

オープンソースのフリーテキスト注釈ツールのおすすめ 10 選

テキスト注釈作業は、テキスト内の特定の内容にラベルまたはタグを対応付ける作業です。その主な目的は、特に人工知能の分野で、より深い分析と処理のためにテキストに追加情報を提供することです。

#テキスト注釈は、人工知能アプリケーションの教師あり機械学習タスクにとって非常に重要です。これは、自然言語テキスト情報をより正確に理解し、テキスト分類、感情分析、言語翻訳などのタスクのパフォーマンスを向上させるために AI モデルをトレーニングするために使用されます。テキスト アノテーションを通じて、AI モデルにテキスト内のエンティティを認識し、コンテキストを理解し、新しい同様のデータが出現したときに正確な予測を行うように教えることができます。
この記事では主に、より優れたオープンソースのテキスト注釈ツールをいくつか推奨します。
1.Label Studio
https://github.com/HumanSignal/label-studio

Label Studio はオープンソース データです注釈ツール。複数のデータ型を処理し、複数のモデル形式へのエクスポートをサポートできます。生データを準備したり、既存のトレーニング データを改善して機械学習モデルの精度を向上させるために広く使用されています。
2.Doccano
https://github.com/doccano/doccano
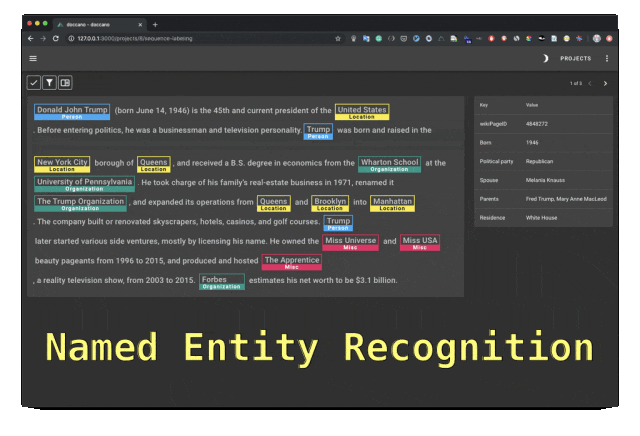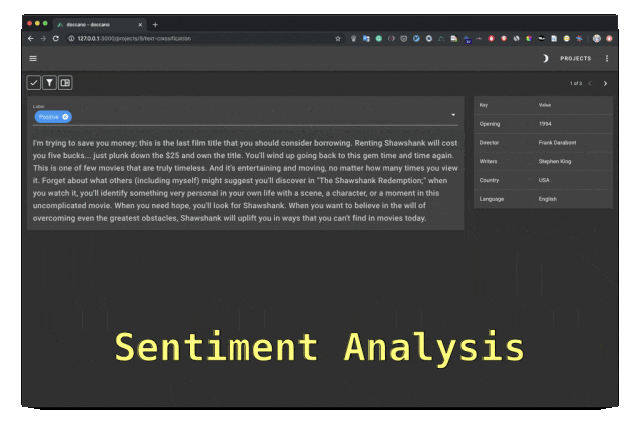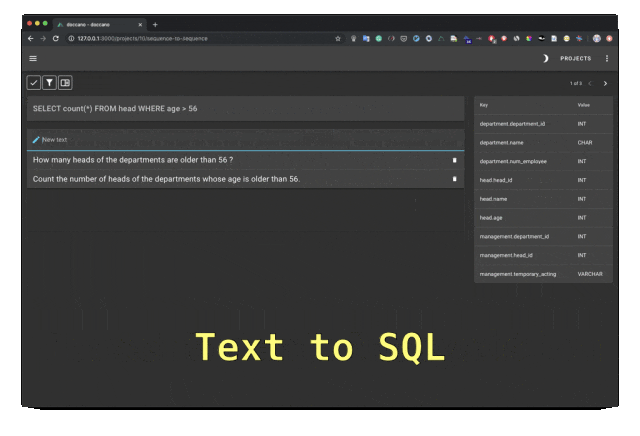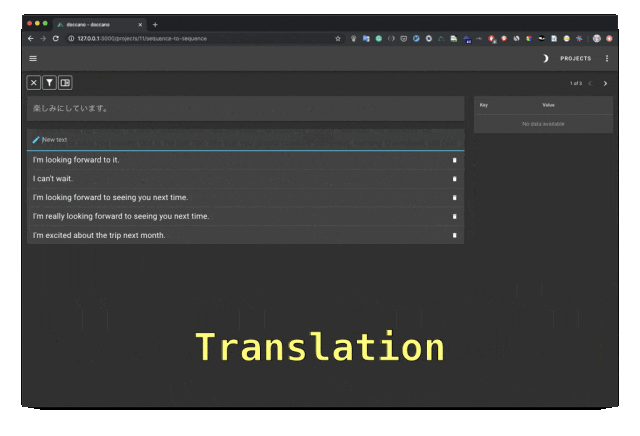
Doccano は、テキスト分類、シーケンスのラベル付け、およびシーケンス タスクの機能を提供するオープン ソースのテキスト アノテーション ツールです。テキスト注釈チームのコラボレーション、多言語、モバイル アプリ、絵文字、ダーク テーマ、REST スタイルの API をサポートします。 Docker および Docker Compose を使用してインストールできます。
