

マンバの超進化形態がトランスフォーマーを一挙に打ち破る! 140K コンテキストを実行する単一の A100

以前 AI サークルを爆発させた Mamba アーキテクチャが、本日スーパーバリアントをリリースしました。
人工知能のユニコーン AI21 Labs は、世界初の実稼働レベルの Mamba 大型モデルである Jamba をオープンソース化しました。

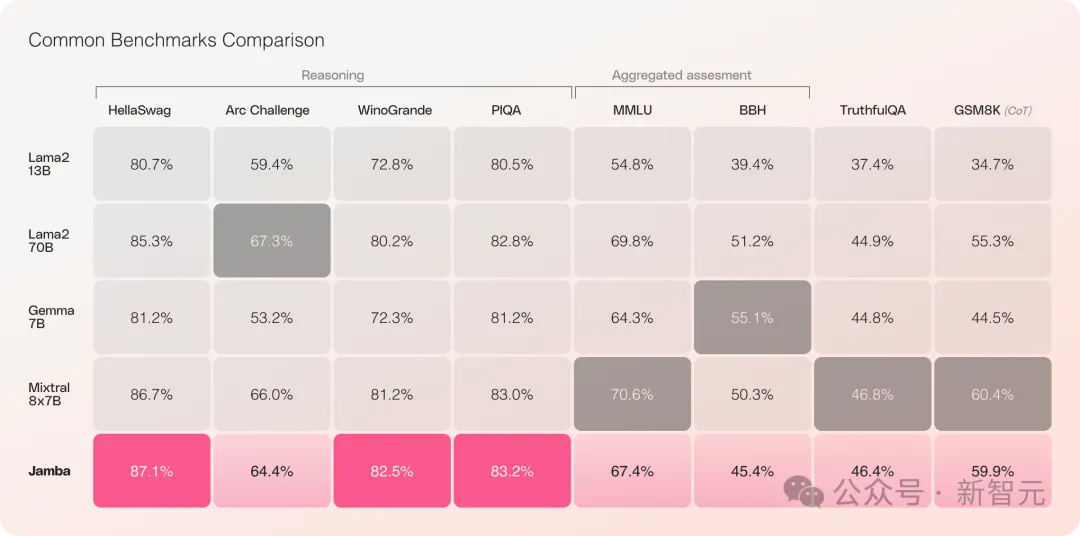
Jamba は複数のベンチマーク テストで良好なパフォーマンスを示し、現在最も強力なオープンソース Transformers の一部と同等の性能を示しています。
特に、最高のパフォーマンスを持ち、MoE アーキテクチャでもある Mixtral 8x7B を比較する場合、勝者と敗者も存在します。
具体的には、——
- は、新しい SSM-Transformer ハイブリッド アーキテクチャに基づく最初の製品グレードの Mamba モデルです
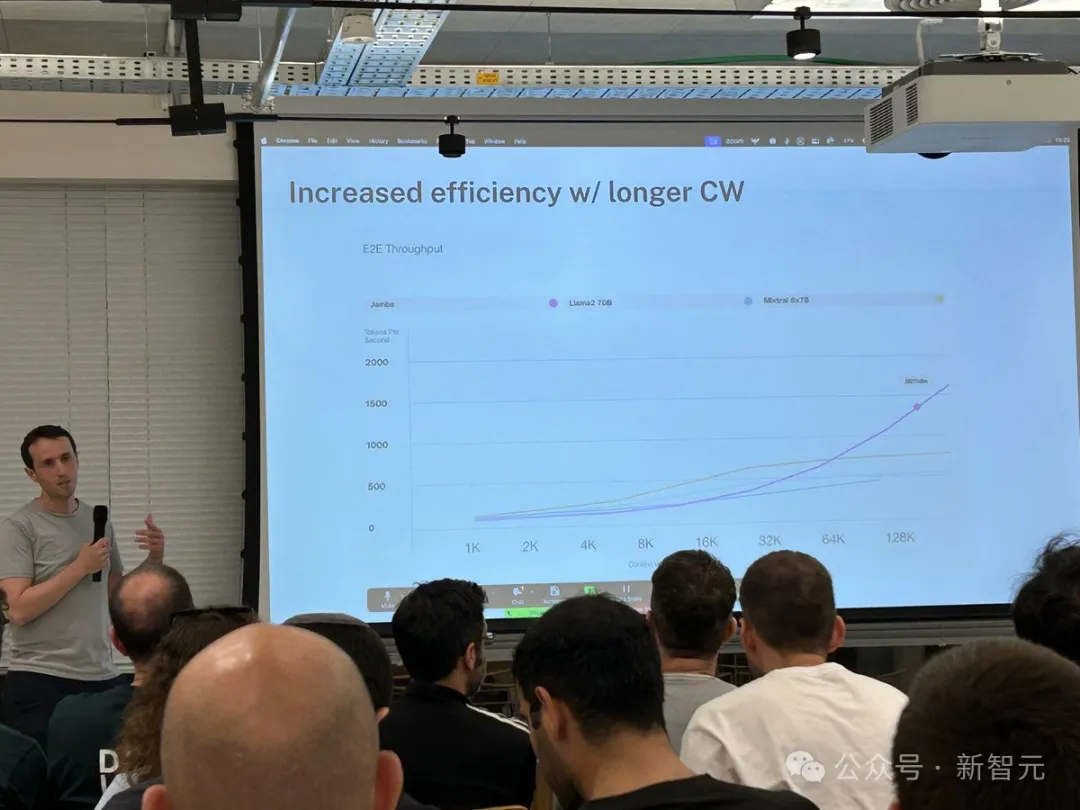
- Mixtral 8x7B と比較して長いテキスト処理のスループットが 3 倍増加
- 256K の超長いコンテキスト ウィンドウを達成
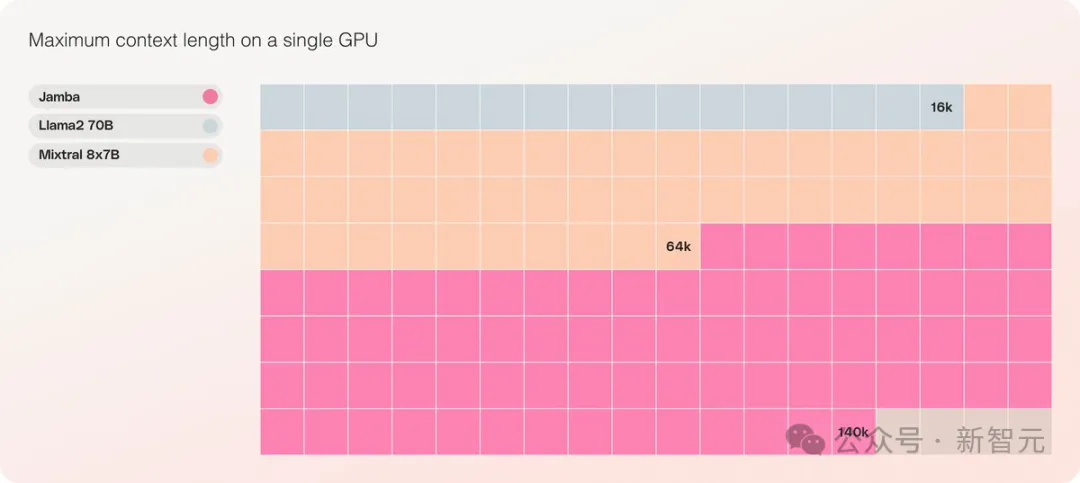
- これは、単一の GPU で 140K のコンテキストを処理できる同じ規模の唯一のモデルです
- Apache 2.0 オープン ソース ライセンスに基づいてリリースされ、大きなオープン権が付与されています
#従来のマンバはさまざまな制約により3Bしかできず、トランスフォーマーを引き継ぐことができるかどうかも疑問視されていました。一方、同じく線形 RNN ファミリである RWKV、Griffin などは 14B までしか拡張されていません。
——今回、Jamba は直接 52B に移行し、Mamba アーキテクチャが製品レベルの Transformer と初めて正面から競合できるようになりました。

オリジナルの Mamba アーキテクチャに基づいて、Jamba は状態空間の欠点を補うために Transformer の利点を組み込んでいます。モデル (SSM) 固有の制限。
これは実際には新しいアーキテクチャであると考えることができます。最も重要なことは、Transformer と Mamba を組み合わせたものです。素晴らしいのは、1 台の A100 で実行できることです。
最大 256K の超長いコンテキスト ウィンドウを提供し、単一の GPU で 140K のコンテキストを実行でき、スループットは Transformer の 3 倍です。
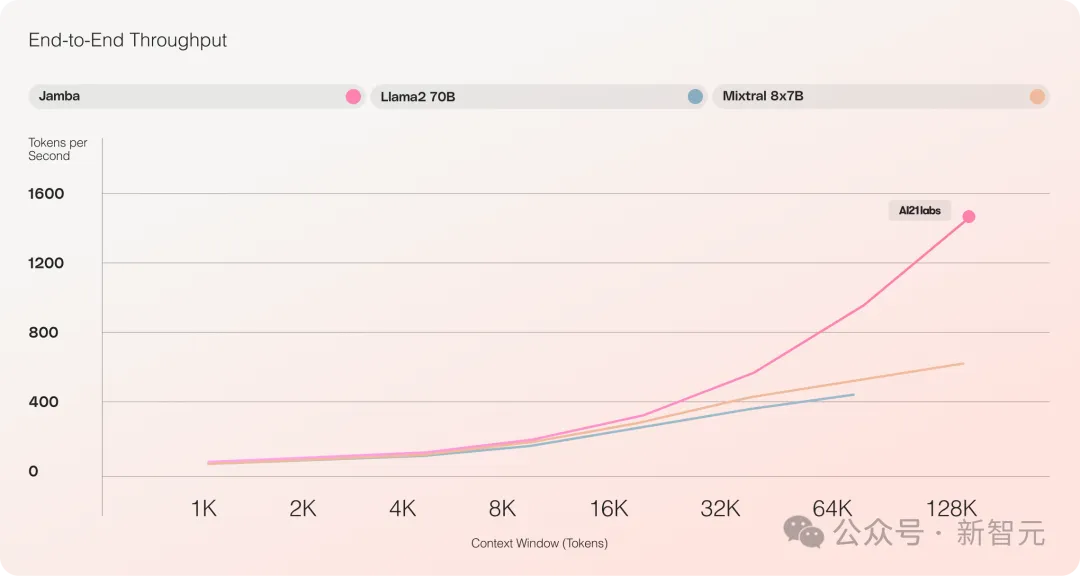
Transformer と比較すると、Jamba が巨大なコンテキスト長にどのように対応するかを見るのは非常に衝撃的です。
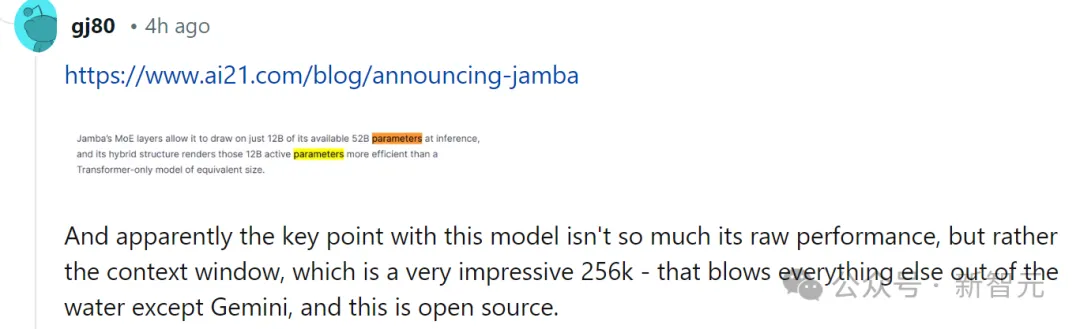
Jamba は MoE ソリューションを採用しています。52B のうち 12B がアクティブなパラメータです。現在のモデルは Apache 2.0 でオープン ウェイトを持ち、huggingface でダウンロードできます。

LLM の新しいマイルストーン
Jamba のリリースは、LLM にとって 2 つの重要なマイルストーンを示します:まず、Mamba と Transformer の統合が成功しました。 2 つ目は、新しい形式のモデル (SSM-Transformer) を実稼働レベルのスケールと品質にアップグレードすることに成功することです。
