
 テクノロジー周辺機器
AI
ケンブリッジ チームのオープン ソース: マルチモーダル大規模モデル RAG アプリケーションを強化する、初の事前トレーニング済みユニバーサル マルチモーダル ポストインタラクティブ ナレッジ リトリーバー
テクノロジー周辺機器
AI
ケンブリッジ チームのオープン ソース: マルチモーダル大規模モデル RAG アプリケーションを強化する、初の事前トレーニング済みユニバーサル マルチモーダル ポストインタラクティブ ナレッジ リトリーバー
ケンブリッジ チームのオープン ソース: マルチモーダル大規模モデル RAG アプリケーションを強化する、初の事前トレーニング済みユニバーサル マルチモーダル ポストインタラクティブ ナレッジ リトリーバー


- 紙のリンク: https://arxiv.org/abs/2402.08327
- デモリンク: https://u60544-b8d4-53eaa55d.westx.seetacloud.com:8443 /
- #プロジェクト ホームページのリンク: https://preflmr.github.io/ # #Paperタイトル: PreFLMR: きめの細かい遅延インタラクション マルチモーダル レトリバーのスケールアップ
- #背景
#大規模なマルチモーダル モデル (GPT4-Vision、Gemini など) は強力な一般的な画像およびテキスト理解機能を示していますが、専門知識が必要な問題を処理する場合、そのパフォーマンスは満足のいくものではありません。 GPT4-Vision でさえ、知識集約型の質問 (図 1 を参照) に効果的に答えることができず、多くのエンタープライズ レベルのアプリケーションに課題をもたらします。
GPT4-Vision は、PreFLMR マルチモーダル知識検索ツールを通じて関連する知識を取得し、正確な回答を生成できます。この図は、モデルの実際の出力を示しています。 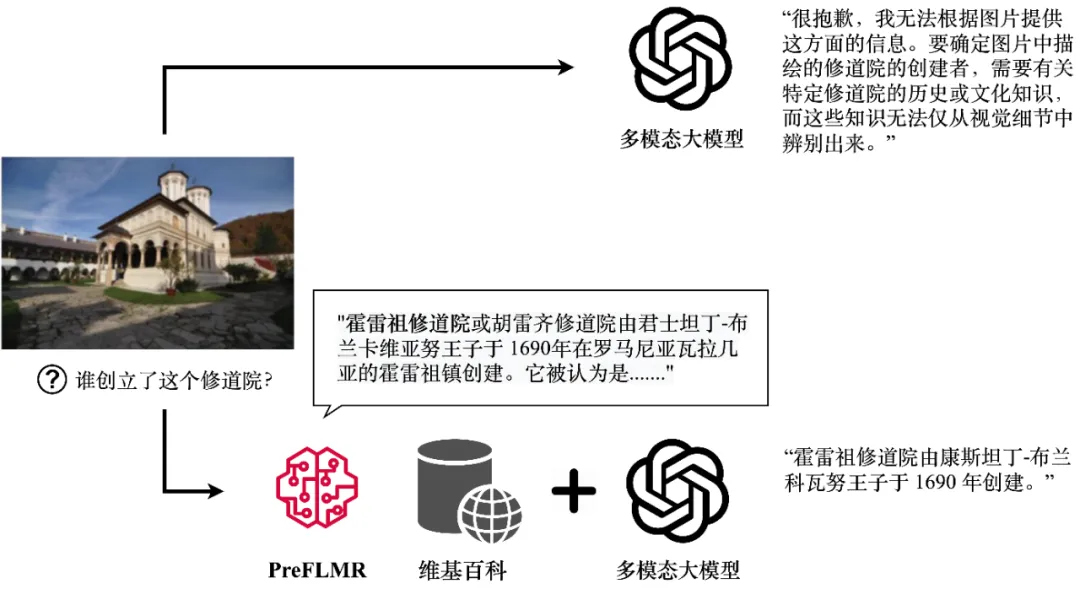
検索拡張生成 (RAG) は、この問題を解決するためのシンプルかつ効果的な方法を提供し、マルチモーダルな大規模モデルを特定の分野の「ドメイン」のようにします。その動作原理は次のとおりです: まず、軽量のナレッジ リトリーバー (Knowledge Retriever) を使用して、専門データベース (Wikipedia やエンタープライズ ナレッジ ベースなど) から関連する専門知識を取得します。次に、大規模モデルがこの知識と質問を入力として受け取ります。そして正確な答えを出力します。マルチモーダル知識抽出器の知識「想起能力」は、大規模モデルが推論の質問に答えるときに正確な専門知識を取得できるかどうかに直接影響します。
最近、ケンブリッジ大学情報工学部の人工知能研究室は、初の事前トレーニング済みユニバーサルマルチモーダルポストインタラクティブ知識検索を完全にオープンソース化しました。 PreFLMR
(事前トレーニングされたファイングレインレイトインタラクションマルチモーダルレトリバー)。 PreFLMR は、従来の一般的なモデルと比較して、次のような特徴があります。PreFLMR は、テキスト検索、画像検索、知識検索などの複数のサブタスクを効果的に解決できる一般的な事前トレーニング モデルです。このモデルは、数百万レベルのマルチモーダル データで事前トレーニングされており、複数の下流の検索タスクで適切に実行されます。さらに、PreFLMR は優れた基本モデルとして、プライベート データに合わせて微調整した後、すぐに優れたドメイン固有モデルに開発できます。
