

CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。

前に書いた&著者の個人的な理解
現在、自動運転システム全体において、道路を走行するときに認識モジュールが重要な役割を果たします 自動運転車の後にのみ認識モジュールを通じて正確なセンシング結果を取得し、自動運転システムの下流の制御モジュールはタイムリーで正しい判断と行動決定を行うことができます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。
純粋な視覚に基づくBEV知覚アルゴリズムは、ハードウェアコストが低く、導入が容易であり、その出力結果はさまざまな下流タスクに簡単に適用できるため、産業界および学界から広く注目されています。近年、BEV空間に基づく多くの視覚認識アルゴリズムが次々に登場し、公開データセット上で優れた認識性能を実証しています。
現在、BEV 空間に基づく知覚アルゴリズムは、BEV 特徴の構築方法に基づいて 2 種類のアルゴリズム モデルに大別できます。
- 1 つのタイプは前方 BEV 特徴で表されます。 LSS アルゴリズムによる 構築方法: このタイプの知覚アルゴリズム モデルは、最初に知覚モデル内の深度推定ネットワークを使用して、特徴マップの各ピクセルの意味論的特徴情報と離散深度確率分布を予測し、次に外部メソッドを使用して、意味的特徴情報と離散深さ確率を取得し、積演算によって意味的錐台特徴を構築し、BEV プーリングおよびその他の方法を使用して、最終的に BEV 空間特徴の構築プロセスを完了します。
- もう 1 つのタイプは、BEVFormer アルゴリズムに代表される逆 BEV 特徴構築方法です。このタイプの知覚アルゴリズム モデルは、まず知覚される BEV 空間内の 3D ボクセル座標点を明示的に生成し、次にカメラの内部および外部の座標点を使用します。パラメータは、3D ボクセル座標点を画像座標系に投影し、対応する特徴位置でピクセル特徴を抽出および集約して、BEV 空間内に BEV 特徴を構築します。
どちらのアルゴリズムも BEV 空間で正確に特徴を生成し、3D 知覚結果を達成できますが、BEVFormer アルゴリズムなど、BEV 空間に基づく現在の 3D ターゲット知覚アルゴリズムには次の 2 つの問題があります。 ##
- 質問 1: BEVFormer 知覚アルゴリズム モデルの全体的なフレームワークはエンコーダー-デコーダー ネットワーク構造を採用しているため、主なアイデアはエンコーダー モジュールを使用して BEV 空間の特徴を取得し、その後デコーダーを使用することです。最終的な知覚結果を予測するモジュールを実装し、出力された知覚結果と真の目標値との間の損失を計算することにより、モデルの BEV 空間特性を予測するプロセスが実現されます。ただし、このネットワーク モデルのパラメータ更新方法は、デコーダ モジュールの知覚パフォーマンスに依存しすぎるため、モデルによって出力される BEV 特徴が真の値の BEV 特徴と一致しないという問題が発生する可能性があり、そのため、さらに制約が生じます。知覚モデルの最終パフォーマンス。
