

ビデオポーズTransformerを高速化するために、北京大学が効率的な3D人間姿勢推定フレームワークHoTを提案

現在、Video Pose Transformer (VPT) は、ビデオベースの 3 次元人物姿勢推定の分野で最高のパフォーマンスを達成しています。近年、これらの VPT の計算負荷はますます大きくなり、これらの膨大な計算負荷により、この分野のさらなる開発も制限されています。コンピューティングリソースが不十分な研究者にとっては非常に不親切です。たとえば、243 フレームの VPT モデルのトレーニングには通常数日かかり、研究の進行が大幅に遅くなり、この分野では早急に解決する必要がある大きな問題点となっています。
では、精度をほとんど損なうことなく、VPT の効率を効果的に向上させるにはどうすればよいでしょうか?
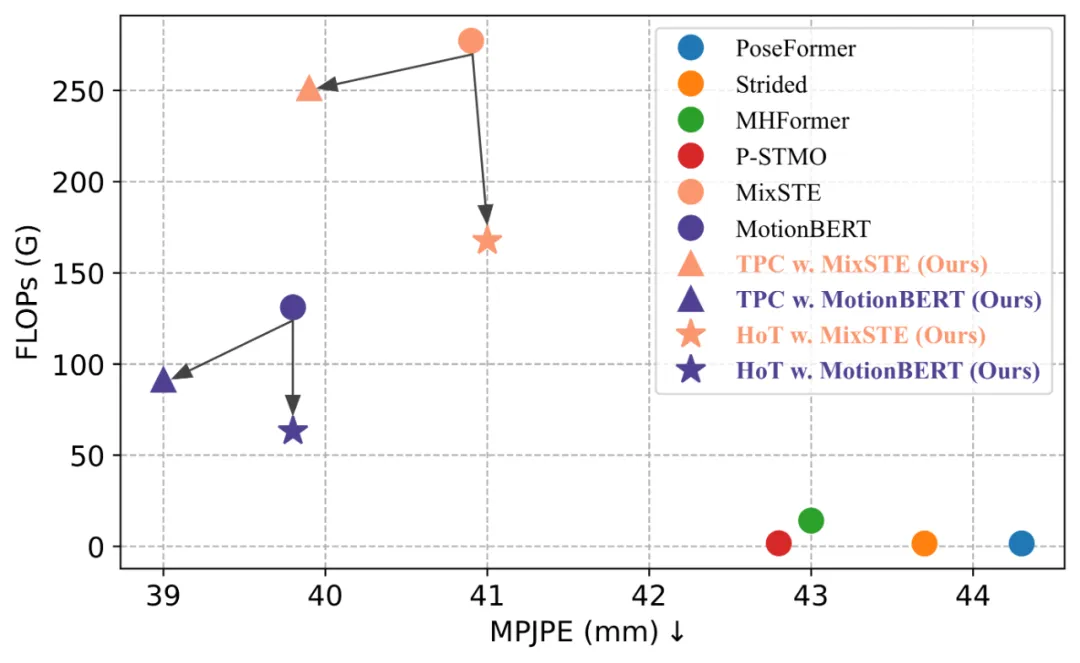
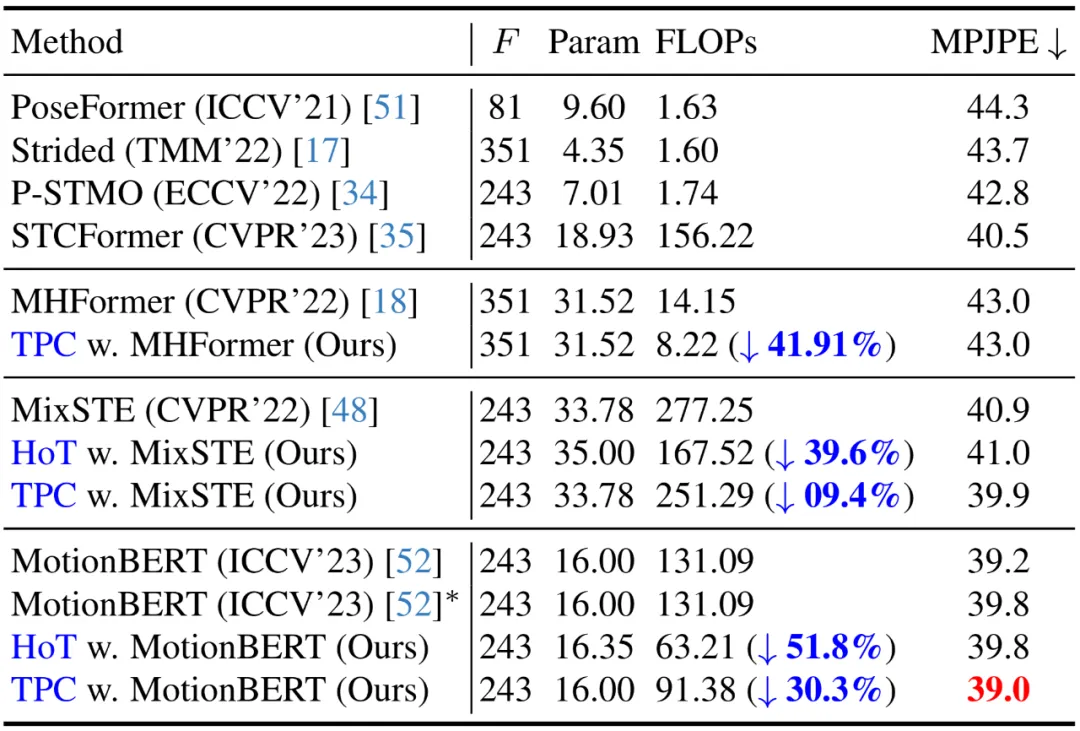
北京大学のチームは、既存の Video Pose Transformer (VPT) の高い計算コストを解決するために、Hourglass Tokenizer に基づいた効率的な 3 次元の人間の姿勢推定フレームワーク HoT を提案しました。需要の。このフレームワークはプラグ アンド プレイで、MHFormer、MixSTE、MotionBERT などのモデルにシームレスに統合でき、精度を損なうことなくモデルの計算を 40% 近く削減できます。コードはオープンソース化されています。

- タイトル: トランスフォーマーベースの効率的な 3D 人間の姿勢推定のための砂時計トークナイザー
- ペーパーアドレス: https://arxiv.org/abs/2311.12028
- コードアドレス: https://github.com/NationalGAILab/HoT


VPT モデルでは、通常、ビデオの各フレームが独立したポーズ トークンに処理されます。数百のフレームを処理することで、ビデオ シーケンス (通常は 243 ~ 351 フレーム) を使用して、優れたパフォーマンスを実現し、Transformer のすべてのレイヤーにわたって全長シーケンス表現を維持します。