

たった1枚の写真からAI動画が生成できる! Googleの新たな普及モデルでキャラクターが動く

写真と音声だけで、キャラクターが話しているビデオを直接生成できます。
最近、Google の研究者がマルチモーダル拡散モデル VLOGGER をリリースし、バーチャル デジタル ヒューマンに一歩近づきました。

#論文アドレス: https://enriccorona.github.io/vlogger/paper.pdf
Vlogger は、単一の入力画像を収集し、テキストまたはオーディオ ドライバーを使用して、口の形、表情、体の動きなどを含む非常に自然な人間の音声のビデオを生成できます。
まずはいくつかの例を見てみましょう:




ビデオ内での他の人の声の使用が少し矛盾していると感じる場合は、エディターが音をオフにするお手伝いをします:

VLOGGER は、人間を 3D モーションに変換するモデルや、時間と空間を介して制御するための新しい拡散ベースのアーキテクチャなど、拡散モデルの生成における最近の成功に基づいて構築されており、テキストで生成された画像。



 #以前の同様のモデルと比較して、VLOGGER は個人に対してトレーニングする必要がなく、トレーニングを行うことができます。顔の検出やトリミングに依存するのではなく、体の動き、胴体、背景もコミュニケーション可能な通常の人間の表現を構成します。
#以前の同様のモデルと比較して、VLOGGER は個人に対してトレーニングする必要がなく、トレーニングを行うことができます。顔の検出やトリミングに依存するのではなく、体の動き、胴体、背景もコミュニケーション可能な通常の人間の表現を構成します。
AI音声、AI表現、AIアクション、AIシーン、最初はデータを提供することが人間の価値ですが、将来的には価値がなくなるのでは?

 データ面では、研究者は以前の同様のデータセットよりも新しく多様なデータセット MENTOR を収集しました。データ セットは一桁大きく、トレーニング セットには 2,200 時間、800,000 人の異なる個人が含まれ、テスト セットには 120 時間、異なるアイデンティティを持つ 4,000 人の人々が含まれていました。
データ面では、研究者は以前の同様のデータセットよりも新しく多様なデータセット MENTOR を収集しました。データ セットは一桁大きく、トレーニング セットには 2,200 時間、800,000 人の異なる個人が含まれ、テスト セットには 120 時間、異なるアイデンティティを持つ 4,000 人の人々が含まれていました。
 研究者らは 3 つの異なるベンチマークで VLOGGER を評価し、このモデルが画質、アイデンティティの保持、最適な時間的一貫性。
研究者らは 3 つの異なるベンチマークで VLOGGER を評価し、このモデルが画質、アイデンティティの保持、最適な時間的一貫性。