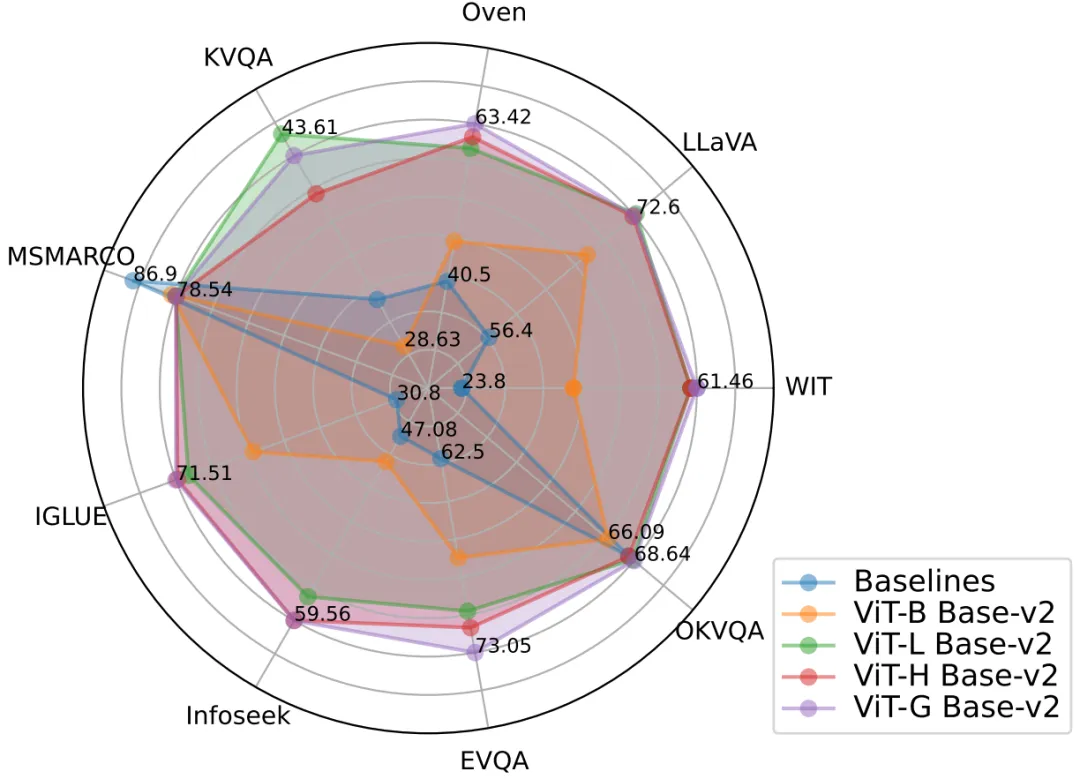
図 2: PreFLMR モデルは、同時に複数のタスクで優れたマルチモーダル検索パフォーマンスを達成し、非常に強力な事前トレーニング ベースとなります。 。 モデル。
2. 従来の密パッセージ検索 (DPR) は、クエリ (Query) またはドキュメント (Document) を表すために 1 つのベクトルのみを使用します。 NeurIPS 2023 で Cambridge チームが公開した FLMR モデルは、DPR の単一ベクトル表現設計がきめ細かい情報損失につながる可能性があり、その結果、詳細な情報照合が必要な検索タスクで DPR のパフォーマンスが低下する可能性があることを証明しました。特にマルチモーダル タスクでは、ユーザーのクエリには複雑なシーン情報が含まれており、それを 1 次元ベクトルに圧縮すると、特徴の表現能力が大幅に阻害されます。 PreFLMR は FLMR の構造を継承および改良し、マルチモーダルな知識検索において独自の利点をもたらします。
# 図 3: PreFLMR はクエリ (クエリ、左側の 1、2) を文字レベル (トークン) でエンコードします。レベル)、3)、ドキュメント(ドキュメント、右の4)は、すべての情報を1次元ベクトルに圧縮するDPRシステムと比較して、きめ細かい情報を得ることができるという利点があります。
3. PreFLMR は、ユーザーが入力した指示に従って、画像内のアイテムに関連するドキュメントを抽出できます (「次の質問に答えるために使用できるドキュメントを抽出する」など)。 「画像内のアイテムに関連するドキュメントを抽出する」) 関連するドキュメントがナレッジ ベースから抽出され、マルチモーダル大規模モデルによる専門知識の質問と回答のタスクのパフォーマンスが大幅に向上します。


#
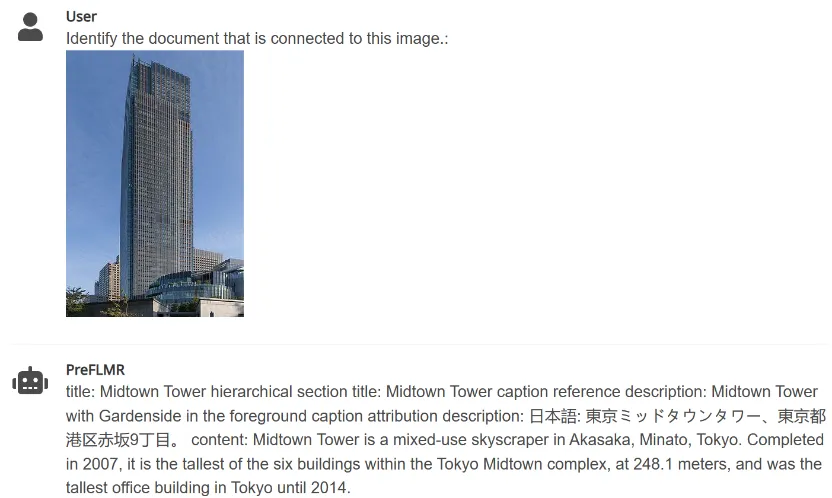
図 4: PreFLMR は、画像からドキュメントを抽出する、質問に基づいてドキュメントを抽出する、質問に基づいてドキュメントを抽出するマルチモーダル クエリを同時に処理できます。と写真を一緒に。
ケンブリッジ大学チームは、サイズの異なる 3 つのモデルをオープンソース化しました。小規模から大規模までのモデルのパラメーターは次のとおりです: PreFLMR_ViT-B (207M)、PreFLMR_ViT-L ( 422M) )、PreFLMR_ViT-G (2B)、ユーザーが実際の条件に応じて選択できます。
オープン ソース モデル PreFLMR 自体に加えて、このプロジェクトはこの研究の方向性において 2 つの重要な貢献も行いました:
- このプロジェクトと同時に、一般知識検索のトレーニングと評価のための大規模なデータセットであるマルチタスク マルチモーダル知識検索ベンチマーク (M2KR) がオープンソース化され、これには学術分野で広く研究されている 10 個の検索サブタスクが含まれます。コミュニティに登録されており、合計 100 万件以上の検索が行われています。