- 質問 2: BEVFormer 知覚アルゴリズム モデルの Decoder モジュールは依然としてセルフ アテンション モジュール -> クロス アテンション モジュール -> フィードフォワード ニューラル ネットワーク ステップを Transformer で使用して、クエリ機能の構築を完了します。検出結果に関しては、プロセス全体が依然としてブラック ボックス モデルであり、適切な解釈性に欠けています。同時に、モデルトレーニングプロセス中のオブジェクトクエリと真の値ターゲットの間の1対1マッチングプロセスには大きな不確実性もあります。
BEVFormer 知覚アルゴリズム モデルの問題点を解決するために、我々はそれを改良し、サラウンド画像に基づく 3D 検出アルゴリズム モデル CLIP-BEVFormer を提案しました。対照学習手法を導入することで、BEV 特徴を構築するモデルの能力が強化され、nuScenes データセットで最高レベルの知覚パフォーマンスを達成しました。
記事リンク: https://arxiv.org/pdf/2403.08919.pdf
全体的なアーキテクチャとネットワーク モデルの詳細
詳細この記事で提案する CLIP-BEVFormer 知覚アルゴリズム モデルの詳細を紹介する前に、次の図に CLIP-BEVFormer アルゴリズムの全体的なネットワーク構造を示します。
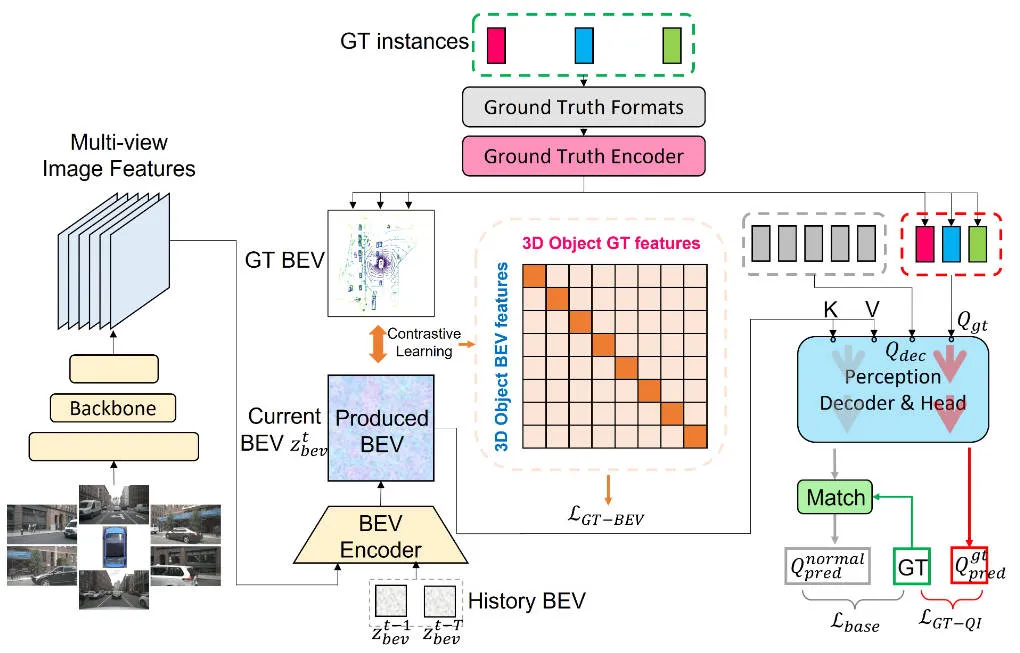 この記事で提案するCLIP-BEVFormer知覚アルゴリズムモデルの全体フローチャート
この記事で提案するCLIP-BEVFormer知覚アルゴリズムモデルの全体フローチャート
アルゴリズムの全体フローチャートから、CLIP-BEVFormerアルゴリズムモデルがこの記事で提案するアルゴリズムは BEVFormer アルゴリズム モデルに基づいており、その改良点に基づいて、BEVFormer 知覚アルゴリズム モデルの実装プロセスを簡単にレビューします。まず、BEVFormer アルゴリズム モデルは、カメラ センサーによって収集されたサラウンド画像データを入力し、2D 画像特徴抽出ネットワークを使用して、入力サラウンド画像のマルチスケール意味論的特徴情報を抽出します。次に、時間的セルフ アテンションと空間的クロス アテンションを含むエンコーダ モジュールを使用して、2D 画像特徴から BEV 空間特徴への変換プロセスを完了します。次に、オブジェクト クエリのセットが 3D 知覚空間で正規分布の形式で生成され、デコーダ モジュールに送信され、エンコーダ モジュールが出力する BEV 空間特徴との空間特徴のインタラクティブな利用が完了します。最後に、フィードフォワード ニューラル ネットワークを使用して、オブジェクト クエリによってクエリされた意味特徴を予測し、ネットワーク モデルの最終的な分類と回帰の結果が出力されます。同時に、BEVFormer アルゴリズム モデルのトレーニング プロセス中に、1 対 1 のハンガリー マッチング戦略を使用して陽性サンプルと陰性サンプルの分配プロセスを完了し、分類と回帰損失を使用してサンプルの更新プロセスを完了します。全体的なネットワーク モデル パラメーター。 BEVFormer アルゴリズム モデルの全体的な検出プロセスは、次の数式で表すことができます。
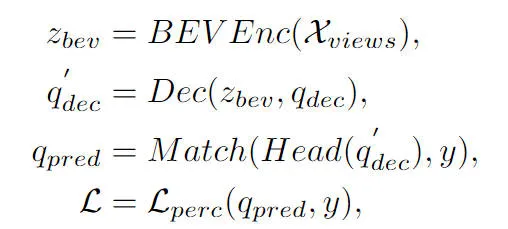
このうち、式中の は、BEVFormerアルゴリズムにおけるEncoder特徴抽出モジュールを表し、BEVFormerアルゴリズムにおけるDecoder復号モジュールを表し、データセットにおける真値ターゲットラベルを表し、現在の BEVFormer アルゴリズム モデルを表し、3D 認識結果を出力します。