VLOGGER
VLOGGER の目標は、対象者が話すプロセス全体を描写する可変長のリアルなビデオを生成することです。 , 頭の動きやジェスチャーが含まれます。

上記のとおり、列 1 に示されている単一の入力画像とサンプル音声入力が与えられた場合、一連の合成画像が得られます。
頭の動き、視線、まばたき、唇の動きの生成、および以前のモデルではできなかった上半身とジェスチャーの生成が含まれており、これはオーディオ駆動合成の大きな進歩です。 。
VLOGGER は、ランダム拡散モデルに基づく 2 段階のパイプラインを採用し、音声からビデオへの 1 対多のマッピングをシミュレートします。
最初のネットワークは、音声波形を入力として受け取り、ターゲット ビデオ全体にわたって視線、顔の表情、ジェスチャーを制御する身体動作制御を生成します。
2 番目のネットワークは、大規模画像拡散モデルを拡張して、予測された身体制御を使用して対応するフレームを生成する時間的な画像間変換モデルです。このプロセスを特定のアイデンティティと一致させるために、ネットワークは対象者の参照画像を取得します。
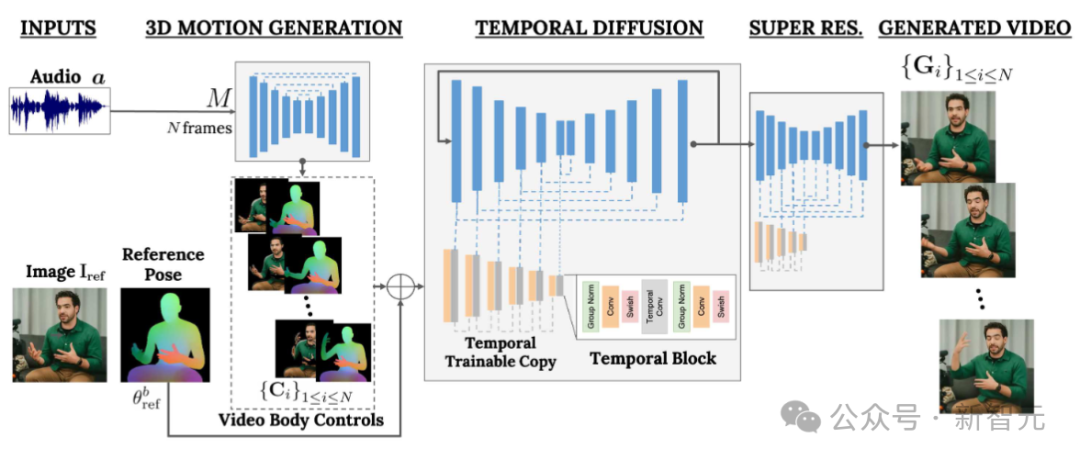
VLOGGER は、統計に基づいた 3D ボディ モデルを使用してビデオ生成プロセスを調整します。入力画像が与えられると、予測された形状パラメーターはターゲット ID の幾何学的特性をエンコードします。
まず、ネットワーク M は入力音声を取得し、3D の顔の表情と体のポーズの一連の N フレームを生成します。
動く 3D ボディの高密度表現は、ビデオ生成段階で 2D コントロールとして機能するようにレンダリングされます。これらの画像は、入力画像とともに、時間拡散モデルおよび超解像度モジュールへの入力として機能します。
オーディオ主導のモーション生成
パイプラインの最初のネットワークは、入力音声に基づいてモーションを予測するように設計されています。 。さらに、入力テキストはテキスト読み上げモデルを通じて波形に変換され、生成された音声は標準のメル スペクトログラムとして表現されます。
パイプラインは Transformer アーキテクチャに基づいており、時間次元に 4 つのマルチヘッド アテンション レイヤーがあります。フレーム番号と拡散ステップの位置エンコーディング、および入力オーディオと拡散ステップの埋め込み MLP が含まれます。
各フレームで因果マスクを使用して、モデルが前のフレームのみに焦点を当てるようにします。モデルは可変長ビデオ (TalkingHead-1KH データセットなど) を使用してトレーニングされ、非常に長いシーケンスを生成します。
研究者らは、統計に基づいて推定された 3D 人体モデルのパラメーターを使用して、合成ビデオの中間制御表現を生成します。
モデルは、顔の表情と体の動きの両方を考慮して、より表現力豊かでダイナミックなジェスチャーを生成します。
さらに、以前の顔生成作業は通常、ワープされた画像に依存していましたが、この方法は拡散ベースのアーキテクチャでは無視されてきました。
著者らは、歪んだ画像を使用して生成プロセスをガイドすることを推奨しています。これにより、ネットワークのタスクが容易になり、キャラクターの主体性の維持に役立ちます。
#話したり動く人間を生成する
#次の目標は、入力画像に対してモーション処理を実行することです。 person を作成し、事前に予測された体と顔の動きに追従させます。
ControlNet に触発されて、研究者らは最初にトレーニングされたモデルを凍結し、入力時間制御を使用してゼロ初期化されたトレーニング可能なエンコード層のコピーを作成しました。
著者は、時間領域で 1 次元の畳み込み層をインターリーブし、連続する N 個のフレームとコントロールを取得することでネットワークをトレーニングし、入力されたコントロールに基づいて参照キャラクターのアクション ビデオを生成します。
モデルは、作成者によって構築された MENTOR データセットを使用してトレーニングされます。トレーニング プロセス中に、ネットワークは一連の連続フレームと任意の参照画像を取得するため、理論上は任意のビデオはフレームを参照として指定できます。
ただし、実際には、サンプルが近いほど一般化の可能性が低くなるため、著者はターゲット クリップから遠く離れた参照をサンプリングすることを選択します。
ネットワークは 2 段階でトレーニングされます。最初に単一フレームで新しい制御層を学習し、次に時間コンポーネントを追加してビデオでトレーニングします。これにより、最初の段階で大規模なバッチを使用し、ヘッド リプレイ タスクをより速く学習できるようになります。
著者が採用した学習率は 5e-5 で、画像モデルは両方のステージでステップ サイズ 400k、バッチ サイズ 128 でトレーニングされています。
#多様性
次の図は、入力画像から生成されたターゲット ビデオの多様な分布を示しています。一番右の列は、生成された 80 個のビデオから得られたピクセルの多様性を示しています。

