

2 分、1200 フレームの長いビデオ ジェネレーターである StreamingT2V が登場し、コードはオープンソースになります

戦場のワイドショット、走っているストームトルーパー...

プロンプト: 戦場のワイドショット、走っているストームトルーパー...
1,200 フレームを含むこの 2 分間のビデオは、テキストからビデオへのモデルによって生成されました。 AI の痕跡はまだ明らかですが、キャラクターとシーンは非常に良好な一貫性を示しています。
これはどのように行われるのでしょうか? Vincent ビデオ テクノロジの生成品質とテキスト配置の品質は近年非常に優れていますが、既存のほとんどの方法は短いビデオ (通常は 16 フレームまたは 24 フレームの長さ) を生成することに焦点を当てていることを知っておく必要があります。ただし、短いビデオでは機能する既存の方法は、長いビデオ (64 フレーム以上) では機能しないことがよくあります。
短いシーケンスを生成する場合でも、260K を超えるトレーニング ステップや 4500 を超えるバッチ サイズなど、高価なトレーニングが必要になることがよくあります。長いビデオでトレーニングせず、短いビデオ ジェネレーターを使用して長いビデオを作成すると、結果として得られる長いビデオの品質が低下することがよくあります。既存の自己回帰手法(短いビデオの最後の数フレームを使用して新しい短いビデオを生成し、その後長いビデオを合成する)にも、シーンの切り替えが一貫しないなどのいくつかの問題があります。
既存の手法の欠点を補うために、Picsart AI Research と他の機関は共同で新しい Vincent ビデオ手法 StreamingT2V を提案しました。この方法では、自己回帰技術を使用し、長期短期記憶モジュールと組み合わせることで、強い時間的コヒーレンスを備えた長いビデオを生成できます。

- #論文タイトル: StreamingT2V: テキストからの一貫性、動的、拡張可能な長時間ビデオ生成
- 論文アドレス: https://arxiv.org/abs/2403.14773
- プロジェクトアドレス: https://streamingt2v.github.io/
次は 600 フレームの 1 分間のビデオ生成結果です。ミツバチと花が優れた一貫性を持っていることがわかります:
したがって、チームは条件アテンションモジュール (CAM)。 CAM は、アテンション メカニズムを使用して、以前のフレームからの情報を効果的に統合して新しいフレームを生成し、以前のフレームの構造や形状に制限されることなく、新しいフレームの動きを自由に処理できます。
生成されたビデオ内の人物やオブジェクトの外観変更の問題を解決するために、チームは外観保存モジュール (APM) も提案しました。これは、初期画像から開始できます (アンカー フレーム) オブジェクトまたはグローバル シーンの外観情報を抽出し、この情報を使用してすべてのビデオ パッチのビデオ生成プロセスを調整します。