真の値 BEV の生成
前述したように、BEV 空間に基づく既存の 3D ターゲット検出アルゴリズムのほとんどには明示的な位置合わせがありません。生成される BEV 空間特徴は次のとおりです。これは、モデルによって生成された BEV 特徴が実際の BEV 特徴と一致しない可能性があるという問題につながり、この BEV 空間特徴の分布の違いにより、モデルの最終的な知覚パフォーマンスが制限されます。この検討に基づいて、私たちは Ground Truth BEV モジュールを提案しました。このモジュールを設計する際の中心的なアイデアは、モデルによって生成された BEV 特徴を現在の真の値の BEV 特徴と一致させ、それによってモデルのパフォーマンスを向上させることです。
具体的には、全体的なネットワーク フレームワーク図に示すように、グラウンド トゥルース エンコーダー () を使用して、BEV 特徴マップ上の任意のグラウンド トゥルース インスタンスのカテゴリ ラベルと空間境界ボックスの位置情報をエンコードします。このプロセスは、次の形式の式で表すことができます。
式は、生成された BEV 特徴マップと同じサイズの特徴次元を持ち、真値ターゲットの符号化された特徴情報を表します。符号化処理では、大規模言語モデル (LLM) と多層パーセプトロン (MLP) の 2 つの形式を採用しましたが、実験の結果、2 つの方式は基本的に同じ性能を達成できることがわかりました。
さらに、BEV 特徴マップ上の真値ターゲットの境界情報をさらに強化するために、空間的位置に応じて BEV 特徴マップ上の真値ターゲットをクロップし、クロッピングを実行します。特徴はプーリング操作を使用して、対応する特徴情報表現を構築します。プロセスは次の形式で表現できます:
最後に、モデルによって生成された BEV 特徴を真の値の BEV 特徴とさらに調整するために、比較学習手法を採用し、2 種類の BEV 特徴間の要素関係と距離を最適化します。最適化プロセスは次の形式で表現できます。生成された BEV 特徴量と真の BEV 特徴量の間の類似度行列は、対比学習における論理スケール ファクターを表し、行列間の乗算演算を表し、クロスエントロピー損失関数を表します。上記の対照学習方法を通じて、私たちが提案する方法は、生成されたBEV特徴に対してより明確な特徴ガイダンスを提供し、モデルの知覚能力を向上させることができます。
True value ターゲット クエリの相互作用
この部分については、前の記事でも説明しています。BEVFormer 認識アルゴリズム モデルのオブジェクト クエリは、Decoder モジュールを通じて生成された BEV 特徴と相互作用し、対応するターゲットクエリの特性を取得しますが、プロセス全体としては依然としてブラックボックスプロセスであり、プロセスの完全な理解が不足しています。この問題に対処するために、真理値クエリ インタラクション モジュールを導入しました。このモジュールは、真理値ターゲットを使用して Decoder モジュールの BEV 特徴インタラクションを実行し、モデル パラメーターの学習プロセスを刺激します。具体的には、truth encoder()モジュールが出力する真理ターゲットの符号化情報をObject Queryに導入し、Decoderモジュールの復号処理に参加させ、通常のObject Queryと同様にセルフアテンションモジュール、クロスアテンションモジュールに参加します。フィードフォワード ニューラル ネットワークは、最終的な知覚結果を出力します。ただし、デコード処理中、すべてのオブジェクト クエリは、真の値のターゲット情報の漏洩を防ぐために並列計算を使用することに注意する必要があります。真理値ターゲットクエリ対話プロセス全体は、次の形式で抽象的に表現できます。