3.ユニバーサル データ ツール
https://github.com/UniversalDataTool/universal-data-tool
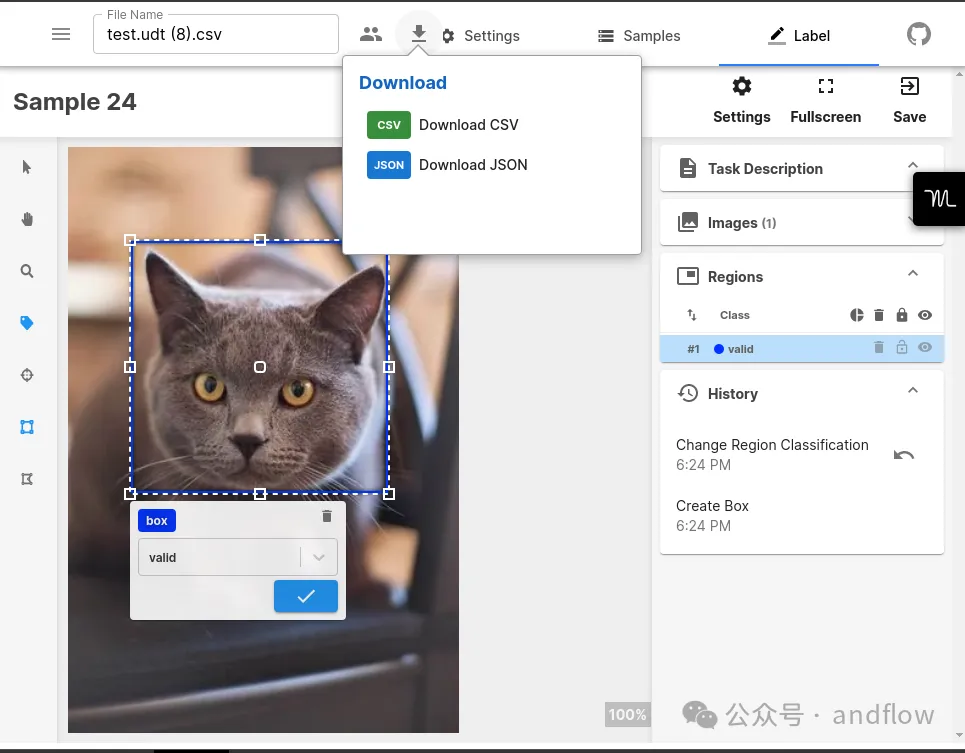
ユニバーサル データ ツールは、画像、テキスト、音声、ドキュメントなど、さまざまな種類のデータを編集し、注釈を付けるための多用途アプリケーションです。幅広いデータ型をサポートし、リアルタイムのコラボレーション、使いやすい GUI、テキスト アノテーター向けのトレーニング コースの作成などを提供します。このツールは Web 上またはデスクトップ アプリケーションとして利用でき、CSV または JSON 形式でのデータのダウンロードとアップロードをサポートしています。
4.YEDDA
https://github.com/jiesutd/YEDDA
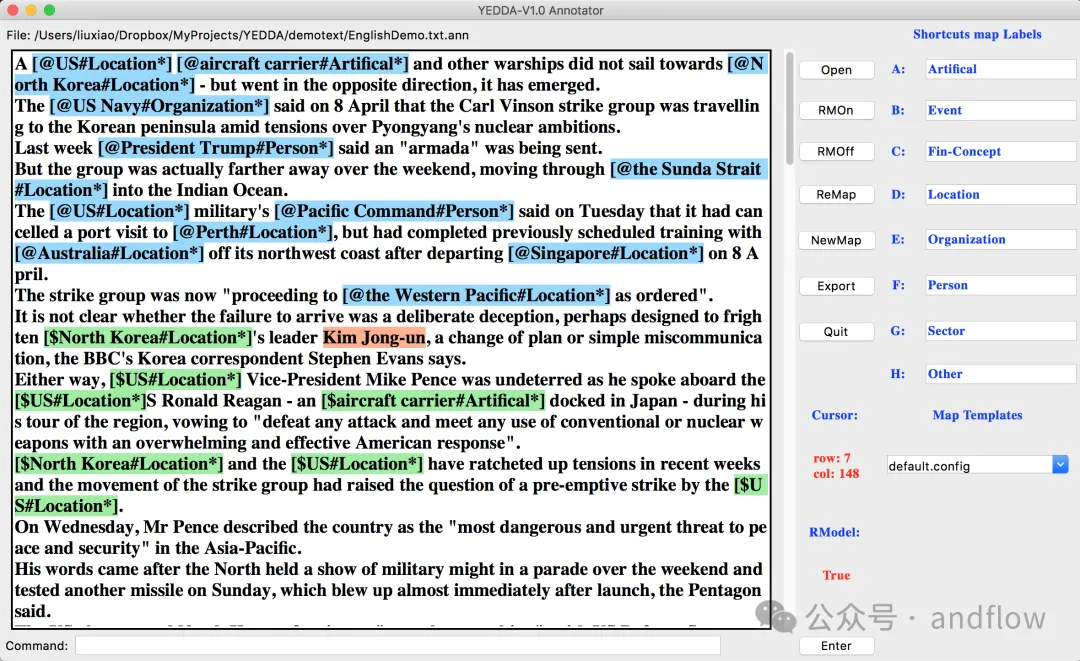
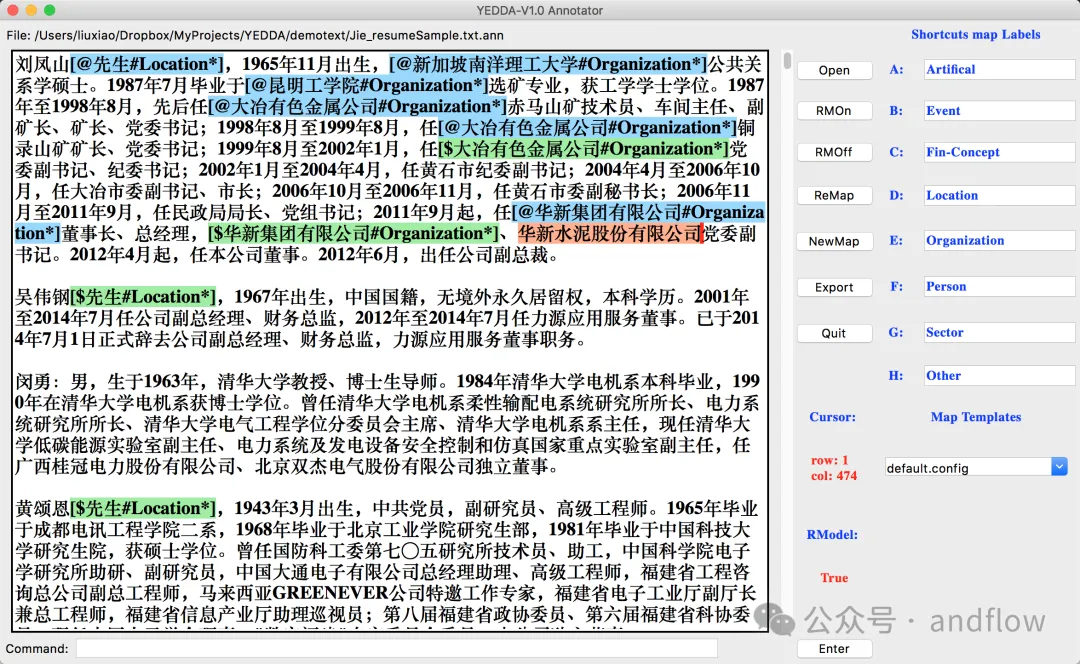
YEDDA は、さまざまな言語、記号、絵文字で使用できるテキスト注釈ツールです。ショートカットの使用、モデルのコマンド実行、注釈テキストのシーケンス テキストとしてのエクスポートがサポートされています。インテリジェントなレコメンデーションや管理者分析などの機能をサポートします。
YEDDA は、Windows、Linux、MacOS を含むすべての主要なオペレーティング システムと互換性があります。
5.Argilla
https://github.com/argilla-io/argilla
Argilla は人工知能のためのプラットフォームですエンジニア 高品質で効率的なデータ出力を提供する、ドメイン専門家とのオープンソース データ コラボレーション プラットフォーム。
データ品質の制御と AI 出力品質の向上に役立ち、データとモデルの迅速な反復を可能にすることで効率が向上します。 Argilla は、データ管理ツールとモデル トレーニング ツールも提供します。