長いビデオ生成の品質と解像度をさらに向上させるために、チームは自己回帰生成タスクのビデオ拡張モデルを改良しました。これを行うために、チームは高解像度の Vincent ビデオ モデルを選択し、SDEdit メソッドを使用して 24 の連続ビデオ ブロック (8 つのオーバーラップ フレームを含む) の品質を向上させました。
ビデオ ブロックのエンハンスメントの移行をスムーズにするために、重複するエンハンスド ビデオ ブロックをシームレスにブレンドするランダム ブレンディング方法も設計しました。
方法
まず、5 秒間の 256 × 256 解像度のビデオ (16fps) を生成し、それをより高い解像度 (720 × 720)。図 2 は、その完全なワークフローを示しています。
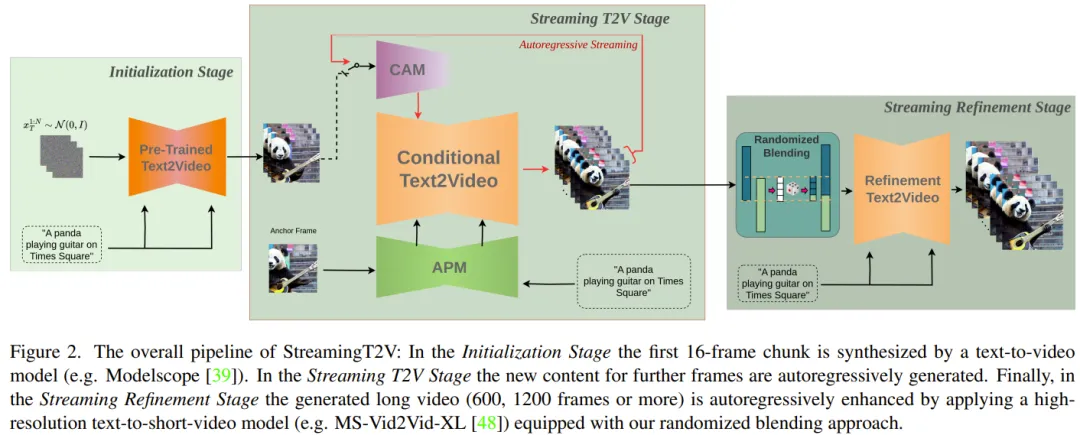
長いビデオの生成部分は、初期化ステージとストリーミング T2V ステージで構成されます。
その中で、初期化段階では、事前トレーニングされた Vincent ビデオ モデル (たとえば、Modelscope を使用できます) を使用して、最初の 16 フレームのビデオ ブロックを生成します。 Vincent ビデオ ステージは、自己回帰方式で後続のフレームの新しいコンテンツを生成します。
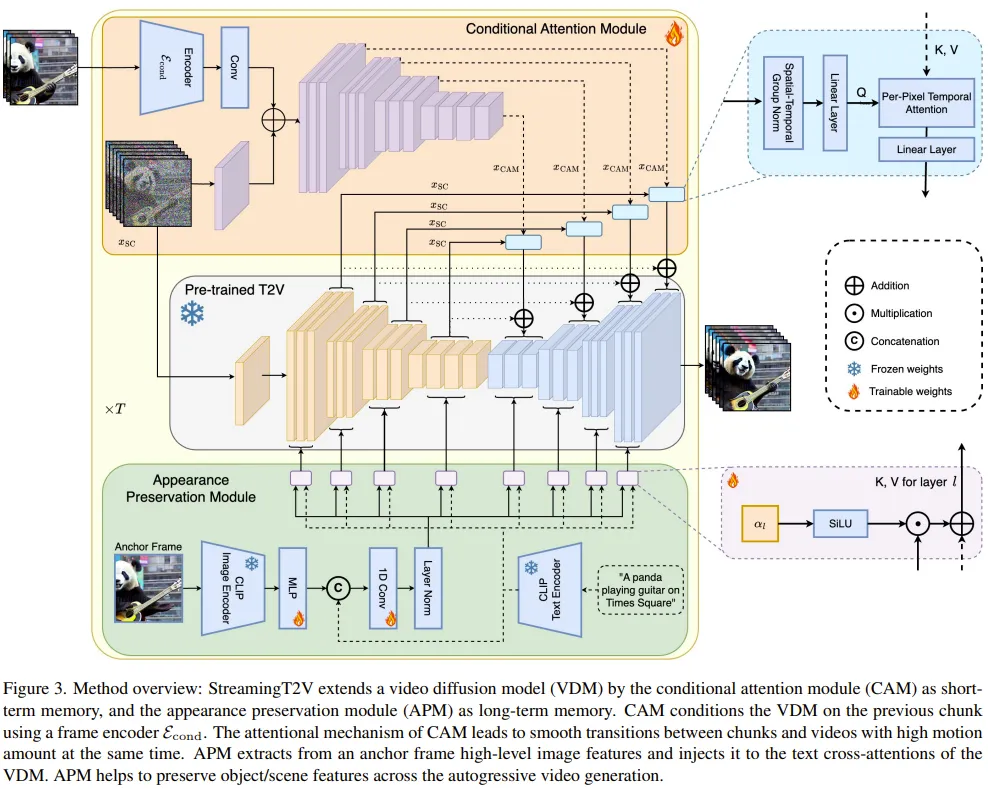
自己回帰プロセス (図 3 を参照) の場合、チームが新たに提案した CAM は、前のビデオ ブロックの最後の 8 フレームの短期情報を利用して、ブロック間のシームレスな切り替えを実現できます。 。さらに、新しく提案されたAPMモジュールを使用して固定アンカーフレームの長期情報を抽出し、生成プロセス中の物事やシーンの詳細の変化に自己回帰プロセスがロバストに対応できるようにします。
長いビデオ (80、240、600、1200 フレーム以上) を生成した後、ストリーミング調整ステージのビデオ品質を向上させます。このプロセスでは、高解像度の Vison ショート ビデオ モデル (MS-Vid2Vid-XL など) を自己回帰方式で使用し、シームレスなビデオ ブロック処理のために新しく提案された確率的混合方法と組み合わせます。さらに、後者のステップでは追加のトレーニングが必要ないため、この方法の計算コストが低くなります。
条件付き注意モジュール
まず、事前トレーニング済みテキスト (短い) を使用します。ビデオ モデルは Video-LDM として表されます。アテンション モジュール (CAM) は、Video-LDM UNet に挿入される特徴エクストラクターと特徴インジェクターで構成されます。
特徴抽出器は、フレームごとの画像エンコーダーを使用し、その後、中間層まで Video-LDM UNet で使用されるのと同じエンコーダー層を使用します (UNet の重みによって初期化されます)。 。
機能注入の場合、ここでの設計は、UNet の各長距離ジャンプ接続が、クロス アテンションを通じて CAM によって生成された対応する機能に焦点を当てるようにすることです。
外観保持モジュール
APM モジュールはアンカー フレーム内の情報を修正できます。を使用して長期記憶をビデオ生成プロセスに統合します。これは、ビデオ パッチの生成中にシーンとオブジェクトの特性を維持するのに役立ちます。
