

CVPR 2024 | ゼロサンプル 6D オブジェクト姿勢推定フレームワーク SAM-6D、身体化されたインテリジェンスに一歩近づく

多くの実際のアプリケーションでは、物体の姿勢推定は、身体化された知能、ロボット操作、拡張現実などの分野で重要な役割を果たします。
この分野で注目すべき最初のタスクは インスタンス レベルの 6D 姿勢推定です。これには、深度モデルをオブジェクト固有のプロパティにするためのモデル トレーニング用のターゲット オブジェクトに関する注釈付きデータが必要です。新しいオブジェクトに転送することはできません。その後、研究の焦点は徐々に カテゴリレベルの 6D 姿勢推定 に移りました。これは目に見えないオブジェクトを処理するために使用されますが、そのオブジェクトが既知の関心のあるカテゴリに属している必要があります。
および ゼロサンプル 6D ポーズ推定 は、より一般化されたタスク設定であり、任意のオブジェクトの CAD モデルが与えられた場合、シーン内のターゲット オブジェクトを検出し、その 6D ポーズを推定することを目的としています。その重要性にもかかわらず、このゼロショット タスク設定は、物体検出と姿勢推定の両方において大きな課題に直面しています。

[ 1] が注目を集めており、その優れたゼロサンプルセグメンテーション能力が目を引きます。 SAM は、ピクセル、バウンディング ボックス、テキスト、マスクなどのさまざまなキューを通じて高精度のセグメンテーションを実現します。これにより、ゼロサンプルの 6D オブジェクトの姿勢推定タスクに対する信頼性の高いサポートも提供され、その有望な可能性が実証されます。 したがって、新しいゼロサンプル 6D 物体姿勢推定フレームワーク SAM-6D が、Cross-Dimensional Intelligence、香港中文大学 (深セン)、および華南理工大学の研究者によって提案されました。この研究は CVPR 2024 によって認められました。
 論文リンク: https://arxiv.org/pdf/2311.15707.pdf
論文リンク: https://arxiv.org/pdf/2311.15707.pdf
コードリンク: https://github.com/JiehongLin/SAM-6D
-
SAM-6D は、インスタンス セグメンテーションと姿勢推定を含む 2 つのステップを通じて、ゼロサンプル 6D オブジェクトの姿勢推定を実装します。したがって、任意のターゲット オブジェクトが与えられると、SAM-6D は 2 つの専用サブネットワーク、つまり
インスタンス セグメンテーション モデル (ISM) とポーズ推定モデル (PEM) を利用して、RGB-D シーン イメージからターゲットを達成します。その中で、ISM は SAM を優れた出発点として使用し、慎重に設計されたオブジェクト マッチング スコアと組み合わせて、任意のオブジェクトのインスタンス セグメンテーションを実現します。PEM は、ローカル対ローカルの 2 段階の点セット マッチング プロセスを通じてオブジェクトの姿勢問題を解決します。 SAM-6Dの概要を図2に示します。
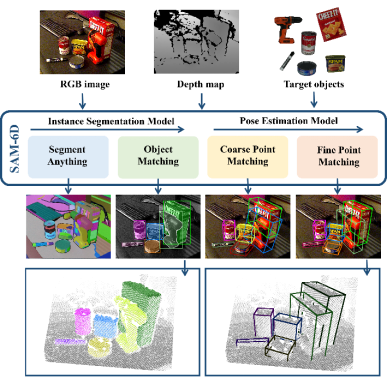
全体として、SAM-6D の技術的貢献は次のように要約できます。
SAM-6D は、あらゆるオブジェクトの CAD を提供する革新的なゼロサンプル 6D 姿勢推定フレームワークです。このモデルは、RGB-D 画像からのターゲット オブジェクトのインスタンス セグメンテーションと姿勢推定を実装しており、BOP [2] の 7 つのコア データ セットに対して優れたパフォーマンスを発揮します。
