

深度推定 SOTA!自動運転のための単眼とサラウンド深度の適応的融合

以前書いた&個人的な理解
マルチビュー深度推定は、さまざまなベンチマークテストで高いパフォーマンスを達成しました。ただし、現在のほぼすべてのマルチビュー システムは、特定の理想的なカメラの姿勢に依存しており、自動運転などの現実世界の多くのシナリオでは利用できません。この研究では、さまざまなノイズの多い姿勢設定の下で深度推定システムを評価するための新しい堅牢性ベンチマークを提案します。驚くべきことに、現在のマルチビュー深度推定方法またはシングルビューとマルチビューの融合方法は、ノイズの多いポーズ設定が与えられると失敗することがわかりました。この課題に対処するために、ここでは、信頼性の高いマルチビューとシングルビューの結果を適応的に統合してロバストで正確な深度推定を実現する、シングルビューとマルチビューの融合深度推定システムである AFNet を提案します。適応融合モジュールは、パーセル信頼度マップに基づいて 2 つのブランチ間の信頼度の高い領域を動的に選択することによって融合を実行します。したがって、テクスチャのないシーン、不正確なキャリブレーション、動的オブジェクト、その他の劣化または困難な条件に直面した場合、システムはより信頼性の高いブランチを選択する傾向があります。堅牢性テストでは、この方法は最先端のマルチビューおよびフュージョン方法を上回ります。さらに、最先端のパフォーマンスが、困難なベンチマーク (KITTI および DDAD) で達成されます。
論文リンク: https://arxiv.org/pdf/2403.07535.pdf
論文名: 自動運転のためのシングルビューとマルチビューの深度の適応的融合
分野の背景
画像深度推定は、コンピューター ビジョンの分野において常に課題であり、幅広い用途があります。ビジョンベースの自動運転システムでは、奥行き認識が鍵となり、道路上の物体を理解し、環境の 3D マップを構築するのに役立ちます。さまざまな視覚的な問題にディープ ニューラル ネットワークが適用されるにつれ、畳み込みニューラル ネットワーク (CNN) に基づく方法が深度推定タスクの主流になりました。