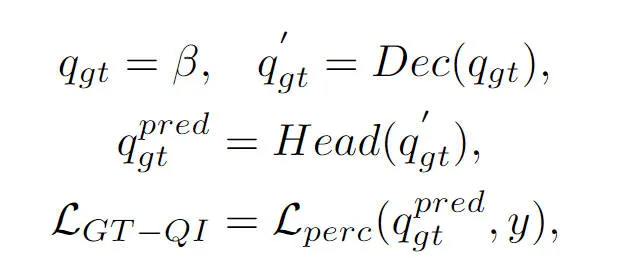
このうち、式内の は初期化されたオブジェクトクエリを表し、真理値オブジェクトを表します。それぞれクエリ処理 デコーダモジュールとセンシング検出ヘッドの出力結果。モデルトレーニングプロセスに真値ターゲットのインタラクションプロセスを導入することにより、私たちが提案した真値ターゲットクエリインタラクションモジュールは、真値ターゲットクエリと真値BEV特徴の間のインタラクションを実現し、それによって、モデルのパラメータ更新プロセスを支援します。モデルデコーダモジュール。
実験結果と評価指標
定量分析部分
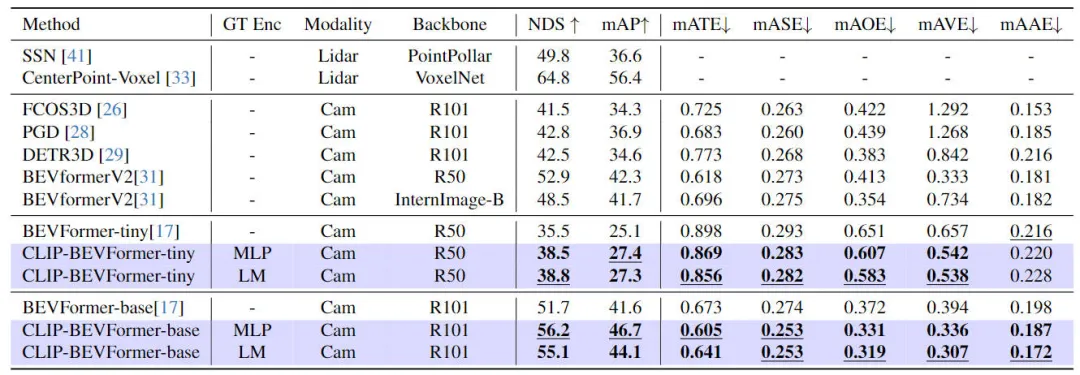
CLIP-BEVFormerアルゴリズムの有効性を検証するために私たちが提案した性別モデルを使用して、3D 知覚効果、データセット内のターゲット カテゴリのロングテール分布、ロバスト性の観点から nuScenes データセットで関連する実験を実施しました。次の表は、私たちが提案したアルゴリズム モデルと他のアルゴリズム モデルの違いを示しています。 3D 認識アルゴリズム モデル nuScenes データセットでの精度比較。
本記事で提案する手法と他の知覚アルゴリズムモデルの比較結果
実験のこの部分では、さまざまなモデル構成での知覚パフォーマンスを評価しました。具体的には、CLIP-BEVFormer アルゴリズム モデルを BEVFormer の小さなバリアントと基本バリアントに適用しました。さらに、事前トレーニングされた CLIP モデルまたは MLP レイヤーをグランド トゥルース ターゲット エンコーダーとして使用した場合のモデルの知覚パフォーマンスへの影響も調査しました。実験結果から、オリジナルの tiny バリアントであっても、base バリアントであっても、私たちが提案した CLIP-BEVFormer アルゴリズムを適用した後、NDS および mAP インジケーターのパフォーマンスが安定して向上していることがわかります。さらに、実験結果を通じて、私たちが提案したアルゴリズム モデルは、グランド トゥルース ターゲット エンコーダーに MLP 層または言語モデルが選択されるかどうかに影響を受けないことがわかり、この柔軟性により、私たちが提案した CLIP-BEVFormer アルゴリズムをより効果的にすることができます。適応性があり、車両への導入が簡単です。要約すると、提案されたアルゴリズム モデルのさまざまなバリアントのパフォーマンス指標は、提案された CLIP-BEVFormer アルゴリズム モデルが優れた知覚ロバスト性を持ち、さまざまなモデルの複雑さとパラメーター量の下で優れた検出パフォーマンスを達成できることを一貫して示しています。
3D 認識タスクで提案した CLIP-BEVFormer のパフォーマンスを検証することに加えて、データセット内のロングテール分布に対するアルゴリズムの堅牢性を評価するためにロングテール分布実験も実施しました。スティッキー性と汎化能力、実験結果は次の表にまとめられています。
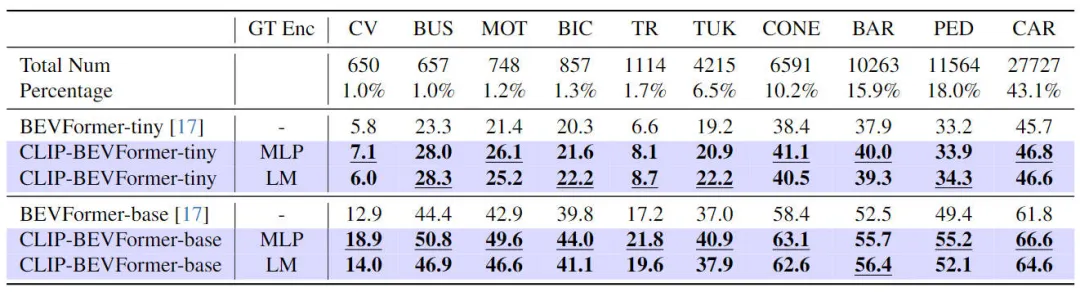
