
 テクノロジー周辺機器
AI
ソラの3Dバージョンは登場しますか? UMass、MIT などが 3D 世界モデルを提案し、身体化されたインテリジェント ロボットが新たなマイルストーンを達成
テクノロジー周辺機器
AI
ソラの3Dバージョンは登場しますか? UMass、MIT などが 3D 世界モデルを提案し、身体化されたインテリジェント ロボットが新たなマイルストーンを達成
ソラの3Dバージョンは登場しますか? UMass、MIT などが 3D 世界モデルを提案し、身体化されたインテリジェント ロボットが新たなマイルストーンを達成

最近の研究では、ビジョン言語アクション (VLA、ビジョン言語アクション) モデルへの入力これは基本的に 2D データであり、より一般的な 3D 物理世界は統合されていません。
さらに、既存のモデルは、世界のダイナミクスやアクションとダイナミクスの関係を無視し、「知覚されたアクションの直接マッピング」を学習することによってアクション予測を実行します。
対照的に、人間が考えるとき、将来のシナリオの想像力を記述し、次の行動を計画できる世界モデルを導入します。
この目的のために、マサチューセッツ大学アマースト校、MIT およびその他の機関の研究者は、3D-VLA モデルを提案しました。新しいクラスの具体化された基盤モデルを導入することにより、生成された世界は、3D 認識、推論、および 3D をシームレスに接続するモデルになります。アクション。 
#プロジェクトのホームページ: https://vis-www.cs.umass .edu/3dvla/
論文アドレス: https://arxiv.org/abs/2403.09631
具体的には、3D-VLA に基づいて構築されています3D ベースの大規模言語モデル (LLM) と、具体化された環境に参加するための一連の対話トークンの導入です。
Ganchuang チームは、一連の具現化拡散モデルをトレーニングし、生成機能をモデルに注入し、LLM に調整してターゲット画像と点群を予測しました。
3D-VLA モデルをトレーニングするために、既存のロボット データセットから大量の 3D 関連情報を抽出し、巨大な 3D 具現化命令データセットを構築しました。
研究結果は、3D-VLA が、具体化された環境での推論、マルチモーダル生成、および計画タスクの処理において優れたパフォーマンスを発揮することを示しており、これは現実世界のシナリオにおける潜在的なアプリケーションの価値を強調しています。
3D エンボディド命令チューニング データセットインターネット上に数十億のデータ セットがあるため、VLM は複数のタスクを実行します。優れたパフォーマンスと 100 万レベルのビデオを実現します。アクション データ セットは、ロボット制御用の特定の VLM の基礎も築きます。
しかし、現在のデータセットのほとんどは、十分な深度や 3D アノテーション、ロボット動作の正確な制御を提供できません。これには、3D 空間推論とインタラクションのコンテンツがデータ セットに含まれている必要があります。 3D 情報が不足しているため、「一番奥のカップを真ん中の引き出しに入れる」など、3D 空間推論を必要とする命令をロボットが理解して実行することが困難になります。

