません。実際、これは私たちの特定のニーズやユースケースには適していない可能性がありますが、以下に示すように、調査および検討する価値のある代替案がいくつかあります:
1. プロンプト エンジニアリング
プロンプト エンジニアリングはプロセスです。 AI モデルに送信されるヒントに詳細な指示やコンテキスト データを提供することで、目的の出力が得られる可能性が高まります。プロンプト エンジニアリングは、微調整よりも操作がはるかに複雑ではなく、基礎となるモデルを変更することなく、いつでもプロンプトを変更して再デプロイできます。
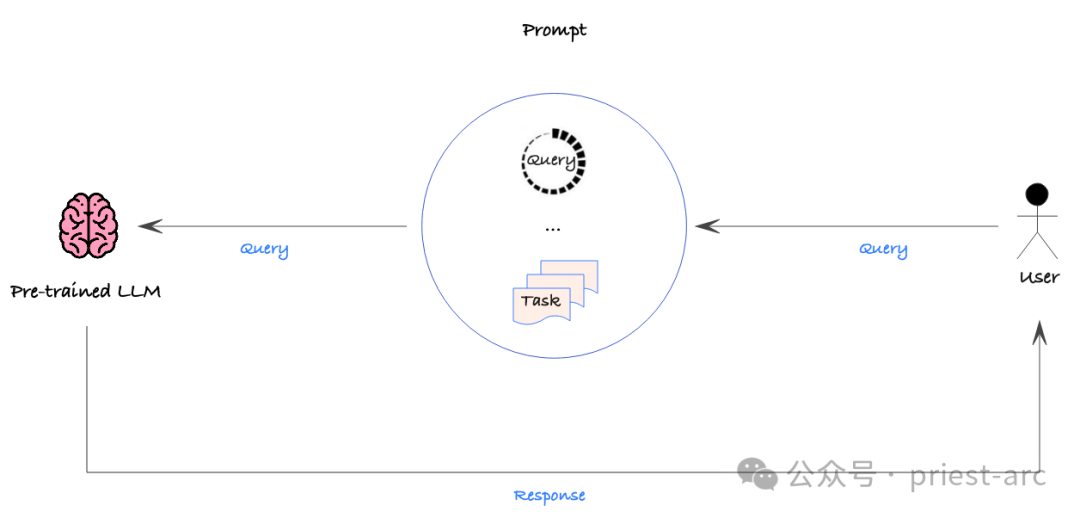
この戦略は比較的単純ですが、望ましいパフォーマンスを確保するために、さまざまなヒントの精度を定量的に評価するには、やはりデータ駆動型のアプローチを使用する必要があります。このようにして、体系的にキューを調整して、モデルを誘導して目的の出力を生成する最も効率的な方法を見つけることができます。
ただし、Prompt Engineering にも欠点がないわけではありません。まず、プロンプトは通常手動で変更および展開されるため、大規模なデータ セットを直接統合することはできません。これは、大規模なデータを処理する場合、プロンプト エンジニアリングの効率が低下する可能性があることを意味します。
さらに、プロンプト エンジニアリングでは、基本的なトレーニング データに存在しない新しい動作や機能をモデルに生成させることはできません。この制限は、モデルにまったく新しい機能を持たせる必要がある場合、ヒント エンジニアリングのみに依存するとニーズを満たすことができない可能性があり、モデルをゼロから微調整したりトレーニングしたりするなど、他の方法を考慮する必要がある可能性があることを意味します。
2. RAG (検索拡張生成)
RAG (検索拡張生成) は、大規模な非構造化データ セット (ドキュメントなど) を LLM と組み合わせる効果的な方法です。これは、セマンティック検索とベクトル データベース テクノロジーをヒンティング メカニズムと組み合わせて活用し、LLM が豊富な外部情報から必要な知識とコンテキストを取得して、より正確で洞察力に富んだ出力を生成できるようにします。
RAG 自体は新しいモデル特徴を生成するためのメカニズムではありませんが、LLM と大規模な非構造化データ セットを効率的に統合するための非常に強力なツールです。 RAG を使用すると、LLM に関連する大量の背景情報を簡単に提供できるため、LLM の知識と理解を強化でき、それによって生成パフォーマンスが大幅に向上します。
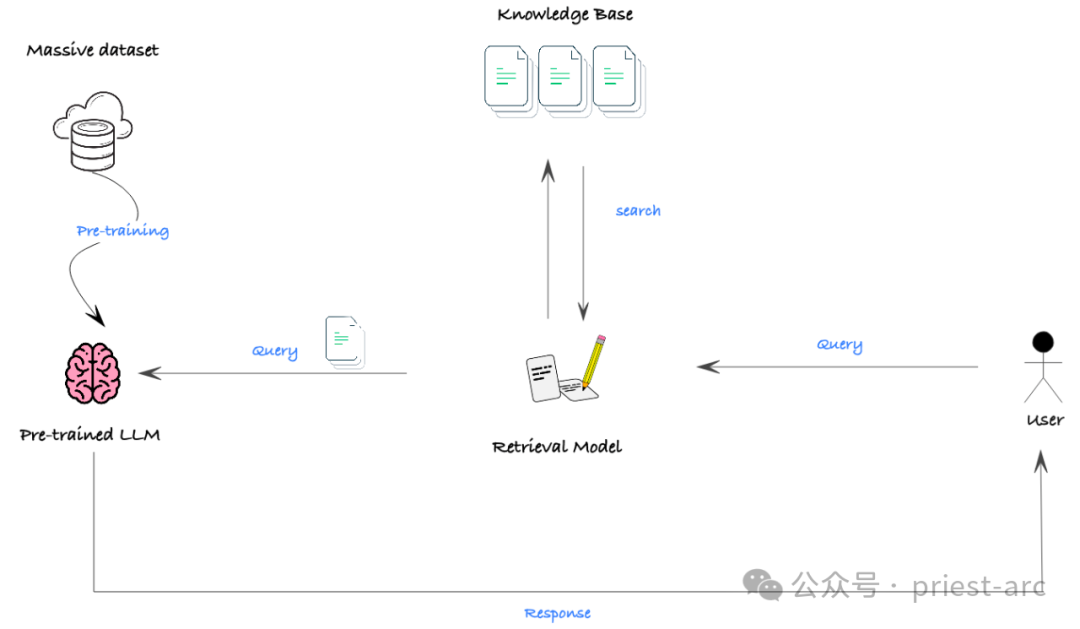
実際のシナリオでは、RAG の有効性に対する最大の障害は、多くのモデルのコンテキスト ウィンドウ、つまりモデルが処理できる最大テキスト長が制限されていることです。 1回限りです。広範な背景知識が必要な状況では、モデルが良好なパフォーマンスを達成するのに十分な情報を取得できない可能性があります。
しかし、テクノロジーの急速な発展に伴い、モデルのコンテキスト ウィンドウは急速に拡大しています。一部のオープンソース モデルでも、最大 32,000 トークンの長いテキスト入力を処理できます。これは、RAG が将来的に幅広いアプリケーションの可能性を持ち、より複雑なタスクを強力にサポートできることを意味します。
次に、データ プライバシーの観点から、これら 3 つのテクノロジーの具体的なパフォーマンスを理解し、比較してみましょう。詳細については、次を参照してください:
(1) 微調整 )
ファインチューニングの主な欠点は、モデルのトレーニング時に使用される情報がモデルのパラメーターにエンコードされることです。これは、モデルの出力がユーザーにプライベートであっても、基礎となるトレーニング データが漏洩する可能性があることを意味します。調査によると、悪意のある攻撃者はインジェクション攻撃を通じてモデルから生のトレーニング データを抽出することもできます。したがって、モデルのトレーニングに使用されるデータは将来のユーザーがアクセスできる可能性があると想定する必要があります。
(2) Prompt Engineering(プロンプト エンジニアリング)
これに比べて、プロンプト エンジニアリングのデータ セキュリティ フットプリントははるかに小さいです。プロンプトはユーザーごとに分離してカスタマイズできるため、ユーザーごとに表示されるプロンプトに含まれるデータは異なる場合があります。ただし、プロンプトに含まれるデータが機密でないこと、またはプロンプトにアクセスできるすべてのユーザーに許可されていることを確認する必要があります。
(3) RAG (検索拡張生成)
RAG のセキュリティは、基礎となる検索システムのデータ アクセス制御に依存します。不正アクセスを防ぐために、基礎となるベクター データベースとプロンプト テンプレートが適切なプライバシーとデータ制御で構成されていることを確認する必要があります。この方法によってのみ、RAG はデータ プライバシーを真に確保できます。
全体として、データ プライバシーに関しては、Prompt Engineering と RAG には微調整よりも明らかな利点があります。ただし、どの方法を採用する場合でも、ユーザーの機密情報が完全に保護されるように、データ アクセスとプライバシー保護を非常に注意深く管理する必要があります。
つまり、ある意味、最終的にファインチューニング、プロンプトエンジニアリング、または RAG を選択するかどうかに関係なく、採用されるアプローチは、組織の戦略目標、利用可能なリソース、専門知識、期待される投資収益率およびその他の要素と一致している必要があります。高い一貫性を維持します。それは純粋な技術的能力だけではなく、これらのアプローチが当社のビジネス戦略、タイムライン、現在のワークフロー、市場のニーズにどのように適合するかについても重要です。
微調整オプションの複雑さを理解することは、情報に基づいた意思決定を行うための鍵となります。ファインチューニングに関わる技術的な詳細とデータの準備は比較的複雑で、モデルとデータを深く理解する必要があります。したがって、微調整の豊富な経験を持つパートナーと緊密に連携することが重要です。これらのパートナーは、信頼できる技術力を備えているだけでなく、当社のビジネス プロセスと目標を完全に理解し、当社に最適なカスタマイズされた技術ソリューションを選択できる必要があります。
同様に、プロンプト エンジニアリングまたは RAG の使用を選択した場合は、これらの方法がビジネス ニーズ、リソースの条件、および期待される効果に適合するかどうかを慎重に評価する必要もあります。最終的には、選択したカスタマイズされたテクノロジーが組織に真の価値を生み出すことができることを確認することによってのみ成功を達成できます。
参考:
- [1] https://medium.com/@younesh.kc/rag-vs-fine-tuning-in-large- language-models-a -comparison-c765b9e21328