ただし、VPT のセルフ アテンション メカニズムの計算の複雑さはトークンの数 (つまり、ビデオ フレームの数) の 2 乗に比例するため、これらのモデルは、より高い時系列解像度でビデオ入力を処理する場合、必然的に大幅な非効率をもたらします。計算オーバーヘッドにより、限られたコンピューティング リソースで実際のアプリケーションに広く導入することが困難になります。さらに、シーケンス全体を処理するこの方法では、ビデオ シーケンス内の冗長性、特に視覚的な変化が明らかではない連続フレーム間の冗長性が考慮されていないため、この情報の重複は不必要な計算負荷を追加するだけでなく、モデルのパフォーマンスの向上にはほとんど貢献しません。
したがって、効率的な VPT を達成するには、この記事では 2 つの要素を最初に考慮する必要があると考えています。
- 時間知覚フィールドは大きくなければなりません : 入力シーケンスの長さを直接短縮すると VPT の効率を向上させることができますが、そうすることでモデルの時間的受容野が減少し、それによってモデルが豊富な時空間情報を捕捉することが制限され、パフォーマンスの向上が制限されます。したがって、効率的な設計戦略を追求する場合、正確な推定を達成するには、大きな時間的受容野を維持することが重要です。
-
ビデオの冗長性を削除する必要があります: 隣接するフレーム間のアクションが類似しているため、ビデオには大量の冗長な情報が含まれることがよくあります。 。さらに、既存の研究では、Transformer アーキテクチャでは、層が深くなるにつれて、トークン間の差異がますます小さくなることが指摘されています。したがって、Transformer の深い層で全長ポーズ トークンを使用すると、不必要な冗長な計算が導入され、これらの冗長な計算が最終的な推定結果に与える影響は限定的になると推測できます。
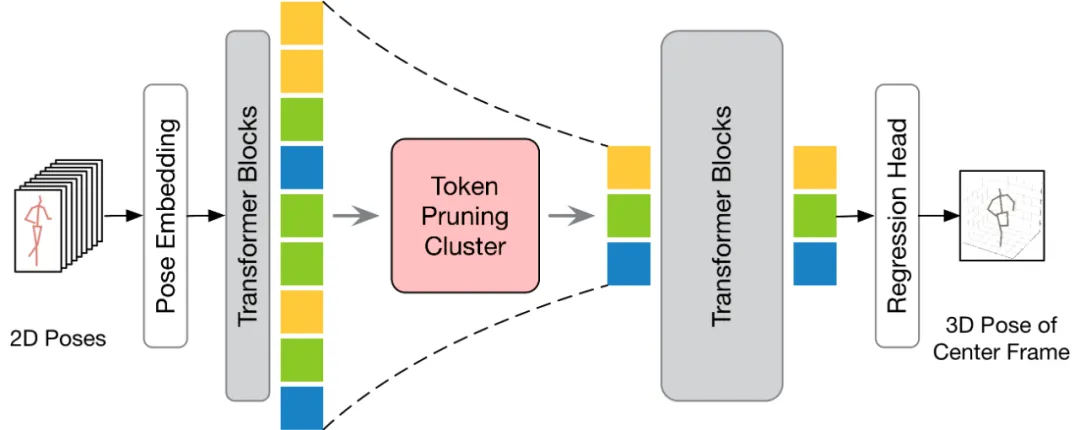
上記の 3 つの考慮事項に基づいて、著者は、砂時計構造に基づく効率的な 3 次元人間の姿勢推定フレームワーク、⏳ Hourglass Tokenizer (HoT) を提案します。一般に、この方法には 2 つの大きな特徴があります。 #HoT は、効率的な 3D 人間の姿勢推定のための初の Transformer ベースのプラグアンドプレイ フレームワークです。以下の図に示すように、従来の VPT は「長方形」パラダイムを採用しています。つまり、モデルのすべての層でポーズ トークンの全長を維持するため、高い計算コストと機能の冗長性が生じます。