

社長が辞めてから初投稿です!安定性公式コードモデル Stable Code Instruct 3B
Mar 29, 2024 pm 10:16 PMボスが去った後、最初のモデルが登場しました!
本日、Stability AI は新しいコード モデルである Stable Code Instruct 3B を正式に発表しました。
 写真
写真
安定性は非常に重要です。CEO の辞任により、Stable Diffusion にいくつかの問題が発生しました。投資会社は、何か問題があれば、給料も下がってしまうかもしれません。
しかし、建物の外は騒然としていますが、研究室の中は静まっており、研究する必要があり、議論する必要があり、モデルを調整する必要があり、各分野で戦争が発生します。大型モデルが所定の位置に収まりました。
全面戦争に向けて広がっているだけでなく、あらゆる研究も日進月歩です 例えば、今日の安定版コード命令 3B は以前の安定版コードをベースにしています3B. 命令のチューニング。
 写真
写真
論文アドレス: https://static1.squarespace.com/static/6213c340453c3f502425776e/t/6601c5713150412edcd56f8e/1711392114564 /Stable_Code_TechReport_release.pdf
自然言語プロンプトを使用すると、Stable Code Instruct 3B は、コード生成、数学、その他のソフトウェア開発関連のクエリなどのさまざまなタスクを処理できます。
 画像
画像
同レベルでは無敵、飛び跳ねによる強力なキル
安定した Code Instruct 同じパラメータ数のモデルでは、3B は現在の SOTA を達成しており、サイズが 2 倍以上である CodeLlama 7B Instruct などのモデルよりも優れており、ソフトウェア エンジニアリング関連のタスクにおけるパフォーマンスは StarChat と同等です。 15B.
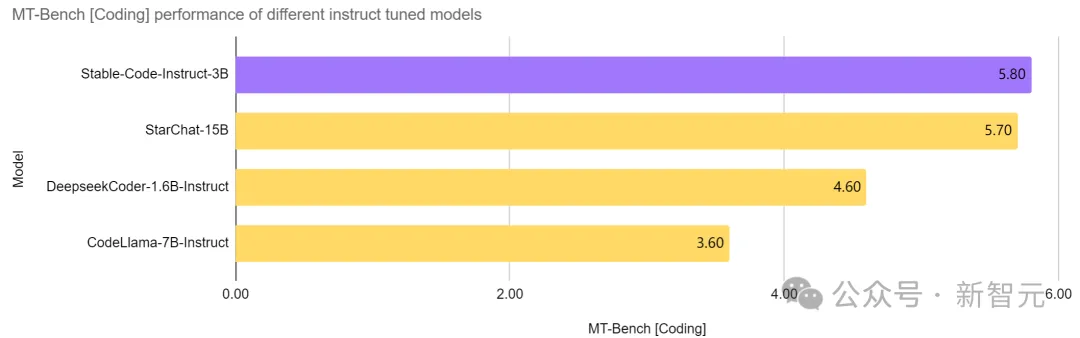 写真
写真
上の写真からわかるように、Codellama 7B Instruct や DeepSeek などの主要モデルと同等です。 -Coder Instruct 1.3B Stable Code Instruct 3B と比較すると、Stable Code Instruct 3B は、さまざまなコーディング タスクにわたって良好に実行されます。
テストの結果、Stable Code Instruct 3B は、コード補完の精度、自然言語命令の理解、およびさまざまなプログラミング言語の相手に対する汎用性の点で競合製品と同等またはそれを上回っていることが示されています。
 画像
画像
