

ゼロサンプル 6D 物体姿勢推定フレームワーク SAM-6D、身体化されたインテリジェンスに一歩近づく

オブジェクトの姿勢推定は、身体化された知能、巧みなロボット操作、拡張現実など、多くの実世界のアプリケーションで重要な役割を果たします。
この分野で注目すべき最初のタスクは インスタンス レベルの 6D 姿勢推定で、これにはモデルのトレーニングのためにターゲット オブジェクトに関する注釈付きデータが必要です。深度モデルはオブジェクト固有であり、新しいオブジェクトに転送することはできません。その後、研究の焦点は徐々に カテゴリレベルの 6D 姿勢推定 に移りました。これは目に見えないオブジェクトを処理するために使用されますが、そのオブジェクトが既知のオブジェクトに属している必要があります。興味のあるカテゴリー。
そして ゼロサンプル 6D 姿勢推定 は、より一般化されたタスク設定であり、任意のオブジェクトの CAD モデルを指定して、シーン内のターゲット オブジェクトを検出することを目的としています。そしてその6D姿勢を推定します。その重要性にもかかわらず、このゼロショット タスク設定は、物体検出と姿勢推定の両方において大きな課題に直面しています。

図 1. ゼロサンプル 6D オブジェクトの姿勢推定タスク
最近、すべてのモデルをセグメント化 SAM [1]は大きな注目を集めており、その優れたゼロサンプルセグメンテーション能力は目を引きます。 SAM は、ピクセル、バウンディング ボックス、テキスト、マスクなどのさまざまなキューを通じて高精度のセグメンテーションを実現します。これにより、ゼロサンプルの 6D オブジェクトの姿勢推定タスクに対する信頼性の高いサポートも提供され、その有望な可能性が実証されます。
そこで、Cross-Dimensional Intelligence、香港中文大学 (深セン)、華南理工大学の研究者は共同で、革新的なゼロサンプル 6D 物体姿勢推定フレームワーク SAM を提案しました。 -6D。この研究は CVPR 2024 に含まれています。

#
- 論文リンク: https://arxiv.org/pdf/2311.15707.pdf
- コードリンク: https://arxiv.org/pdf/2311.15707.pdf
://github.com/JiehongLin/SAM-6D
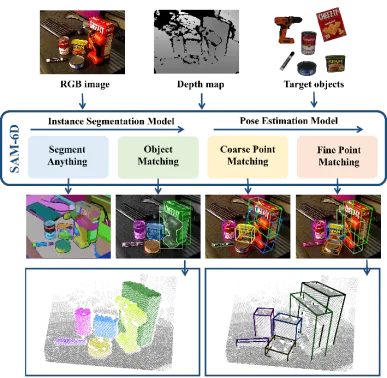 SAM-6D は、インスタンスのセグメンテーションとポーズを含む 2 つのステップを通じて、ゼロサンプルの 6D オブジェクトのポーズ推定を実現します。推定。したがって、任意のターゲット オブジェクトが与えられると、SAM-6D は 2 つの専用サブネットワーク、つまり
SAM-6D は、インスタンスのセグメンテーションとポーズを含む 2 つのステップを通じて、ゼロサンプルの 6D オブジェクトのポーズ推定を実現します。推定。したがって、任意のターゲット オブジェクトが与えられると、SAM-6D は 2 つの専用サブネットワーク、つまり
を利用して、RGB-D シーン イメージからターゲットを達成します。その中で、ISM は SAM を優れた出発点として使用し、慎重に設計されたオブジェクト マッチング スコアと組み合わせて、任意のオブジェクトのインスタンス セグメンテーションを実現します。PEM は、ローカル対ローカルの 2 段階の点セット マッチング プロセスを通じてオブジェクトの姿勢問題を解決します。 SAM-6Dの概要を図2に示します。
図 2. SAM-6D の概要
- 一般的に、SAM-6D テクノロジの貢献は次のとおりです。
- SAM-6D は、CAD を使用して RGB-D 画像から RGB-D 画像を生成できる革新的なゼロサンプル 6D 姿勢推定フレームワークです。あらゆるオブジェクトのモデルを作成し、ターゲット オブジェクトのインスタンス セグメンテーションと姿勢推定を実行し、BOP [2] の 7 つのコア データセットで優れたパフォーマンスを発揮します。
