

ビッグデータAI統合解釈

1. AI の「iPhone」の瞬間
過去 1 年間で、大規模なモデルの開発が非常に急速に進み、コンピューティング能力とデータが作成したモデルには、いくつかの一般的な構造と質問に答える機能があり、人々を常に夢見てきた人工知能の段階に導きます。たとえば、大規模な言語モデルとチャットしているとき、鈍いロボットではなく、生身の人間に直面しているように感じるでしょう。それは私たちの想像力の余地をさらに広げます。元来の人間とコンピュータの対話では、キーボードとマウスを使用して、いくつかのフォーマット方法で命令をマシンに伝える必要がありました。現在、人々は言語を通じてコンピューターと対話することができ、マシンは私たちの意味を理解し、応答することができます。
この傾向に追いつくために、多くのテクノロジー企業は大規模モデルの研究に注力し始めています。 iPhone の発売がモバイル インターネットの新時代を切り開いたのと同じように、2023 年は人工知能元年とみなされます。今回の真のブレークスルーは、大規模なコンピューティング能力と大量のデータの応用にあります。
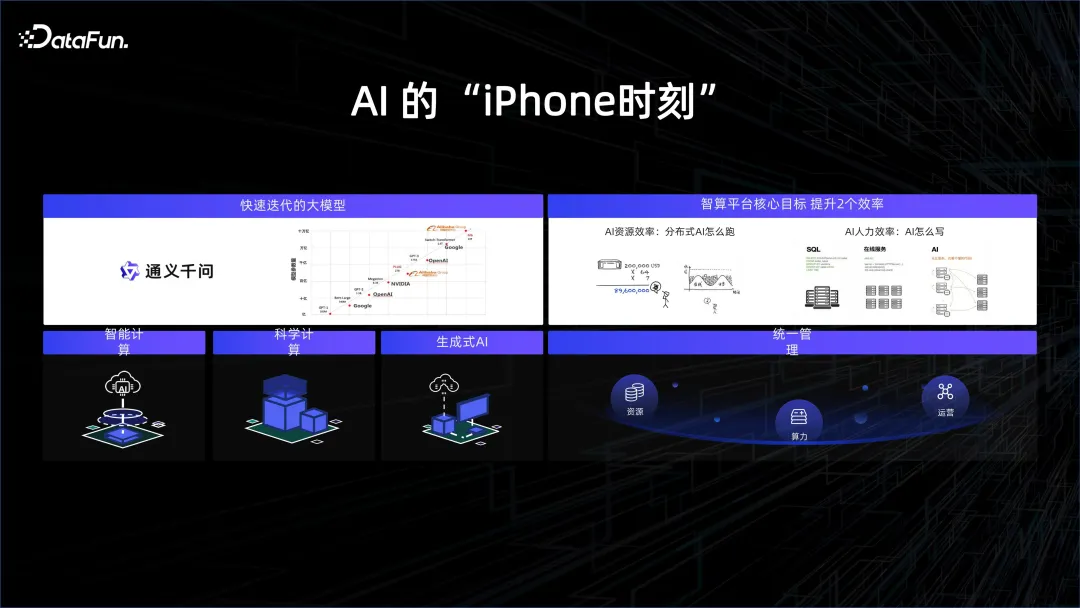
モデル構造の観点から見ると、Transformer 構造は実際には長い間導入されてきました。実際、GPT モデルは Bert モデルより 1 年早く発表されました。しかし、当時の計算能力の限界により、GPT は Bert よりも効果がはるかに低かったため、Bert が最初に普及し、翻訳に使用されました。非常に良い結果が得られました。しかし、今年の焦点は GPT です。その背後にある理由は、非常に高いコンピューティング能力のためです。ハードウェア メーカーの努力と、パッケージングとストレージ粒子の進歩により、私たちは非常に高いコンピューティング能力を使用できるようになりました。これらを組み合わせることで、より多くのデータの深い理解を促進し、AI に画期的な結果をもたらします。基礎となるプラットフォームの強力なサポートに基づいて、アルゴリズムの学習者はモデルをより便利かつ効率的に開発および反復し、迅速なモデルの進化を促進できます。
#2. モデル開発パラダイム
一般モデル開発サイクルは次の図に示されています。
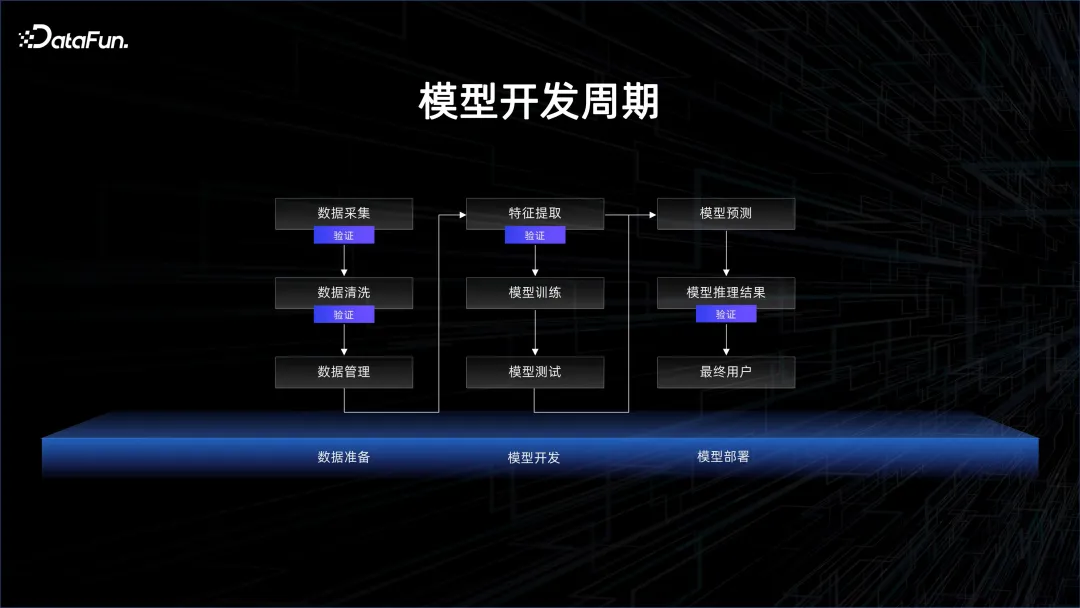
#多くの人は、モデルのトレーニングが最も重要なステップであると考えています。しかし実際には、モデルのトレーニングの前に、収集、クリーニング、管理する必要がある大量のデータがあります。このプロセスでは、ダーティ データが存在するかどうか、データの統計的分布が代表的であるかどうかなど、検証する必要がある手順が多数あることがわかります。モデルが世に出た後は、テストと検証が必要ですが、これはデータの検証でもあり、データはモデルの有効性をフィードバックするために使用されます。

より優れた機械学習は 80% のデータと 20% のモデルで構成されており、データに重点を置く必要があります。
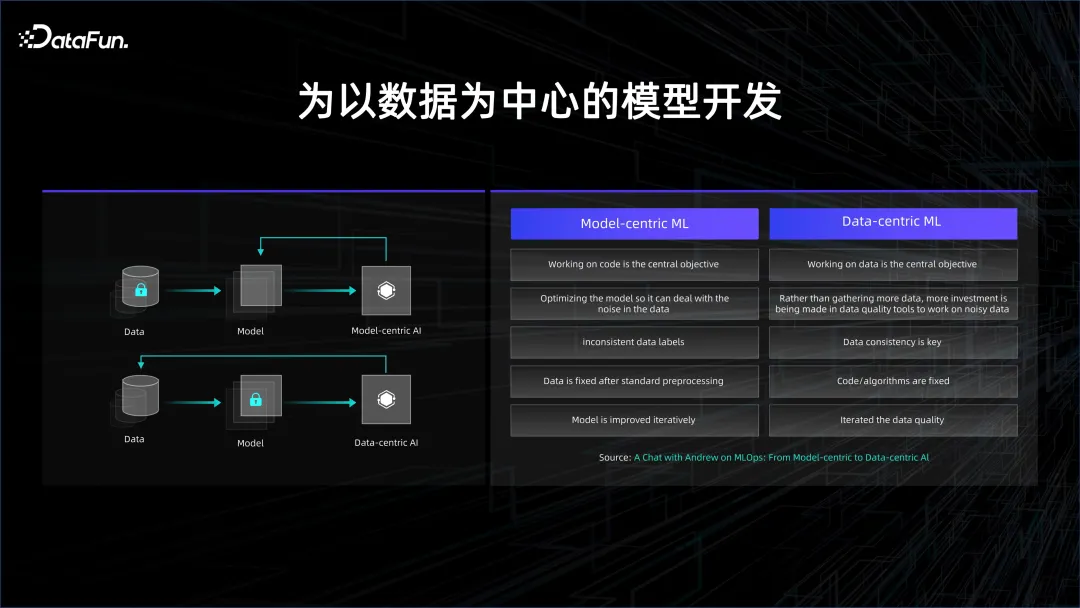
これは、モデル開発の進化傾向も反映しています。元のモデル開発はモデル中心でしたが、現在はデータ中心になっています。