このギャップを埋めるために、研究者らは、モデルをトレーニングするために十分な「3D 関連情報」と「対応するテキスト命令」を提供する大規模な 3D 命令調整データ セットを構築しました。
研究者らは、既存の具体化されたデータセットから 3D 言語アクションのペアを抽出し、点群、深度マップ、3D 境界ボックス、ロボットの 7D アクション、およびテキスト説明ラベルを取得するパイプラインを設計しました。
3D-VLA ベース モデル
3D-VLA は、具体化された環境における 3 次元の推論、目標生成、および意思決定のための世界モデルです。
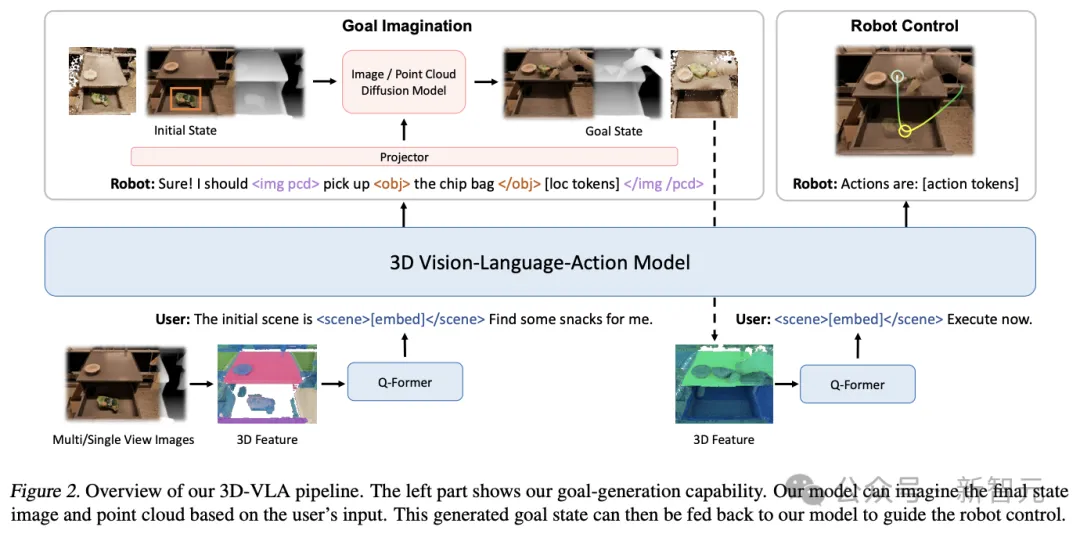
まず 3D-LLM 上にバックボーン ネットワークを構築し、一連のインタラクティブ トークン; 次に、拡散モデルを事前トレーニングし、射影を使用して LLM モデルと拡散モデルを調整することにより、ターゲット生成機能が 3D-VLA
バックボーン ネットワークに注入されます。
第一段階では、研究者らは 3D-LLM 手法に従って 3D-VLA ベース モデルを開発しました。収集されたデータ セットが必要な 10 億レベルのスケールに達していなかったためです。マルチモーダル LLM を最初からトレーニングするには、マルチビュー機能を使用して 3D シーンの特徴を生成する必要があります。これにより、視覚的特徴を調整せずに事前トレーニングされた VLM にシームレスに統合できます。
同時に、3D-LLM のトレーニング データ セットには主にオブジェクトと屋内シーンが含まれており、これらは特定の設定と直接一致しないため、研究者は BLIP2- を使用することを選択しました。 PlanT5XL を事前トレーニング モデルとして使用します。
トレーニング プロセス中に、トークンの入力および出力の埋め込みと Q-Former の重みを解凍します。
インタラクション トークン
3D シーンと環境内のインタラクションに対するモデルの理解を強化するために、研究者らは、新しいインタラクティブ トークンのセットを導入しました。
まず、解析された文内のオブジェクト名詞 (
第 2 に、空間情報を言語でより適切に表現するために、研究者らは、AABB 形式の 6 つのマークを使用して位置トークンのセット
3 番目に、動的エンコーディングをより適切に実行するために、
このアーキテクチャは、ロボットの動作を表す特殊なタグのセットを拡張することによってさらに強化されています。ロボットの動作には 7 つの自由度があり、
目標生成機能の導入
人間はシーンの最終状態を事前に視覚化し、目標生成の精度を向上させることができます。行動の予測や意思決定も世界モデル構築の重要な側面であり、研究者らは予備実験で現実的な最終状態を提供することでモデルの推論能力と計画能力を強化できることも発見した。
しかし、MLLM をトレーニングして画像、深度、点群を生成するのは簡単ではありません:
第一に、ビデオ拡散モデルは具体化されたシーン用に設計されていません。オーダーメイドの場合、たとえば、Runway が今後の「引き出しを開いた」フレームを生成すると、ビューの変更、オブジェクトの変形、奇妙なテクスチャの置き換え、レイアウトの歪みなどの問題がシーン内で発生します。
さらに、さまざまなモードの拡散モデルを単一の基本モデルに統合する方法は依然として難しい問題です。