最強のパフォーマンスを備えた現在の大規模モデルはすべて Transformer に基づいていますが、Transformer アーキテクチャの 2 つの主な欠点も誰もが認識しています。
大きなメモリ フットプリント: Transformer のメモリ フットプリントは、コンテキストの長さに応じて拡大します。長いコンテキスト ウィンドウや大規模な並列バッチ処理を実行するには、大量のハードウェア リソースが必要となるため、大規模な実験や展開が制限されます。数年前、カーネギーメロン大学とプリンストン大学の 2 人の偉人が Mamba を提案し、人々の希望にすぐに火をつけました。コンテキストが大きくなるにつれて、推論速度は遅くなります。Transformer のアテンション メカニズムにより、推論時間はシーケンスの長さに比例して増加し、スループットはますます遅くなります。各トークンはその前のシーケンス全体に依存するため、非常に長いコンテキストを実現するのは非常に困難になります。
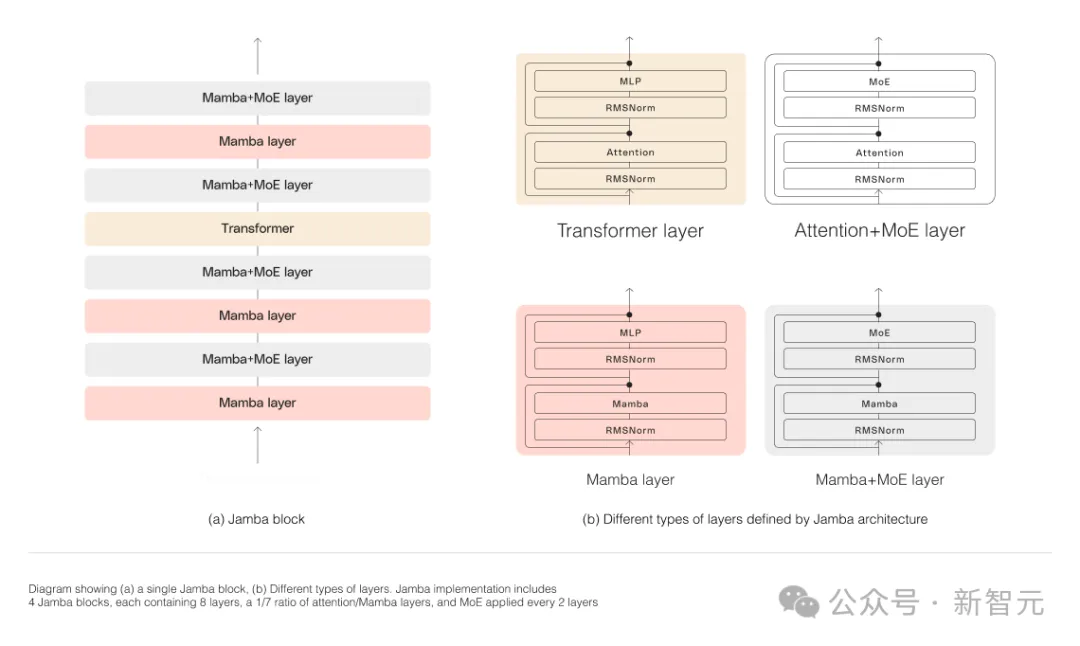
Mamba is based on SSM, adds the ability to selectively extract information, and efficient algorithms on hardware, solving the problems of Transformer in one fell swoop. This new field immediately attracted a large number of researchers. A large number of applications and improvements about Mamba emerged on arXiv, such as Vision Mamba, which uses Mamba for vision. I have to say that the current scientific research field is really complicated. It took three years to introduce Transformer into Vision (ViT), but Mamba arrived Vision Mamba only lasted a month. However, the context length of the original Mamba is shorter, and the model itself has not been enlarged, so it is difficult to beat the SOTA Transformer model, especially in tasks related to recall. Jamba then went a step further and integrated the advantages of Transformer, Mamba, and Mix of Experts (MoE) through the Joint Attention and Mamba architecture, while optimizing memory, throughput and performance. Jamba is the first hybrid architecture to reach production scale (52B parameters). As shown in the figure below, AI21’s Jamba architecture adopts a blocks-and-layers approach, allowing Jamba to