ロングテール問題に対する提案された CLIP-BEVFormer アルゴリズム モデルのパフォーマンス
表の実験結果から、nuScenes データセットはカテゴリ数に大きな不均衡を示していることがわかります。(建設車両、バス、オートバイ、自転車など) などの一部のカテゴリは、非常に大きな割合を占めています。割合は低いですが、自動車の場合はその割合が非常に高くなります。ロングテール分布を使用して関連する実験を実行することにより、特徴カテゴリに対する提案された CLIP-BEVFormer アルゴリズム モデルの知覚パフォーマンスを評価し、それによってあまり一般的ではないカテゴリを解決するその処理能力を検証します。上記の実験データから、提案された CLIP-BEVFormer アルゴリズム モデルがすべてのカテゴリでパフォーマンスの向上を達成し、非常に小さな割合を占めるカテゴリでは、CLIP-BEVFormer アルゴリズム モデルが明らかな実質的なパフォーマンスの向上を示していることがわかります。
実際の環境における自動運転システムは、ハードウェアの故障、厳しい気象条件、人工障害物によって容易に引き起こされるセンサーの故障などの問題に直面する必要があることを考慮して、提案されたアルゴリズムの堅牢性をさらに実験的に検証しました。モデル。具体的には、センサーの故障問題をシミュレートするために、モデルの実装推論プロセス中にカメラのカメラをランダムにブロックして、カメラが故障する可能性のあるシーンをシミュレートしました。関連する実験結果は以下の表に示されています
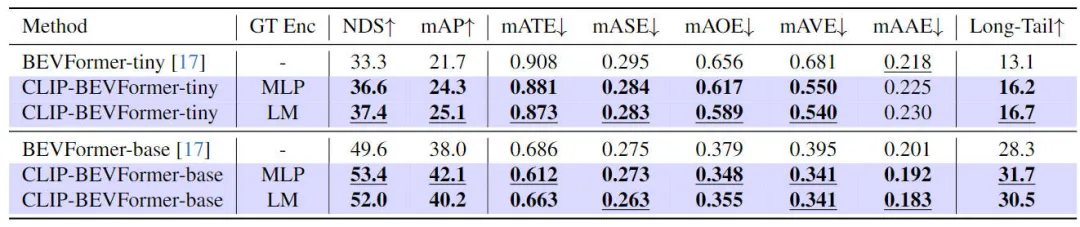 提案されたCLIP-BEVFormerアルゴリズムモデルのロバストネス実験結果
提案されたCLIP-BEVFormerアルゴリズムモデルのロバストネス実験結果
実験結果から、tiny または Base のモデル パラメーター構成に関係なく、私たちが提案した CLIP-BEVFormer アルゴリズム モデルは、BEVFormer の同じ構成のベースライン モデルよりも常に優れていることがわかります。アルゴリズム モデルはシミュレーションで良好なパフォーマンスを発揮します。 センサーの故障状況下でも優れたパフォーマンスと優れた堅牢性を備えています。
定性分析パート
次の図は、私たちが提案したCLIP-BEVFormerアルゴリズムモデルとBEVFormerアルゴリズムモデルの知覚結果の視覚的な比較を示しています。視覚的な結果から、私たちが提案したCLIP-BEVFormerアルゴリズムモデルの知覚結果が真の値ターゲットに近いことがわかり、私たちが提案した真の値BEV特徴生成モジュールと真の値ターゲットクエリインタラクションモジュールの有効性を示しています。

提案されたCLIP-BEVFormerアルゴリズムモデルとBEVFormerアルゴリズムモデルの知覚結果の視覚的比較
結論
この記事では、元の BEVFormer アルゴリズムで BEV 特徴マップを生成するプロセスにおける表示監視の欠如と、Decoder モジュールのオブジェクト クエリと BEV 特徴の間の対話型クエリの不確実性を考慮して、CLIP- BEVFormer アルゴリズム モデルから始まり、アルゴリズム モデルの 3D 認識性能、ターゲットのロングテール分布、センサー故障に対するロバスト性について実験が行われ、多くの実験結果が私たちが提案した CLIP-BEVFormer アルゴリズム モデルの有効性を示しています。