従来の VPT とは異なり、HoT は最初にプルーニングして冗長なトークンを削除し、次にトークンのシーケンス全体 (「砂時計」のように見える) を復元するため、トランスフォーマーの中間層には少量のトークンのみが保持され、効果的にモデルの効率が向上します。また、HoT は非常に高い汎用性を示しており、seq2seq ベースの VPT や seq2frame ベースの VPT など、従来の VPT モデルにシームレスに統合できるだけでなく、さまざまなトークンプルーニングやリカバリ戦略にも適応できます。 HoT は、全長のポーズ シーケンスを維持するのは冗長であり、少数の代表フレームのポーズ トークンを使用することで高効率と高性能の両方を達成できることを明らかにしました。従来の VPT モデルと比較して、HoT は処理効率を大幅に向上させるだけでなく、非常に競争力の高い、またはそれ以上の結果を達成します。たとえば、パフォーマンスを犠牲にすることなく MotionBERT の FLOP を 50% 近く削減できますが、MixSTE の FLOP は 0.2% というわずかなパフォーマンスの低下で 40% 近く削減できます。
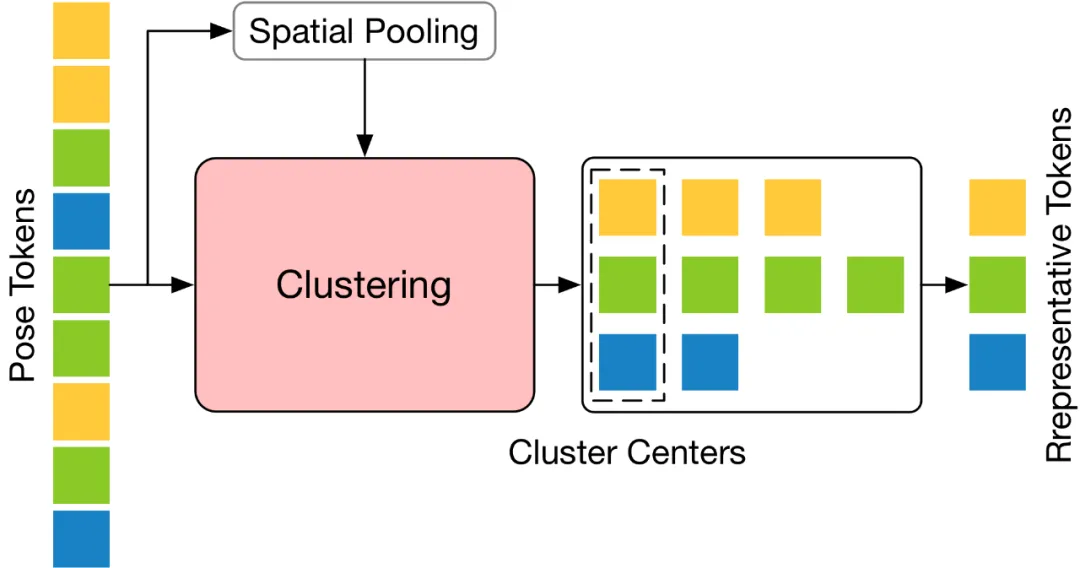
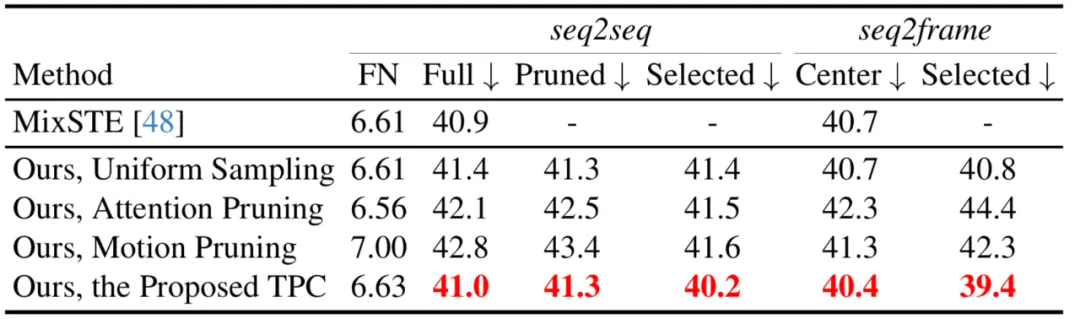
この記事では、人間の 3 次元姿勢を正確に推定するために、豊富な情報を持つ少数のポーズ トークンを選択することは困難な問題であると考えています。 この問題を解決するために、この記事では、意味論的多様性の高い代表的なトークンを選択することが重要であると考えています。なぜなら、そのようなトークンはビデオの冗長性を減らしながら必要な情報を保持できるからです。この概念に基づいて、この記事では、シンプルかつ効果的で追加のパラメーターを必要としないトークン プルーニング クラスター (TPC) モジュールを提案します。このモジュールの核心は、意味論的にほとんど寄与しないトークンを特定して削除し、最終的な 3 次元の人間の姿勢推定に重要な情報を提供できるトークンに焦点を当てることです。 TPC はクラスタリング アルゴリズムを使用して、クラスタ センターを代表トークンとして動的に選択し、それによってクラスタ センターの特性を利用して元のデータの豊富なセマンティクスを保持します。 TPC の構造は下図のとおりで、入力された Pose Token を空間次元でプールし、プールした Token の特徴類似度を利用して処理を行います。入力トークンをクラスター化して、クラスターの中心を代表トークンとして選択します。
