

産業用アプリケーションを機械学習で強化するにはどうすればよいでしょうか?

機器の故障は産業部門に深刻な問題を引き起こし、生産損失や計画外のダウンタイムを引き起こします。この状況は世界中の加工メーカーにとって深刻な課題であり、年間数十億ドルに達する可能性のある損失を引き起こしています。たとえば、主要な生産設備が突然故障した場合、生産ライン全体が数時間停止し、サプライチェーン全体の運営に影響を与える可能性があります。

幸いなことに、最新の機械学習 (ML) は画期的なソリューションを提供します。 ML アルゴリズムは大量のセンサー データを分析することで、障害やバックログを発生前に予測し、事前の修復を可能にし、ダウンタイムを大幅に削減します。しかし、それだけではありません。ML は実稼働データの隠れたパターンも明らかにし、プロセスを最適化し、無駄を削減し、全体的な効率を向上させます。
組織が機械学習の可能性を最大限に発揮するには、まずチーム コラボレーションの基本要素の強化を開始する必要があります。正確で影響力のあるモデルを構築するには、データ サイエンティストと分野の専門家が緊密に連携し、産業機器の複雑さを深く理解する必要があります。彼らのコラボレーションは、製造現場の専門知識をデータ言語に変換し、機械学習ソリューションの適用を成功に導きます。
従来の産業データの欠点を克服する
ML の洞察を使用して業務効率を向上させることは、一夜にして実現するものではありません。最初の課題は、生の産業データを理解することです。
産業データは、ネイティブ形式では膨大かつ多様であり、多くの場合、停止ログなどの誤った情報や無関係な情報が含まれています。ガイダンスがなければ、データ サイエンティストは、無関係な複雑性を選別して貴重な時間とリソースを浪費し、誤解を招くモデルを作成してしまうことがよくあります。このため、プロセス エンジニアやオペレーターなどの専門家は、正確なモデル用のデータを準備する際に重要であり、彼らの広範なプロセス知識は、正しいデータと関連する期間を決定するのに役立ちます。
ただし、適切なデータを特定することは最初のステップにすぎません。生の産業データは多くの場合乱雑であり、理解するにはコンテキストが必要です。メンテナンス中の温度測定値が動作中の温度測定値と混合されているモデルがあることを想像してください。これにより、予測モデルが混乱に陥ることになります! 手掛かりなしでモデルにデータを挿入すると、大混乱が生じる可能性があり、分析を実行する際にデータのクリーニングとコンテキスト化の重要性が示唆されます。予め。プロセスの専門家は、そのような考慮事項を特定し、アルゴリズムのエラーを減らし、一貫性を確保し、モデルの成功に最も重要な特定の動作条件を特定するのに役立ちます。
データがクリーンアップされた後も、ML で使用できるようにするためにやるべき作業がまだたくさんあります。特徴量エンジニアリングはこのギャップを埋めるものであり、生の読み取り値を目の前の問題に直接対処するコンテキストに即した洞察に変換するには、データ サイエンティストとプロセス専門家の継続的なコラボレーションが必要です。これらの情報洞察、つまり「シグネチャ」には、統計的な概要、頻度パターン、および ML アルゴリズムが隠れたパターンを発見し、モデルの精度を向上させ、複雑な運用上の決定を支援するのに役立つセンサー データのその他の賢い組み合わせが含まれます。
産業環境で ML モデルを導入するには、精度以上のものが必要です。真に価値を生み出すためには、モデルは生産プロセスで使用するためにオペレーターに簡単に転送できる必要があります。これは、インターフェイスが読みやすく、予測、アラート、リアルタイム データを明確かつ簡潔に表示する必要があることを意味します。さらに、可能な場合は、操作インターフェイスに説明を含めることで、エンド ユーザー間の信頼と理解を構築します。
産業プロセスは時間の経過とともに変化するため、機械学習を適切に導入するには、モデルを新しいデータで定期的に再トレーニングして精度を確保する必要があります。これには、データ サイエンティストと運用チームが緊密に連携してパフォーマンスを監視し、モデルを継続的に反復処理する必要があります。