入力形式に応じて、主にマルチビュー深度推定とシングルビュー深度推定に分けられます。深度を推定するためのマルチビュー手法の背後にある仮定は、正しい深度、カメラのキャリブレーション、およびカメラのポーズが与えられた場合、ビュー全体のピクセルが類似しているはずであるということです。彼らはエピポーラ幾何学に依存して高品質の深さ測定を三角測量します。ただし、マルチビュー手法の精度と堅牢性は、カメラの幾何学的構成とビュー間の対応するマッチングに大きく依存します。まず、カメラは三角測量を可能にするために十分に平行移動する必要があります。自動運転シナリオでは、自車が信号で停止したり、前進せずに曲がったりする可能性があり、三角測量が失敗する可能性があります。さらに、マルチビュー手法には、自動運転シナリオでよく見られる動的ターゲットとテクスチャのない領域の問題があります。もう 1 つの問題は、移動車両における SLAM 姿勢の最適化です。既存の SLAM 方式では、困難で避けられない状況は言うまでもなく、ノイズは避けられません。たとえば、ロボットや自動運転車は再調整なしで何年も配備される可能性があり、その結果、ポーズに騒音が発生する可能性があります。対照的に、シングルビュー手法はシーンの意味的理解と透視投影キューに依存するため、テクスチャのない領域や動的オブジェクトに対してより堅牢であり、カメラのポーズに依存しません。ただし、スケールが曖昧であるため、そのパフォーマンスは依然としてマルチビュー方式に比べてはるかに遅れています。ここでは、自動運転シナリオで堅牢かつ正確な単眼ビデオ深度推定を行うために、これら 2 つの方法の利点をうまく組み合わせることができるかどうかを検討する傾向があります。
AFNet ネットワーク構造
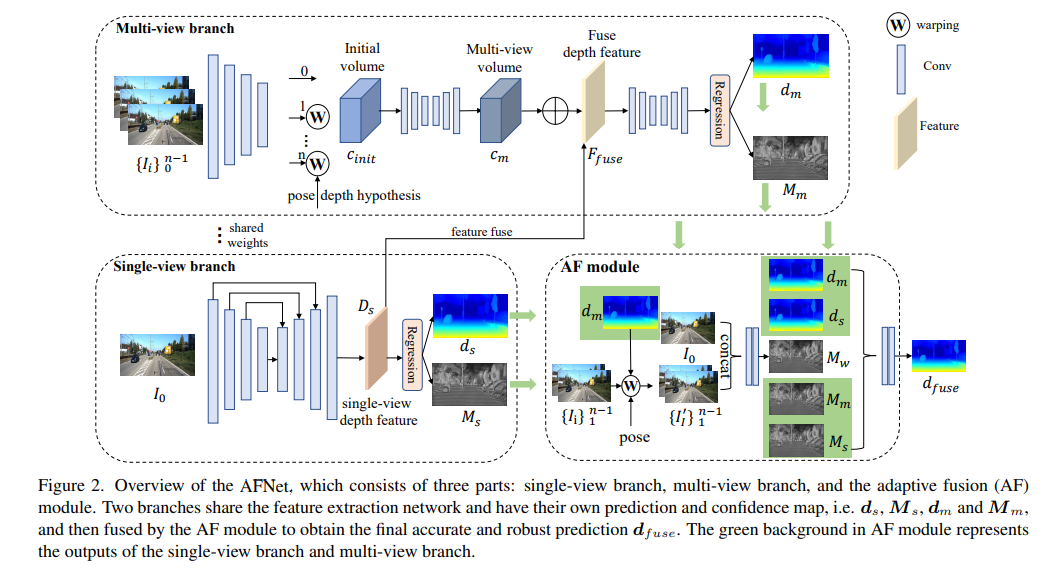
AFNet の構造は次のとおりで、シングルビュー ブランチ、マルチビュー ブランチ、アダプティブ フュージョン (AF) モジュールの 3 つの部分で構成されます。 2 つのブランチは特徴抽出ネットワークを共有し、独自の予測マップと信頼マップ (つまり、 、 、および ) を持ち、AF モジュールによって融合されて、最終的な正確でロバストな予測が得られます。AF モジュールの緑色の背景は、単一のブランチを表します。 -view ブランチとマルチビュー ブランチの出力。
損失関数:

シングルビューおよびマルチビュー深度モジュール