6.KernAI Refinery
https://github.com/code-kern-ai/refinery
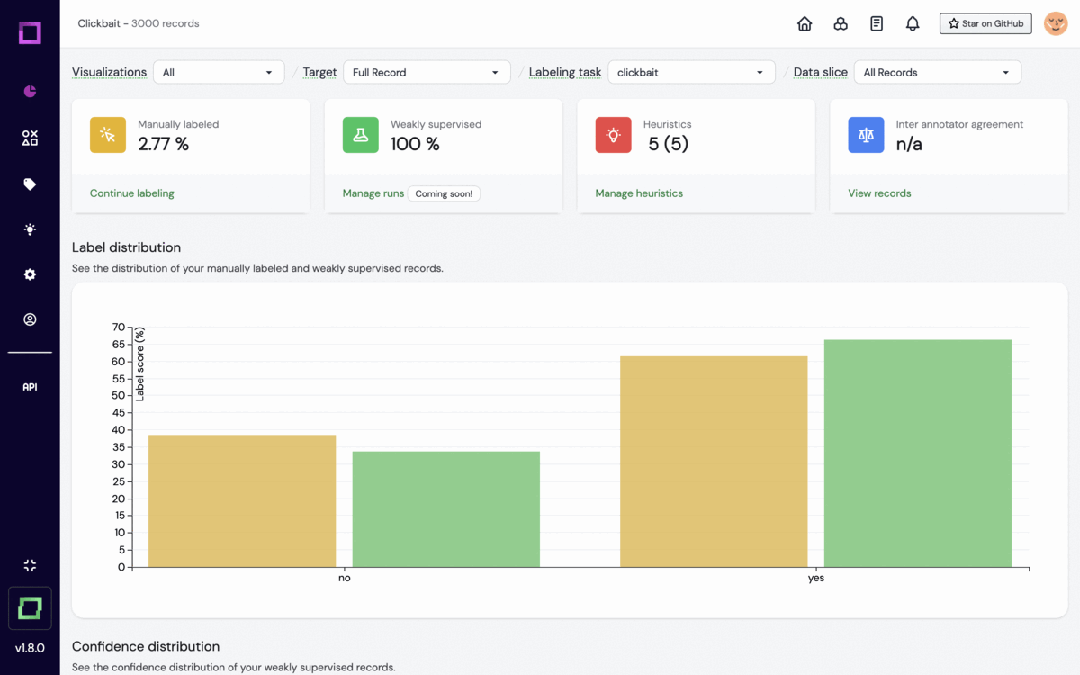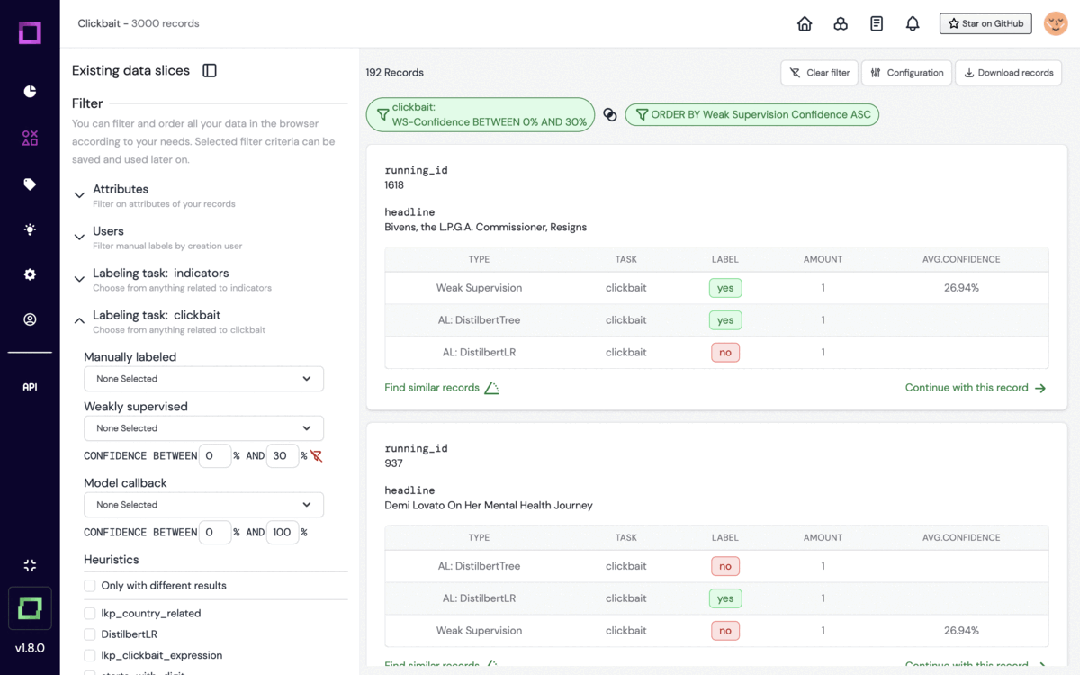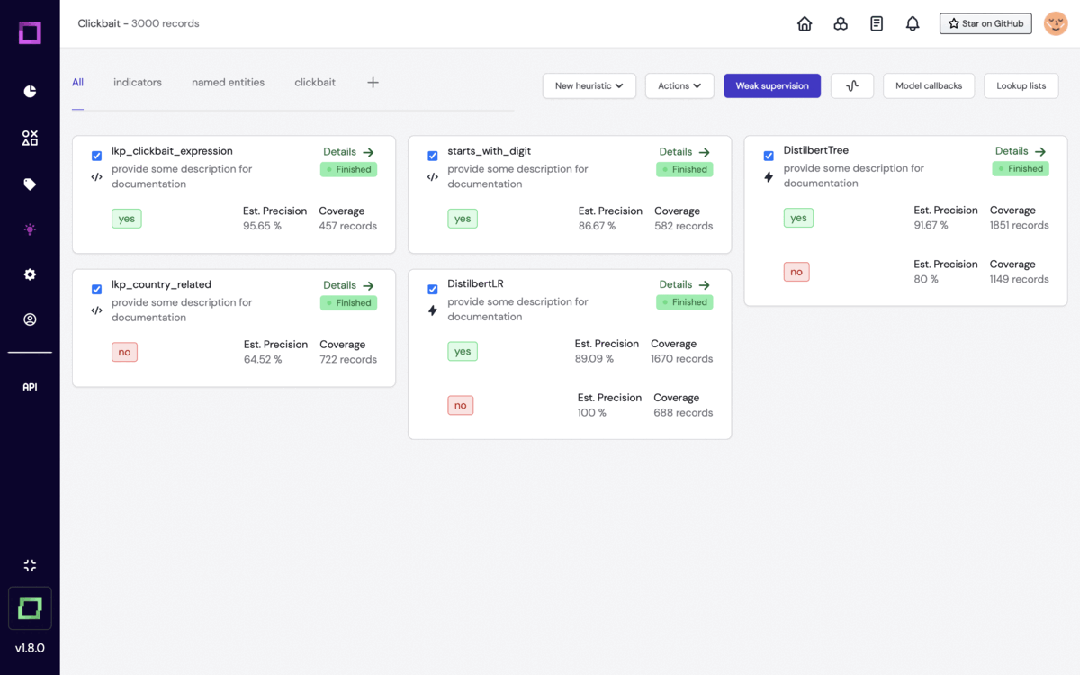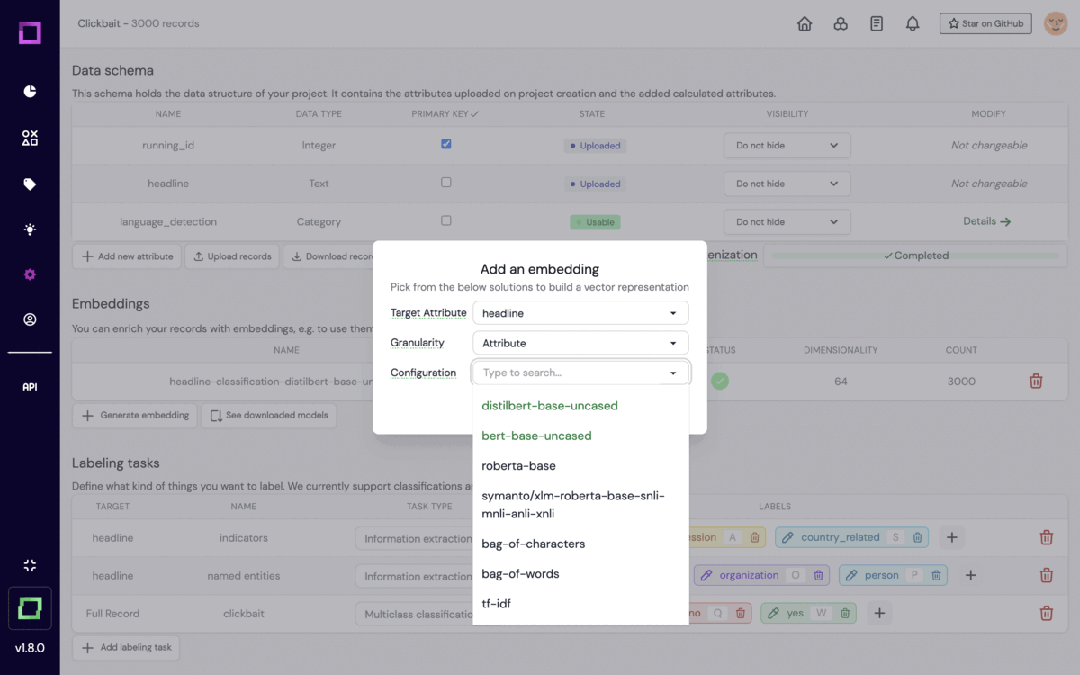
Refinery は、自然言語データを扱うデータ サイエンティスト向けに設計された KernAI のオープンソース プラットフォームです。半自動データアノテーション、データサブセット品質評価、集中データ監視などの機能を提供し、手動ラベル付けの効率向上を目指します。
このツールは、Hugging Face や spaCy などのテクノロジーを活用して、事前構築された言語モデルを構築し、他のラベル付けツールと統合して柔軟なデータ処理を実現します。
機能:
- NLP タスクの (半) 自動化されたラベル付けワークフロー
- 手動およびプログラムによる分類とスパンのラベル付け
- 状態によるサポート-最先端のライブラリとフレームワークの統合
- ルックアップ テーブル/ナレッジ ベースの作成と管理
- ニューラル検索ベースの類似レコードと外れ値の取得
- スライス可能なタグ セッション
- プロジェクトごとに複数のタグタスク
- 豊富な自動化ライブラリ
- 広範なデータ管理とモニタリング
- 埋め込みの自動作成のためのHugging Faceとの統合
- JSONデータのアップロード/ダウンロード用のベースのデータ モデル
- プロジェクト メトリクスの概要
- Python SDK を介したデータへのアクセスと拡張
- インプレース属性の変更
- チーム コラボレーションホスト型バージョンでは
- 複数ユーザー向けのロールベースのアクセスと最小化されたタグ ビュー
- 統合されたグループ タグ ワークフロー
- アノテーター間の合意を自動的に計算
##7.Recogito.js
##https://github.com/recogito/recogito-js