ディープラーニングの初期の頃は、教師あり学習が主な焦点であり、最も重要なことはデータにラベルを付けることでした。ラベル付きデータは 2 つのカテゴリに分類され、1 つはトレーニング データ、もう 1 つは検証データです。トレーニング データを使用してモデルをトレーニングし、モデルがテスト データで良好な結果を出せるかどうかを検証します。データにラベルを付けるには人が必要なため、データにラベルを付けるコストは非常に高くなります。モデルの効果を向上させたい場合は、モデルの構造に多くの時間と労力を費やし、構造の変更を通じてモデルの汎化能力を向上させ、モデルの過剰適合を減らす必要があります。中心的な開発パラダイム。
データとコンピューティング能力の蓄積に伴い、教師なし学習が徐々に使用され始めており、大量のデータを通じて、モデルはデータ内に存在する関係性を自律的に発見できます。データ中心の開発パラダイムの到来。
データ中心の開発モデルでは、モデルの構造が似ており、基本的には Transformer のスタックであるため、データの活用方法により注意が払われます。データを使用するプロセスでは、大量のデータが必要となるため、多くのデータのクリーニングと比較が発生し、時間がかかります。データを正確に制御する方法によって、モデルの収束と反復の速度が決まります。
##3. ビッグ データ AI の統合
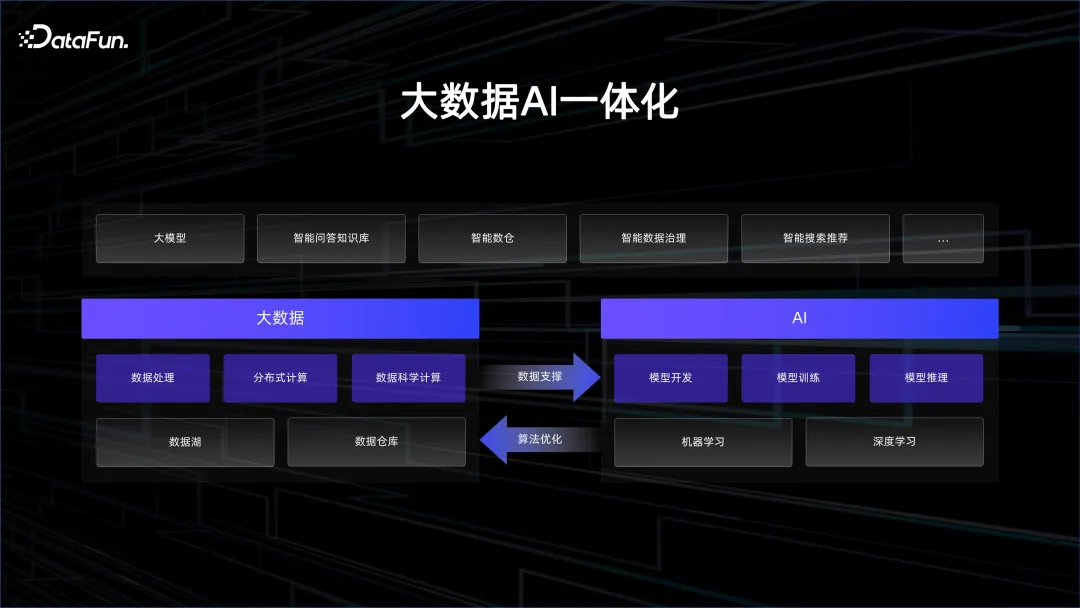
1 . ビッグデータ AI パノラマ

Alibaba Cloud は、AI とビッグデータの統合を常に重視してきました。そのため、当社は、高性能 AI コンピューティング能力を提供する高帯域幅 GPU クラスターや、コスト効率の高いストレージとデータ管理機能を提供する CPU クラスターなど、非常に優れたインフラストラクチャを備えたプラットフォームを構築しました。これに加えて、ビッグデータ プラットフォーム、AI プラットフォーム、ハイコンピューティング パワー プラットフォーム、クラウドネイティブ プラットフォームなどを含むビッグデータと AI の統合 PaaS プラットフォームを構築しました。エンジン部分には、ストリーミング コンピューティング、ビッグ データ オフライン コンピューティング MaxCompute、および PAI が含まれます。
サービス層には、大規模モデル アプリケーション プラットフォーム Bailian とオープンソース モデル コミュニティ ModelScope があります。アリババはモデル コミュニティの共有を積極的に推進しており、Model as a Service の概念を利用して、より多くのユーザーに AI ニーズを刺激し、これらのモデルの基本機能を使用して AI アプリケーションを迅速に構築することを望んでいます。
2. ビッグデータと AI の連携が必要な理由
ビッグデータと AI の連携がなぜ必要なのかを、以下の 2 つの事例を用いて説明します。
ケース 1: ナレッジ ベースの検索が強化された大規模モデルの質問応答システム
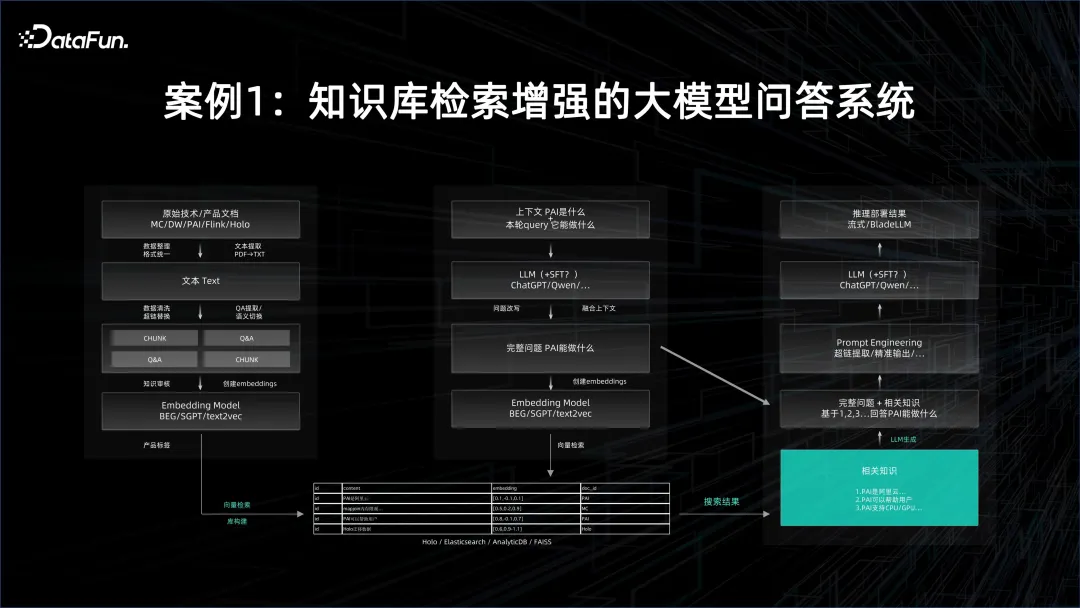
大規模モデルの質問の場合応答システムでは、まず基本モデルを使用し、次に対象文書を埋め込み、埋め込み結果をベクトル データベースに保存します。ドキュメントの数は非常に多くなる場合があるため、埋め込みにはバッチ処理機能が必要です。基本モデルの推論サービス自体も非常にリソースを大量に消費しますが、もちろん、これは基本モデルの規模と並列化の方法にも依存します。生成されたすべてのエンベディングはベクトル データベースに注がれ、クエリを実行する場合はクエリもベクトル化する必要があり、その後、ベクトル検索を通じて質問と回答に関連する可能性のある知識がベクトル データベースから抽出されます。これには、推論サービスの非常に優れたパフォーマンスが必要です。