バックボーン特徴をマージし、深い特徴 D を取得するために、AFNet はマルチスケール デコーダーを構築します。このプロセスでは、Ds の最初の 256 チャネルに対してソフトマックス演算が実行され、深度確率ボリューム Ps が取得されます。深度特徴の最後のチャネルは、単一ビューの深度信頼度マップとして使用されます。最後に、単一ビューの深度がソフト重み付けによって計算されます。
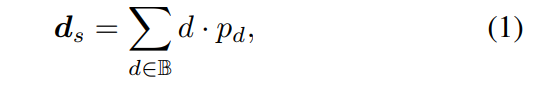
マルチビュー ブランチ
マルチビュー ブランチは、シングルビュー ブランチとバックボーンを共有して、参照画像とソース画像。デコンボリューションを採用して、低解像度の特徴を 4 分の 1 の解像度にデコンボリューションし、それらをコスト ボリュームの構築に使用される最初の 4 分の 1 の特徴と組み合わせます。フィーチャ ボリュームは、ソース フィーチャを仮想平面にラップし、その後に参照カメラを配置することによって形成されます。あまり多くの情報を必要としない堅牢なマッチングの場合、特徴のチャネル次元が計算で保持され、4D コスト ボリュームが構築され、2 つの 3D 畳み込み層によってチャネル数が 1 に減ります。
深度仮説のサンプリング方法はシングルビュー ブランチと一致していますが、サンプル数は 128 のみです。その後、スタックされた 2D 砂時計ネットワークを使用して正則化され、最終的なマルチビュー コストが取得されます。音量。シングルビュー特徴の豊富な意味情報とコスト正則化によって失われた詳細を補うために、残差構造を使用してシングルビュー深度特徴 Ds とコスト ボリュームを組み合わせて、次のように融合深度特徴を取得します。
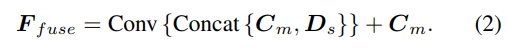
アダプティブ フュージョン モジュール
最終的に正確でロバストな予測を取得するために、AF モジュールは次の値の間で最適な値を適応的に選択するように設計されています。図 2 に示すように、正確な深度が最終出力として使用されます。融合マッピングは 3 つの信頼度を通じて実行され、そのうちの 2 つは 2 つのブランチによってそれぞれ生成された信頼度マップ Ms と Mm であり、最も重要なものは、マルチビュー ブランチの予測が正しいかどうかを決定するためにフォワード ラッピングによって生成された信頼度マップ Mw です。信頼性のある。 。実験結果