高度な分析により産業用機械学習の取り組みが強化
運用ワークフローで ML モデルを構築および実装する多くの手順は簡単ではありませんが、最新の高度な分析ソリューションにより ML 統合のプロセスが簡素化され、全体的なソリューションを提供します産業プロセス向け。
これらのソリューションは、複数のデータ ソースをリアルタイムで接続することで、一般的な産業データの混乱を打破します。これらのソフトウェア ツールは、集計に加えてデータ クリーニングを自動化し、多くの手動データ処理と調整を排除します (図 1)。
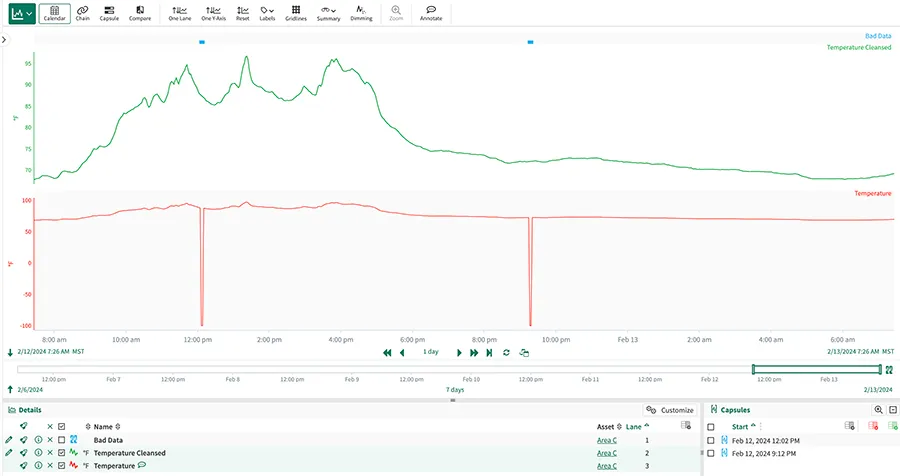
図 1: Seeq は、一連の組み込みの平滑化メソッドを使用してデータ クリーニングを自動化し、プラントのパフォーマンスの状況に応じた全体像を提供します。たとえば、2 つの不適切な温度測定値は、精製されたプロセス変数から自動的に削除され、プロセスに関する洞察のモデリングと作成に使用されます。
この適応性は、ML モデルを最新の状態に保ち、現在の動作条件を反映する関連情報を提供するため、プロセスが変化する場合に非常に重要です。たとえば、コンベア ベルトの故障シナリオでは、高度な分析ソリューションにより、エンジニアは異常を迅速に特定し、不一致に対処し、意味のある情報を即座に抽出できます。この高品質のデータは、トラブルシューティングの手順を知らせ、実用的な ML の洞察を提供し、運用上の意思決定の信頼性を高めることができます。
特徴量エンジニアリングは産業環境における機械学習の成功に不可欠ですが、コラボレーションが必要です。高度な分析ソリューションは、さまざまな専門家の役割に合わせて構築された明確に厳選されたユーザー プロファイルと、運用チーム間で調査結果をシームレスに共有するために必要なツールを通じて、この必要な相乗効果を促進します (図 2)。
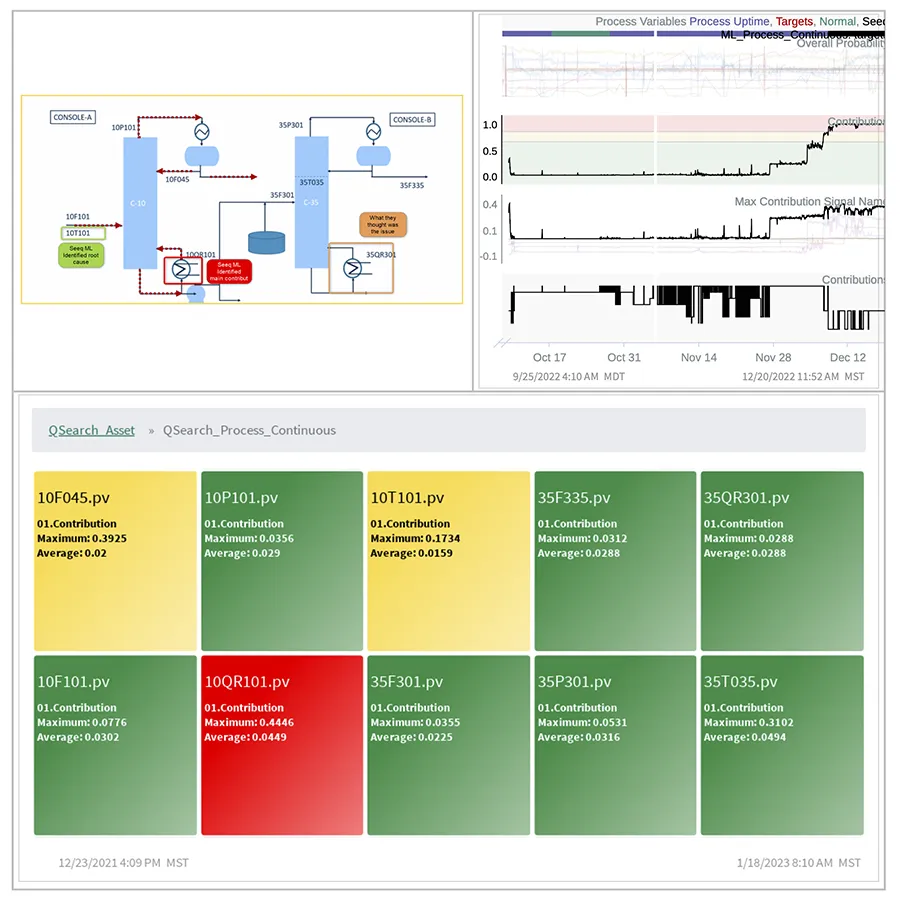
図 2: Seeq は、自動レポートとダッシュボードを簡単に構築することで ML を実装し、エンジニアやデータ サイエンティストが分析結果を基幹業務チームや運用チームと共有して推進できるようにします。日々の価値。
たとえば、Seeq の Data Lab を使用すると、データ サイエンティストはモデルを簡単にデプロイして、エンジニアリング チームや運用チームが直接使用できるようになり、フィードバックを提供してモデルを改良できるようになります。予測とアラートは、ワークベンチ、オーガナイザー、および外部視覚化ツールに送られ、通常は管理ユーザーがアクセスできます。高度な分析ソリューションは、歴史的に別々だったこれらの部門の橋渡しをし、モデルを強力なツールに変換して、組織全体でのより厳密なプロセス制御、運用の最適化、より賢明な意思決定を実現します。
予測分析によるコンプレッサーの故障の制御
実際の結果は、高度な分析ソリューションがコストのかかるダウンタイム イベントを効果的に削減できることを示しています。たとえば、重要なコンプレッサーの予期せぬ故障に悩まされている大手化学メーカーは、Seeq ソリューションを使用して、ある動作サイクルから別の動作サイクルまでのコンプレッサーの微妙な偏差を特定しました。損失は 1 件あたり 100 万ドルと推定されており、これらの障害を予測して防止する方法を見つけることがすぐに優先事項になりました。
同社は大量のプロセス データの収集を開始しましたが、データは 170 を超える変数を含む大規模かつ複雑なものであったため、ノイズから真のパターンを識別するのは困難でした。従来の分析方法では、障害の原因となっている可能性のある要因の組み合わせを特定できません。