ベクトルを抽出した後、ベクトルによって表されるドキュメントをコンテキストとして使用し、この大規模なモデルを制約し、これに基づいて質問と回答を作成する必要があります。自分で検索して得られた結果よりもはるかに優れた答えが得られ、自然言語で答えられます。
上記のプロセスでは、エンベディングを迅速に生成するためにオフラインの分散ビッグ データ プラットフォームが必要であり、プロセス全体を接続するには大規模モデルのトレーニングとサービス用の AI プラットフォームの両方が必要です。大規模なモデルの質問応答システムを形成するため。
ケース 2: インテリジェントなレコメンデーション システム
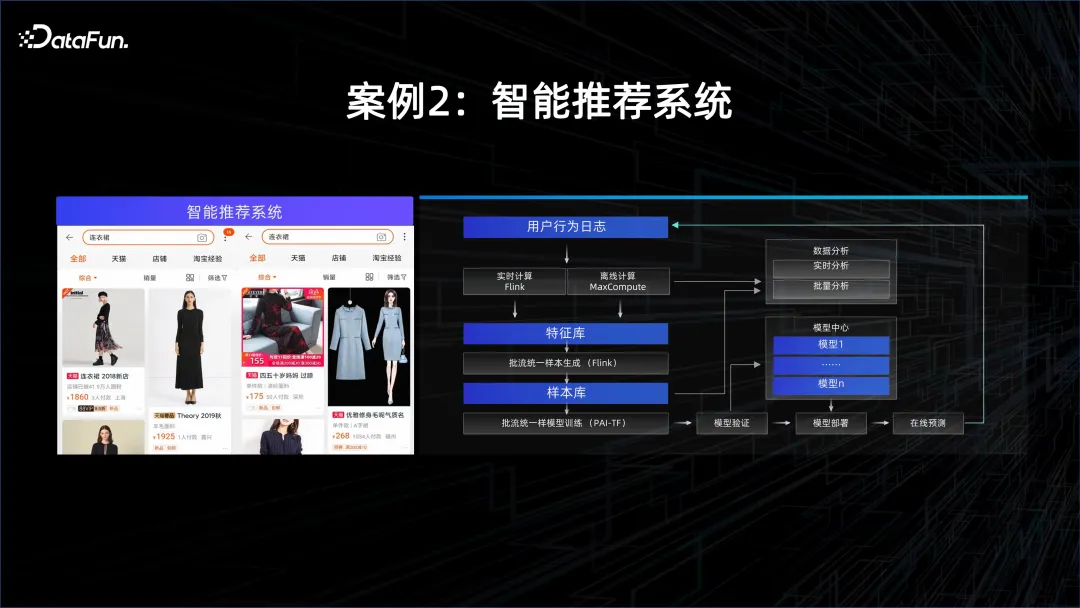
もう 1 つの例は、パーソナライズされたレコメンデーションです。このモデルは、多くの場合、高い適時性を備えています。すべての人の興味や性格は変化するため、これが必要です。これらの変化を捉えるには、ストリーミング コンピューティング システムを使用して APP で取得したデータを分析し、新しいデータが入ってくるたびに、抽出された特徴を継続的に使用してオンライン学習をモデル化する必要があります。モデルは更新され、新しいモデルを通じて顧客にサービスを提供します。したがって、このシナリオでは、モデルの提供とトレーニングの機能に加えて、ストリーミング コンピューティング機能が必要です。
3. ビッグデータと AI を組み合わせる方法
上記の事例を通じて、AI とビッグデータの組み合わせにより、は避けられない開発トレンドになります。このコンセプトに基づいて、まずビッグデータ プラットフォームと AI プラットフォームを一緒に管理できるワークスペースが必要であるという考えから、AI ワークスペースが誕生しました。
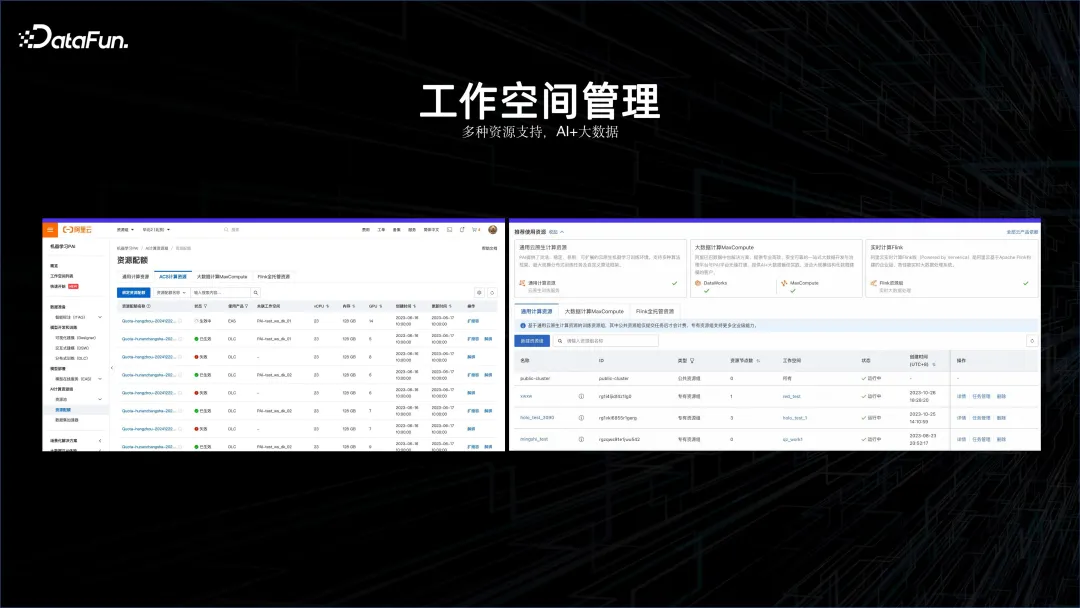
この AI ワークスペースでは、Flink クラスター、オフライン コンピューティング クラスター MaxCompute、AI プラットフォーム、コンテナー サービス コンピューティング プラットフォームなどをサポートします。
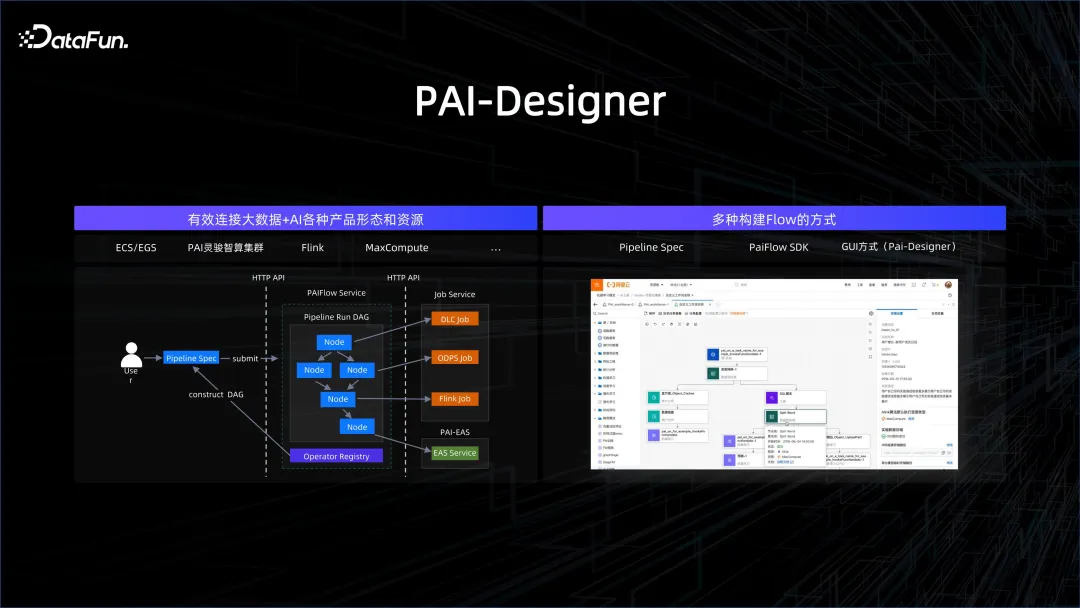
ビッグデータと AI の統合は最初のステップにすぎず、より重要なのはそれらをワークフローで接続することです。ワークフローは、SDK、グラフィカル、GUI、SPEC 作成など、さまざまな方法で確立できます。ワークフロー内のノードはビッグ データ処理ノードまたは AI 処理ノードにすることができるため、複雑なプロセスを適切に接続できます。
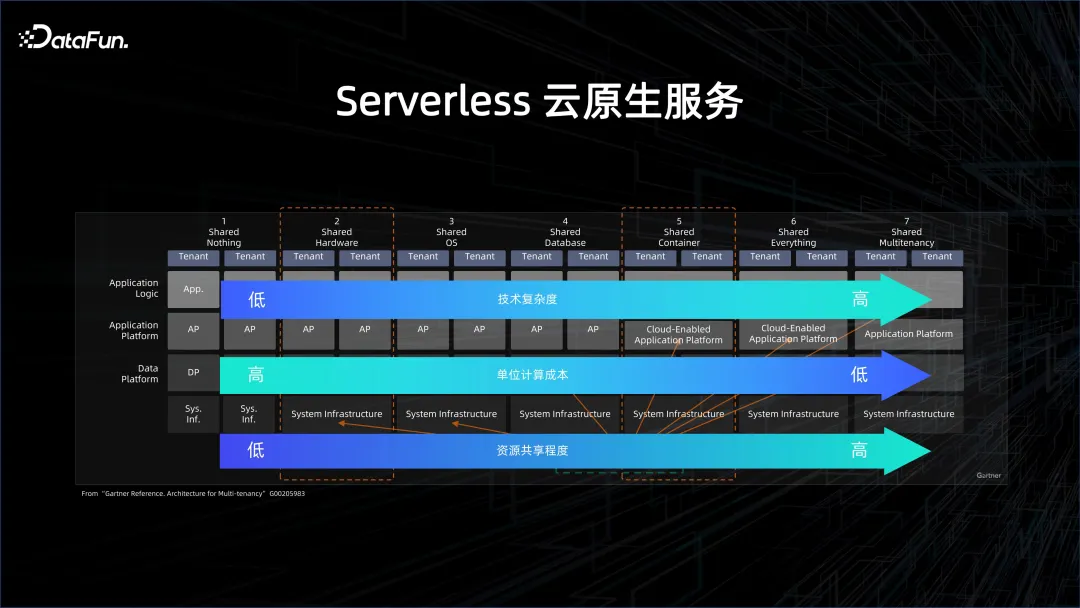
効率をさらに向上させ、コストを削減するには、サーバーレス クラウド ネイティブ サービスが必要です。 Severless とは何かについては、上の画像で詳しく説明されています。クラウド ネイティブには、何も共有しない (非クラウド アプローチ) からすべてを共有する (非常にクラウド アプローチ) まで、さまざまなレベルがあります。レベルが高くなるほど、リソース共有の度合いが高まり、コンピューティング単位のコストは低くなりますが、システムへの負荷は大きくなります。