DDAD (Dense Depth for Autonomous Driving) は、困難で多様な都市条件の推定における高密度深度の新しい自動運転ベンチマークです。これは 6 台の同期カメラによってキャプチャされ、高密度 LIDAR によって生成された正確な地表深度 (360 度の視野全体) が含まれています。解像度 1936×1216 の単一カメラ ビューに 12650 のトレーニング サンプルと 3950 の検証サンプルがあります。 6 台のカメラからのすべてのデータはトレーニングとテストに使用されます。 KITTI データセットは、移動中の車両で撮影された屋外シーンの立体画像と、対応する 3D レーザー スキャンを提供します (解像度は約 1241 × 376)。
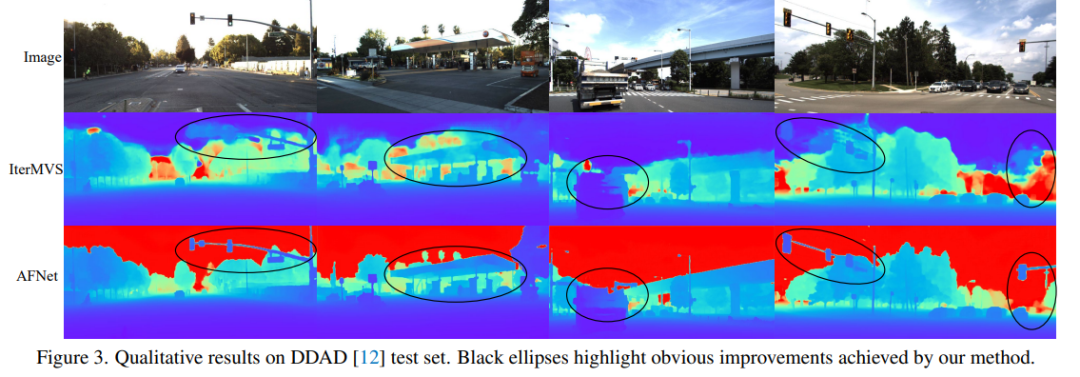
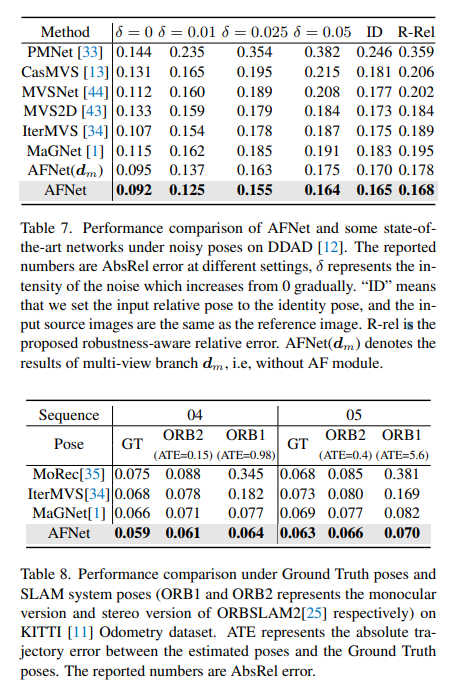
DDADとKITTIの評価結果の比較。 * はオープン ソース コードを使用して複製された結果を示しており、その他の報告された数値は対応する元の論文からのものであることに注意してください。
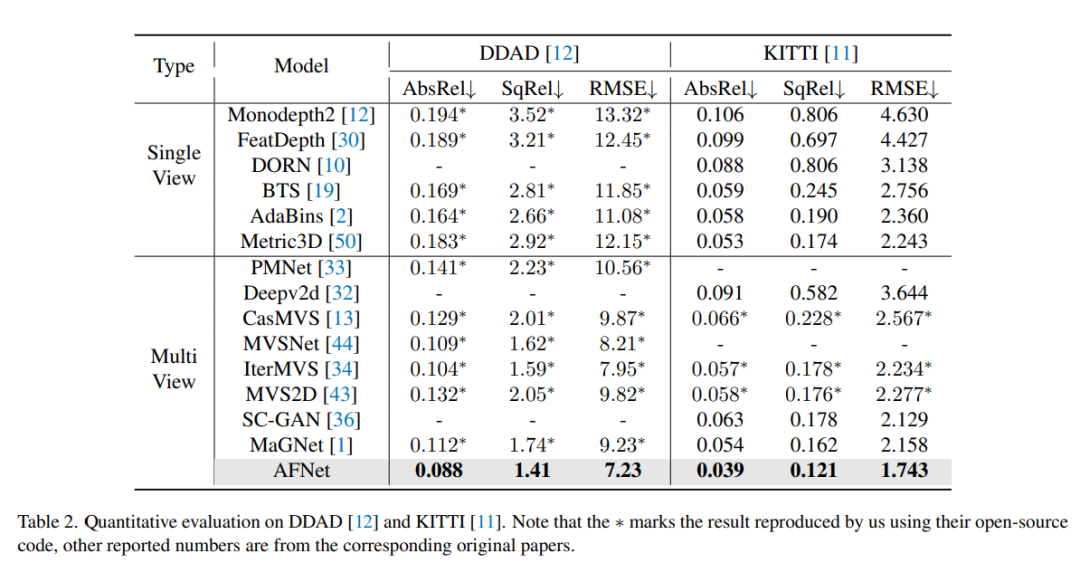
DDAD のメソッドにおける各戦略のアブレーション実験結果。 Singleはシングルビュー分岐予測の結果を表し、Multi-はマルチビュー分岐予測の結果を表し、Fuseは融合結果dfuseを表す。
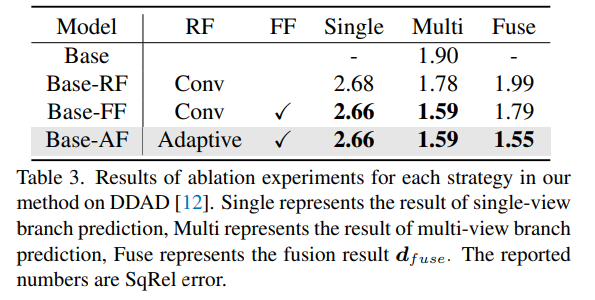
#ネットワークパラメータを共有し、アブレーション結果の特徴抽出のための一致情報を抽出する方法。
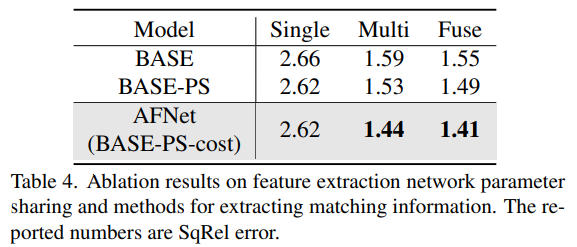
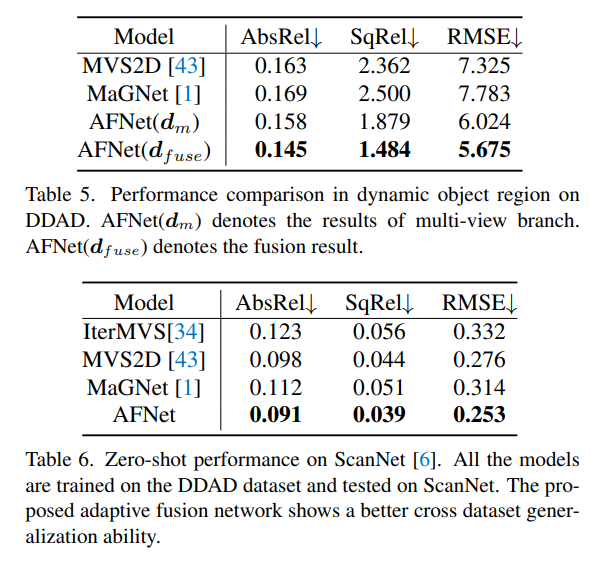

以上が深度推定 SOTA!自動運転のための単眼とサラウンド深度の適応的融合の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 CUDA の汎用行列乗算: 入門から習熟まで!