したがって、研究者によって提案された新しいフレームワークは、まず画像、深度、点群などのさまざまな形式に基づいて特定の拡散モデルを事前トレーニングし、次に拡散モデルのデコーダを使用します。アライメント段階で、3D-VLAの埋め込み空間に合わせてアライメントします。

3D-VLA は、3D 世界で使用できる多機能の 3D ベースの生成世界モデルです。研究者らは、推論と位置特定、マルチモーダルターゲットの内容の想像、およびロボット操作のためのアクションの生成を実行する際に、主に 3D 推論と位置特定、マルチモーダルターゲットの生成、具現化されたアクション計画の 3 つの側面から 3D-VLA を評価しました。
3D 推論とローカリゼーション
3D-VLA は、言語推論タスクにおいてすべての 2D VLM メソッドよりも優れています。研究担当者によるこれは、推論のためにより正確な空間情報を提供する 3D 情報の活用につながります。
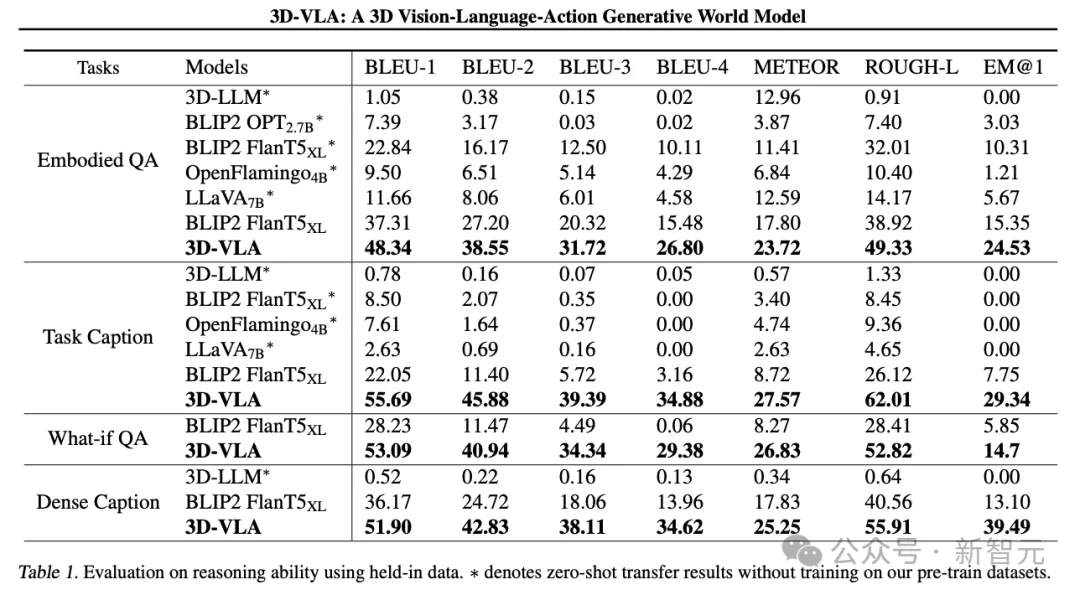
さらに、データセットには 3D 位置決めアノテーションのセットが含まれているため、3D-VLA は関連するオブジェクトの位置を学習し、モデルが推論のために主要なオブジェクトにさらに焦点を当てるのに役立ちます。
研究者らは、3D-LLM がこれらのロボット推論タスクのパフォーマンスが低いことを発見し、ロボット関連の 3D データセットの収集とトレーニングの必要性を示しました。
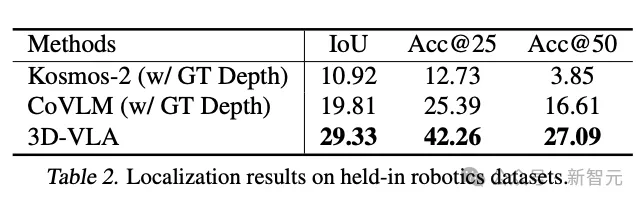
そして、3D-VLA は、位置決めパフォーマンスにおいて 2D ベースライン手法よりも大幅に優れたパフォーマンスを示しました。この発見は、アノテーション プロセスの有効性の証拠でもあります。説得力のある証拠は、モデルが強力な 3D 位置決め機能を獲得するのに役立ちます。
マルチモーダル ターゲット生成
ロボット工学分野への移行のための既存のゼロショット生成方法と比較して、3D-VLA はほとんどの指標でより良い結果を達成します。このパフォーマンスは、ワールド モデルをトレーニングするために「ロボット アプリケーション用に特別に設計されたデータセット」を使用することの重要性を裏付けています。
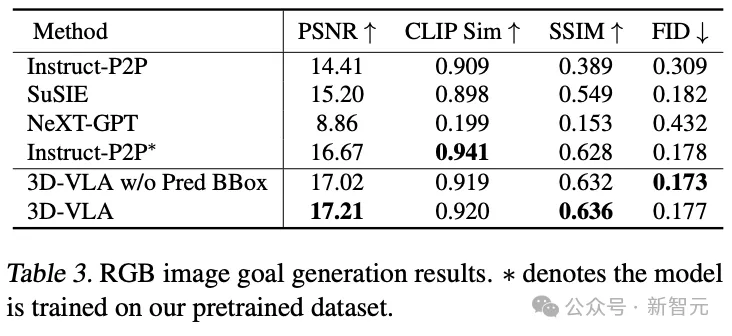
Instruct-P2P* と直接比較しても、3D-VLA は一貫して優れたパフォーマンスを示しており、その結果は、大規模な言語モデルを 3D に統合することができることを示しています。 VLA、ロボットの動作命令をより包括的かつ深く理解できるようになり、ターゲット画像の生成パフォーマンスが向上します。
さらに、入力プロンプトから予測境界ボックスを除外すると、わずかなパフォーマンスの低下が観察され、モデルの理解を助けるために中間の予測境界ボックスを使用することの有効性が確認されています。シーン全体でモデルが許可されています。特定の指示で言及されている特定のオブジェクトにより多くの注意を割り当てることで、最終的には最終的なターゲット画像を想像する能力が向上します。
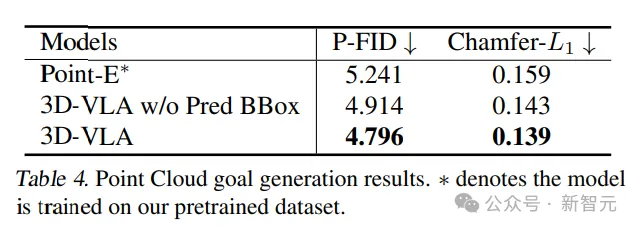