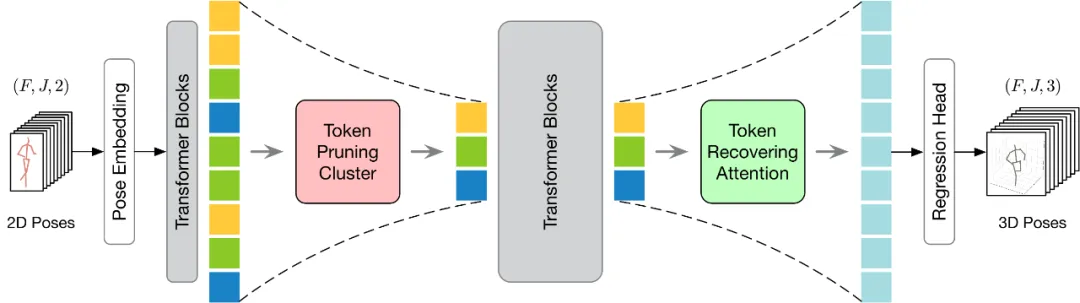
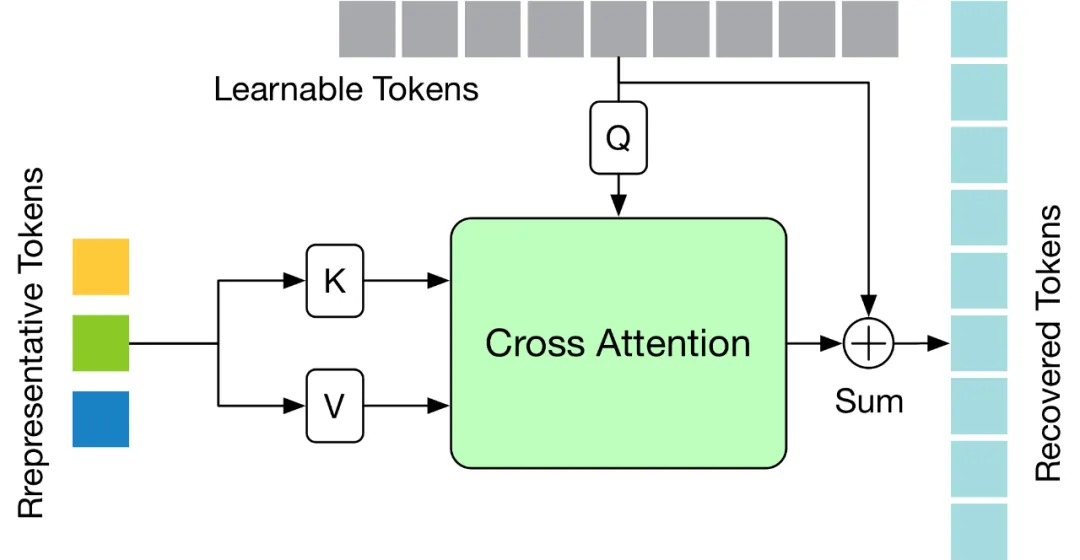
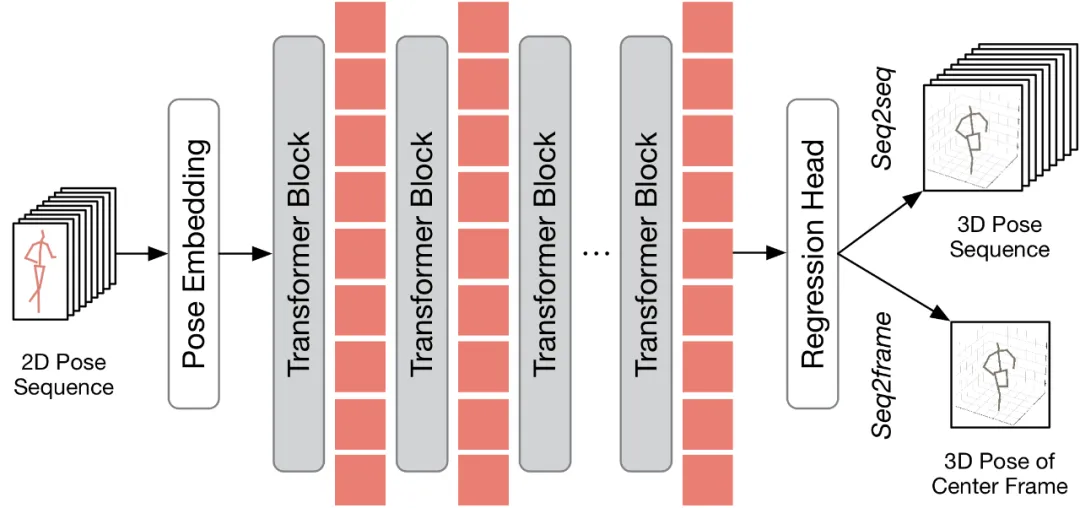
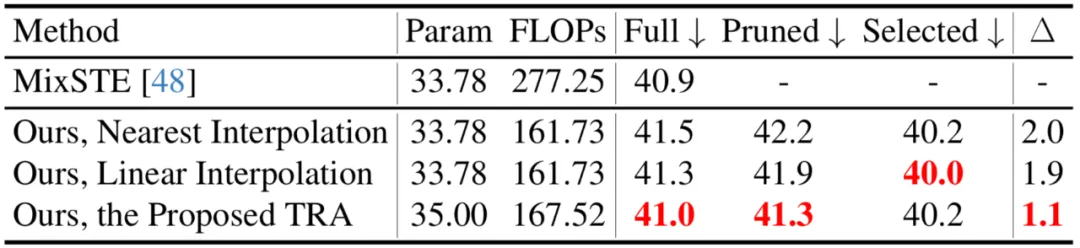
TPC モジュールはポーズ トークンの数を効果的に削減しますが、プルーニング操作による時間分解能の低下により、高速 seq2seq 推論のための VPT が制限されます。したがって、トークンを復元する必要があります。同時に、効率係数を考慮して、モデル全体の計算コストへの影響を最小限に抑えるために、回復モジュールは軽量になるように設計する必要があります。 上記の課題を解決するために、この記事では、選択されたトークンに基づいて詳細な時空間情報を回復できる軽量のトークン回復アテンション (TRA) モジュールを設計します。このようにして、枝刈り操作によって引き起こされる低い時間解像度が、元の完全なシーケンスの時間解像度まで効果的に拡張され、ネットワークがすべてのフレームの 3 次元の人間のポーズ シーケンスを一度に推定できるようになり、高速な seq2seq 推論が実現します。 TRA モジュールの構造は次の図に示されており、Transformer の最後の層にある代表的なトークンと、単純なクロスアテンションを通じてゼロに初期化された学習可能なトークンを使用します。完全なトークン シーケンスを復元します。 既存の VPT に適用する すべてを適用する方法について説明します 適用する前に提案手法を既存の VPT に適用するために、本稿ではまず既存の VPT アーキテクチャを要約します。以下の図に示すように、VPT アーキテクチャは主に 3 つのコンポーネントで構成されます。ポーズ シーケンスの時空間情報をエンコードするポーズ埋め込みモジュール、グローバルな時空間表現を学習するための多層トランスフォーマー、回帰のための回帰ヘッド モジュールです。 3D 人間の姿勢結果を出力します。
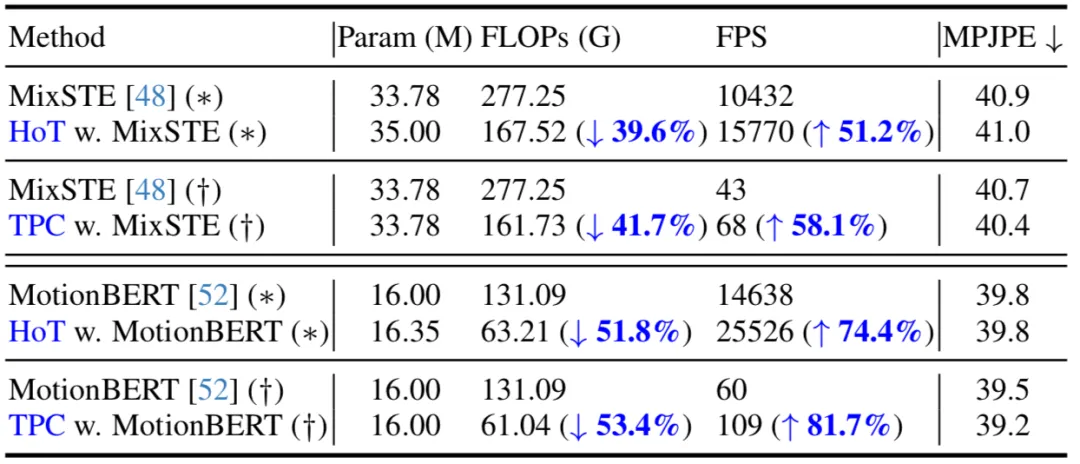