ビッグデータとデータベースの分野は、コストの観点から、過去 2 年間でゆっくりとサーバーレスへの移行を開始しました。もともと、クラウド上のデータベースなど、クラウド上で利用されるサーバーもインスタンス化という形で存在していました。これらのインスタンスの背後には、このインスタンスが持つ CPU とコアの数などのリソースの影があります。ゆっくりと段階的にサーバーレスに移行し、最初のレベルはシングルテナント コンピューティングです。これは、クラウド上にクラスターをセットアップし、そこにビッグ データまたはデータベース プラットフォームを展開することを指します。ただし、このクラスターはシングルテナントです。つまり、物理マシンを他のユーザーと共有します。物理マシンは仮想マシンに仮想化され、ビッグ データ プラットフォームの構築に使用されます。これはシングルテナント コンピューティングと呼ばれます。テナントストレージ、シングルテナントの管理と制御。ユーザーが得られるのはクラウド上の Elastic ECS マシンですが、ビッグデータの管理と運用保守ソリューションは自分で行う必要があります。 EMR はこの点における古典的なソリューションです。
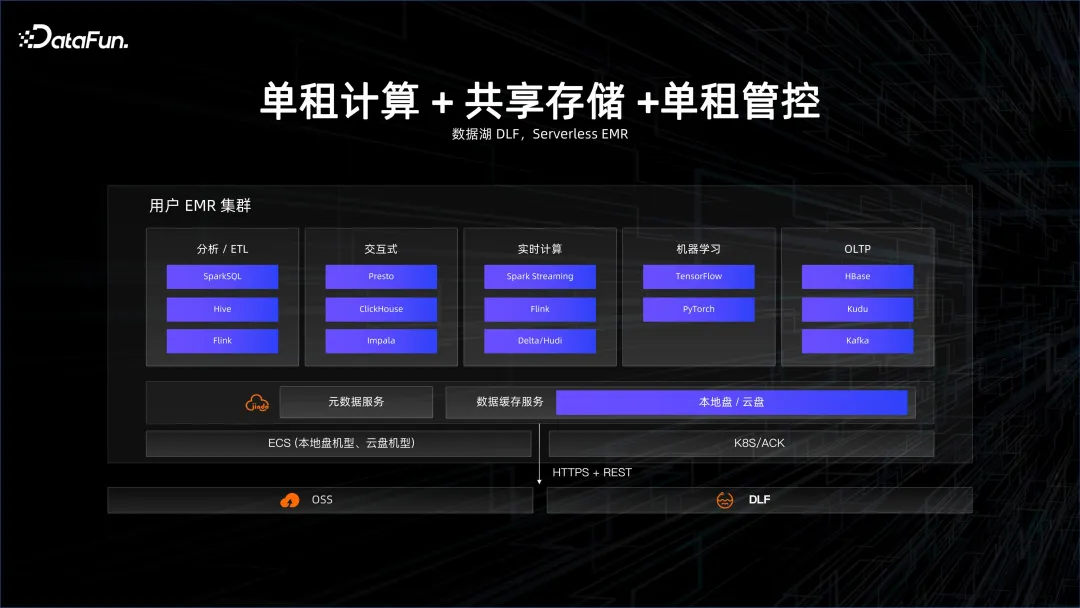
シングルテナント ストレージから、データ レイク ソリューションである共有ストレージにゆっくりと移行していきます。データは、より共有されたビッグ データ システム内にあります。計算は、クラスタを動的にプルアップすることです。計算が完了すると、クラスタは停止しますが、データは信頼できるリモートのストレージ側にあるため、データは停止しません. これは共有ストレージです。代表的なものは、データ レイク DLF とサーバーレス EMR ソリューションです。

最も極端なことは、すべてを共有することです。BigQuery または Alibaba Cloud の MaxCompute を使用すると、プロジェクト管理用のプラットフォームと仮想化が表示されます。ユーザーがクエリを提供すると、プラットフォームはクエリに基づいて請求と測定を実行します。

# これにより、多くのメリットが得られます。たとえば、ビッグ データの計算には多くのノードがあり、これらのノードは実際には結合やアグリゲータなどの組み込み演算子であるため、ユーザー コードは必要ありません。これらの決定的な結果には、比較的重いサンドボックスは必要ありません。オペレーターは厳密にテストされており、悪意のあるコードや任意の UDF コードが含まれていないため、仮想化のオーバーヘッドを排除できます。
UDF の利点は、豊富なデータを処理できる柔軟性と、データ量が大きい場合の優れた拡張性です。しかし、UDF がもたらす課題の 1 つは、セキュリティと分離の必要性です。
Google の BigQuery と MaxComputer は両方とも、すべてを共有するアーキテクチャに基づいています。テクノロジーの継続的な改善によってのみ、リソースをより緊密に使用でき、コンピューティングは人件費の節約につながると信じています。により、より多くの企業がこのデータを利用できるようになり、モデルのトレーニングでのデータの使用が促進されます。
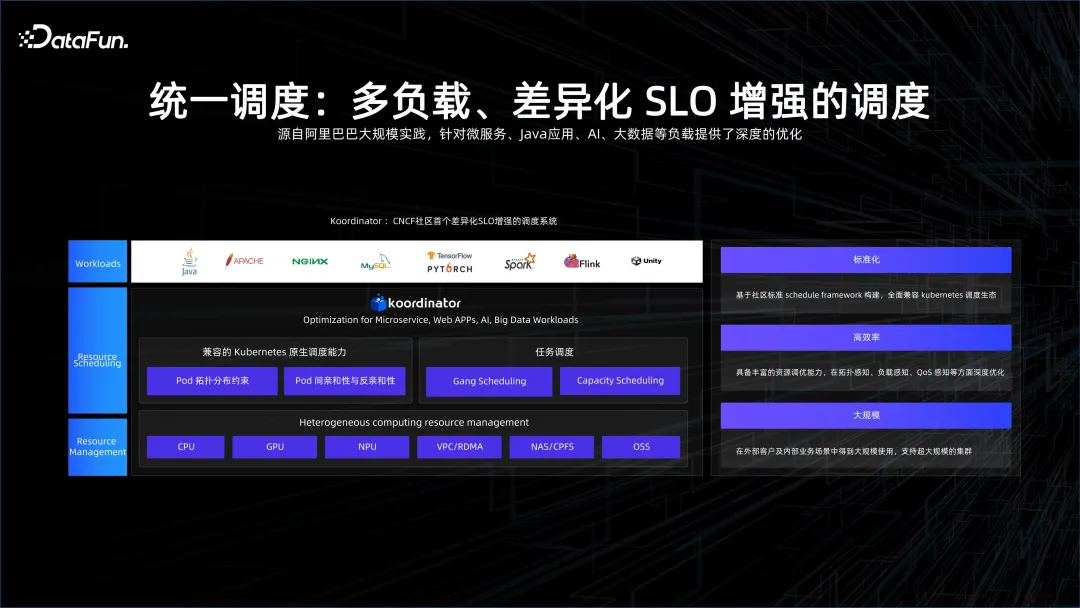