APM がアンカー フレームとテキスト命令によって与えられるガイダンス情報の処理のバランスを取れるようにするために、チームは 2 つの改善を行いました: (1) アンカーの CLIP 画像トークンを結合するテキストを含むフレーム 命令の CLIP テキスト トークンが混合されます; (2) クロスアテンションを使用するために、各クロスアテンション レイヤーに重みが導入されます。
自動回帰ビデオ強化
生成された 24 フレームのビデオ ブロックを自己回帰的に強化するために、ここでは高解像度を使用します。 (1280x720) Vincent (ショート) ビデオ モデル (Refiner Video-LDM、図 3 を参照)。この処理は、まず入力ビデオ ブロックに大量のノイズを追加し、次にこの Vincent ビデオ拡散モデルを使用してノイズ除去処理を実行します。
しかし、この方法はビデオ ブロック間のトランジションの不一致の問題を解決するには十分ではありません。
この目的を達成するために、チームのソリューションはランダム ハイブリッド アプローチです。具体的な詳細については、元の論文を参照してください。
実験
実験でチームが使用した評価指標には、時間的一貫性を評価するための SCuts スコア、モーションを意識したツイスト エラーが含まれます。 (MAWE) は動きとツイスト エラーの量、CLIP テキストと画像の類似性スコア (CLIP) はテキストの配置品質を評価し、美的スコア (AE) を評価します。
アブレーション研究
さまざまな新しいコンポーネントの有効性を評価するために、アブレーション チームは研究は、検証セットからランダムに抽出された 75 個のプロンプトに対して実行されました。
条件付き処理用の CAM: CAM は、モデルがより一貫性のあるビデオを生成するのに役立ち、比較すると、SCuts スコアは他のベースライン モデルより 88% 低くなります。
長期記憶: 図 6 は、長期記憶が自己回帰生成プロセス中にオブジェクトやシーンの特性の安定性を維持するのに大きく役立つことを示しています。

定量的な評価指標 (人物再識別スコア) では、APM は 20% の改善を達成しました。
ビデオ強化のためのランダム ミキシング: 他の 2 つのベンチマークと比較して、ランダム ミキシングは品質を大幅に向上させることができます。これは、図 4: StreamingT2V でよりスムーズなトランジションが得られることからもわかります。

StreamingT2V とベースライン モデルの比較
##チームは、画像からビデオへの手法 I2VGen-XL、SVD、DynamiCrafter-XL、自己回帰手法を使用した SEINE、ビデオ to -ビデオ メソッド SparseControl、およびテキストから長いビデオ MethodFreeNoise。定量的評価: 表 8 からわかるように、テスト セットの定量的評価は、StreamingT2V がシームレスなビデオ ブロックの遷移とモーションの一貫性の点で最高のパフォーマンスを発揮することを示しています。新しいメソッドの MAWE スコアも他のすべてのメソッドよりも大幅に優れており、2 番目に優れた SEINE よりも 50% 以上低いです。