#以下の表では、この記事では seq2seq (*) と seq2frame (†) の推論プロセスでの比較を示しています。その結果、提案手法を既存の VPT に適用することで、モデルパラメータの数をほとんど変えずに FLOP を大幅に削減し、FPS を大幅に向上できることがわかりました。さらに、提案手法は元のモデルと比較して、基本的に性能が同じか、より優れた性能を達成できます。
この記事では、注意スコアの枝刈り、均一サンプリング、モーションのより大きな上位 k 個のトークンの選択など、さまざまなトークン枝刈り戦略も比較しています。モーション トークンの枝刈り戦略から、提案された TPC が最高のパフォーマンスを達成していることがわかります。
この記事では、最近傍補間や線形補間など、さまざまなトークン回復戦略も比較しています。提案された TRA が最高のパフォーマンスを達成していることがわかります。 。
#SOTA 方式との比較 現在Human3.6M データセットでは、3D 人間の姿勢推定の主要な方法はすべて、Transformer ベースのアーキテクチャを採用しています。この手法の有効性を検証するために、著者らはこの手法を 3 つの最新の VPT モデル (MHForme、MixSTE、MotionBERT) に適用し、パラメータ量、FLOP、MPJPE の観点から比較しました。 以下の表に示すように、この方法では、元の精度を維持しながら、SOTA VPT モデルの計算量が大幅に削減されます。これらの結果は、この方法の有効性と高効率を検証するだけでなく、既存の VPT モデルには計算の冗長性があり、これらの冗長性が最終的な推定パフォーマンスにほとんど寄与せず、パフォーマンスの低下につながる可能性があることも明らかにしています。さらに、この方法では、これらの不必要な計算を排除しながら、非常に競争力の高い、またはさらに優れたパフォーマンスを実現できます。 作者はデモ操作も提供しています (https://github.com/ NationalGAILab/HoT)、YOLOv3 人間検出器、HRNet 2D ポーズ検出器、HoT と MixSTE 2D から 3D ポーズ エンハンサーを統合します。著者が提供する事前トレーニング済みモデルをダウンロードし、人物が含まれる短いビデオを入力するだけで、1 行のコードで 3D 人間の姿勢推定のデモを直接出力できます。 