SAM-6D は、すべてのセグメンテーション モデルのゼロショット セグメンテーション機能を活用して、考えられるすべての候補オブジェクトを生成し、ターゲット オブジェクトに対応するオブジェクトを識別するための新しいオブジェクト マッチング スコアを設計します。候補者。
SAM-6D は、姿勢推定をローカル間の点集合のマッチング問題と見なし、シンプルだが効果的なバックグラウンド トークン設計を採用し、任意のオブジェクトに対する 2 次元アルゴリズムを提案します。ステージ点セット マッチング モデル。第 1 ステージでは粗い点セット マッチングを実装して初期オブジェクト ポーズを取得し、第 2 ステージでは新しい疎点セットから高密度点セットへの変換を使用して細かい点セット マッチングを実行し、ポーズをさらに最適化します。
インスタンス セグメンテーション モデル (ISM)
SAM-6D は、インスタンス セグメンテーション モデル (ISM) を使用して、任意のオブジェクトのマスクを検出してセグメント化します。
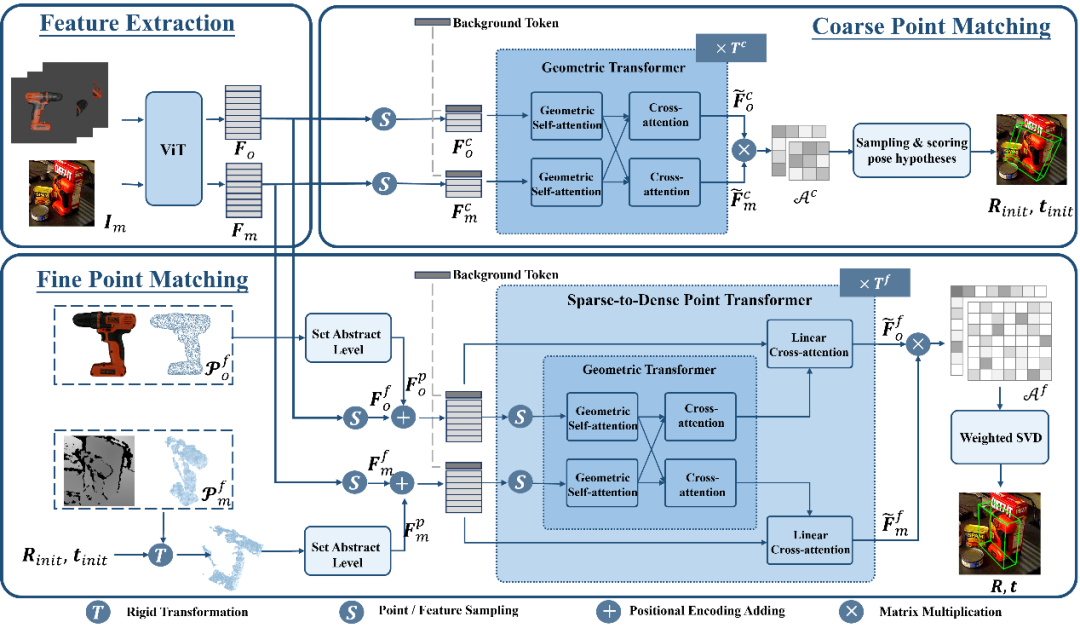
RGB イメージで表される乱雑なシーンを考慮して、ISM はセグメンテーション エブリシング モデル (SAM) のゼロショット転送機能を利用して、考えられるすべての候補を生成します。 ISM は候補オブジェクトごとにオブジェクト一致スコアを計算し、セマンティクス、外観、ジオメトリの観点からターゲット オブジェクトとどの程度一致しているかを推定します。最後に、一致しきい値を設定するだけで、ターゲット オブジェクトに一致するインスタンスを識別できます。
オブジェクト一致スコアの計算は、3 つの一致項目の加重合計によって取得されます。
セマンティック一致項目 - ターゲット オブジェクトに対して、ISM は複数のビューをレンダリングします。オブジェクト テンプレートを使用し、DINOv2 [3] の事前トレーニング済み ViT モデルを使用して、候補オブジェクトとオブジェクト テンプレートの意味論的特徴を抽出し、それらの間の相関スコアを計算します。意味的一致スコアは、上位 K 個の最高スコアを平均することによって取得され、最も高い相関スコアに対応するオブジェクト テンプレートが最も一致するテンプレートとみなされます。
外観一致項目 - 最も一致するテンプレートについては、ViT モデルを使用して画像ブロック特徴を抽出し、それと候補オブジェクトのブロック特徴の間の相関を計算して、外観一致を取得します。 item スコア。意味的には似ているが視覚的に異なるオブジェクトを区別するために使用されます。
幾何学的一致 - ISM は、さまざまなオブジェクトの形状やサイズの違いなどの要因を考慮して、幾何学的一致スコアも設計しました。最もよく一致するテンプレートと候補オブジェクトの点群に対応する回転の平均により、大まかなオブジェクトのポーズが得られ、このポーズを使用してオブジェクト CAD モデルを剛体変換および投影することにより、バウンディング ボックスを取得できます。境界ボックスと候補境界ボックスの間の交差対和集合 (IoU) 比を計算すると、幾何学的マッチング スコアを取得できます。
姿勢推定モデル (PEM)
ターゲット オブジェクトと一致する各候補オブジェクトについて、SAM-6D は姿勢推定モデル (PEM) を利用して相対的な 6D を予測します。オブジェクトの CAD モデルのポーズ。
セグメント化された候補オブジェクトとオブジェクト CAD モデルのサンプリング点セットはそれぞれ 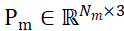 と