このメーカーは Seeq に注目し、ソフトウェアに組み込まれた ML ツールを活用して、データ サイエンティストに全面的に依存することなく、自社のドメインの専門家がモデル開発の問題を解決できるようにしました。このソリューションのユーザーフレンドリーなインターフェイスは、包括的なコンプレッサーの専門知識を持つプロセス エンジニアの手に ML のパワーを直接与え、従来の分析では達成がより困難であった中小企業とデータ サイエンティストの間の知識のギャップを埋めるのに役立ちます。これは、予測モデルにドメインの正しい理解と進化を確実に組み込むのに役立ちます。
同社は、高度な分析ソリューションの専用機能を活用することで、モデルの結果をほぼリアルタイムの運用上の洞察に変換します。このモデルは、問題を示すコンプレッサー パラメーターの微妙な偏差に焦点を当てており、視覚的なダッシュボードは、運用チームやエンジニアリング チームに早期に警告を発し、コストのかかる障害を回避するための予防措置を講じるのに役立ちます。この予測アプローチにより、チームは事後的なメンテナンスを予防的な戦略に変えることができます。
同社は、問題が発生する前に問題を解決することで、コストのかかるダウンタイム イベントを大幅に削減します。高度な分析ソリューションは、技術的なバックボーンを提供するだけでなく、新しいデータの流動性も提供し、エンジニアが機器の状態をより適切に制御できるようにします。
メーターの凍結問題を解決し、ガス供給を最適化する
メーターの凍結は石油とガスのサプライヤーの収益を脅かし、測定エラーや高価な製品の廃棄につながります。問題の規模は、32,000マイルのパイプラインにまたがり、1日あたり74億立方フィートの天然ガスを処理する、ある事業者の広大なネットワークによって増幅されます。フリーズ イベントを特定するための乱雑なデータとルールベースのアプローチへの依存は、時間がかかり信頼性が低いことが判明し、ルールの維持には貴重なリソースが消費されるだけでなく、多くの誤検知や検出漏れをフィルタリングする必要がありました。
同社は、清掃を合理化し、膨大な量のメーター データにアクセスするための新しい方法を必要としていました。ドメインの専門家はソフトウェア ツールを使用してデータ品質を向上させ、過去の凍結されたイベントに注釈を付けます。一方、データ サイエンティストはエンジニアと協力して正確なモデルを開発し、厳格なルールを超えて ML を採用します。
高度な分析ソリューションでは、オペレーターは、データの前処理、モデル構成、自動再トレーニングを含む完全に自動化されたワークフローを確立し、動作条件の変化に応じてモデルの精度を維持します。モデルの予測は視覚的なダッシュボードと入力されたレポートに直接フィードされ、潜在的なフリーズの問題についてのリアルタイムの洞察を関係者に提供します。
この合理化されたワークフローにより、一部の場所で精度がわずかに向上したとしても、フリーズの問題を軽減するために積極的に介入することができ、その結果、製品の特典が減り、年間数百万ドルの節約につながります。このソリューションは、精度の向上に加えて、業務効率を継続的に向上させるために不可欠なデータ駆動型のコラボレーションを促進します。
この取り組みは、ベンダーにとって 3 つの重要な成果をもたらします。
- スケーラビリティ: 高度な分析ソリューションは、大規模な資産である企業の膨大なデータ セットを処理できます。 管理の主な利点。
- ML による効率の向上: 自動検出タスクにより、エンジニアはより価値の高い問題に集中できるようになります。
- 洞察から収益性へ: 高度な分析ソリューションは、効果的な ML 導入の重要な兆候である、予測からコスト削減までのプロセスを簡素化します。
産業環境における機械学習の効果的な導入
機械学習が製造プロセスを変えていることは否定できません。複雑なタスクを自動化し、生産サイクルを最適化し、予知保全を可能にするその機能は、従来の方法に比べて明らかな利点をもたらします。 ML は、資産の稼働時間を増やし、スループットを向上させ、意思決定プロセスを強化することにより、多くの産業分野で効率を高め、コストを削減します。