successfully integrate the two architectures. Each Jamba block consists of an attention layer or a Mamba layer, followed by a multilayer perceptron (MLP). The second feature of Jamba is to use MoE to increase the total number of model parameters and simplify the parameters used in inference. number of active parameters, thereby increasing model capacity without increasing computational requirements. To maximize model quality and throughput on a single 80GB GPU, the researchers optimized the number of MoE layers and experts used, leaving room for common inference workloads enough memory. Compared with Transformer-based models of similar size such as Mixtral 8x7B, Jamba achieves 3 times acceleration in long contexts . Jamba will be added to the NVIDIA API directory soon. Recently, major companies are rolling out long context. Models with smaller context windows tend to forget the content of recent conversations, while models with larger context avoid this pitfall and can better grasp what they receive data flow. However, models with long context windows tend to be computationally intensive. Generative models from startup AI21 Labs prove that this is not the case. Jamba can handle up to 140,000 when running on a single GPU (such as the A100) with at least 80GB of video memory token. This equates to approximately 105,000 words, or 210 pages, which is the length of a medium-length novel. In contrast, Meta Llama 2’s context window has only 32,000 tokens and requires 12GB of GPU memory. By today's standards, this context window is obviously small. Regarding this, some netizens immediately said that performance is not important. The key is that Jamba has a 256K context. Except for Gemini, no one else is that long. — —And Jamba is open source. On the surface, Jamba seems unremarkable. Whether it is DBRX, which was in the limelight yesterday, or Llama 2, there are now a large number of free and downloadable generative AI models. The uniqueness of Jamba is hidden under the model: it combines two model architectures at the same time-Transformer and state space model SSM. On the one hand, Transformer is the preferred architecture for complex reasoning tasks. Its core defining feature is the “attention mechanism”. For each piece of input data, the Transformer weighs the relevance of all other inputs and extracts from them to generate the output. On the other hand, SSM combines many advantages of earlier AI models, such as recurrent neural networks and convolutional neural networks, so it can process long sequence data with high computational efficiency. higher. Although SSM has its own limitations. But some early representatives, such as Mamba proposed by Princeton and CMU, can handle larger outputs than the Transformer model and are better at language generation tasks. In this regard, AI21 Labs product manager Dagan said - Although there are some preliminary examples of SSM models, Jamba is the first production-scale commercial grade model. In his view, in addition to being innovative and interesting for the community to further study, Jamba also provides huge efficiency and throughput possibilities. Currently, Jamba is released under the Apache 2.0 license, with fewer usage restrictions but not for commercial