サンプル ビデオを実行して得られた結果: #この記事では、既存のビデオ ポーズ変換 (VPT) の高い計算コストの問題を解決するための、プラグ アンド プレイのトークン プルーニングである Hourglass Tokenizer (HoT) と、その回復フレームワークを提案します。 Transformer ベースのビデオからの効率的な 3D 人間の姿勢推定。この研究では、VPT で全長のポーズ シーケンスを維持する必要がなく、少数の代表フレームのポーズ トークンを使用することで高い精度と効率の両方を達成できることがわかりました。多数の実験により、この方法の高い互換性と幅広い適用可能性が検証されています。 seq2seq ベースの VPT であっても seq2frame ベースの VPT であっても、さまざまな一般的な VPT モデルに簡単に統合でき、さまざまなトークン プルーニングおよび回復戦略に効果的に適応でき、その大きな可能性を実証します。著者らは、HoT がより強力で高速な VPT の開発を推進すると期待しています。 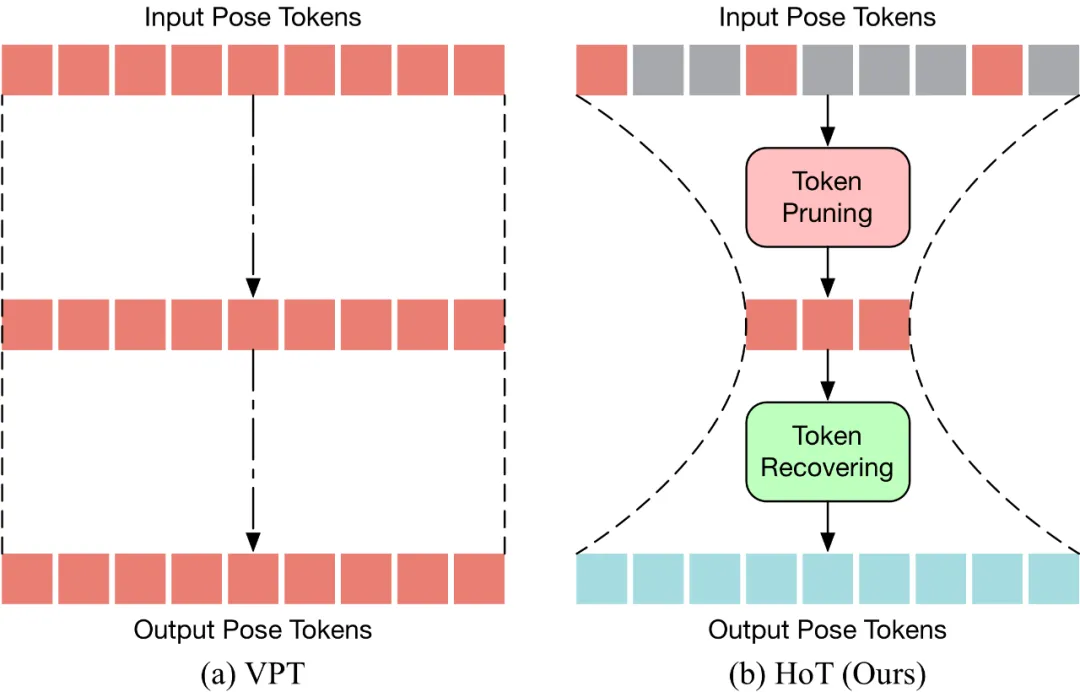
提案する HoT の全体的な枠組みを以下の図に示します。トークン プルーニングと回復をより効果的に実行するために、この記事では、トークン プルーニング クラスター (TPC) とトークン リカバリ アテンション (TRA) という 2 つのモジュールを提案します。その中で、TPC モジュールは、ビデオ フレームの冗長性を軽減しながら、セマンティック多様性の高い少数の代表的なトークンを動的に選択します。 TRA モジュールは、選択されたトークンに基づいて詳細な時空間情報を復元し、それによってネットワーク出力を元の全長の時間解像度に拡張して、高速推論を実現します。
 #実験結果
#実験結果
##アブレーション実験
コード操作
python demo/vis.py --video sample_video.mp4

概要
以上がビデオポーズTransformerを高速化するために、北京大学が効率的な3D人間姿勢推定フレームワークHoTを提案の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7469
7469
 15
1376
52
77
11
19
29
15
1376
52
77
11
19
29

 Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
700万のレコードを効率的に処理し、地理空間技術を使用したインタラクティブマップを作成します。この記事では、LaravelとMySQLを使用して700万を超えるレコードを効率的に処理し、それらをインタラクティブなマップの視覚化に変換する方法について説明します。最初の課題プロジェクトの要件:MySQLデータベースに700万のレコードを使用して貴重な洞察を抽出します。多くの人は最初に言語をプログラミングすることを検討しますが、データベース自体を無視します。ニーズを満たすことができますか?データ移行または構造調整は必要ですか? MySQLはこのような大きなデータ負荷に耐えることができますか?予備分析:キーフィルターとプロパティを特定する必要があります。分析後、ソリューションに関連している属性はわずかであることがわかりました。フィルターの実現可能性を確認し、検索を最適化するためにいくつかの制限を設定しました。都市に基づくマップ検索
 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
MySQLはJSONデータを返すことができます。 json_extract関数はフィールド値を抽出します。複雑なクエリについては、Where句を使用してJSONデータをフィルタリングすることを検討できますが、そのパフォーマンスへの影響に注意してください。 JSONに対するMySQLのサポートは絶えず増加しており、最新バージョンと機能に注意を払うことをお勧めします。
 リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニアの求人事業者:サークル場所:リモートオフィスジョブタイプ:フルタイム給与:$ 130,000- $ 140,000職務記述書サークルモバイルアプリケーションとパブリックAPI関連機能の研究開発に参加します。ソフトウェア開発ライフサイクル全体をカバーします。主な責任は、RubyonRailsに基づいて独立して開発作業を完了し、React/Redux/Relay Front-Endチームと協力しています。 Webアプリケーションのコア機能と改善を構築し、機能設計プロセス全体でデザイナーとリーダーシップと緊密に連携します。肯定的な開発プロセスを促進し、反復速度を優先します。 6年以上の複雑なWebアプリケーションバックエンドが必要です
 酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
データベース酸属性の詳細な説明酸属性は、データベーストランザクションの信頼性と一貫性を確保するための一連のルールです。データベースシステムがトランザクションを処理する方法を定義し、システムのクラッシュ、停電、または複数のユーザーの同時アクセスの場合でも、データの整合性と精度を確保します。酸属性の概要原子性:トランザクションは不可分な単位と見なされます。どの部分も失敗し、トランザクション全体がロールバックされ、データベースは変更を保持しません。たとえば、銀行の譲渡が1つのアカウントから控除されているが別のアカウントに増加しない場合、操作全体が取り消されます。 TRANSACTION; updateaccountssetbalance = balance-100wh
 MySQLはダウンロード後にインストールできません
Apr 08, 2025 am 11:24 AM
MySQLはダウンロード後にインストールできません
Apr 08, 2025 am 11:24 AM
MySQLのインストール障害の主な理由は次のとおりです。1。許可の問題、管理者として実行するか、SUDOコマンドを使用する必要があります。 2。依存関係が欠落しており、関連する開発パッケージをインストールする必要があります。 3.ポート競合では、ポート3306を占めるプログラムを閉じるか、構成ファイルを変更する必要があります。 4.インストールパッケージが破損しているため、整合性をダウンロードして検証する必要があります。 5.環境変数は誤って構成されており、環境変数はオペレーティングシステムに従って正しく構成する必要があります。これらの問題を解決し、各ステップを慎重に確認して、MySQLを正常にインストールします。
 MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLプライマリキーは、データベース内の各行を一意に識別するキー属性であるため、空にすることはできません。主キーが空になる可能性がある場合、レコードを一意に識別することはできません。これにより、データの混乱が発生します。一次キーとして自己挿入整数列またはUUIDを使用する場合、効率やスペース占有などの要因を考慮し、適切なソリューションを選択する必要があります。