- 論文の中で、ケンブリッジ大学のチームは、さまざまなサイズと性能の画像エンコーダとテキストエンコーダを比較し、拡張パラメータと事前トレーニングマルチモーダルポストインタラクティブ知識検索システムを要約しました。将来の一般的な検索モデルに経験的なガイダンスを提供するベスト プラクティス。
以下では、M2KR データセット、PreFLMR モデル、実験結果解析について簡単に紹介します。
M2KR データセット
一般的なマルチモーダル検索モデルを大規模に事前トレーニングして評価するために、著者は公開されている 10 個のデータセットをコンパイルし、それを次の形式に変換しました。統一された質問文書検索形式。これらのデータセットの本来のタスクには、画像キャプション、マルチモーダルダイアログなどが含まれます。以下の図は、5 つのタスクに対する質問 (1 行目) と対応するドキュメント (2 行目) を示しています。

#図 5: M2KR データセットの知識抽出タスクの一部
PreFLMR 検索モデル
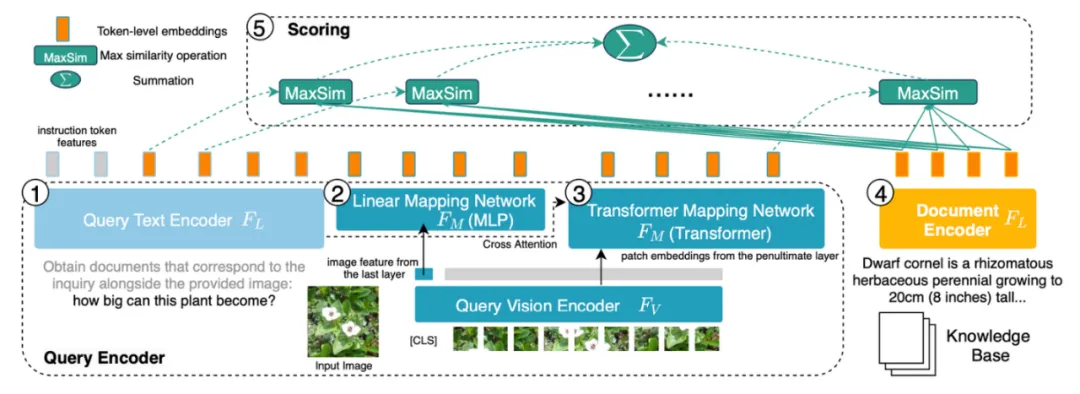
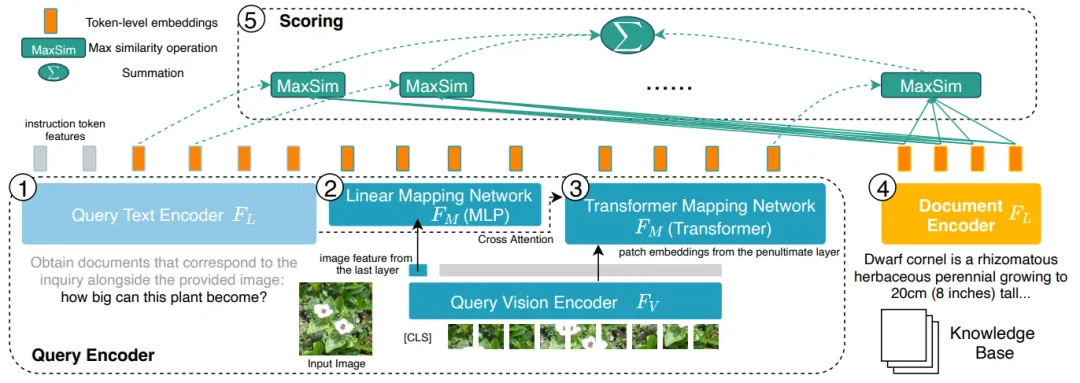
# 図 6: PreFLMR のモデル構造。クエリはトークンレベルの機能としてエンコードされます。クエリ行列内のベクトルごとに、PreFLMR はドキュメント行列内で最も近いベクトルを見つけてドット積を計算し、これらの最大ドット積を合計して最終的な関連性を取得します。
PreFLMR モデルは、NeurIPS 2023 で公開されたファイングレイン レイト インタラクション マルチモーダル レトリバー (FLMR) に基づいており、モデルの改良と M2KR での大規模な事前トレーニングが行われています。 DPR と比較して、FLMR および PreFLMR は、すべてのトークン ベクトルで構成される行列を使用してドキュメントとクエリを特徴付けます。トークンには、テキスト トークンとテキスト空間に投影された画像トークンが含まれます。遅延相互作用は、2 つの表現行列間の相関を効率的に計算するためのアルゴリズムです。具体的な方法は、クエリ行列内のベクトルごとに、ドキュメント行列内の最も近いベクトルを見つけて、ドット積を計算することです。これらの最大ドット積が合計されて、最終的な相関関係が得られます。このようにして、各トークンの表現が最終的な相関関係に明示的に影響を与えることができるため、トークンレベルのきめ細かい情報が維持されます。専用のポストインタラクティブ検索エンジンのおかげで、PreFLMR はわずか 0.2 秒で 400,000 のドキュメントから 100 の関連ドキュメントを抽出でき、RAG シナリオでの使いやすさが大幅に向上します。
PreFLMR の事前トレーニングは、次の 4 つの段階で構成されます。
- テキスト エンコーダーの事前トレーニング: まず、PreFLMR のテキスト エンコーダーとして MSMAARCO (純粋なテキスト知識検索データ セット) 上で後期対話型テキスト検索モデルを事前トレーニングしました。
- 画像テキスト投影レイヤーの事前トレーニング: 次に、M2KR で画像テキスト投影レイヤーをトレーニングし、他の部分をフリーズします。この段階では、モデルがテキスト情報に過度に依存しないようにすることを目的として、投影された画像ベクトルのみを検索に使用します。