安定したコードの指示 3B Stack Overflow 2023 開発者アンケートの結果に基づいて、トレーニングは Python に焦点を当てています。 Javascript、Java、C、C、Goなどのプログラミング言語。
上のグラフは、Multi-PL ベンチマークを使用して、さまざまなプログラミング言語の 3 つのモデルによって生成された出力の強度を比較しています。 Stable Code Instruct 3B は、すべての言語において CodeLlama よりも大幅に優れており、パラメーターの数が半分以上であることがわかります。
上記の一般的なプログラミング言語に加えて、Stable Code Instruct 3B には、他の言語 (SQL、PHP、Rust など) のトレーニングも含まれています。トレーニングのない言語 (Lua など) では、強力なテスト パフォーマンスを提供することもできます。
安定したコード Instruct 3B は、コード生成だけでなく、FIM (Fill-in-the-Code) タスク、データベース クエリ、コード変換、解釈、作成にも熟練しています。
命令チューニングを通じて、モデルは微妙な命令を理解し、それに基づいて動作できるようになり、単純なコード補完を超えた、数学的理解、論理的推論、ソフトウェア処理などの幅広いコーディング タスクを容易にします。複雑な技術の開発。
 写真
写真
モデルのダウンロード: https://huggingface.co/stabilityai/stable-code-instruct-3b
Stable Code Instruct 3B は、Stability AI メンバーシップを通じて商用目的で利用できるようになりました。非営利目的の場合、モデルの重みとコードは Hugging Face からダウンロードできます。
技術的な詳細
 写真
写真
モデル アーキテクチャ
Stable Code は Stable LM 3B に基づいて構築されており、LLaMA と同様の設計を持つデコーダ専用の Transformer 構造です。次の表は、重要な構造情報の一部です:
 写真
写真
##LLaMA との主な違いは次のとおりです:
位置埋め込み: ヘッダー埋め込みの最初の 25% で回転位置埋め込みを使用して、その後のスループットを向上させます。
正則化: RMSNorm の代わりに学習バイアス項を含む LayerNorm を使用します。
バイアス項: KQV を除き、フィードフォワード ネットワークとマルチヘッド セルフ アテンション層のすべてのバイアス項が削除されます。
Stable LM 3B モデルと同じトークナイザー (BPE) を使用し、サイズは 50,257 です。さらに、ファイル名を示すなど、StarCoder の特別なマーカーも参照されます。 、ストレージ ライブラリ スター、中間補充 (FIM) など。