以上がCLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7517
7517
 15
1378
52
79
11
21
66
15
1378
52
79
11
21
66

 カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
0.前面に書かれています&& 自動運転システムは、さまざまなセンサー (カメラ、ライダー、レーダーなど) を使用して周囲の環境を認識し、アルゴリズムとモデルを使用することにより、高度な知覚、意思決定、および制御テクノロジーに依存しているという個人的な理解リアルタイムの分析と意思決定に。これにより、車両は道路標識の認識、他の車両の検出と追跡、歩行者の行動の予測などを行うことで、安全な運行と複雑な交通環境への適応が可能となり、現在広く注目を集めており、将来の交通分野における重要な開発分野と考えられています。 。 1つ。しかし、自動運転を難しくしているのは、周囲で何が起こっているかを車に理解させる方法を見つけることです。これには、自動運転システムの 3 次元物体検出アルゴリズムが、周囲環境にある物体 (位置を含む) を正確に認識し、記述することができる必要があります。
 CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
上記および筆者の個人的な理解: 現在、自動運転システム全体において、認識モジュールが重要な役割を果たしている。道路を走行する自動運転車は、認識モジュールを通じてのみ正確な認識結果を得ることができる。下流の規制および制御モジュール自動運転システムでは、タイムリーかつ正確な判断と行動決定が行われます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。純粋な視覚に基づく BEV 認識アルゴリズムは、ハードウェア コストが低く導入が容易であるため、業界で好まれており、その出力結果はさまざまな下流タスクに簡単に適用できます。
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の最下層はマージ ソートを使用し、その複雑さは O(nlogn) で、クイック ソート、ヒープ ソート、安定したソートなど、さまざまなソート アルゴリズムの選択肢を提供します。
 オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
オックスフォード大学の最新情報!ミッキー:2D画像を3D SOTAでマッチング! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
前に書かれたプロジェクトのリンク: https://nianticlabs.github.io/mickey/ 2 枚の写真が与えられた場合、それらの写真間の対応関係を確立することで、それらの間のカメラのポーズを推定できます。通常、これらの対応は 2D 対 2D であり、推定されたポーズはスケール不定です。いつでもどこでもインスタント拡張現実などの一部のアプリケーションでは、スケール メトリクスの姿勢推定が必要なため、スケールを回復するために外部深度推定器に依存します。この論文では、3D カメラ空間でのメトリックの対応を予測できるキーポイント マッチング プロセスである MicKey を提案します。画像全体の 3D 座標マッチングを学習することで、相対的なメトリックを推測できるようになります。