#点群によって生成された結果の比較では、中間予測境界ボックスを使用した 3D-VLA が最も優れたパフォーマンスを示し、指示とシーンを理解することの重要性が確認されました。 . 大規模な言語モデルと正確なオブジェクトのローカリゼーションを組み合わせる重要性をコンテキスト化します。
具体的なアクション プランニング
3D-VLA は、RLBench アクション予測のほとんどのタスクでベースラインを上回っています。モデルはその計画能力を示しています。
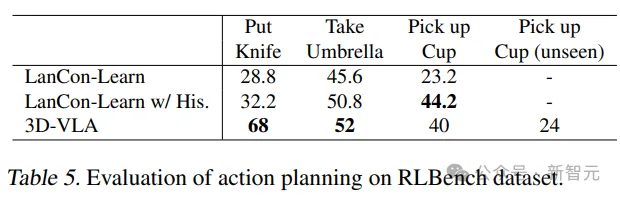
ベースライン モデルでは履歴観察、オブジェクトのステータス、および現在のステータス情報を使用する必要があるのに対し、3D-VLA モデルは開ループ制御を通じてのみ実行されることに注意してください。 。
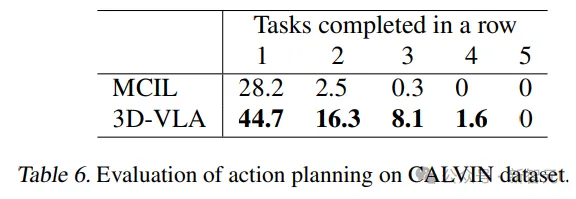
さらに、モデルの汎化能力はカップピックアップタスクで実証され、3D-VLA は CALVIN Better で使用されました。研究者らは、この利点は、関心のあるオブジェクトを見つけて目標状態を想像し、行動を推測するための豊富な情報を提供する能力によるものであると考えています。
以上がソラの3Dバージョンは登場しますか? UMass、MIT などが 3D 世界モデルを提案し、身体化されたインテリジェント ロボットが新たなマイルストーンを達成の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7566
7566
 15
1386
52
87
11
28
105
15
1386
52
87
11
28
105

 CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CENTOSシステムでHDFS構成をチェックするための完全なガイドこの記事では、CENTOSシステム上のHDFSの構成と実行ステータスを効果的に確認する方法をガイドします。次の手順は、HDFSのセットアップと操作を完全に理解するのに役立ちます。 Hadoop環境変数を確認します。最初に、Hadoop環境変数が正しく設定されていることを確認してください。端末では、次のコマンドを実行して、Hadoopが正しくインストールおよび構成されていることを確認します。HDFS構成をチェックするHDFSファイル:HDFSのコア構成ファイルは/etc/hadoop/conf/ディレクトリにあります。使用
 Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centos Shutdownコマンドはシャットダウンし、構文はシャットダウン[オプション]時間[情報]です。オプションは次のとおりです。-hシステムをすぐに停止します。 -pシャットダウン後に電源をオフにします。 -r再起動; -t待機時間。時間は、即時(現在)、数分(分)、または特定の時間(HH:mm)として指定できます。追加の情報をシステムメッセージに表示できます。