長いコンテキスト トレーニングの場合、連結された 2 つのファイルが同じリポジトリに属していることを示すために特別なマーカーが使用されます。
トレーニング プロセス
トレーニング データ
トレーニング前データコード リポジトリ、技術文書 (readthedocs など)、数学に焦点を当てたテキスト、広範な Web データセットなど、公的にアクセス可能なさまざまな大規模データ ソースが収集されます。
最初の事前トレーニング段階の主な目標は、豊富な内部表現を学習して、数学的理解、論理的推論、ソフトウェア開発に関連する複雑な技術文書の処理におけるモデルの能力を大幅に向上させることです。 。
さらに、トレーニング データには、より広範な言語知識とコンテキストをモデルに提供するための一般的なテキスト データセットが含まれており、最終的にはモデルがより広範囲のクエリやタスクを会話形式で処理できるようになります。 。
次の表は、事前トレーニング コーパスのデータ ソース、カテゴリ、およびサンプリングの重みを示しています。コード データと自然言語データの比率は 80:20 です。
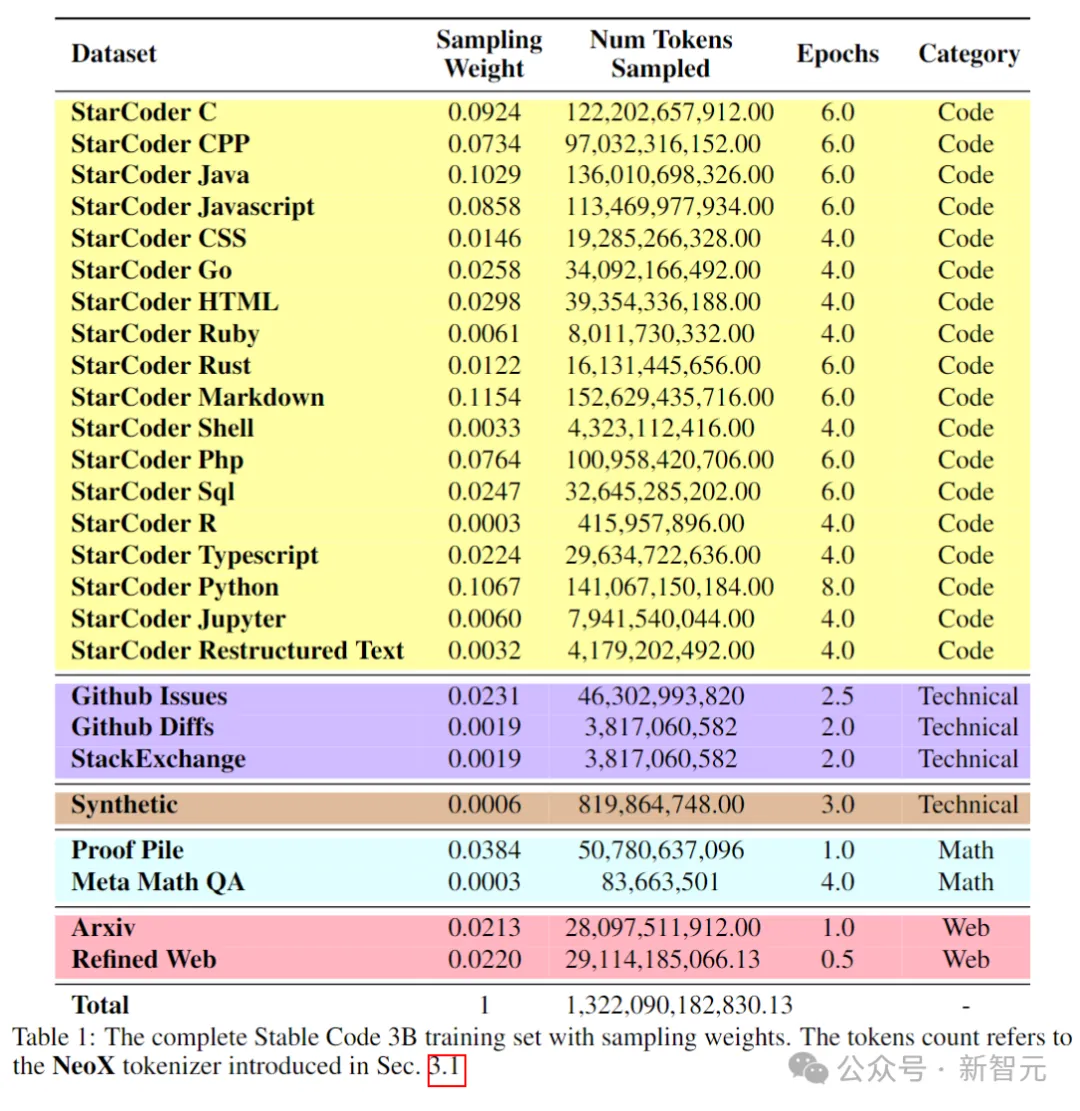 写真
写真
さらに、研究者らは小規模な合成データセットも導入しました。データは CodeAlpaca のシード プロンプトから合成されました。データセット、174,000 のヒントが含まれています。
そして、WizardLM メソッドに従い、指定されたシード プロンプトの複雑さを徐々に増やし、追加の 100,000 プロンプトを取得しました。
著者らは、トレーニング前の段階の早い段階でこの合成データを導入することで、モデルが自然言語テキストに対してより適切に応答できるようになると考えています。
長いコンテキスト データセット
リポジトリ内の複数のファイルは相互に依存していることが多いため、コンテキストの長さが重要ですエンコードにはモデルが重要です。
研究者らは、ソフトウェア リポジトリ内のトークン数の中央値と平均値がそれぞれ 12,000 と 18,000 であると推定したため、コンテキストの長さとして 16,384 が選択されました。
次のステップは、長いコンテキスト データセットを作成することでした。研究者たちは、リポジトリ内の一般的な言語で書かれたいくつかのファイルを取得し、それらを結合し、各ファイルの間に挿入しました。特別なタグコンテンツの流れを維持しながら分離を維持します。
ファイルの順序が固定されていることによって生じる可能性のある潜在的なバイアスを回避するために、作成者はランダム化戦略を採用しました。リポジトリごとに、2 つの異なるシーケンスの接続ファイルが生成されます。
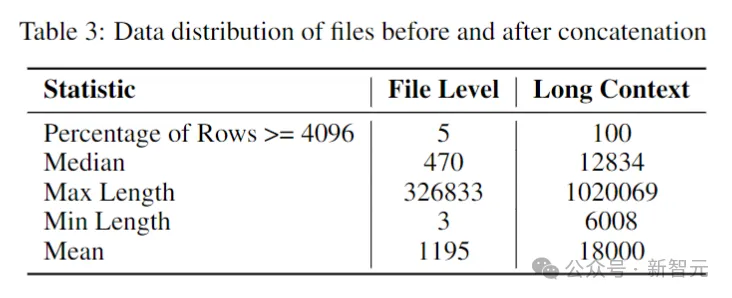 写真
写真
フェーズベースのトレーニング