すべてを共有することで、ワークスペースを通じてビッグデータと AI を一元管理できるだけでなく、PAI を通じてそれらを接続することもできます。すべてを共有することで統一的にスケジュールを立てることも可能です。これにより、エンタープライズAIビッグデータの研究開発コストはさらに削減されます。
現時点では、やるべきことがたくさんあります。 K8S 自体のスケジューリングはマイクロサービスを指向していますが、ビッグデータのサービススケジューリングの粒度は非常に小さく、多くのタスクは数秒から数十秒しか存続しないため、ビッグデータにとって大きな課題に直面することになります。数桁増加します。私たちは主に、K8S 上でこのスケジューリング機能をスケールオフする方法を解決する必要があります。私たちが立ち上げた Koordinator オープンソース プロジェクトは、スケジューリング機能を改善し、K8S エコシステムにビッグデータと AI を統合することを目的としています。

#もう 1 つの重要なタスクは、複数レンタルのセキュリティの分離です。 K8S のサービス層と制御層にマルチテナントを実装する方法、およびネットワーク上でオーバーレイク マルチテナントを実装する方法。これにより、複数のユーザーが 1 つの K8S でサービスを受けられ、各ユーザーのデータとリソースが効率的に利用できるようになります。孤立した。
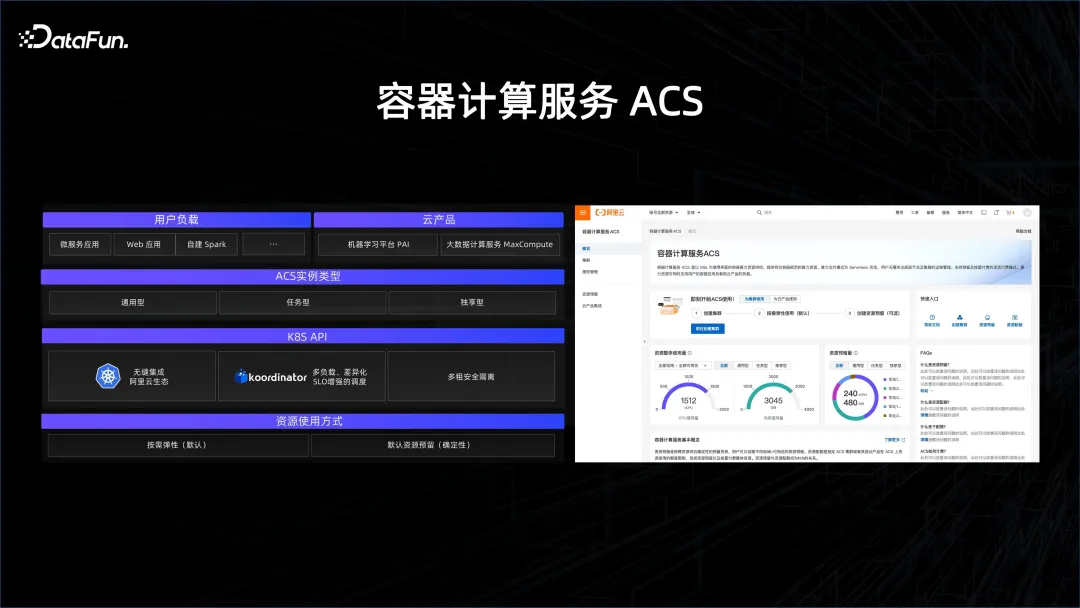
Alibaba は、ACS と呼ばれるコンテナ サービスを開始しました。これは、前に紹介した 2 つのテクノロジを使用して、コンテナ化を通じてすべてのリソースを公開します。ビッグデータプラットフォームとAIプラットフォームをシームレスに実現します。マルチテナント方式であり、ビッグデータのニーズに対応できます。ビッグデータのスケジューリング要件は、マイクロサービスや AI のスケジューリング要件よりも数桁高く、適切に実行する必要があります。これに基づいて、ACS 製品は、顧客がリソースを適切に管理できるように支援します。
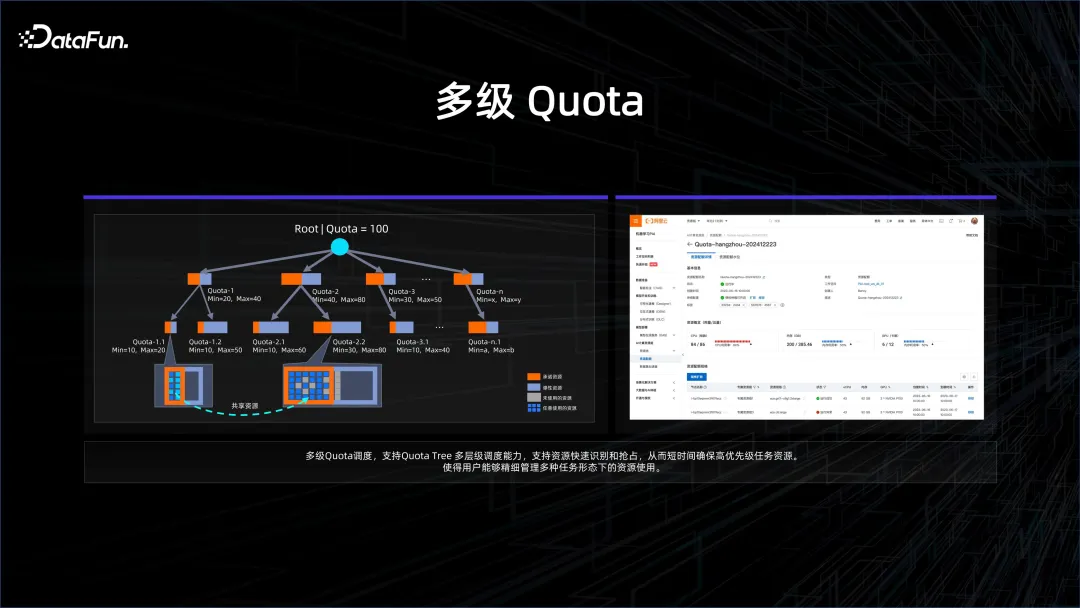
実は、AI シナリオには多くの特殊性があり、多くの場合、同期計算が必要であり、同期計算は遅延に非常に敏感であり、AI の計算密度が高く、ネットワークは非常に高いです。計算能力を確保したい場合は、データを供給して勾配情報を交換する必要があり、モデルが並列化されると、より多くのものが交換されます。このような場合、通信に欠陥がないようにするには、トポロジを意識したスケジューリングが必要です。
たとえば、モデル トレーニングの All Reduce リンクで、ランダムなスケジューリングを実行すると、クロスポート スイッチ接続が多数発生しますが、順序を細かく制御すると、クロスポートスイッチ接続は非常にクリーンになり、上位層スイッチで競合が発生しないため、遅延が十分に保証されます。
これらの最適化を行うと、パフォーマンスが大幅に向上します。 AI によるデータ プラットフォームの管理が強化される場合、これらのトポロジを意識したスケジュールをプラットフォーム全体の管理者にどのように転送するかも考慮する必要がある問題です。
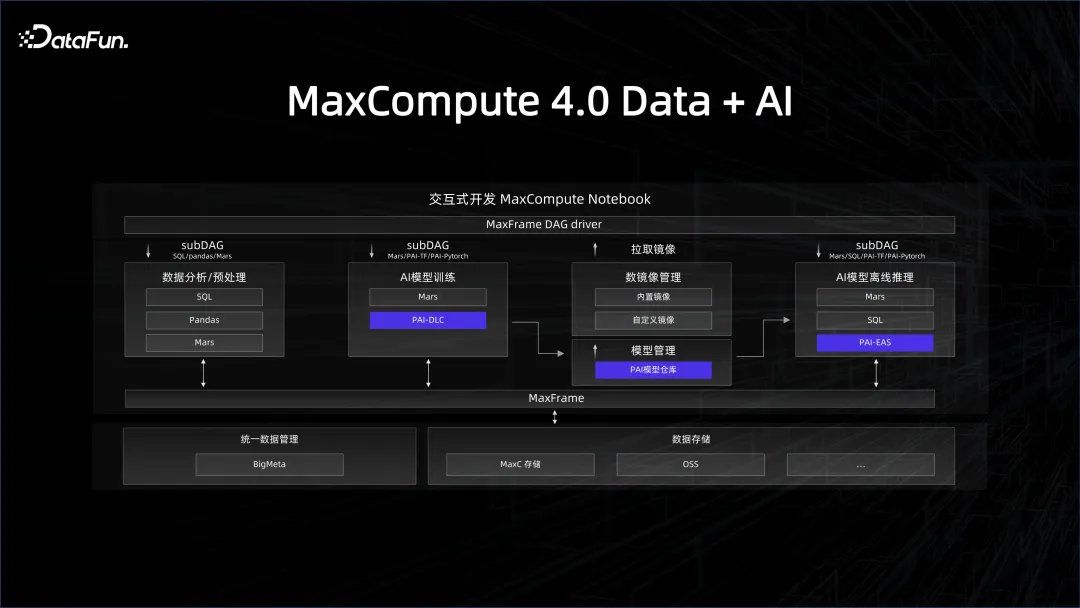
