

Googleが「Vlogger」モデルをリリース:1枚の写真から10秒の動画が生成される

Google は新しいビデオ フレームワークをリリースしました:
あなたの顔の写真とスピーチの録音だけがあれば、本物のようなスピーチのビデオを取得できます。
ビデオの長さは可変で、現在の例では最大 10 秒です。
口の形にしても表情にしても、とても自然であることがわかります。
入力画像が上半身全体をカバーしている場合、リッチジェスチャと一致させることもできます:

それを読んだネチズンは次のように言いました:
はい。これにより、将来的にはオンラインビデオ会議のために髪を整えたり、着替えたりする必要がなくなりました。
まあ、ポートレートを撮って音声音声を録音するだけです (手動の犬の頭)
あなたの声を使ってポートレートを制御し、ビデオを生成します
このフレームワークは VLOGGER と呼ばれます。
これは主に拡散モデルに基づいており、2 つの部分で構成されています。
1 つはランダムな人間から 3D モーションへの拡散モデルです。
もう 1 つは、テキストから画像へのモデルを強化するための新しい拡散アーキテクチャです。
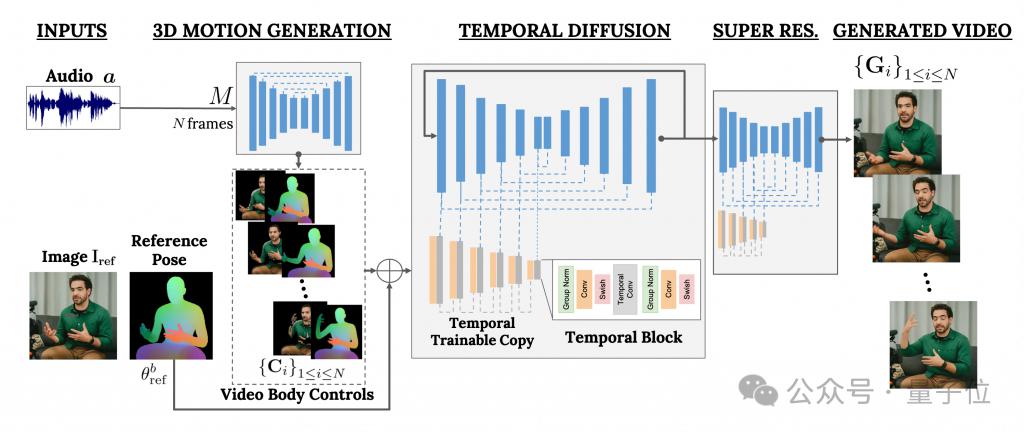
このうち、前者はオーディオ波形を入力として使用して、目、表情やジェスチャー、全体的な身体の姿勢などを含むキャラクターの身体制御アクションを生成します。
後者は、大規模な画像拡散モデルを拡張し、予測されたアクションを使用して対応するフレームを生成するために使用される時間次元の画像間モデルです。
結果を特定のキャラクター画像に適合させるために、VLOGGER はパラメータ画像のポーズ マップも入力として受け取ります。
VLOGGER のトレーニングは、非常に大規模なデータセット (MENTOR という名前) 上で完了します。 ######それはどれくらい大きいですか?長さは 2,200 時間で、合計 800,000 文字のビデオが含まれています。
その中で、テスト セットのビデオの長さも 120 時間、合計 4,000 文字です。
Google によると、VLOGGER の最も優れたパフォーマンスはその多様性にあります。
下の図に示すように、最終的なピクセル画像の色が濃い (赤) ほど、アクションが豊富になります。 。
 業界のこれまでの同様の手法と比較した場合、VLOGGER の最大の利点は、全員をトレーニングする必要がなく、顔検出やトリミングに依存しないことです。生成されたビデオは完成しています (顔と唇の両方、体の動きなどを含む)。
業界のこれまでの同様の手法と比較した場合、VLOGGER の最大の利点は、全員をトレーニングする必要がなく、顔検出やトリミングに依存しないことです。生成されたビデオは完成しています (顔と唇の両方、体の動きなどを含む)。
 具体的には、次の表に示すように:
具体的には、次の表に示すように:
顔の再現方法では、オーディオやテキストを使用してビデオ生成を制御することはできません。
Audio-to-motion では、音声を 3D の顔の動きにエンコードすることで音声を生成できますが、生成される効果は十分に現実的ではありません。
リップシンクはさまざまなテーマのビデオを処理できますが、シミュレートできるのは口の動きだけです。
比較すると、後者の 2 つの方法、SadTaker と Styletalk は Google VLOGGER に最も近いパフォーマンスを示しますが、本体を制御したりビデオをさらに編集したりできないという点でも劣っています。
ビデオ編集と言えば、下図にあるように、キャラクターを黙らせたり、目を閉じたり、左目だけ閉じたり、片方の目だけ開けたりすることができるのがVLOGGERモデルの応用例です。クリック:

もう 1 つのアプリケーションはビデオ翻訳です:
たとえば、元のビデオの英語の音声を同じ口の形でスペイン語に変更します。
ネチズンは苦情を申し立てました
最終的に、「古いルール」に従って、Googleはモデルをリリースせず、現在確認できるのはより多くの効果と論文だけです。
そうですね、多くの不満があります:
モデルの画質、口の形が正しくない、依然としてロボットのように見えるなど。
したがって、否定的なレビューをためらわずに残す人もいます:
これが Google のレベルですか?