と 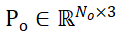 で表され、N_m と N_o はそれらの点の数を表し、同時にこれら 2 つの点セットの特性を表しますは
で表され、N_m と N_o はそれらの点の数を表し、同時にこれら 2 つの点セットの特性を表しますは 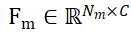 および
および 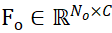 で表され、C は機能のチャネル数を表します。 PEM の目的は、P_m から P_o までのローカル間対応を表す割り当て行列を取得することです。オクルージョンにより、P_o は P_m と部分的にのみ一致し、セグメンテーションの不正確さとセンサー ノイズにより、P_m は部分的にのみ一致します。 部分的 AND 一致ぽ。
で表され、C は機能のチャネル数を表します。 PEM の目的は、P_m から P_o までのローカル間対応を表す割り当て行列を取得することです。オクルージョンにより、P_o は P_m と部分的にのみ一致し、セグメンテーションの不正確さとセンサー ノイズにより、P_m は部分的にのみ一致します。 部分的 AND 一致ぽ。
2 つの点セット間で重複しない点を割り当てる問題を解決するために、ISM は 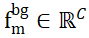 と
と 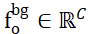 のマークが付いたバックグラウンド トークンをそれらの点セットに装備します。これにより、ローカル間の関係をベースにして効果的に確立できます。機能の類似性について。具体的には、最初に注目行列を次のように計算できます。
のマークが付いたバックグラウンド トークンをそれらの点セットに装備します。これにより、ローカル間の関係をベースにして効果的に確立できます。機能の類似性について。具体的には、最初に注目行列を次のように計算できます。
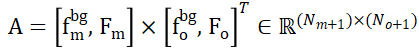
次に、分布行列を取得できます
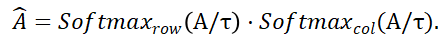
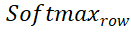 と
と 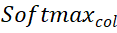 はそれぞれ行と列に沿ったソフトマックス演算を表し、
はそれぞれ行と列に沿ったソフトマックス演算を表し、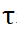 は定数を表します。
は定数を表します。 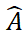 の各行 (最初の行を除く) の値は、点集合 P_m 内の各点 P_m と背景および P_o の中点との一致確率を表します。最大スコアのインデックスを見つけることで、点集合 P_m と一致する点が決定されます。を見つけることができます(背景を含む)。
の各行 (最初の行を除く) の値は、点集合 P_m 内の各点 P_m と背景および P_o の中点との一致確率を表します。最大スコアのインデックスを見つけることで、点集合 P_m と一致する点が決定されます。を見つけることができます(背景を含む)。
計算が  になると、すべての一致点ペア {(P_m,P_o)} とその一致スコアが収集され、最後に重み付き SVD を使用してオブジェクトの姿勢が計算されます。