- SAM-6D は、すべてのセグメンテーション モデルのゼロショット セグメンテーション機能を活用して、考えられるすべての候補オブジェクトを生成し、ターゲット オブジェクトに対応するオブジェクトを識別するための新しいオブジェクト マッチング スコアを設計します。候補者。
SAM-6D は、姿勢推定をローカル間の点集合のマッチング問題と見なし、シンプルだが効果的なバックグラウンド トークン設計を採用し、任意のオブジェクトに対する 2 次元アルゴリズムを提案します。ステージ点セット マッチング モデル。第 1 ステージでは粗い点セット マッチングを実装して初期オブジェクト ポーズを取得し、第 2 ステージでは新しい疎点セットから高密度点セットへの変換を使用して細かい点セット マッチングを実行し、ポーズをさらに最適化します。
インスタンス セグメンテーション モデル (ISM)
SAM-6D は、インスタンス セグメンテーション モデル (ISM) を使用して、任意のオブジェクトを検出してセグメント化します。マスク。
RGB イメージで表される乱雑なシーンを考慮して、ISM はセグメンテーション エブリシング モデル (SAM) のゼロショット転送機能を活用して、考えられるすべての候補を生成します。 ISM は候補オブジェクトごとにオブジェクト一致スコアを計算し、セマンティクス、外観、ジオメトリの観点からターゲット オブジェクトとどの程度一致しているかを推定します。最後に、一致しきい値を設定するだけで、ターゲット オブジェクトに一致するインスタンスを識別できます。 ############オブジェクト一致スコアは、3 つの一致項目の加重合計によって計算されます:######
セマンティック マッチング アイテム - ターゲット オブジェクトについて、ISM は複数の観点からオブジェクト テンプレートをレンダリングし、DINOv2 [3] の事前トレーニング済み ViT モデルを使用して候補オブジェクトとオブジェクト テンプレートを抽出します。そしてそれらの間の相関スコアを計算します。意味的一致スコアは、上位 K 個の最高スコアを平均することによって取得され、最も高い相関スコアに対応するオブジェクト テンプレートが最も一致するテンプレートとみなされます。
外観マッチング項目 ——最適にマッチングするテンプレートについては、ViT モデルを使用して画像ブロックの特徴を抽出し、それと画像のブロック特徴の間の相関を計算します。これにより、意味的に類似しているが外観が異なるオブジェクトを区別するために使用される外観一致スコアが得られます。
幾何学的一致 - さまざまなオブジェクトの形状やサイズの違いなどの要因を考慮して、ISM は幾何学的一致スコアも設計しました。最もよく一致するテンプレートと候補オブジェクトの点群に対応する回転の平均により、大まかなオブジェクトのポーズが得られ、このポーズを使用してオブジェクト CAD モデルを剛体変換および投影することにより、バウンディング ボックスを取得できます。境界ボックスと候補境界ボックスの間の交差対和集合 (IoU) 比を計算すると、幾何学的マッチング スコアを取得できます。
姿勢推定モデル (PEM)
ターゲット オブジェクトと一致する各候補オブジェクトに対して、SAM-6D は姿勢推定モデル (PEM) を利用します。 ) ) を使用して、オブジェクトの CAD モデルを基準にして 6D 姿勢を予測します。
セグメント化された候補オブジェクトとオブジェクト CAD モデルのサンプリング ポイント セットをそれぞれ 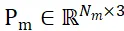 と
と 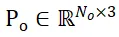 として表します。 N_m と N_o はそれらの点の数を表し、同時にこれら 2 つの点セットの特徴は
として表します。 N_m と N_o はそれらの点の数を表し、同時にこれら 2 つの点セットの特徴は 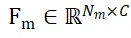 と