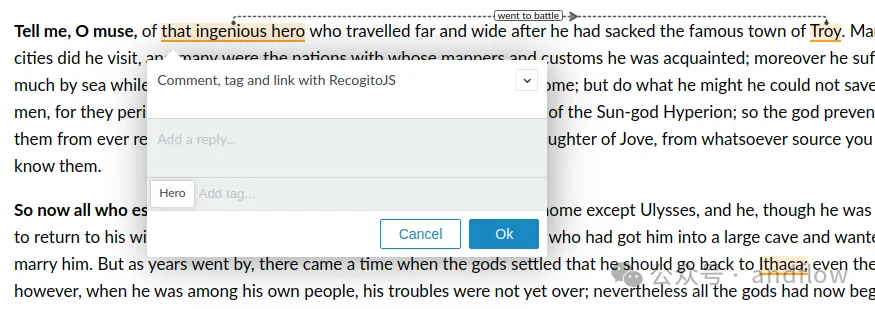 ApplitoJS はテキスト注釈用の JavaScript ライブラリ。Web ページにテキスト注釈機能を追加したり、カスタム テキスト注釈プログラムを構築したりするために使用されます。 npm 経由でインストールするか、最新バージョンをダウンロードしてインストールできます。
ApplitoJS はテキスト注釈用の JavaScript ライブラリ。Web ページにテキスト注釈機能を追加したり、カスタム テキスト注釈プログラムを構築したりするために使用されます。 npm 経由でインストールするか、最新バージョンをダウンロードしてインストールできます。
8.ラベルスルース
https://github.com/label-sleuth/label-sleuth

##Label Sleuth は、テキストのラベル付けと分類のためのオープンソースのノーコード システムです。これにより、医師、弁護士、心理学者などの分野の専門家が、NLP 専門家の協力を得ずにカスタム NLP モデルを構築できるようになります。
通常、NLP モデルの作成にはドメインと機械学習の専門知識が必要です。 Label Sleuth は、直感的なテキスト注釈と AI モデル構築により、NLP の専門知識の要件を回避します。ユーザーがデータにラベルを付けている間、機械学習モデルがバックグラウンドでトレーニングされ、予測を行って次に何をラベル付けするかを提案します。
ノーコード システムであるため、機械学習の知識は必要なく、タスク定義から完成モデルまでわずか数時間で迅速なモデル開発が可能です。
9.マークアップ
https://github.com/samueldobbie/markup
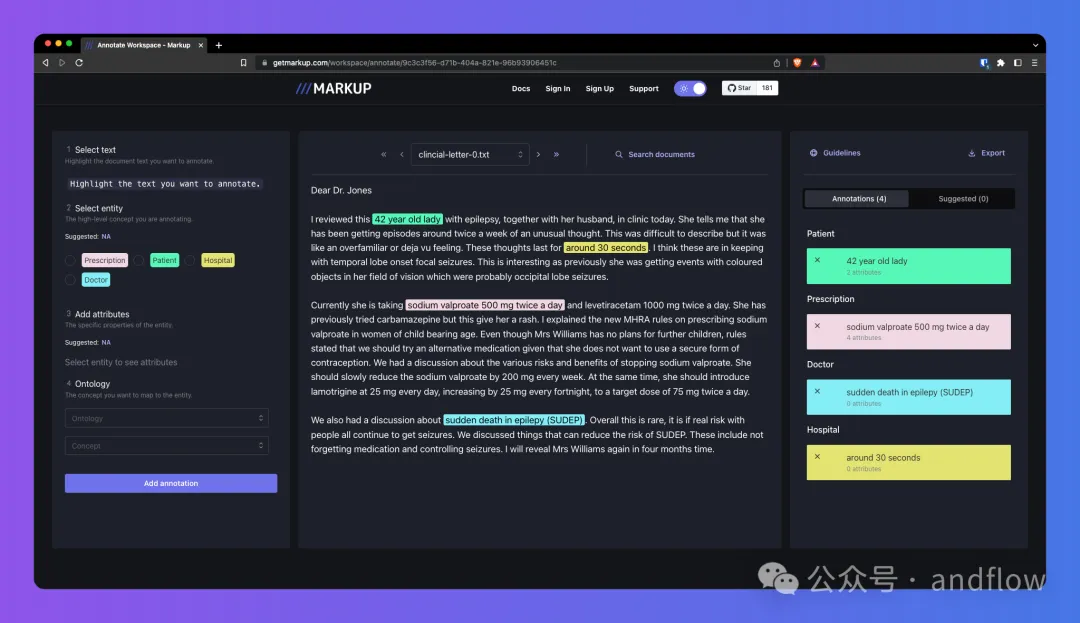
マークアップは、エンティティ認識などの NLP および ML タスク用に、非構造化ドキュメントを構造化形式に変換するために使用できるオンライン注釈ツールです。アノテーションを付けながら同時に学習して、より複雑なアノテーションを予測および推奨します。また、概念マッピングのための共通オントロジーとカスタム オントロジーへの統合されたアクセスも提供します。