Mar 25, 2024 pm 12:30 PM
CUDA の汎用行列乗算: 入門から習熟まで!
Mar 25, 2024 pm 12:30 PM
General Matrix Multiplication (GEMM) は、多くのアプリケーションやアルゴリズムの重要な部分であり、コンピューター ハードウェアのパフォーマンスを評価するための重要な指標の 1 つでもあります。 GEMM の実装に関する徹底的な調査と最適化は、ハイ パフォーマンス コンピューティングとソフトウェア システムとハードウェア システムの関係をより深く理解するのに役立ちます。コンピューター サイエンスでは、GEMM を効果的に最適化すると、計算速度が向上し、リソースが節約されます。これは、コンピューター システムの全体的なパフォーマンスを向上させるために非常に重要です。 GEMM の動作原理と最適化方法を深く理解することは、最新のコンピューティング ハードウェアの可能性をより有効に活用し、さまざまな複雑なコンピューティング タスクに対してより効率的なソリューションを提供するのに役立ちます。 GEMMのパフォーマンスを最適化することで
 ファーウェイのQiankun ADS3.0インテリジェント運転システムは8月に発売され、初めてXiangjie S9に搭載される
Jul 30, 2024 pm 02:17 PM
ファーウェイのQiankun ADS3.0インテリジェント運転システムは8月に発売され、初めてXiangjie S9に搭載される
Jul 30, 2024 pm 02:17 PM
7月29日、AITO Wenjieの40万台目の新車のロールオフ式典に、ファーウェイの常務取締役、ターミナルBG会長、スマートカーソリューションBU会長のYu Chengdong氏が出席し、スピーチを行い、Wenjieシリーズモデルの発売を発表した。 8月にHuawei Qiankun ADS 3.0バージョンが発売され、8月から9月にかけて順次アップグレードが行われる予定です。 8月6日に発売されるXiangjie S9には、ファーウェイのADS3.0インテリジェント運転システムが初搭載される。 LiDARの支援により、Huawei Qiankun ADS3.0バージョンはインテリジェント運転機能を大幅に向上させ、エンドツーエンドの統合機能を備え、GOD(一般障害物識別)/PDP(予測)の新しいエンドツーエンドアーキテクチャを採用します。意思決定と制御)、駐車スペースから駐車スペースまでのスマート運転のNCA機能の提供、CAS3.0のアップグレード
 Apple 16 システムのどのバージョンが最適ですか?
Mar 08, 2024 pm 05:16 PM
Apple 16 システムのどのバージョンが最適ですか?
Mar 08, 2024 pm 05:16 PM
Apple 16 システムの最適なバージョンは iOS16.1.4 です。iOS16 システムの最適なバージョンは人によって異なります。日常の使用体験における追加と改善も多くのユーザーから賞賛されています。 Apple 16 システムの最適なバージョンはどれですか? 回答: iOS16.1.4 iOS 16 システムの最適なバージョンは人によって異なる場合があります。公開情報によると、2022 年にリリースされた iOS16 は非常に安定していてパフォーマンスの高いバージョンであると考えられており、ユーザーはその全体的なエクスペリエンスに非常に満足しています。また、iOS16では新機能の追加や日常の使用感の向上も多くのユーザーからご好評をいただいております。特に最新のバッテリー寿命、信号性能、加熱制御に関して、ユーザーからのフィードバックは比較的好評です。ただし、iPhone14を考慮すると、
 常に新しい! Huawei Mate60シリーズがHarmonyOS 4.2にアップグレード:AIクラウドの強化、Xiaoyi方言はとても使いやすい
Jun 02, 2024 pm 02:58 PM
常に新しい! Huawei Mate60シリーズがHarmonyOS 4.2にアップグレード:AIクラウドの強化、Xiaoyi方言はとても使いやすい
Jun 02, 2024 pm 02:58 PM
4月11日、ファーウェイはHarmonyOS 4.2 100台のアップグレード計画を初めて正式に発表し、今回は携帯電話、タブレット、時計、ヘッドフォン、スマートスクリーンなどのデバイスを含む180台以上のデバイスがアップグレードに参加する予定だ。先月、HarmonyOS4.2 100台アップグレード計画の着実な進捗に伴い、Huawei Pocket2、Huawei MateX5シリーズ、nova12シリーズ、Huawei Puraシリーズなどの多くの人気モデルもアップグレードと適応を開始しました。 HarmonyOS によってもたらされる共通の、そして多くの場合新しい体験を楽しむことができる Huawei モデルのユーザーが増えることになります。ユーザーのフィードバックから判断すると、HarmonyOS4.2にアップグレードした後、Huawei Mate60シリーズモデルのエクスペリエンスがあらゆる面で向上しました。特にファーウェイM
 コンピュータのオペレーティング システムとは何ですか?