 人工知能は犯罪を予測できるのか? CrimeGPT の機能を調べる
Mar 22, 2024 pm 10:10 PM
人工知能は犯罪を予測できるのか? CrimeGPT の機能を調べる
Mar 22, 2024 pm 10:10 PM
人工知能 (AI) と法執行機関の融合により、犯罪の予防と検出の新たな可能性が開かれます。人工知能の予測機能は、犯罪行為を予測するためにCrimeGPT (犯罪予測技術) などのシステムで広く使用されています。この記事では、犯罪予測における人工知能の可能性、その現在の応用、人工知能が直面する課題、およびこの技術の倫理的影響について考察します。人工知能と犯罪予測: 基本 CrimeGPT は、機械学習アルゴリズムを使用して大規模なデータセットを分析し、犯罪がいつどこで発生する可能性があるかを予測できるパターンを特定します。これらのデータセットには、過去の犯罪統計、人口統計情報、経済指標、気象パターンなどが含まれます。人間のアナリストが見逃す可能性のある傾向を特定することで、人工知能は法執行機関に力を与えることができます
 改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
01 今後の概要 現時点では、検出効率と検出結果の適切なバランスを実現することが困難です。我々は、光学リモートセンシング画像におけるターゲット検出ネットワークの効果を向上させるために、多層特徴ピラミッド、マルチ検出ヘッド戦略、およびハイブリッドアテンションモジュールを使用して、高解像度光学リモートセンシング画像におけるターゲット検出のための強化されたYOLOv5アルゴリズムを開発しました。 SIMD データセットによると、新しいアルゴリズムの mAP は YOLOv5 より 2.2%、YOLOX より 8.48% 優れており、検出結果と速度のバランスがより優れています。 02 背景と動機 リモート センシング技術の急速な発展に伴い、航空機、自動車、建物など、地表上の多くの物体を記述するために高解像度の光学式リモート センシング画像が使用されています。リモートセンシング画像の判読における物体検出
 LLMはすべて完了しました! OmniDrive: 3D 認識と推論プランニングの統合 (NVIDIA の最新)
May 09, 2024 pm 04:55 PM
LLMはすべて完了しました! OmniDrive: 3D 認識と推論プランニングの統合 (NVIDIA の最新)
May 09, 2024 pm 04:55 PM
上記と著者の個人的な理解: この論文は、自動運転アプリケーションにおける現在のマルチモーダル大規模言語モデル (MLLM) の主要な課題、つまり MLLM を 2D 理解から 3D 空間に拡張する問題の解決に特化しています。自動運転車 (AV) は 3D 環境について正確な決定を下す必要があるため、この拡張は特に重要です。 3D 空間の理解は、情報に基づいて意思決定を行い、将来の状態を予測し、環境と安全に対話する車両の能力に直接影響を与えるため、AV にとって重要です。現在のマルチモーダル大規模言語モデル (LLaVA-1.5 など) は、ビジュアル エンコーダーの解像度制限や LLM シーケンス長の制限により、低解像度の画像入力しか処理できないことがよくあります。ただし、自動運転アプリケーションには次の要件が必要です。