機能:
- 予測アノテーション: マークアップの機械学習主導の予測アノテーション機能は、作業中により複雑なアノテーションを推奨できるため、アノテーション プロセスがより効率的になります。
- 統合オントロジー アクセス タグ: 幅広い一般的なオントロジー (UMLS、SNOMED-CT、ICD-10 など) への統合アクセスと、概念マッピング用のカスタム オントロジーをアップロードする機能を提供します。
- 予測オントロジー マッピング: Markup の予測オントロジー マッピング機能は、機械学習を使用して、注釈を付けているテキストに基づいて標準用語とカスタム用語への適切なマッピングを推奨します。
- ユーザーフレンドリーなインターフェイス: 技術専門家でも初心者でも、Markup のユーザーフレンドリーなインターフェイスにより、誰でも最小限のセットアップで簡単にドキュメントに注釈を付けることができます。
10.ポテト
https://github.com/davidjuurgens/potato
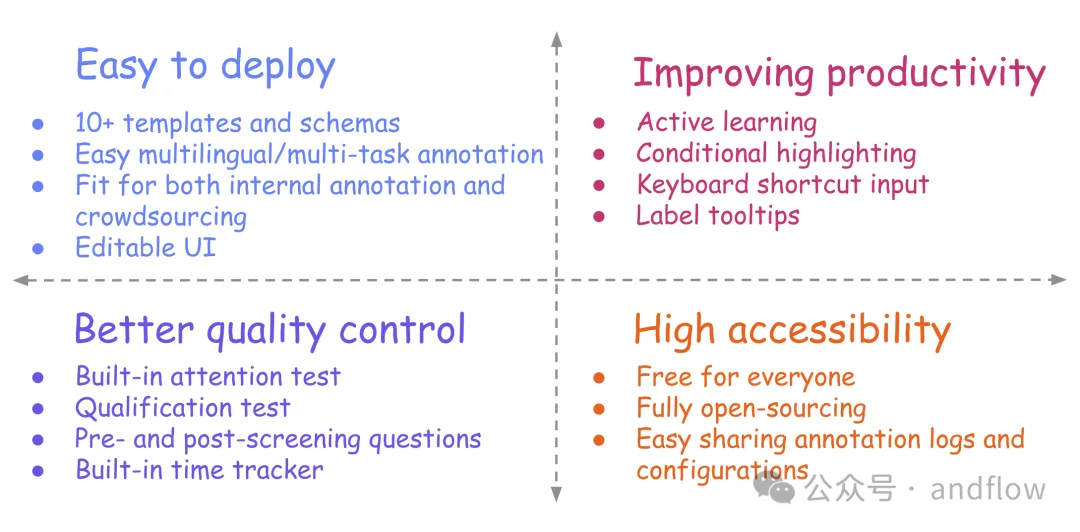
Potato は、さまざまなテキスト注釈タスクの迅速なセットアップと展開をサポートする Web ベースのテキスト注釈ツールです。単一の構成ファイルによって駆動される Web サーバーとして実行でき、起動時のコーディングは必要ありません。ただし、Potato はカスタマイズが簡単で、通常、テキスト アノテーター用にユーザー インターフェイスを調整するために追加の Web デザインを必要としません。
主な機能:
- セットアップとカスタマイズが簡単
- 豊富な組み込みスキーマとテンプレート
- 複数のデータ型をサポート
- マルチタスク設定のサポート
- キーボード ショートカット、動的強調表示、ラベル ツールチップなどの機能でアノテーションの効率を向上させます
- フィルタリングの前後など、アノテーターの機能をより深く理解します質問
- 注意力テスト、認定テスト、組み込み時間チェックなどの品質管理機能