「VLOGGER」という名前がちょっと残念です。

——OpenAI の Sora と比較すると、このネチズンの発言は確かに不合理ではありません。 。 ######どう思いますか?
その他のエフェクト:
https://enriccorona.github.io/vlogger/
全文:
https://enriccorona.github 。 io/vlogger/paper.pdf
以上がGoogleが「Vlogger」モデルをリリース:1枚の写真から10秒の動画が生成されるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7321
7321
 9
1625
14
1349
46
1261
25
1209
29
9
1625
14
1349
46
1261
25
1209
29


 DeepSeekを検索する方法
Feb 19, 2025 pm 05:39 PM
DeepSeekを検索する方法
Feb 19, 2025 pm 05:39 PM
DeepSeekは、特定のデータベースまたはシステムでのみ検索する独自の検索エンジンであり、より速く、より正確です。それを使用する場合、ユーザーはドキュメントを読み、さまざまな検索戦略を試し、ユーザーエクスペリエンスに関するヘルプを求めてフィードバックを求めて、利点を最大限に活用することをお勧めします。
 セサミオープンドア交換Webページ登録リンクゲートトレーディングアプリ登録Webサイト最新
Feb 28, 2025 am 11:06 AM
セサミオープンドア交換Webページ登録リンクゲートトレーディングアプリ登録Webサイト最新
Feb 28, 2025 am 11:06 AM
この記事では、SESAME Open Exchange(gate.io)Webバージョンの登録プロセスとGate Tradingアプリを詳細に紹介します。 Web登録であろうとアプリの登録であろうと、公式Webサイトまたはアプリストアにアクセスして、本物のアプリをダウンロードし、ユーザー名、パスワード、電子メール、携帯電話番号、その他の情報を入力し、電子メールまたは携帯電話の確認を完了する必要があります。
 Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか?
Feb 21, 2025 pm 10:57 PM
Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか?
Feb 21, 2025 pm 10:57 PM
Bybit Exchangeリンクを直接ダウンロードしてインストールできないのはなぜですか? BYBITは、ユーザーにトレーディングサービスを提供する暗号通貨交換です。 Exchangeのモバイルアプリは、次の理由でAppStoreまたはGooglePlayを介して直接ダウンロードすることはできません。1。AppStoreポリシーは、AppleとGoogleがApp Storeで許可されているアプリケーションの種類について厳しい要件を持つことを制限しています。暗号通貨交換アプリケーションは、金融サービスを含み、特定の規制とセキュリティ基準を必要とするため、これらの要件を満たしていないことがよくあります。 2。法律と規制のコンプライアンス多くの国では、暗号通貨取引に関連する活動が規制または制限されています。これらの規制を遵守するために、BYBITアプリケーションは公式Webサイトまたはその他の認定チャネルを通じてのみ使用できます
 DeepSeekをダウンロードする方法
Feb 19, 2025 pm 05:45 PM
DeepSeekをダウンロードする方法
Feb 19, 2025 pm 05:45 PM
公式のウェブサイトのダウンロードにアクセスし、ドメイン名とウェブサイトのデザインを注意深く確認してください。ダウンロード後、ファイルをスキャンします。インストール中にプロトコルを読み、インストール時にシステムディスクを避けてください。関数をテストし、カスタマーサービスに連絡して問題を解決します。ソフトウェアのセキュリティと安定性を確保するために、バージョンを定期的に更新します。
 セサミオープンドアトレーディングプラットフォームダウンロードモバイルバージョンgateioトレーディングプラットフォームのダウンロードアドレス
Feb 28, 2025 am 10:51 AM
セサミオープンドアトレーディングプラットフォームダウンロードモバイルバージョンgateioトレーディングプラットフォームのダウンロードアドレス
Feb 28, 2025 am 10:51 AM
アプリをダウンロードしてアカウントの安全を確保するために、正式なチャネルを選択することが重要です。
 gate.io交換公式登録ポータル
Feb 20, 2025 pm 04:27 PM
gate.io交換公式登録ポータル
Feb 20, 2025 pm 04:27 PM
Gate.ioは、幅広い暗号資産と取引ペアを提供する主要な暗号通貨交換です。 gate.ioの登録は非常に簡単です。公式ウェブサイトにアクセスするか、「登録」をクリックし、登録フォームに入力し、電子メールを確認し、2因子検証(2FA)を設定する必要があります。登録を完了します。 gate.ioを使用すると、ユーザーは安全で便利な暗号通貨取引体験を楽しむことができます。
 Binance Binance公式Webサイト最新バージョンログインポータル
Feb 21, 2025 pm 05:42 PM
Binance Binance公式Webサイト最新バージョンログインポータル
Feb 21, 2025 pm 05:42 PM
Binance Webサイトログインポータルの最新バージョンにアクセスするには、これらの簡単な手順に従ってください。公式ウェブサイトに移動し、右上隅の[ログイン]ボタンをクリックします。既存のログインメソッドを選択してください。「登録」してください。登録済みの携帯電話番号または電子メールとパスワードを入力し、認証を完了します(モバイル検証コードやGoogle Authenticatorなど)。検証が成功した後、Binance公式WebサイトLogin Portalの最新バージョンにアクセスできます。