と 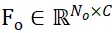 として表され、C はその数を表します機能のチャンネル数。 PEM の目的は、P_m から P_o までのローカル間対応を表す割り当て行列を取得することです。オクルージョンにより、P_o は P_m と部分的にのみ一致し、セグメンテーションの不正確さとセンサー ノイズにより、P_m は部分的にのみ一致します。 部分的 AND 一致ぽ。
として表され、C はその数を表します機能のチャンネル数。 PEM の目的は、P_m から P_o までのローカル間対応を表す割り当て行列を取得することです。オクルージョンにより、P_o は P_m と部分的にのみ一致し、セグメンテーションの不正確さとセンサー ノイズにより、P_m は部分的にのみ一致します。 部分的 AND 一致ぽ。
2 つの点セット間で重複しない点を割り当てる問題を解決するために、ISM にはそれぞれのバックグラウンド トークンが装備されており、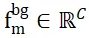 および ## として記録されます。
および ## として記録されます。 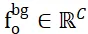 #、すると、特徴の類似性に基づいて、ローカル間の対応を効果的に確立できます。具体的には、まず注目行列を次のように計算できます。
#、すると、特徴の類似性に基づいて、ローカル間の対応を効果的に確立できます。具体的には、まず注目行列を次のように計算できます。
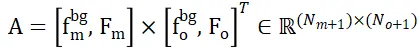
次に、分布行列を取得できます
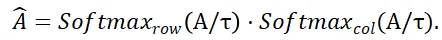
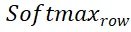 と
と 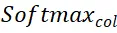 はそれぞれ行と列に沿ったソフトマックス演算を表し、
はそれぞれ行と列に沿ったソフトマックス演算を表し、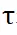 は定数を表します。
は定数を表します。 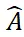 の各行の値 (最初の行を除く) は、点集合 P_m 内の各点 P_m と背景および P_o の中点との一致確率を表します。スコアを取得すると、P_m (背景を含む) に一致するポイントを見つけることができます。
の各行の値 (最初の行を除く) は、点集合 P_m 内の各点 P_m と背景および P_o の中点との一致確率を表します。スコアを取得すると、P_m (背景を含む) に一致するポイントを見つけることができます。
計算結果が得られたら、すべてのマッチング ポイント ペア {(P_m,P_o)} とそのマッチング スコアを収集し、最終的に重み付き SVD オブジェクト姿勢を使用して計算できます。 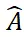
図 3. SAM-6D
バックグラウンド トークンに基づく上記の戦略を使用して、PEM で 2 つの点セット マッチング ステージが設計されています。モデル構造は図 3 に示されています。特徴抽出、大まかな点セット マッチング、および詳細な点セットが含まれます。 3 つのモジュールに一致します。
ラフ点セット マッチング モジュールは、スパース対応を実装してオブジェクトの初期ポーズを計算し、このポーズを使用して候補オブジェクトの点セットを変換し、位置エンコード学習を実現します。
詳細点セット マッチング モジュールは、候補オブジェクトとターゲット オブジェクトのサンプリング点セットの位置エンコーディングを組み合わせて、第 1 段階で大まかな対応関係を注入し、さらに確立します。より正確なオブジェクトのポーズを取得するための密な対応関係。この段階で密な相互作用を効果的に学習するために、PEM は新しい疎から密への点集合変換器を導入します。これは、密な特徴の疎なバージョンで相互作用を実装し、線形変換器 [5] を利用して強化された疎な特徴を拡散に変換して密な特徴に戻します。特徴。
実験結果