以上がオープンソースのフリーテキスト注釈ツールのおすすめ 10 選の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7678
7678
 15
1393
52
1208
24
91
11
15
1393
52
1208
24
91
11

 Web3トレーディングプラットフォームranking_web3グローバル交換トップ10の概要
Apr 21, 2025 am 10:45 AM
Web3トレーディングプラットフォームranking_web3グローバル交換トップ10の概要
Apr 21, 2025 am 10:45 AM
Binanceは、グローバルデジタルアセット取引エコシステムの大君主であり、その特性には次のものが含まれます。1。1日の平均取引量は1,500億ドルを超え、500の取引ペアをサポートし、主流の通貨の98%をカバーしています。 2。イノベーションマトリックスは、デリバティブ市場、Web3レイアウト、教育システムをカバーしています。 3.技術的な利点は、1秒あたり140万のトランザクションのピーク処理量を伴うミリ秒のマッチングエンジンです。 4.コンプライアンスの進捗状況は、15か国のライセンスを保持し、ヨーロッパと米国で準拠した事業体を確立します。
 WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)は、独自の生体認証とプライバシー保護メカニズムを備えた暗号通貨市場で際立っており、多くの投資家の注目を集めています。 WLDは、特にOpenai人工知能技術と組み合わせて、革新的なテクノロジーを備えたAltcoinsの間で驚くほど演奏しています。しかし、デジタル資産は今後数年間でどのように振る舞いますか? WLDの将来の価格を一緒に予測しましょう。 2025年のWLD価格予測は、2025年にWLDで大幅に増加すると予想されています。市場分析は、平均WLD価格が1.31ドルに達する可能性があり、最大1.36ドルであることを示しています。ただし、クマ市場では、価格は約0.55ドルに低下する可能性があります。この成長の期待は、主にWorldCoin2によるものです。