前回はリソースとプラットフォームの管理について説明しましたが、データの管理も重要です。ウェアハウス、データガバナンス、データ品質などのシステム。データ システムを AI システムに関連付けるには、データ ウェアハウスが AI に適したデータ リンクを提供する必要があります。例えばAIの開発プロセスではPythonのエコシステムが使われていますが、データ側はPython SDKを通じてこのプラットフォームをどのように利用できるのでしょうか。 Python で最も人気のあるライブラリは、pandas に似たデータ フレーム データ構造であり、ビッグ データ エンジンのクライアント側を pandas インターフェイスにパッケージ化できるため、Python に精通しているすべての AI 開発者がうまく使用できます。 。これは、私たちが今年 MaxCompute 上で立ち上げた MaxFrame フレームワークの背後にある哲学でもあります。
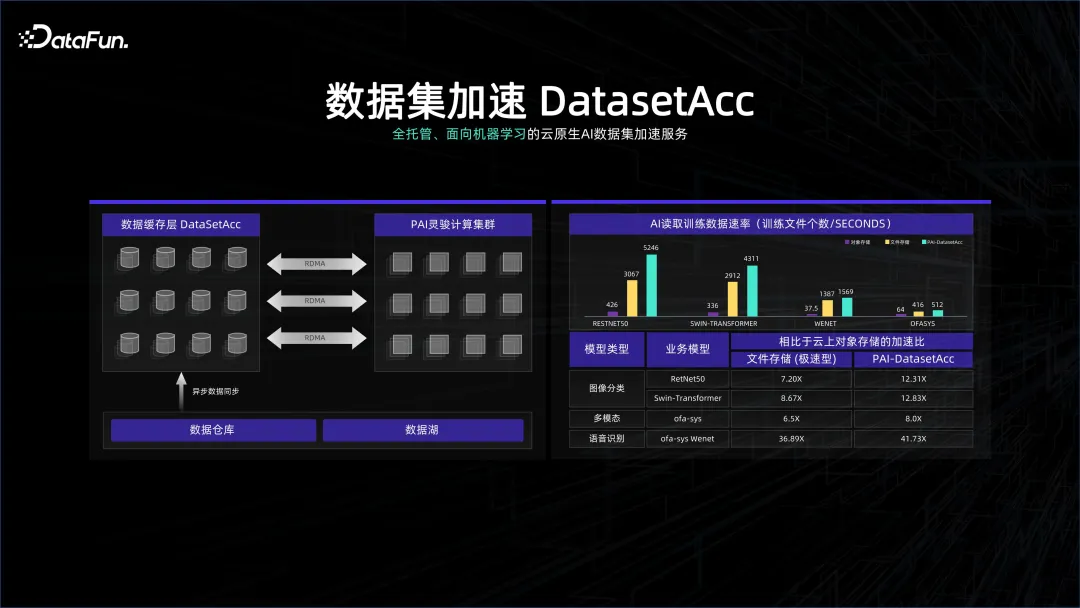
データ処理システムは多くの場合コストに非常に敏感であり、データ ウェアハウスの保存にはより高密度のストレージ システムが使用されることがあります。このシステムを無駄にしないために、多くの GPU がシステム上にデプロイされます。この高密度クラスターはネットワークと GPU に非常に要求が高く、2 つのシステムはストレージと計算から分離される可能性があります。データシステムはガバナンスや管理に偏り、コンピューティングシステムは計算に偏っている可能性があります。リモート接続方式である可能性があります。両方ともK8Sの管理下にありますが、計算中のデータの待ち時間を避けるために、 DataSetAcc は実際には、リモート ストレージ ノードのデータにシームレスに接続するデータ キャッシュであり、アルゴリズム エンジニアが計算のために舞台裏でデータをローカル メモリまたは SSD に取り込むのに役立ちます。
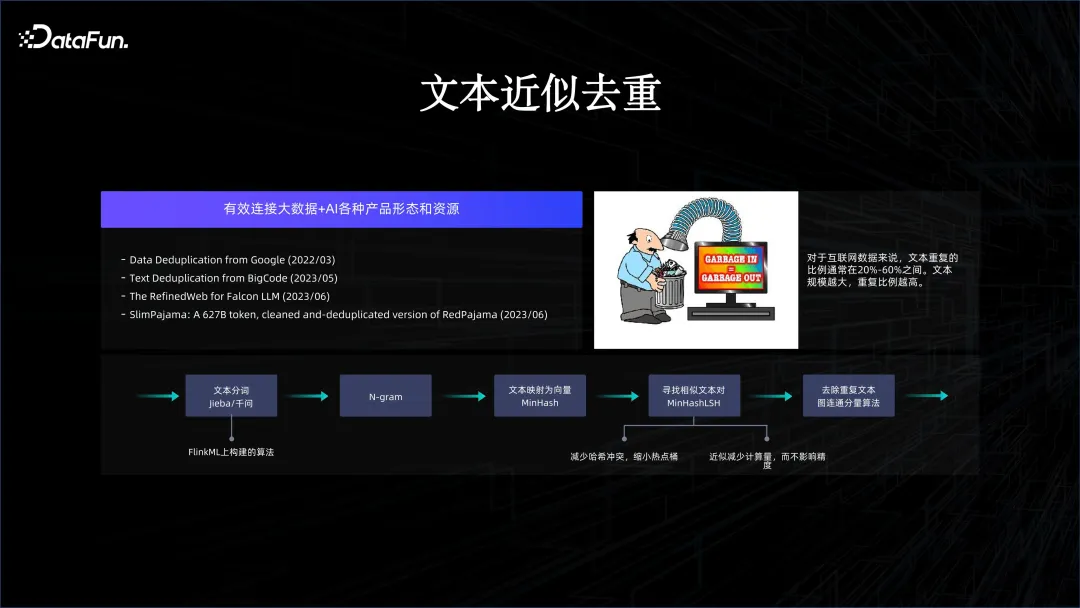
上記の方法により、AIとビッグデータプラットフォームを有機的に組み合わせることができ、イノベーションを起こすことができます。たとえば、多くの一般的なシリーズのモデル トレーニングをサポートする場合、インターネット データには多くの重複があるため、クリーンアップする必要があるデータが大量にあります。そのため、ビッグ データ システムを通じてデータの重複を排除する方法が重要です。 2 つのシステムを有機的に組み合わせているからこそ、ビッグデータ プラットフォーム上のデータのクリーンアップが容易になり、その結果をすぐにモデルのトレーニングに反映させることができます。

# 前回の記事では、ビッグデータが AI モデルのトレーニングをどのようにサポートするかを主に紹介しました。一方で、AI テクノロジーを使用してデータの洞察を支援し、BI AI データ処理モデルに移行することもできます。
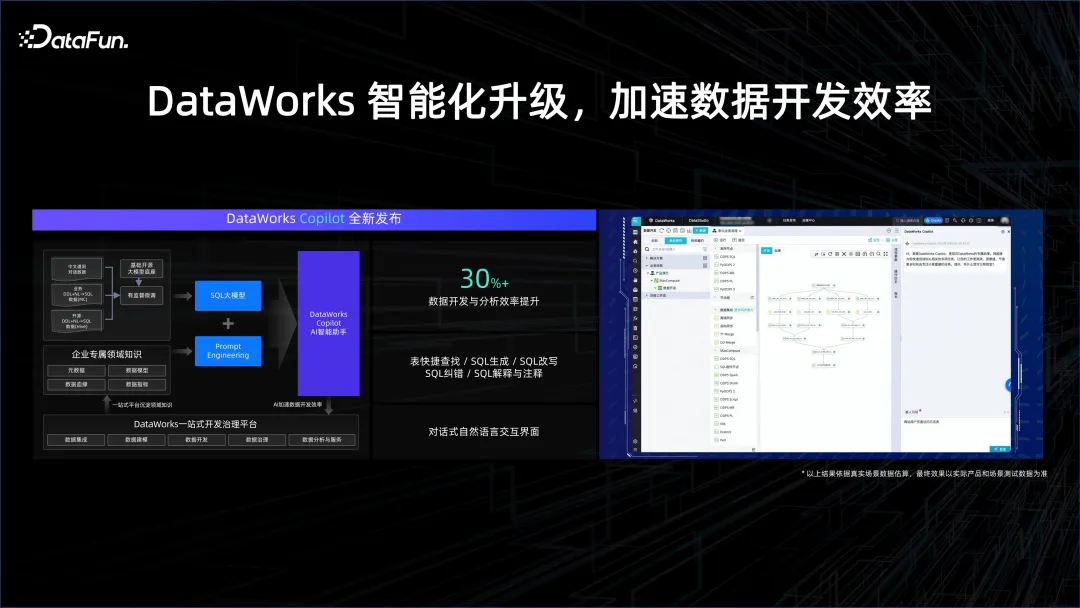
データ処理プロセスにおいて、データ アナリストがより簡単に分析を構築するのに役立ちます。本来は SQL を記述し、その使用方法を学ぶ必要があるかもしれません。ツールとデータ、相互作用するシステム。しかし、AI 時代は人間とコンピューターのやり取りの方法を変え、自然言語を通じてデータ システムとやり取りできるようになりました。たとえば、Copilot プログラミング アシスタントは SQL の生成を支援し、データ開発プロセスのさまざまなステップの完了を支援するため、開発効率が大幅に向上します。