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosシステムの下でのGitlabのバックアップと回復ポリシーデータセキュリティと回復可能性を確保するために、Gitlab on Centosはさまざまなバックアップ方法を提供します。この記事では、いくつかの一般的なバックアップ方法、構成パラメーター、リカバリプロセスを詳細に紹介し、完全なGitLabバックアップと回復戦略を確立するのに役立ちます。 1.手動バックアップGitlab-RakeGitlabを使用:バックアップ:コマンドを作成して、マニュアルバックアップを実行します。このコマンドは、gitlabリポジトリ、データベース、ユーザー、ユーザーグループ、キー、アクセスなどのキー情報をバックアップします。デフォルトのバックアップファイルは、/var/opt/gitlab/backupsディレクトリに保存されます。 /etc /gitlabを変更できます
 Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
CentOSにMySQLをインストールするには、次の手順が含まれます。適切なMySQL Yumソースの追加。 yumを実行して、mysql-serverコマンドをインストールして、mysqlサーバーをインストールします。ルートユーザーパスワードの設定など、MySQL_SECURE_INSTALLATIONコマンドを使用して、セキュリティ設定を作成します。必要に応じてMySQL構成ファイルをカスタマイズします。 MySQLパラメーターを調整し、パフォーマンスのためにデータベースを最適化します。
 CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
Pytorchの分散トレーニングでは、Centosシステムでトレーニングには次の手順が必要です。Pytorchのインストール:PythonとPipがCentosシステムにインストールされていることです。 CUDAバージョンに応じて、Pytorchの公式Webサイトから適切なインストールコマンドを入手してください。 CPUのみのトレーニングには、次のコマンドを使用できます。PipinstalltorchtorchtorchvisionTorchaudioGPUサポートが必要な場合は、CUDAとCUDNNの対応するバージョンがインストールされ、インストールに対応するPytorchバージョンを使用してください。分散環境構成:分散トレーニングには、通常、複数のマシンまたは単一マシンの複数GPUが必要です。場所
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Centosでgitlabログを表示する方法
Apr 14, 2025 pm 06:18 PM
Centosでgitlabログを表示する方法
Apr 14, 2025 pm 06:18 PM
CENTOSシステムでGitLabログを表示するための完全なガイドこの記事では、メインログ、例外ログ、その他の関連ログなど、CentosシステムでさまざまなGitLabログを表示する方法をガイドします。ログファイルパスは、gitlabバージョンとインストール方法によって異なる場合があることに注意してください。次のパスが存在しない場合は、gitlabインストールディレクトリと構成ファイルを確認してください。 1.メインGitLabログの表示
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