use. Subsequent fine-tuned versions are expected to be launched within a few weeks. Even though it is still in the early stages of research, Dagan asserts that Jamba undoubtedly shows the great promise of the SSM architecture. "The added value of this model - both due to size and architectural innovation - is that it can be easily installed on a single GPU." 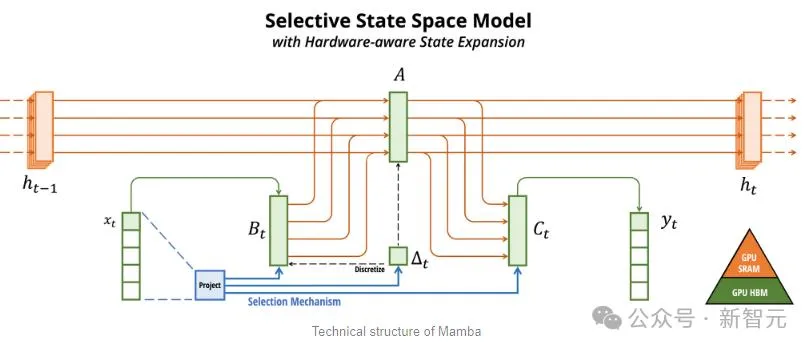

Long context has a new player

What makes Jamba truly unique
以上がマンバの超進化形態がトランスフォーマーを一挙に打ち破る! 140K コンテキストを実行する単一の A100の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7470
7470
 15
1377
52
77
11
19
29
15
1377
52
77
11
19
29

 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
MySQLはJSONデータを返すことができます。 json_extract関数はフィールド値を抽出します。複雑なクエリについては、Where句を使用してJSONデータをフィルタリングすることを検討できますが、そのパフォーマンスへの影響に注意してください。 JSONに対するMySQLのサポートは絶えず増加しており、最新バージョンと機能に注意を払うことをお勧めします。
 酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
データベース酸属性の詳細な説明酸属性は、データベーストランザクションの信頼性と一貫性を確保するための一連のルールです。データベースシステムがトランザクションを処理する方法を定義し、システムのクラッシュ、停電、または複数のユーザーの同時アクセスの場合でも、データの整合性と精度を確保します。酸属性の概要原子性:トランザクションは不可分な単位と見なされます。どの部分も失敗し、トランザクション全体がロールバックされ、データベースは変更を保持しません。たとえば、銀行の譲渡が1つのアカウントから控除されているが別のアカウントに増加しない場合、操作全体が取り消されます。 TRANSACTION; updateaccountssetbalance = balance-100wh
 マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
sqllimit句:クエリ結果の行数を制御します。 SQLの制限条項は、クエリによって返される行数を制限するために使用されます。これは、大規模なデータセット、パジネートされたディスプレイ、テストデータを処理する場合に非常に便利であり、クエリ効率を効果的に改善することができます。構文の基本的な構文:SelectColumn1、column2、... FromTable_nameLimitnumber_of_rows; number_of_rows:返された行の数を指定します。オフセットの構文:SelectColumn1、column2、... FromTable_nameLimitoffset、number_of_rows; offset:skip