さらに、データの洞察は AI を通じて行うこともできます。例えば、AIを使えば、どのようなデータがあるのか、一意のキーは何個あるのか、どのような方法で可視化するのが適しているのかなどを知ることができます。 AIがデータをさまざまな角度から観察して理解し、自動データ探索、インテリジェントなデータクエリ、チャート生成、ワンクリックでの分析レポート生成などを実現するインテリジェントな分析サービスです。
##4. 概要
以上がビッグデータAI統合解釈の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7694
7694
 15
1640
14
1393
52
1287
25
1229
29
15
1640
14
1393
52
1287
25
1229
29

 新しいカメラ、A18 Pro SoC、大きな画面を備えた iPhone 16 Pro および iPhone 16 Pro Max 公式
Sep 10, 2024 am 06:50 AM
新しいカメラ、A18 Pro SoC、大きな画面を備えた iPhone 16 Pro および iPhone 16 Pro Max 公式
Sep 10, 2024 am 06:50 AM
Apple はついに、新しいハイエンド iPhone モデルのカバーを外しました。 iPhone 16 Pro と iPhone 16 Pro Max には、前世代のものと比較して大きな画面が搭載されています (Pro では 6.3 インチ、Pro Max では 6.9 インチ)。強化された Apple A1 を入手
 iPhone の部品アクティベーション ロックが iOS 18 RC で発見 — ユーザー保護を装って販売された修理権利に対する Apple の最新の打撃となる可能性がある
Sep 14, 2024 am 06:29 AM
iPhone の部品アクティベーション ロックが iOS 18 RC で発見 — ユーザー保護を装って販売された修理権利に対する Apple の最新の打撃となる可能性がある
Sep 14, 2024 am 06:29 AM
今年初め、Apple はアクティベーション ロック機能を iPhone コンポーネントにも拡張すると発表しました。これにより、バッテリー、ディスプレイ、FaceID アセンブリ、カメラ ハードウェアなどの個々の iPhone コンポーネントが iCloud アカウントに効果的にリンクされます。
 iPhoneの部品アクティベーションロックは、ユーザー保護を装って販売されたAppleの修理権に対する最新の打撃となる可能性がある
Sep 13, 2024 pm 06:17 PM
iPhoneの部品アクティベーションロックは、ユーザー保護を装って販売されたAppleの修理権に対する最新の打撃となる可能性がある
Sep 13, 2024 pm 06:17 PM
今年初め、Apple はアクティベーション ロック機能を iPhone コンポーネントにも拡張すると発表しました。これにより、バッテリー、ディスプレイ、FaceID アセンブリ、カメラ ハードウェアなどの個々の iPhone コンポーネントが iCloud アカウントに効果的にリンクされます。
 gate.ioトレーディングプラットフォーム公式アプリのダウンロードとインストールアドレス