同様の動作が SCuts スコアでも見られます。 さらに、StreamingT2V は、生成されるビデオの単一フレーム品質の点で SparseCtrl よりわずかに劣るだけです。これは、この新しい方法が他の比較方法よりも優れた時間的一貫性とモーション ダイナミクスを備えた高品質の長時間ビデオを生成できることを示しています。 定性的評価: 次の図は、StreamingT2V と他の方式の効果を比較したもので、新しい方式の方がビデオの動的な効果を確保しながら、より高い一貫性を維持できることがわかります。 。 研究の詳細については、元の論文を参照してください。 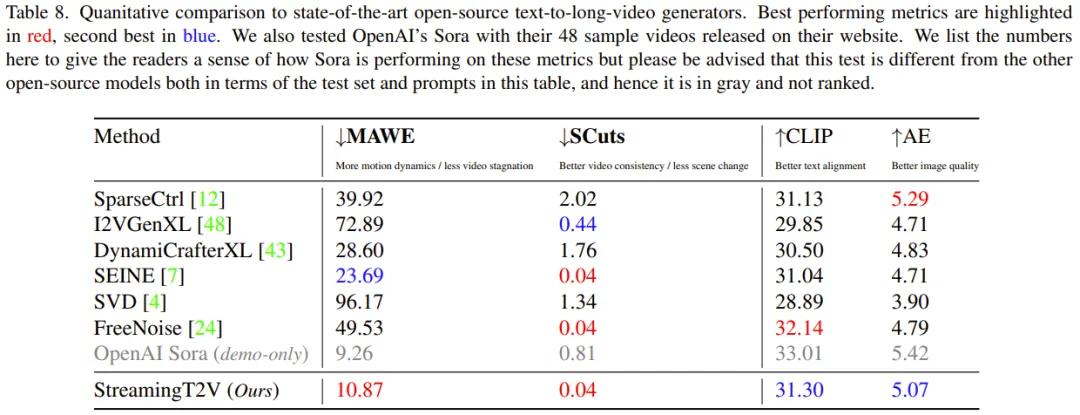

以上が2 分、1200 フレームの長いビデオ ジェネレーターである StreamingT2V が登場し、コードはオープンソースになりますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7742
7742
 15
1643
14
1397
52
1291
25
1233
29
15
1643
14
1397
52
1291
25
1233
29

 WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)価格予測2025-2031:WLDは2031年までに4ドルに達しますか?
Apr 21, 2025 pm 02:42 PM
WorldCoin(WLD)は、独自の生体認証とプライバシー保護メカニズムを備えた暗号通貨市場で際立っており、多くの投資家の注目を集めています。 WLDは、特にOpenai人工知能技術と組み合わせて、革新的なテクノロジーを備えたAltcoinsの間で驚くほど演奏しています。しかし、デジタル資産は今後数年間でどのように振る舞いますか? WLDの将来の価格を一緒に予測しましょう。 2025年のWLD価格予測は、2025年にWLDで大幅に増加すると予想されています。市場分析は、平均WLD価格が1.31ドルに達する可能性があり、最大1.36ドルであることを示しています。ただし、クマ市場では、価格は約0.55ドルに低下する可能性があります。この成長の期待は、主にWorldCoin2によるものです。
 クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションとはどういう意味ですか?クロスチェーントランザクションとは何ですか?
Apr 21, 2025 pm 11:39 PM
クロスチェーントランザクションをサポートする交換:1。Binance、2。Uniswap、3。Sushiswap、4。CurveFinance、5。Thorchain、6。1inchExchange、7。DLNTrade、これらのプラットフォームはさまざまな技術を通じてマルチチェーン資産トランザクションをサポートします。
 なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
なぜ仮想通貨価格の上昇または下落があるのですか?なぜ仮想通貨価格の上昇または下落があるのですか?