SAM-6D の 2 つのサブモデルでは、インスタンス セグメンテーション モデル (ISM) が SAM とネットワークは再トレーニングされ、微調整されますが、姿勢推定モデル (PEM) は、MegaPose [4] によって提供される大規模な ShapeNet-Objects および Google-Scanned-Objects 合成データセットを使用してトレーニングされます。
ゼロサンプル機能を検証するために、SAM-6D は、LM-O、T-LESS、TUD-L、IC を含む BOP [2] の 7 つのコア データ セットでテストされました。 -BIN、ITODD、HB、YCB-V。表 1 と表 2 は、これら 7 つのデータセットに対するさまざまな方法によるインスタンスのセグメンテーションと姿勢推定の結果の比較をそれぞれ示しています。他の手法と比較して、SAM-6D は両方の手法で非常に優れたパフォーマンスを発揮し、その強力な汎化能力を十分に実証しています。
#表 1. BOP 7 つのコア データ セットに対するさまざまな方法のインスタンス セグメンテーション結果の比較
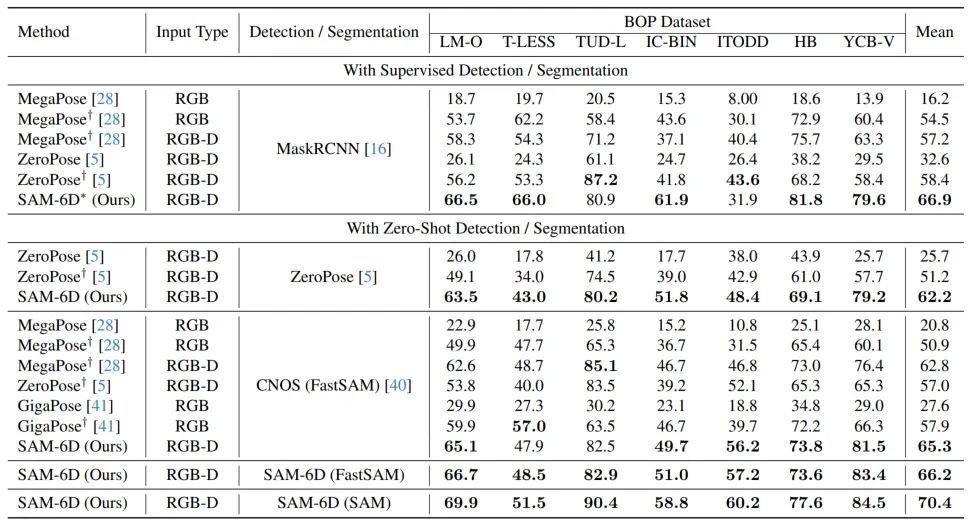
表 2. BOP の 7 つのコア データ セットに対するさまざまな方法の姿勢推定結果の比較
図 4 は、BOP における SAM-6D のパフォーマンスを示しています。 7 3 つのデータセットに対する検出セグメンテーションと 6D 姿勢推定の視覚化結果。(a) と (b) はそれぞれテスト RGB 画像と深度マップ、(c) は指定されたターゲット オブジェクト、(d) と (e)はそれぞれ検出セグメンテーションと 6D ポーズの可視化結果です。

図 4. BOP の 7 つのコア データセットに対する SAM-6D の視覚化結果。
SAM-6D の実装の詳細については、元の論文をお読みください。
以上がゼロサンプル 6D 物体姿勢推定フレームワーク SAM-6D、身体化されたインテリジェンスに一歩近づくの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7745
7745
 15
1643
14
1397
52
1291
25
1234
29
15
1643
14
1397
52
1291
25
1234
29

 WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)は、独自の生体認証とプライバシー保護メカニズムを備えた暗号通貨市場で際立っており、多くの投資家の注目を集めています。 WLDは、特にOpenai人工知能技術と組み合わせて、革新的なテクノロジーを備えたAltcoinsの間で驚くほど演奏しています。しかし、デジタル資産は今後数年間でどのように振る舞いますか? WLDの将来の価格を一緒に予測しましょう。 2025年のWLD価格予測は、2025年にWLDで大幅に増加すると予想されています。市場分析は、平均WLD価格が1.31ドルに達する可能性があり、最大1.36ドルであることを示しています。ただし、クマ市場では、価格は約0.55ドルに低下する可能性があります。この成長の期待は、主にWorldCoin2によるものです。
 クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションをサポートする交換:1。Binance、2。Uniswap、3。Sushiswap、4。CurveFinance、5。Thorchain、6。1inchExchange、7。DLNTrade、これらのプラットフォームはさまざまな技術を通じてマルチチェーン資産トランザクションをサポートします。
 なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
仮想通貨価格の上昇の要因には、次のものが含まれます。1。市場需要の増加、2。供給の減少、3。刺激された肯定的なニュース、4。楽観的な市場感情、5。マクロ経済環境。衰退要因は次のとおりです。1。市場需要の減少、2。供給の増加、3。ネガティブニュースのストライキ、4。悲観的市場感情、5。マクロ経済環境。
 ハイブリッドブロックチェーン取引プラットフォームとは何ですか?