 バングラ部分モデル検索のlaravelEloquent orm)
Apr 08, 2025 pm 02:06 PM
バングラ部分モデル検索のlaravelEloquent orm)
Apr 08, 2025 pm 02:06 PM
LaravelEloquentモデルの検索:データベースデータを簡単に取得するEloquentormは、データベースを操作するための簡潔で理解しやすい方法を提供します。この記事では、さまざまな雄弁なモデル検索手法を詳細に紹介して、データベースからのデータを効率的に取得するのに役立ちます。 1.すべてのレコードを取得します。 ALL()メソッドを使用して、データベーステーブルですべてのレコードを取得します:useapp \ models \ post; $ post = post :: all();これにより、コレクションが返されます。 Foreach Loopまたはその他の収集方法を使用してデータにアクセスできます。
 MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLプライマリキーは、データベース内の各行を一意に識別するキー属性であるため、空にすることはできません。主キーが空になる可能性がある場合、レコードを一意に識別することはできません。これにより、データの混乱が発生します。一次キーとして自己挿入整数列またはUUIDを使用する場合、効率やスペース占有などの要因を考慮し、適切なソリューションを選択する必要があります。
 高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
高負荷アプリケーションのMySQLパフォーマンスを最適化する方法は?
Apr 08, 2025 pm 06:03 PM
MySQLデータベースパフォーマンス最適化ガイドリソース集約型アプリケーションでは、MySQLデータベースが重要な役割を果たし、大規模なトランザクションの管理を担当しています。ただし、アプリケーションのスケールが拡大すると、データベースパフォーマンスのボトルネックが制約になることがよくあります。この記事では、一連の効果的なMySQLパフォーマンス最適化戦略を検討して、アプリケーションが高負荷の下で効率的で応答性の高いままであることを保証します。実際のケースを組み合わせて、インデックス作成、クエリ最適化、データベース設計、キャッシュなどの詳細な主要なテクノロジーを説明します。 1.データベースアーキテクチャの設計と最適化されたデータベースアーキテクチャは、MySQLパフォーマンスの最適化の基礎です。いくつかのコア原則は次のとおりです。適切なデータ型を選択し、ニーズを満たす最小のデータ型を選択すると、ストレージスペースを節約するだけでなく、データ処理速度を向上させることもできます。
 MySQLにはサーバーが必要ですか
Apr 08, 2025 pm 02:12 PM
MySQLにはサーバーが必要ですか
Apr 08, 2025 pm 02:12 PM
生産環境の場合、パフォーマンス、信頼性、セキュリティ、スケーラビリティなどの理由により、通常、MySQLを実行するためにサーバーが必要です。サーバーには通常、より強力なハードウェア、冗長構成、より厳しいセキュリティ対策があります。小規模で低負荷のアプリケーションの場合、MySQLはローカルマシンで実行できますが、リソースの消費、セキュリティリスク、メンテナンスコストを慎重に考慮する必要があります。信頼性とセキュリティを高めるには、MySQLをクラウドまたは他のサーバーに展開する必要があります。適切なサーバー構成を選択するには、アプリケーションの負荷とデータボリュームに基づいて評価が必要です。