になると、すべての一致点ペア {(P_m,P_o)} とその一致スコアが収集され、最後に重み付き SVD を使用してオブジェクトの姿勢が計算されます。
バックグラウンド トークンの戦略に基づいて、2 つの点セット マッチング ステージが PEM で設計されています。モデル構造は図 3 に示されており、3 つのステージが含まれていますモジュール: 特徴抽出、大まかな点セット マッチング、および詳細な点セット マッチング。
ラフ点セット マッチング モジュールは、スパース対応を実装してオブジェクトの初期姿勢を計算し、その姿勢を使用して候補オブジェクトの点セットを変換し、位置コーディング学習を実現します。 詳細点セット マッチング モジュールは、候補オブジェクトとターゲット オブジェクトのサンプル点セットの位置エンコーディングを組み合わせることで、第 1 段階で大まかな対応関係を注入し、さらに密な対応関係を確立して、より正確な対応関係を取得します。オブジェクトのポーズ。この段階で密な相互作用を効果的に学習するために、PEM は新しい疎から密への点集合変換器を導入します。これは、密な特徴の疎なバージョンで相互作用を実装し、線形変換器 [5] を利用して強化された疎な特徴を拡散に変換して密な特徴に戻します。特徴。 #########実験結果######
SAM-6D の 2 つのサブモデルの場合、インスタンス セグメンテーション モデル (ISM) はネットワークの再トレーニングや微調整を必要とせずに SAM に基づいて構築されますが、姿勢推定モデル (PEM) は MegaPose によって提供されます [4]トレーニング用の大規模な ShapeNet-Objects および Google-Scanned-Objects 合成データセット。
ゼロサンプル機能を検証するために、SAM-6D は、LM-O、T-LESS、TUD-L、IC-BIN、ITODD、HB を含む BOP [2] の 7 つのコア データ セットでテストされました。そしてYCB-V。表 1 と表 2 は、これら 7 つのデータセットに対するさまざまな方法によるインスタンスのセグメンテーションと姿勢推定の結果の比較をそれぞれ示しています。他の手法と比較して、SAM-6D は両方の手法で非常に優れたパフォーマンスを発揮し、その強力な汎化能力を十分に実証しています。
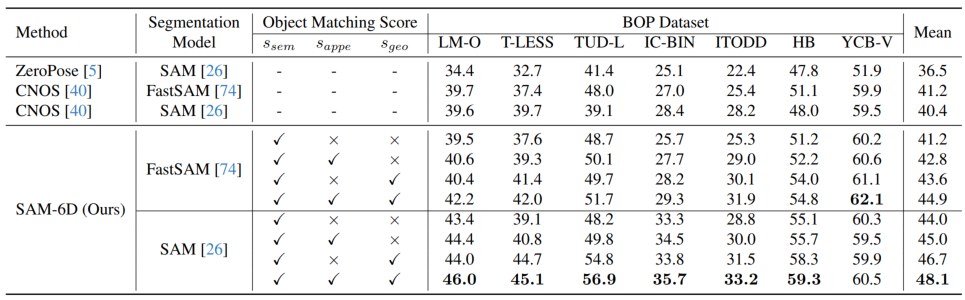
#表2.さまざまな方法の態度推定結果の比較BOP の 7 つのコア データ セットでの 
#図 4 は、7 つの BOP データ セットでの SAM-6D の検出セグメンテーションと 6D 姿勢推定の視覚化結果を示しています。ここで (a) と (b)はそれぞれテスト RGB 画像と深度マップ、(c) は指定されたターゲット オブジェクト、(d) と (e) はそれぞれ検出セグメンテーションと 6D ポーズの視覚化結果です。
図 4. BOP の 7 つのコア データセットに対する SAM-6D の視覚化結果。
参考資料:
[1] Alexander Kirillov 他、「Segment anything」
[2] Martin Sundermeyer 他。 al.、「特定の剛体オブジェクトの検出、セグメンテーション、姿勢推定に関する Bop チャレンジ 2022」
[3] Maxime Oquab et. al.、「Dinov2 : 監視なしで堅牢な視覚機能を学習します。"
[4] Yann Labbe et. al.、「Megapose: レンダリングと比較による新規オブジェクトの 6D 姿勢推定」 .”