安定版コードは、256 個の NVIDIA A100 (40GB HBM2) GPU を含む 32 個の Amazon P4d インスタンスをトレーニングに使用し、分散最適化に ZeRO を使用します。
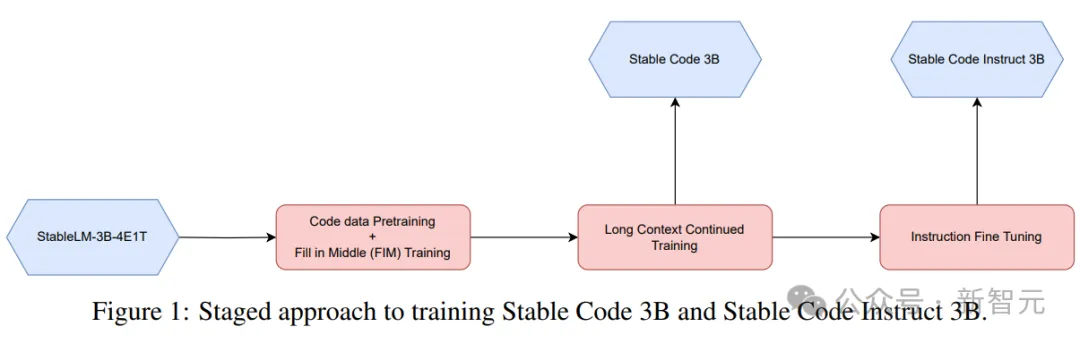 図
図
上の図に示すように、ここでは段階的なトレーニング方法が使用されます。
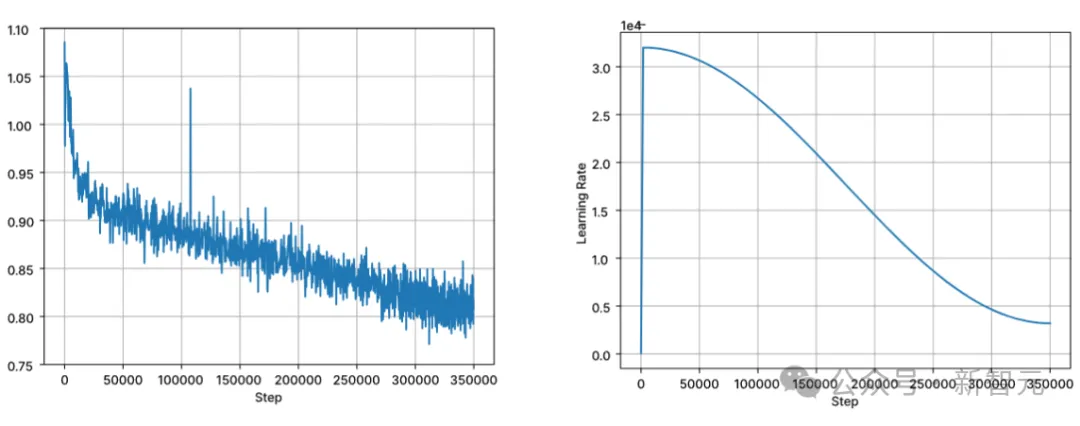
トレーニングは、標準の自己回帰シーケンス モデリングに従って次のトークンを予測します。モデルは Stable LM 3B のチェックポイントを使用して初期化され、トレーニングの最初の段階のコンテキスト長は 4096 で、その後継続的な事前トレーニングが実行されます。
トレーニングは BFloat16 混合精度で実行され、FP32 は all-reduce に使用されます。 AdamW オプティマイザ設定は、β1=0.9、β2=0.95、ε=1e−6、λ (重み減衰)=0.1 です。学習率 = 3.2e-4 から開始し、最小学習率を 3.2e-5 に設定し、コサイン減衰を使用します。
 図
図
自然言語モデルのトレーニングの中核となる前提の 1 つは、左から右への因果的順序ですが、これはコードの場合です。たとえば、この仮定は常に成り立つわけではありません (たとえば、多くの関数では、関数呼び出しと関数宣言は任意の順序で実行できます)。
この問題を解決するために、研究者たちは FIM (fill-in-the-middle) を使用しました。文書をランダムにプレフィックス、中間、サフィックスの 3 つのセグメントに分割し、中央のセグメントを文書の末尾に移動します。再配置後、同じ自己回帰トレーニング プロセスが続きます。
命令の微調整
事前トレーニングの後、作成者は、次のような微調整段階を通じてモデルの対話スキルをさらに向上させます。教師あり微調整 (SFT) と直接優先最適化 (DPO)。
まず、Hugging Face で公開されているデータセット (OpenHermes、Code Feedback、CodeAlpaca など) を使用して SFT 微調整を実行します。
完全一致重複排除を実行すると、3 つのデータセットから合計約 500,000 のトレーニング サンプルが提供されます。
コサイン学習率スケジューラを使用してトレーニング プロセスを制御し、グローバル バッチ サイズを 512 に設定して、入力を長さ 4096 を超えないシーケンスにパックします。
SFT の後、DPO フェーズが開始され、UltraFeedback からのデータを使用して、約 7,000 のサンプルを含むデータセットがキュレーションされます。さらに、モデルのセキュリティを向上させるために、著者は有益で無害な RLFH データセットも含めました。