背景は固定されたままですが、人の頭と体は大きく動きます (赤はピクセルの色の多様性が高いことを意味します)。そして、多様性にもかかわらず、すべてビデオがリアルに見えます。
ビデオ編集

モデルの応用例の 1 つは、次のようなものです。既存のビデオを編集します。この場合、VLOGGER はビデオを撮影し、被写体の口や目を閉じるなどの表情を変えます。
実際には、作成者は拡散モデルの柔軟性を利用して、変更する必要がある画像の部分を修復し、ビデオ編集を元の変更されていないピクセルと一致させます。
ビデオ翻訳
モデルの主な用途の 1 つはビデオ翻訳です。この場合、VLOGGER は特定の言語で既存のビデオを取得し、新しい音声 (スペイン語など) に合わせて唇と顔の領域を編集します。
以上がたった1枚の写真からAI動画が生成できる! Googleの新たな普及モデルでキャラクターが動くの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
19
20
15
1376
52
77
11
19
20

 OPPO Phoneで画面ビデオを録画する方法(簡単な操作)
May 07, 2024 pm 06:22 PM
OPPO Phoneで画面ビデオを録画する方法(簡単な操作)
May 07, 2024 pm 06:22 PM
ゲームのスキルや指導のデモンストレーションなど、日常生活では、操作手順を示すために携帯電話を使用して画面ビデオを録画する必要がよくあります。画面録画機能も非常に優れており、OPPO携帯電話は強力なスマートフォンです。録画タスクを簡単かつ迅速に完了できるように、この記事では、OPPO 携帯電話を使用して画面ビデオを録画する方法を詳しく紹介します。準備 - 録音の目標を決定する 開始する前に、録音の目標を明確にする必要があります。ステップバイステップのデモビデオを録画したいですか?それともゲームの素晴らしい瞬間を記録したいですか?それとも教育ビデオを録画したいですか?録音プロセスをより適切に調整し、明確な目標を設定することによってのみ可能です。 OPPO 携帯電話の画面録画機能を開き、ショートカット パネルで見つけます。 画面録画機能はショートカット パネルにあります。
 クアッドコアと 8 コアのコンピュータ CPU の違いは何ですか?
May 06, 2024 am 09:46 AM
クアッドコアと 8 コアのコンピュータ CPU の違いは何ですか?
May 06, 2024 am 09:46 AM
クアッドコアと 8 コアのコンピュータ CPU の違いは何ですか?違いは処理速度とパフォーマンスです。クアッドコア CPU には 4 つのプロセッサ コアがあり、8 コア CPU には 8 つのコアがあります。これは、前者は同時に 4 つのタスクを実行でき、後者は同時に 8 つのタスクを実行できることを意味します。したがって、大量のデータを処理したり、複数のプログラムを実行したりする場合、オクタコア CPU はクアッドコア CPU よりも高速になります。同時に、8 コア CPU は、ビデオ編集やゲームなどのマルチメディア作業にもより適しています。これらのタスクではより高い処理速度と優れたグラフィックス処理能力が必要となるからです。ただし、8 コア CPU のコストも高くなるため、実際のニーズと予算に基づいて適切な CPU を選択することが非常に重要です。コンピューターの CPU はデュアルコアとクアッドコアのどちらの方が良いですか?デュアルコアとクアッドコアのどちらが優れているかは、使用上のニーズによって異なります。
 Adobe After Effects cs6 (Ae cs6) で言語を切り替える方法 Ae cs6 で中国語と英語を切り替える詳細な手順 - ZOL ダウンロード
May 09, 2024 pm 02:00 PM
Adobe After Effects cs6 (Ae cs6) で言語を切り替える方法 Ae cs6 で中国語と英語を切り替える詳細な手順 - ZOL ダウンロード
May 09, 2024 pm 02:00 PM
1. まず、AMTLanguages フォルダーを見つけます。 AMTLanguages フォルダーにいくつかのドキュメントが見つかりました。簡体字中国語をインストールすると、zh_CN.txt テキスト ドキュメントが作成されます (テキストの内容は zh_CN)。英語でインストールした場合は、テキスト ドキュメント en_US.txt が作成されます (テキストの内容は en_US)。 3. したがって、中国語に切り替えたい場合は、AdobeAfterEffectsCCSupportFilesAMTLanguages パスの下に zh_CN.txt (テキストの内容: zh_CN) の新しいテキストドキュメントを作成する必要があります。 4. 逆に、英語に切り替えたい場合は、
 Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
何?ズートピアは国産AIによって実現するのか?ビデオとともに公開されたのは、「Keling」と呼ばれる新しい大規模な国産ビデオ生成モデルです。 Sora も同様の技術的ルートを使用し、自社開発の技術革新を多数組み合わせて、大きく合理的な動きをするだけでなく、物理世界の特性をシミュレートし、強力な概念的結合能力と想像力を備えたビデオを制作します。データによると、Keling は、最大 1080p の解像度で 30fps で最大 2 分の超長時間ビデオの生成をサポートし、複数のアスペクト比をサポートします。もう 1 つの重要な点は、Keling は研究所が公開したデモやビデオ結果のデモンストレーションではなく、ショートビデオ分野のリーダーである Kuaishou が立ち上げた製品レベルのアプリケーションであるということです。さらに、主な焦点は実用的であり、白紙小切手を書かず、リリースされたらすぐにオンラインに移行することです。Ke Ling の大型モデルは Kuaiying でリリースされました。
 アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
最近、軍事界は、米軍戦闘機が AI を使用して完全自動空戦を完了できるようになったというニュースに圧倒されました。そう、つい最近、米軍のAI戦闘機が初めて公開され、その謎が明らかになりました。この戦闘機の正式名称は可変安定性飛行シミュレーター試験機(VISTA)で、アメリカ空軍長官が自ら飛行させ、一対一の空戦をシミュレートした。 5 月 2 日、フランク ケンダル米国空軍長官は X-62AVISTA でエドワーズ空軍基地を離陸しました。1 時間の飛行中、すべての飛行動作が AI によって自律的に完了されたことに注目してください。ケンダル氏は「過去数十年にわたり、私たちは自律型空対空戦闘の無限の可能性について考えてきたが、それは常に手の届かないものだと思われてきた」と語った。しかし今では、
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
 わずか 250 ドルで、Hugging Face のテクニカル ディレクターが Llama 3 を段階的に微調整する方法を教えます
May 06, 2024 pm 03:52 PM
わずか 250 ドルで、Hugging Face のテクニカル ディレクターが Llama 3 を段階的に微調整する方法を教えます
May 06, 2024 pm 03:52 PM
Meta が立ち上げた Llama3、MistralAI が立ち上げた Mistral および Mixtral モデル、AI21 Lab が立ち上げた Jamba など、おなじみのオープンソースの大規模言語モデルは、OpenAI の競合相手となっています。ほとんどの場合、モデルの可能性を最大限に引き出すには、ユーザーが独自のデータに基づいてこれらのオープンソース モデルを微調整する必要があります。単一の GPU で Q-Learning を使用して、大規模な言語モデル (Mistral など) を小規模な言語モデルに比べて微調整することは難しくありませんが、Llama370b や Mixtral のような大規模なモデルを効率的に微調整することは、これまで課題として残されています。 。したがって、HuggingFace のテクニカル ディレクター、Philipp Sch 氏は次のように述べています。
 携帯電話向けおすすめ動画圧縮ソフト(画質を落とさずに圧縮した動画)
May 06, 2024 pm 06:31 PM
携帯電話向けおすすめ動画圧縮ソフト(画質を落とさずに圧縮した動画)
May 06, 2024 pm 06:31 PM
スマートフォンの発展に伴い、私たちはスマートフォンを使ってビデオを視聴したり録画したりすることがますます増えています。ただし、HD ビデオの保存スペースは多くのスペースを占有するため、携帯電話上のビデオの量と品質が制限されます。この記事では、ビデオの品質を維持しながら、携帯電話の空き容量を増やすために、いくつかの携帯電話用ビデオ圧縮ソフトウェアをお勧めします。 1. 動画圧縮ソフトとは何ですか?ビデオ圧縮ソフトウェアを使用すると、ビデオ ファイルのサイズを小さくして、携帯電話のストレージ領域を解放できます。この圧縮は可逆圧縮であるため、ファイル サイズが小さくなってもビデオ品質に大きな影響はありません。 2. 動画圧縮の必要性 携帯電話のカメラ機能の向上により、ハイビジョンや4K解像度の動画が簡単に撮影できるようになりました。これらの高解像度ビデオ