 通貨サークルでのレバレッジされた交換のランキングは
Apr 21, 2025 pm 11:24 PM
通貨サークルでのレバレッジされた交換のランキングは
Apr 21, 2025 pm 11:24 PM
2025年のレバレッジド取引、セキュリティ、ユーザーエクスペリエンスで優れたパフォーマンスを持つプラットフォームは次のとおりです。1。OKX、高周波トレーダーに適しており、最大100倍のレバレッジを提供します。 2。世界中の多通貨トレーダーに適したバイナンス、125倍の高いレバレッジを提供します。 3。Gate.io、プロのデリバティブプレーヤーに適し、100倍のレバレッジを提供します。 4。ビットゲットは、初心者やソーシャルトレーダーに適しており、最大100倍のレバレッジを提供します。 5。Kraken、安定した投資家に適しており、5倍のレバレッジを提供します。 6。Altcoinエクスプローラーに適したBybit。20倍のレバレッジを提供します。 7。低コストのトレーダーに適したKucoinは、10倍のレバレッジを提供します。 8。ビットフィネックス、シニアプレイに適しています
 クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションをサポートする交換:1。Binance、2。Uniswap、3。Sushiswap、4。CurveFinance、5。Thorchain、6。1inchExchange、7。DLNTrade、これらのプラットフォームはさまざまな技術を通じてマルチチェーン資産トランザクションをサポートします。
 なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
仮想通貨価格の上昇の要因には、次のものが含まれます。1。市場需要の増加、2。供給の減少、3。刺激された肯定的なニュース、4。楽観的な市場感情、5。マクロ経済環境。衰退要因は次のとおりです。1。市場需要の減少、2。供給の増加、3。ネガティブニュースのストライキ、4。悲観的市場感情、5。マクロ経済環境。
 トップ10の暗号通貨交換プラットフォーム世界最大のデジタル通貨交換リスト