研究者らは、最適化アルゴリズムとして RMSProp を採用し、DPO トレーニングの初期段階で学習率をピークの 5e-7 に高めました。
パフォーマンス テスト
以下では、マルチ PL ベンチマークを使用してモデルを評価し、コード補完タスクでのモデルのパフォーマンスを比較します。 。
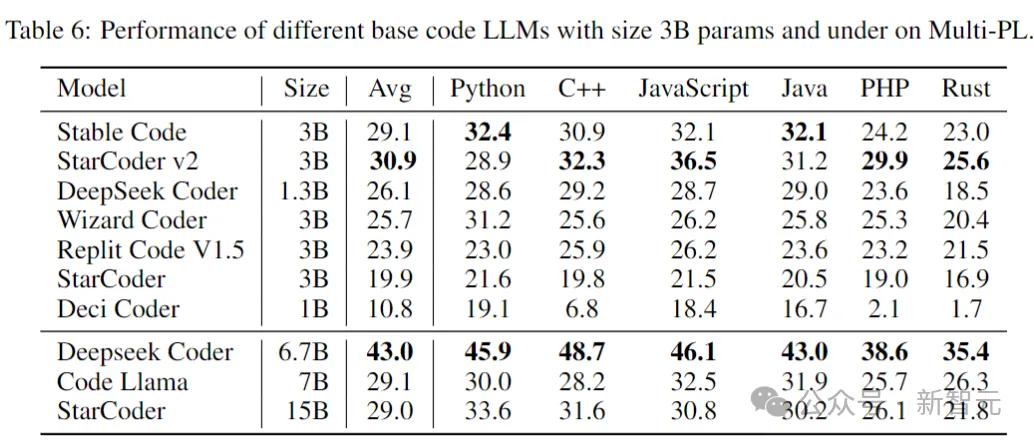
安定したコード ベース
次の表は、マルチ PL パフォーマンスに関する 3B パラメータ以下のサイズを示しています。異なるコードモデル。
 写真
写真
安定版コードのパラメーターは、Code Llama および StarCoder 15B のパラメーターの 40% および 20% 未満ですが、 、それぞれ、プログラミング言語全体のモデルの平均パフォーマンスはそれらと同等です。
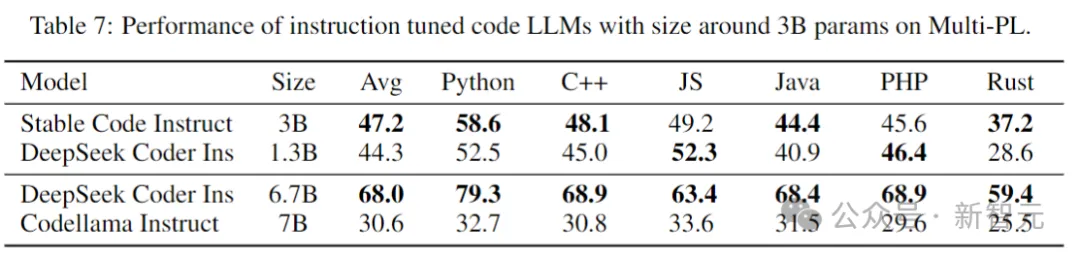
安定したコード命令
次の表は、Multi-PL ベンチマーク テスト Fine でのいくつかのモデルの命令を評価したものです。 -チューンバージョン。
 図
図
SQL パフォーマンス
コード言語モデルの重要なアプリケーションは、データベース クエリ タスクです。この分野では、Stable Code Instruct のパフォーマンスが、他の一般的な命令調整モデルや SQL 専用にトレーニングされたモデルと比較されます。ここでは Defog AI を使用して作成されたベンチマーク。
 図
図
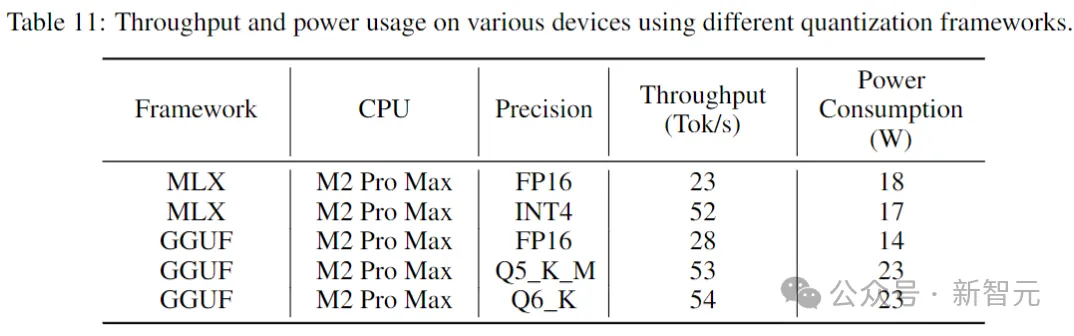
推論パフォーマンス
下の表コンシューマーグレードのデバイスおよび対応するシステム環境で安定したコードを実行するときのスループットと消費電力が示されています。
 写真
写真
結果は、より低い精度を使用すると、スループットがほぼ 2 倍増加することを示しています。ただし、低精度の量子化を実装すると、モデルのパフォーマンスがある程度 (潜在的に大幅に) 低下する可能性があることに注意することが重要です。
#参考:https://www.php.cn/link/8cb3522da182ff9ea5925bbd8975b203
# #以上が社長が辞めてから初投稿です!安定性公式コードモデル Stable Code Instruct 3Bの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

人気の記事


人気の記事

ホットな記事タグ

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7291
7291
 9
1622
14
1342
46
1259
25
1206
29
9
1622
14
1342
46
1259
25
1206
29