- 継続的な事前トレーニング: 次に、E-VQA での高品質の知識集約型視覚的質問応答タスクのトレーニングを継続します。 M2KR テキスト エンコーダと画像 - テキスト プロジェクション レイヤー。この段階では、PreFLMR の詳細な知識検索機能を向上させることを目的としています。
- ユニバーサル検索トレーニング: 最後に、M2KR データセット全体ですべての重みをトレーニングし、画像エンコーダーのみをフリーズします。同時に、クエリ テキスト エンコーダーとドキュメント テキスト エンコーダーのパラメーターのロックが解除され、別々にトレーニングされます。この段階は、PreFLMR の一般的な検索機能を向上させることを目的としています。
同時に、著者らは、PreFLMR をサブデータセット (OK-VQA、Infoseek など) でさらに微調整して、より優れた検索パフォーマンスを得ることができることを示しています。特定のタスク。
実験結果と垂直拡張
最良の検索結果: 最もパフォーマンスの高い PreFLMR モデルは、画像エンコーダーとして ViT-G と ColBERT ベースを使用します。 -v2 はテキスト エンコーダとして、合計 20 億のパラメータ。 7 つの M2KR 取得サブタスク (WIT、OVEN、Infoseek、E-VQA、OKVQA など) でベースライン モデルを超えるパフォーマンスを実現します。
拡張ビジュアル エンコーディングはより効果的です。著者は、画像エンコーダ ViT を ViT-B (86M) から ViT-L (307M) にアップグレードすると大幅なパフォーマンスの向上が得られるが、テキスト エンコーダ ColBERT を Expanding ベースからアップグレードすることを発見しました。 (110M) から大規模 (345M) まではパフォーマンスの低下とトレーニングの不安定性をもたらしました。実験結果は、後のインタラクティブなマルチモーダル検索システムでは、ビジュアル エンコーダのパラメータを増やすと、より大きな利益がもたらされることを示しています。同時に、画像テキスト投影に複数のクロスアテンション層を使用すると、単一層を使用する場合と同じ効果が得られるため、画像テキスト投影ネットワークの設計をそれほど複雑にする必要はありません。
PreFLMR により、RAG がより効果的になります。知識集約型の視覚的な質問応答タスクでは、PreFLMR を使用した検索強化により、最終システムのパフォーマンスが大幅に向上しました。Infoseek と EVQA でそれぞれ 94% に達しました。効果が 275% 向上。簡単な微調整の後、BLIP-2 ベースのモデルは、数千億のパラメータを備えた PALI-X モデルや、Google API で強化された PaLM-Bison レンズ システムを上回ることができます。
結論
ケンブリッジ人工知能研究所によって提案された PreFLMR モデルは、初のオープンソースの汎用後期対話型マルチモーダル検索モデルです。 M2KR 上の数百万のデータで事前トレーニングした後、PreFLMR は複数の取得サブタスクで優れたパフォーマンスを示します。 M2KR データセット、PreFLMR モデルの重み、およびコードは、プロジェクトのホームページ https://preflmr.github.io/ で入手できます。