Apr 21, 2025 pm 07:15 PM
トップ10の暗号通貨交換プラットフォーム世界最大のデジタル通貨交換リスト
Apr 21, 2025 pm 07:15 PM
交換は、今日の暗号通貨市場で重要な役割を果たしています。それらは、投資家が取引するためのプラットフォームであるだけでなく、市場の流動性と価格発見の重要なソースでもあります。世界最大の仮想通貨交換はトップ10にランクされており、これらの交換は取引量がはるかに先を行っているだけでなく、ユーザーエクスペリエンス、セキュリティ、革新的なサービスに独自の利点を持っています。リストの上にある交換は通常、ユーザーベースが大きく、広範な市場の影響力があり、その取引量と資産タイプは、他の取引所で到達するのが難しいことがよくあります。
 通貨交換サークルのトップ10のプラットフォームは何ですか?
Apr 21, 2025 pm 12:21 PM
通貨交換サークルのトップ10のプラットフォームは何ですか?
Apr 21, 2025 pm 12:21 PM
上位の交換には、次のものが含まれます。1。世界最大の取引量であるバイナンスは600通貨をサポートし、スポット処理料は0.1%です。 2。バランスの取れたプラットフォームであるOKXは、708の取引ペアをサポートし、永続的な契約処理手数料は0.05%です。 3。Gate.io、2700の小通貨をカバーし、スポット処理料は0.1%-0.3%です。 4。Coinbase、米国のコンプライアンスベンチマーク、スポット処理料は0.5%です。 5。Kraken、トップセキュリティ、および定期的な予備監査。
 カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
暗号通貨の賑やかな世界では、新しい機会が常に現れます。現在、Kerneldao(Kernel)Airdropアクティビティは多くの注目を集め、多くの投資家の注目を集めています。それで、このプロジェクトの起源は何ですか? BNBホルダーはそれからどのような利点を得ることができますか?心配しないでください、以下はあなたのためにそれを一つ一つ明らかにします。