 2009 年から 2025 年の誕生以来のビットコインの価格 BTC 過去の価格の最も完全な概要
Jan 15, 2025 pm 08:11 PM
2009 年から 2025 年の誕生以来のビットコインの価格 BTC 過去の価格の最も完全な概要
Jan 15, 2025 pm 08:11 PM
2009 年から 2025 年の誕生以来のビットコインの価格 BTC 過去の価格の最も完全な概要
 OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
 清華大学と Zhipu AI オープンソース GLM-4: 自然言語処理に新たな革命を起こす
Jun 12, 2024 pm 08:38 PM
清華大学と Zhipu AI オープンソース GLM-4: 自然言語処理に新たな革命を起こす
Jun 12, 2024 pm 08:38 PM
清華大学と Zhipu AI オープンソース GLM-4: 自然言語処理に新たな革命を起こす
 世界のトップ10の仮想通貨取引プラットフォームのトップ10のランキングは何ですか?
Feb 20, 2025 pm 02:15 PM
世界のトップ10の仮想通貨取引プラットフォームのトップ10のランキングは何ですか?
Feb 20, 2025 pm 02:15 PM
世界のトップ10の仮想通貨取引プラットフォームのトップ10のランキングは何ですか?

 Google Gemini 1.5 テクニカル レポート: 数学オリンピックの問題を簡単に証明、Flash バージョンは GPT-4 Turbo より 5 倍高速
Jun 13, 2024 pm 01:52 PM
Google Gemini 1.5 テクニカル レポート: 数学オリンピックの問題を簡単に証明、Flash バージョンは GPT-4 Turbo より 5 倍高速
Jun 13, 2024 pm 01:52 PM
Google Gemini 1.5 テクニカル レポート: 数学オリンピックの問題を簡単に証明、Flash バージョンは GPT-4 Turbo より 5 倍高速
 砲撃スキャンダルにスタンフォードAI研究所所長激怒!盗作チームの 2 人のメンバーが責任を負い、1 人が失踪し、彼の犯罪歴が暴露されました。ネチズン: 中国のオープンソース モデルを再理解する。
Jun 09, 2024 am 09:38 AM
砲撃スキャンダルにスタンフォードAI研究所所長激怒!盗作チームの 2 人のメンバーが責任を負い、1 人が失踪し、彼の犯罪歴が暴露されました。ネチズン: 中国のオープンソース モデルを再理解する。
Jun 09, 2024 am 09:38 AM
砲撃スキャンダルにスタンフォードAI研究所所長激怒!盗作チームの 2 人のメンバーが責任を負い、1 人が失踪し、彼の犯罪歴が暴露されました。ネチズン: 中国のオープンソース モデルを再理解する。