Feb 13, 2025 pm 07:33 PM
gate.ioトレーディングプラットフォーム公式アプリのダウンロードとインストールアドレス
Feb 13, 2025 pm 07:33 PM
この記事では、gate.ioの公式Webサイトに最新のアプリを登録およびダウンロードする手順について詳しく説明しています。まず、登録情報の記入、電子メール/携帯電話番号の確認、登録の完了など、登録プロセスが導入されます。第二に、iOSデバイスとAndroidデバイスでgate.ioアプリをダウンロードする方法について説明します。最後に、公式ウェブサイトの信頼性を検証し、2段階の検証を可能にすること、ユーザーアカウントと資産の安全性を確保するためのリスクのフィッシングに注意を払うなど、セキュリティのヒントが強調されています。
 複数のiPhone 16 Proユーザーがタッチスクリーンのフリーズ問題を報告、おそらくパームリジェクションの感度に関連している
Sep 23, 2024 pm 06:18 PM
複数のiPhone 16 Proユーザーがタッチスクリーンのフリーズ問題を報告、おそらくパームリジェクションの感度に関連している
Sep 23, 2024 pm 06:18 PM
Apple の iPhone 16 ラインナップのデバイス (具体的には 16 Pro/Pro Max) をすでに入手している場合は、最近タッチスクリーンに関する何らかの問題に直面している可能性があります。希望の光は、あなたは一人ではないということです - レポート
 Beats が電話ケースをラインナップに追加:iPhone 16 シリーズ用の MagSafe ケースを発表
Sep 11, 2024 pm 03:33 PM
Beats が電話ケースをラインナップに追加:iPhone 16 シリーズ用の MagSafe ケースを発表
Sep 11, 2024 pm 03:33 PM
Beats は Bluetooth スピーカーやヘッドフォンなどのオーディオ製品を発売することで知られていますが、驚きと形容するのが最も適切なことで、Apple 所有の会社は iPhone 16 シリーズを皮切りに電話ケースの製造に進出しました。ビートiPhone
 ANBIアプリの公式ダウンロードv2.96.2最新バージョンインストールANBI公式Androidバージョン
Mar 04, 2025 pm 01:06 PM
ANBIアプリの公式ダウンロードv2.96.2最新バージョンインストールANBI公式Androidバージョン
Mar 04, 2025 pm 01:06 PM
Binance Appの公式インストール手順:Androidは、ダウンロードリンクを見つけるために公式Webサイトにアクセスする必要があります。すべては、公式チャネルを通じて契約に注意を払う必要があります。
 PHPを使用してAlipay EasySDKを呼び出すときの「未定義の配列キー」「サイン」「エラー」の問題を解決する方法は?
Mar 31, 2025 pm 11:51 PM
PHPを使用してAlipay EasySDKを呼び出すときの「未定義の配列キー」「サイン」「エラー」の問題を解決する方法は?
Mar 31, 2025 pm 11:51 PM
問題の説明公式コードに従ってパラメーターを記入した後、PHPを使用してAlipay EasySDKを呼び出すとき、操作中にエラーメッセージが報告されました。