ML の導入には独自の課題がありますが、障害をはるかに上回る多大なメリットがあり、高度な分析ソリューションは導入を確実に成功させるのに役立ちます。これらのソフトウェア ツールは強力なデータ分析機能を提供し、産業環境における時系列データと ML アプリケーションのニーズに対応するように特別に設計されています。ユーザーフレンドリーなインターフェイスとコラボレーションに重点を置いたこれらのソリューションにより、企業は機械学習ベースの洞察を全面的に導入でき、競争が激化する製造市場において大幅な効率性と収益性のメリットをもたらします。
以上が産業用アプリケーションを機械学習で強化するにはどうすればよいでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7725
7725
 15
1643
14
1397
52
1290
25
1233
29
15
1643
14
1397
52
1290
25
1233
29

 オープンソースの無料画像注釈ツールおすすめ 15 選
Mar 28, 2024 pm 01:21 PM
オープンソースの無料画像注釈ツールおすすめ 15 選
Mar 28, 2024 pm 01:21 PM
画像の注釈は、ラベルまたは説明情報を画像に関連付けて、画像の内容に深い意味と説明を与えるプロセスです。このプロセスは機械学習にとって重要であり、画像内の個々の要素をより正確に識別するために視覚モデルをトレーニングするのに役立ちます。画像に注釈を追加することで、コンピュータは画像の背後にあるセマンティクスとコンテキストを理解できるため、画像の内容を理解して分析する能力が向上します。画像アノテーションは、コンピュータ ビジョン、自然言語処理、グラフ ビジョン モデルなどの多くの分野をカバーする幅広い用途があり、車両が道路上の障害物を識別するのを支援したり、障害物の検出を支援したりするなど、幅広い用途があります。医用画像認識による病気の診断。この記事では主に、より優れたオープンソースおよび無料の画像注釈ツールをいくつか推奨します。 1.マケセンス
 この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
機械学習とデータ サイエンスの分野では、モデルの解釈可能性が常に研究者や実務家に焦点を当ててきました。深層学習やアンサンブル手法などの複雑なモデルが広く適用されるようになったことで、モデルの意思決定プロセスを理解することが特に重要になってきました。 Explainable AI|XAI は、モデルの透明性を高めることで、機械学習モデルに対する信頼と自信を構築するのに役立ちます。モデルの透明性の向上は、複数の複雑なモデルの普及や、モデルを説明するための意思決定プロセスなどの方法によって実現できます。これらの方法には、特徴重要度分析、モデル予測間隔推定、ローカル解釈可能性アルゴリズムなどが含まれます。特徴重要度分析では、入力特徴に対するモデルの影響度を評価することで、モデルの意思決定プロセスを説明できます。モデルの予測間隔の推定
 学習曲線を通じて過学習と過小学習を特定する
Apr 29, 2024 pm 06:50 PM
学習曲線を通じて過学習と過小学習を特定する
Apr 29, 2024 pm 06:50 PM
この記事では、学習曲線を通じて機械学習モデルの過学習と過小学習を効果的に特定する方法を紹介します。過小適合と過適合 1. 過適合 モデルがデータからノイズを学習するためにデータ上で過学習されている場合、そのモデルは過適合していると言われます。過学習モデルはすべての例を完璧に学習するため、未確認の新しい例を誤って分類してしまいます。過適合モデルの場合、完璧/ほぼ完璧なトレーニング セット スコアとひどい検証セット/テスト スコアが得られます。若干修正: 「過学習の原因: 複雑なモデルを使用して単純な問題を解決し、データからノイズを抽出します。トレーニング セットとしての小さなデータ セットはすべてのデータを正しく表現できない可能性があるため、2. 過学習の Heru。」
 透明!主要な機械学習モデルの原理を徹底的に分析!