#リソースを展開
- ##FLMR 論文 (NeurIPS 2023): https: / /proceedings.neurips.cc/paper_files/paper/2023/hash/47393e8594c82ce8fd83adc672cf9872-Abstract-Conference.html
- コードベース: https://github.com/LinWeizheDragon/Retrieval- Augmented -Visual-Question-Answering
- 英語版ブログ: https://www.jinghong-chen.net/preflmr-sota-open-sourced-multi/
- FLMR の概要: https://www.jinghong-chen.net/fined-graned-late-interaction-multimodal-retrieval-flmr/
- # #
以上がケンブリッジ チームのオープン ソース: マルチモーダル大規模モデル RAG アプリケーションを強化する、初の事前トレーニング済みユニバーサル マルチモーダル ポストインタラクティブ ナレッジ リトリーバーの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7554
7554
 15
1382
52
83
11
24
96
15
1382
52
83
11
24
96

 Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centosシャットダウンコマンドライン
Apr 14, 2025 pm 09:12 PM
Centos Shutdownコマンドはシャットダウンし、構文はシャットダウン[オプション]時間[情報]です。オプションは次のとおりです。-hシステムをすぐに停止します。 -pシャットダウン後に電源をオフにします。 -r再起動; -t待機時間。時間は、即時(現在)、数分(分)、または特定の時間(HH:mm)として指定できます。追加の情報をシステムメッセージに表示できます。
 Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosのgitlabのバックアップ方法は何ですか
Apr 14, 2025 pm 05:33 PM
Centosシステムの下でのGitlabのバックアップと回復ポリシーデータセキュリティと回復可能性を確保するために、Gitlab on Centosはさまざまなバックアップ方法を提供します。この記事では、いくつかの一般的なバックアップ方法、構成パラメーター、リカバリプロセスを詳細に紹介し、完全なGitLabバックアップと回復戦略を確立するのに役立ちます。 1.手動バックアップGitlab-RakeGitlabを使用:バックアップ:コマンドを作成して、マニュアルバックアップを実行します。このコマンドは、gitlabリポジトリ、データベース、ユーザー、ユーザーグループ、キー、アクセスなどのキー情報をバックアップします。デフォルトのバックアップファイルは、/var/opt/gitlab/backupsディレクトリに保存されます。 /etc /gitlabを変更できます
 CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CentOS HDFS構成をチェックする方法
Apr 14, 2025 pm 07:21 PM
CENTOSシステムでHDFS構成をチェックするための完全なガイドこの記事では、CENTOSシステム上のHDFSの構成と実行ステータスを効果的に確認する方法をガイドします。次の手順は、HDFSのセットアップと操作を完全に理解するのに役立ちます。 Hadoop環境変数を確認します。最初に、Hadoop環境変数が正しく設定されていることを確認してください。端末では、次のコマンドを実行して、Hadoopが正しくインストールおよび構成されていることを確認します。HDFS構成をチェックするHDFSファイル:HDFSのコア構成ファイルは/etc/hadoop/conf/ディレクトリにあります。使用
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
Centosはmysqlをインストールします
Apr 14, 2025 pm 08:09 PM
CentOSにMySQLをインストールするには、次の手順が含まれます。適切なMySQL Yumソースの追加。 yumを実行して、mysql-serverコマンドをインストールして、mysqlサーバーをインストールします。ルートユーザーパスワードの設定など、MySQL_SECURE_INSTALLATIONコマンドを使用して、セキュリティ設定を作成します。必要に応じてMySQL構成ファイルをカスタマイズします。 MySQLパラメーターを調整し、パフォーマンスのためにデータベースを最適化します。
 Centos8はsshを再起動します
Apr 14, 2025 pm 09:00 PM
Centos8はsshを再起動します
Apr 14, 2025 pm 09:00 PM
SSHサービスを再起動するコマンドは次のとおりです。SystemCTL再起動SSHD。詳細な手順:1。端子にアクセスし、サーバーに接続します。 2。コマンドを入力します:SystemCtl RestArt SSHD; 3.サービスステータスの確認:SystemCTLステータスSSHD。
 CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
CentosでPytorchの分散トレーニングを操作する方法
Apr 14, 2025 pm 06:36 PM
Pytorchの分散トレーニングでは、Centosシステムでトレーニングには次の手順が必要です。Pytorchのインストール:PythonとPipがCentosシステムにインストールされていることです。 CUDAバージョンに応じて、Pytorchの公式Webサイトから適切なインストールコマンドを入手してください。 CPUのみのトレーニングには、次のコマンドを使用できます。PipinstalltorchtorchtorchvisionTorchaudioGPUサポートが必要な場合は、CUDAとCUDNNの対応するバージョンがインストールされ、インストールに対応するPytorchバージョンを使用してください。分散環境構成:分散トレーニングには、通常、複数のマシンまたは単一マシンの複数GPUが必要です。場所