Jan 12, 2024 pm 03:12 PM
コンピュータのオペレーティング システムとは何ですか?
Jan 12, 2024 pm 03:12 PM
コンピュータ オペレーティング システムは、コンピュータ ハードウェアとソフトウェア プログラムを管理するために使用されるシステムです。また、すべてのソフトウェア システムに基づいて開発されたオペレーティング システム プログラムでもあります。オペレーティング システムが異なれば、ユーザーも異なります。では、コンピュータ システムとは何でしょうか?以下では、編集者がコンピューターのオペレーティング システムとは何かについて説明します。いわゆるオペレーティング システムはコンピュータのハードウェアとソフトウェア プログラムを管理するもので、すべてのソフトウェアはオペレーティング システム プログラムに基づいて開発されます。実際、OSには産業用、商業用、個人用など多くの種類があり、幅広い用途に対応しています。以下では、編集者がコンピューターのオペレーティングシステムとは何かについて説明します。 Windows システムとはどのようなコンピュータのオペレーティング システムですか? Windows システムは、米国 Microsoft Corporation によって開発されたオペレーティング システムです。ほとんどよりも
 Oracleデータベースのシステム日付を変更する方法の詳細な説明
Mar 09, 2024 am 10:21 AM
Oracleデータベースのシステム日付を変更する方法の詳細な説明
Mar 09, 2024 am 10:21 AM
Oracle データベースでのシステム日付の変更方法の詳細説明 Oracle データベースでのシステム日付の変更方法は、主に NLS_DATE_FORMAT パラメータの変更と SYSDATE 関数の使用です。この記事では、読者が Oracle データベースのシステム日付を変更する操作をよりよく理解し、習得できるように、これら 2 つの方法とその具体的なコード例を詳しく紹介します。 1. NLS_DATE_FORMAT パラメータメソッドの変更 NLS_DATE_FORMAT は Oracle データです
 Linux と Windows システムにおける cmd コマンドの相違点と類似点
Mar 15, 2024 am 08:12 AM
Linux と Windows システムにおける cmd コマンドの相違点と類似点
Mar 15, 2024 am 08:12 AM
Linux と Windows は 2 つの一般的なオペレーティング システムで、それぞれオープン ソースの Linux システムと商用 Windows システムを表します。どちらのオペレーティング システムにも、ユーザーがオペレーティング システムと対話するためのコマンド ライン インターフェイスがあります。 Linux システムでは、ユーザーはシェル コマンド ラインを使用しますが、Windows システムでは、cmd コマンド ラインを使用します。 Linux システムのシェル コマンド ラインは、ほぼすべてのシステム管理タスクを完了できる非常に強力なツールです。
 システムフォントの保存パスはどこですか?
Feb 19, 2024 pm 09:11 PM
システムフォントの保存パスはどこですか?
Feb 19, 2024 pm 09:11 PM
システム フォントはどのフォルダーにありますか? 現代のコンピューター システムでは、フォントは重要な役割を果たし、読書体験やテキスト表現の美しさに影響を与えます。パーソナライズやカスタマイズに熱心な一部のユーザーにとって、システム フォントの保存場所を理解することが特に重要です。では、システムフォントはどのフォルダーに保存されているのでしょうか?この記事では、それらを皆さんに一つずつ明らかにしていきます。 Windows オペレーティング システムでは、システム フォントは「Fonts」というフォルダーに保存されます。このフォルダーは、デフォルトでは Win C ドライブにあります。