- [2] https://kili-technology.com/large- language-models-llms/the-ultimate-guide-to-fine-tuning-llms-2023
以上が大規模な言語モデルを微調整するための技術的な課題と最適化戦略を理解するための 1 つの記事の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7526
7526
 15
1378
52
81
11
21
74
15
1378
52
81
11
21
74

 Debian Apacheログレベルを設定する方法
Apr 13, 2025 am 08:33 AM
Debian Apacheログレベルを設定する方法
Apr 13, 2025 am 08:33 AM
この記事では、DebianシステムのApachewebサーバーのロギングレベルを調整する方法について説明します。構成ファイルを変更することにより、Apacheによって記録されたログ情報の冗長レベルを制御できます。方法1:メイン構成ファイルを変更して、構成ファイルを見つけます。Apache2.xの構成ファイルは、通常/etc/apache2/ディレクトリにあります。ファイル名は、インストール方法に応じて、apache2.confまたはhttpd.confである場合があります。構成ファイルの編集:テキストエディターを使用してルートアクセス許可を使用して構成ファイルを開く(nanoなど):sudonano/etc/apache2/apache2.conf
 Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Systemsでは、Directoryコンテンツを読み取るためにReadDirシステム呼び出しが使用されます。パフォーマンスが良くない場合は、次の最適化戦略を試してください。ディレクトリファイルの数を簡素化します。大きなディレクトリをできる限り複数の小さなディレクトリに分割し、Readdirコールごとに処理されたアイテムの数を減らします。ディレクトリコンテンツのキャッシュを有効にする:キャッシュメカニズムを構築し、定期的にキャッシュを更新するか、ディレクトリコンテンツが変更されたときに、頻繁な呼び出しをreaddirに削減します。メモリキャッシュ(memcachedやredisなど)またはローカルキャッシュ(ファイルやデータベースなど)を考慮することができます。効率的なデータ構造を採用する:ディレクトリトラバーサルを自分で実装する場合、より効率的なデータ構造(線形検索の代わりにハッシュテーブルなど)を選択してディレクトリ情報を保存およびアクセスする
 Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Systemsでは、Readdir関数はディレクトリコンテンツを読み取るために使用されますが、それが戻る順序は事前に定義されていません。ディレクトリ内のファイルを並べ替えるには、最初にすべてのファイルを読み取り、QSORT関数を使用してソートする必要があります。次のコードは、debianシステムにreaddirとqsortを使用してディレクトリファイルを並べ替える方法を示しています。
 Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverのファイアウォールの構成は、サーバーのセキュリティを確保するための重要なステップです。以下は、iPtablesやFirewalldの使用を含む、一般的に使用されるファイアウォール構成方法です。 iPtablesを使用してファイアウォールを構成してIPTablesをインストールします(まだインストールされていない場合):sudoapt-getupdatesudoapt-getinstalliptablesview現在のiptablesルール:sudoiptables-l configuration
 Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail ServerにSSL証明書をインストールする手順は次のとおりです。1。最初にOpenSSL Toolkitをインストールすると、OpenSSLツールキットがシステムに既にインストールされていることを確認してください。インストールされていない場合は、次のコマンドを使用してインストールできます。sudoapt-getUpdatesudoapt-getInstalopenssl2。秘密キーと証明書のリクエストを生成次に、OpenSSLを使用して2048ビットRSA秘密キーと証明書リクエスト(CSR)を生成します:Openss
 Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
DebianシステムのReadDir関数は、ディレクトリコンテンツの読み取りに使用されるシステムコールであり、Cプログラミングでよく使用されます。この記事では、ReadDirを他のツールと統合して機能を強化する方法について説明します。方法1:C言語プログラムを最初にパイプラインと組み合わせて、cプログラムを作成してreaddir関数を呼び出して結果をinclude#include#include inctargc、char*argv []){dir*dir; structdireant*entry; if(argc!= 2){(argc!= 2){
 Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian Systemsでは、OpenSSLは暗号化、復号化、証明書管理のための重要なライブラリです。中間の攻撃(MITM)を防ぐために、以下の測定値をとることができます。HTTPSを使用する:すべてのネットワーク要求がHTTPの代わりにHTTPSプロトコルを使用していることを確認してください。 HTTPSは、TLS(Transport Layer Security Protocol)を使用して通信データを暗号化し、送信中にデータが盗まれたり改ざんされたりしないようにします。サーバー証明書の確認:クライアントのサーバー証明書を手動で確認して、信頼できることを確認します。サーバーは、urlsessionのデリゲート方法を介して手動で検証できます
 Debian Hadoopログ管理を行う方法
Apr 13, 2025 am 10:45 AM
Debian Hadoopログ管理を行う方法
Apr 13, 2025 am 10:45 AM
DebianでHadoopログを管理すると、次の手順とベストプラクティスに従うことができます。ログ集約を有効にするログ集約を有効にします。Yarn.log-Aggregation-set yarn-site.xmlファイルでは、ログ集約を有効にします。ログ保持ポリシーの構成:yarn.log-aggregation.retain-secondsを設定して、172800秒(2日)などのログの保持時間を定義します。ログストレージパスを指定:Yarn.Nを介して