[5] Angelos Katharopoulos et. al.、「トランスフォーマーは rnns: 高速自己回帰
」 ##リニアな注目を集めるトランスフォーマー。」
以上がCVPR 2024 | ゼロサンプル 6D オブジェクト姿勢推定フレームワーク SAM-6D、身体化されたインテリジェンスに一歩近づくの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7455
7455
 15
1375
52
77
11
14
9
15
1375
52
77
11
14
9

 ControlNet の作者がまたヒット作を出しました!写真から絵画を生成し、2 日間で 1.4,000 個のスターを獲得する全プロセス
Jul 17, 2024 am 01:56 AM
ControlNet の作者がまたヒット作を出しました!写真から絵画を生成し、2 日間で 1.4,000 個のスターを獲得する全プロセス
Jul 17, 2024 am 01:56 AM
これも Tusheng のビデオですが、PaintsUndo は別の道を歩んでいます。 ControlNet 作者 LvminZhang が再び生き始めました!今回は絵画の分野を目指します。新しいプロジェクト PaintsUndo は、開始されて間もなく 1.4kstar を獲得しました (まだ異常なほど上昇しています)。プロジェクトアドレス: https://github.com/lllyasviel/Paints-UNDO このプロジェクトを通じて、ユーザーが静止画像を入力すると、PaintsUndo が線画から完成品までのペイントプロセス全体のビデオを自動的に生成するのに役立ちます。 。描画プロセス中の線の変化は驚くべきもので、最終的なビデオ結果は元の画像と非常によく似ています。完成した描画を見てみましょう。
 RLHF から DPO、TDPO に至るまで、大規模なモデル アライメント アルゴリズムはすでに「トークンレベル」になっています
Jun 24, 2024 pm 03:04 PM
RLHF から DPO、TDPO に至るまで、大規模なモデル アライメント アルゴリズムはすでに「トークンレベル」になっています
Jun 24, 2024 pm 03:04 PM
AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com 人工知能の開発プロセスにおいて、大規模言語モデル (LLM) の制御とガイダンスは常に中心的な課題の 1 つであり、これらのモデルが両方とも確実に機能することを目指しています。強力かつ安全に人類社会に貢献します。初期の取り組みは人間のフィードバックによる強化学習手法に焦点を当てていました (RL
 オープンソース AI ソフトウェア エンジニアのリストのトップに立つ UIUC のエージェントレス ソリューションは、SWE ベンチの実際のプログラミングの問題を簡単に解決します
Jul 17, 2024 pm 10:02 PM
オープンソース AI ソフトウェア エンジニアのリストのトップに立つ UIUC のエージェントレス ソリューションは、SWE ベンチの実際のプログラミングの問題を簡単に解決します
Jul 17, 2024 pm 10:02 PM
AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出電子メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com この論文の著者は全員、イリノイ大学アーバナ シャンペーン校 (UIUC) の Zhang Lingming 教師のチームのメンバーです。博士課程4年、研究者
 OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
AIモデルによって与えられた答えがまったく理解できない場合、あなたはそれをあえて使用しますか?機械学習システムがより重要な分野で使用されるにつれて、なぜその出力を信頼できるのか、またどのような場合に信頼してはいけないのかを実証することがますます重要になっています。複雑なシステムの出力に対する信頼を得る方法の 1 つは、人間または他の信頼できるシステムが読み取れる、つまり、考えられるエラーが発生する可能性がある点まで完全に理解できる、その出力の解釈を生成することをシステムに要求することです。見つかった。たとえば、司法制度に対する信頼を築くために、裁判所に対し、決定を説明し裏付ける明確で読みやすい書面による意見を提供することを求めています。大規模な言語モデルの場合も、同様のアプローチを採用できます。ただし、このアプローチを採用する場合は、言語モデルが
 公理的トレーニングにより、LLM は因果推論を学習できます。6,700 万個のパラメータ モデルは、1 兆個のパラメータ レベル GPT-4 に匹敵します。