Apr 21, 2025 am 08:57 AM
仮想通貨価格の上昇の要因には、次のものが含まれます。1。市場需要の増加、2。供給の減少、3。刺激された肯定的なニュース、4。楽観的な市場感情、5。マクロ経済環境。衰退要因は次のとおりです。1。市場需要の減少、2。供給の増加、3。ネガティブニュースのストライキ、4。悲観的市場感情、5。マクロ経済環境。
 カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
カーネルエアドロップ報酬を獲得する方法バイナンスフルプロセス戦略
Apr 21, 2025 pm 01:03 PM
暗号通貨の賑やかな世界では、新しい機会が常に現れます。現在、Kerneldao(Kernel)Airdropアクティビティは多くの注目を集め、多くの投資家の注目を集めています。それで、このプロジェクトの起源は何ですか? BNBホルダーはそれからどのような利点を得ることができますか?心配しないでください、以下はあなたのためにそれを一つ一つ明らかにします。
 Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Tokenの買戻しを導入するための推奨事項です。
Apr 21, 2025 pm 06:24 PM
Aavenomicsは、Aaveプロトコルトークンを変更し、Aavedaoの定足数を実装したToken Reposを導入する提案です。 Aave Project Chain(ACI)の創設者であるMarc Zellerは、これをXで発表し、契約の新しい時代をマークしていることに注目しました。 Aave Chain Initiative(ACI)の創設者であるMarc Zellerは、Aavenomicsの提案にAave Protocolトークンの変更とトークンリポジトリの導入が含まれていると発表しました。 Zellerによると、これは契約の新しい時代を告げています。 Aavedaoのメンバーは、水曜日の週に100でした。
 ハイブリッドブロックチェーン取引プラットフォームとは何ですか?
Apr 21, 2025 pm 11:36 PM
ハイブリッドブロックチェーン取引プラットフォームとは何ですか?
Apr 21, 2025 pm 11:36 PM
暗号通貨交換を選択するための提案:1。流動性の要件については、優先度は、その順序の深さと強力なボラティリティ抵抗のため、Binance、gate.ioまたはokxです。 2。コンプライアンスとセキュリティ、Coinbase、Kraken、Geminiには厳格な規制の承認があります。 3.革新的な機能、Kucoinのソフトステーキング、Bybitのデリバティブデザインは、上級ユーザーに適しています。
 通貨サークル市場に関するリアルタイムデータの上位10の無料プラットフォーム推奨事項がリリースされます
Apr 22, 2025 am 08:12 AM
通貨サークル市場に関するリアルタイムデータの上位10の無料プラットフォーム推奨事項がリリースされます
Apr 22, 2025 am 08:12 AM
初心者に適した暗号通貨データプラットフォームには、Coinmarketcapと非小さいトランペットが含まれます。 1。CoinMarketCapは、初心者と基本的な分析のニーズに合わせて、グローバルなリアルタイム価格、市場価値、取引量のランキングを提供します。 2。小さい引用は、中国のユーザーが低リスクの潜在的なプロジェクトをすばやくスクリーニングするのに適した中国フレンドリーなインターフェイスを提供します。
 Rexas Finance(RXS)は、2025年にSolana(Sol)、Cardano(ADA)、XRP、Dogecoin(Doge)を上回ることができます
Apr 21, 2025 pm 02:30 PM
Rexas Finance(RXS)は、2025年にSolana(Sol)、Cardano(ADA)、XRP、Dogecoin(Doge)を上回ることができます
Apr 21, 2025 pm 02:30 PM
不安定な暗号通貨市場では、投資家は人気のある通貨を超えた代替品を探しています。 Solana(Sol)、Cardano(ADA)、XRP、Dogecoin(DOGE)などのよく知られた暗号通貨も、市場の感情、規制の不確実性、スケーラビリティなどの課題に直面しています。ただし、新しい新興プロジェクトであるRexasFinance(RXS)が出現しています。それは有名人の効果や誇大広告に依存するのではなく、現実世界の資産(RWA)とブロックチェーン技術を組み合わせて投資家に革新的な投資方法を提供することに焦点を当てています。この戦略により、2025年の最も成功したプロジェクトの1つになることを望んでいます。Rexasfi