Apr 12, 2024 pm 05:55 PM
透明!主要な機械学習モデルの原理を徹底的に分析!
Apr 12, 2024 pm 05:55 PM
平たく言えば、機械学習モデルは、入力データを予測された出力にマッピングする数学関数です。より具体的には、機械学習モデルは、予測出力と真のラベルの間の誤差を最小限に抑えるために、トレーニング データから学習することによってモデル パラメーターを調整する数学関数です。機械学習には、ロジスティック回帰モデル、デシジョン ツリー モデル、サポート ベクター マシン モデルなど、多くのモデルがあります。各モデルには、適用可能なデータ タイプと問題タイプがあります。同時に、異なるモデル間には多くの共通点があったり、モデル進化の隠れた道が存在したりすることがあります。コネクショニストのパーセプトロンを例にとると、パーセプトロンの隠れ層の数を増やすことで、それをディープ ニューラル ネットワークに変換できます。パーセプトロンにカーネル関数を追加すると、SVM に変換できます。これです
 宇宙探査と人類居住工学における人工知能の進化
Apr 29, 2024 pm 03:25 PM
宇宙探査と人類居住工学における人工知能の進化
Apr 29, 2024 pm 03:25 PM
1950 年代に人工知能 (AI) が誕生しました。そのとき、研究者たちは、機械が思考などの人間と同じようなタスクを実行できることを発見しました。その後、1960 年代に米国国防総省は人工知能に資金を提供し、さらなる開発のために研究所を設立しました。研究者たちは、宇宙探査や極限環境での生存など、多くの分野で人工知能の応用を見出しています。宇宙探査は、地球を超えた宇宙全体を対象とする宇宙の研究です。宇宙は地球とは条件が異なるため、極限環境に分類されます。宇宙で生き残るためには、多くの要素を考慮し、予防策を講じる必要があります。科学者や研究者は、宇宙を探索し、あらゆるものの現状を理解することが、宇宙の仕組みを理解し、潜在的な環境危機に備えるのに役立つと信じています。
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 フラッシュ アテンションは安定していますか?メタとハーバードは、モデルの重みの偏差が桁違いに変動していることを発見しました
May 30, 2024 pm 01:24 PM
フラッシュ アテンションは安定していますか?メタとハーバードは、モデルの重みの偏差が桁違いに変動していることを発見しました
May 30, 2024 pm 01:24 PM
MetaFAIR はハーバード大学と協力して、大規模な機械学習の実行時に生成されるデータの偏りを最適化するための新しい研究フレームワークを提供しました。大規模な言語モデルのトレーニングには数か月かかることが多く、数百、さらには数千の GPU を使用することが知られています。 LLaMA270B モデルを例にとると、そのトレーニングには合計 1,720,320 GPU 時間が必要です。大規模なモデルのトレーニングには、これらのワークロードの規模と複雑さにより、特有のシステム上の課題が生じます。最近、多くの機関が、SOTA 生成 AI モデルをトレーニングする際のトレーニング プロセスの不安定性を報告しています。これらは通常、損失スパイクの形で現れます。たとえば、Google の PaLM モデルでは、トレーニング プロセス中に最大 20 回の損失スパイクが発生しました。数値的なバイアスがこのトレーニングの不正確さの根本原因です。