Jul 17, 2024 am 10:14 AM
公理的トレーニングにより、LLM は因果推論を学習できます。6,700 万個のパラメータ モデルは、1 兆個のパラメータ レベル GPT-4 に匹敵します。
Jul 17, 2024 am 10:14 AM
LLM に因果連鎖を示すと、LLM は公理を学習します。 AI はすでに数学者や科学者の研究を支援しています。たとえば、有名な数学者のテレンス タオは、GPT などの AI ツールを活用した研究や探索の経験を繰り返し共有しています。 AI がこれらの分野で競争するには、強力で信頼性の高い因果推論能力が不可欠です。この記事で紹介する研究では、小さなグラフでの因果的推移性公理の実証でトレーニングされた Transformer モデルが、大きなグラフでの推移性公理に一般化できることがわかりました。言い換えれば、Transformer が単純な因果推論の実行を学習すると、より複雑な因果推論に使用できる可能性があります。チームが提案した公理的トレーニング フレームワークは、デモンストレーションのみで受動的データに基づいて因果推論を学習するための新しいパラダイムです。
 arXiv 論文は「弾幕」として投稿可能、スタンフォード alphaXiv ディスカッション プラットフォームはオンライン、LeCun は気に入っています
Aug 01, 2024 pm 05:18 PM
arXiv 論文は「弾幕」として投稿可能、スタンフォード alphaXiv ディスカッション プラットフォームはオンライン、LeCun は気に入っています
Aug 01, 2024 pm 05:18 PM
乾杯!紙面でのディスカッションが言葉だけになると、どんな感じになるでしょうか?最近、スタンフォード大学の学生が、arXiv 論文のオープン ディスカッション フォーラムである alphaXiv を作成しました。このフォーラムでは、arXiv 論文に直接質問やコメントを投稿できます。 Web サイトのリンク: https://alphaxiv.org/ 実際、URL の arXiv を alphaXiv に変更するだけで、alphaXiv フォーラムの対応する論文を直接開くことができます。この Web サイトにアクセスする必要はありません。その中の段落を正確に見つけることができます。論文、文: 右側のディスカッション エリアでは、ユーザーは論文のアイデアや詳細について著者に尋ねる質問を投稿できます。たとえば、次のような論文の内容についてコメントすることもできます。
 リーマン予想の大きな進歩!陶哲軒氏はMITとオックスフォードの新しい論文を強く推薦し、37歳のフィールズ賞受賞者も参加した
Aug 05, 2024 pm 03:32 PM
リーマン予想の大きな進歩!陶哲軒氏はMITとオックスフォードの新しい論文を強く推薦し、37歳のフィールズ賞受賞者も参加した
Aug 05, 2024 pm 03:32 PM
最近、2000年代の7大問題の一つとして知られるリーマン予想が新たなブレークスルーを達成した。リーマン予想は、数学における非常に重要な未解決の問題であり、素数の分布の正確な性質に関連しています (素数とは、1 とそれ自身でのみ割り切れる数であり、整数論において基本的な役割を果たします)。今日の数学文献には、リーマン予想 (またはその一般化された形式) の確立に基づいた 1,000 を超える数学的命題があります。言い換えれば、リーマン予想とその一般化された形式が証明されれば、これらの 1,000 を超える命題が定理として確立され、数学の分野に重大な影響を与えることになります。これらの命題の一部も有効性を失います。 MIT数学教授ラリー・ガスとオックスフォード大学から新たな進歩がもたらされる
 無制限のビデオ生成、計画と意思決定、次のトークン予測とフルシーケンス拡散の拡散強制統合
Jul 23, 2024 pm 02:05 PM
無制限のビデオ生成、計画と意思決定、次のトークン予測とフルシーケンス拡散の拡散強制統合
Jul 23, 2024 pm 02:05 PM
現在、次のトークン予測パラダイムを使用した自己回帰大規模言語モデルが世界中で普及していると同時に、インターネット上の多数の合成画像やビデオがすでに拡散モデルの威力を示しています。最近、MITCSAIL の研究チーム (そのうちの 1 人は MIT の博士課程学生、Chen Boyuan です) は、全系列拡散モデルとネクスト トークン モデルの強力な機能を統合することに成功し、トレーニングおよびサンプリング パラダイムである拡散強制 (DF) を提案しました。 )。論文タイトル:DiffusionForcing:Next-tokenPredictionMeetsFull-SequenceDiffusion 論文アドレス:https:/