Apr 21, 2025 pm 11:36 PM
ハイブリッドブロックチェーン取引プラットフォームとは何ですか?
Apr 21, 2025 pm 11:36 PM
暗号通貨交換を選択するための提案:1。流動性の要件については、優先度は、その順序の深さと強力なボラティリティ抵抗のため、Binance、gate.ioまたはokxです。 2。コンプライアンスとセキュリティ、Coinbase、Kraken、Geminiには厳格な規制の承認があります。 3.革新的な機能、Kucoinのソフトステーキング、Bybitのデリバティブデザインは、上級ユーザーに適しています。
 カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
暗号通貨の賑やかな世界では、新しい機会が常に現れます。現在、Kerneldao(Kernel)Airdropアクティビティは多くの注目を集め、多くの投資家の注目を集めています。それで、このプロジェクトの起源は何ですか? BNBホルダーはそれからどのような利点を得ることができますか?心配しないでください、以下はあなたのためにそれを一つ一つ明らかにします。
 Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Aavedaoの定足数を実装したToken Reposを導入する提案です。 Aave Project Chain(ACI)の創設者であるMarc Zellerは、これをXで発表し、契約の新しい時代をマークしていることに注目しました。 Aave Chain Initiative(ACI)の創設者であるMarc Zellerは、Aavenomicsの提案にAave Protocolトークンの変更とトークンリポジトリの導入が含まれていると発表しました。 Zellerによると、これは契約の新しい時代を告げています。 Aavedaoのメンバーは、水曜日の週に100でした。
 ビットコイン完成品構造の分析チャートは何ですか?描く方法は?
Apr 21, 2025 pm 07:42 PM
ビットコイン完成品構造の分析チャートは何ですか?描く方法は?
Apr 21, 2025 pm 07:42 PM
ビットコイン構造分析チャートを描画する手順には、次のものが含まれます。1。図面の目的と視聴者を決定します。2。適切なツールを選択します。3。フレームワークを設計し、コアコンポーネントを入力します。4。既存のテンプレートを参照してください。完全な手順チャートが正確で理解しやすいことを確認してください。
 通貨サークル市場に関するリアルタイムデータの上位10の無料プラットフォーム推奨事項がリリースされます
Apr 22, 2025 am 08:12 AM
通貨サークル市場に関するリアルタイムデータの上位10の無料プラットフォーム推奨事項がリリースされます
Apr 22, 2025 am 08:12 AM
初心者に適した暗号通貨データプラットフォームには、Coinmarketcapと非小さいトランペットが含まれます。 1。CoinMarketCapは、初心者と基本的な分析のニーズに合わせて、グローバルなリアルタイム価格、市場価値、取引量のランキングを提供します。 2。小さい引用は、中国のユーザーが低リスクの潜在的なプロジェクトをすばやくスクリーニングするのに適した中国フレンドリーなインターフェイスを提供します。
