

3D ビジョンには点群の登録が不可欠です。すべての主流のソリューションと課題を 1 つの記事で理解する

点の集合としての点群は、3D 再構成、工業用検査、ロボット操作などを通じて、物体の 3 次元 (3D) 表面情報の取得と生成に変化をもたらすことが期待されています。最も困難だが重要なプロセスは、点群の登録です。つまり、2 つの異なる座標で取得された 2 つの点群を位置合わせして一致させる空間変換を取得します。このレビューは、点群登録の概要と基本原理を紹介し、さまざまな方法を体系的に分類して比較し、点群登録に存在する技術的問題を解決することで、分野外の学術研究者やエンジニアに指導を提供し、統一されたビジョンに関する議論を促進することを目的としています。点群登録用。
点群取得の一般的な方法は、アクティブ方式とパッシブ方式に分かれており、センサーが能動的に点群を取得するのがアクティブ方式、点群を再構成する方式です。後の段階ではパッシブな方法です。
SFM から MVS への高密度再構築。 (a) SFM。 (b) SfM によって生成された点群の例。 (c) PMVS アルゴリズムのフローチャート、パッチベースのマルチビュー ステレオ アルゴリズム。 (d) PMVS によって生成された高密度点群の例。 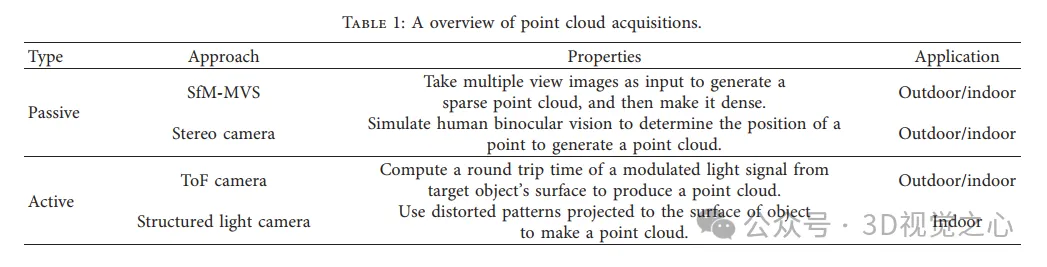
 #環境では、変換は回転と平行移動に分解できます。適切な剛体変換の後、同じ形状とサイズを維持したまま、1 つの点群が別の点群にマッピングされます。
#環境では、変換は回転と平行移動に分解できます。適切な剛体変換の後、同じ形状とサイズを維持したまま、1 つの点群が別の点群にマッピングされます。
非剛体レジストレーションでは、スキャンされたデータをターゲット点群にラップするために非剛体変換が確立されます。非剛体変換には、剛体位置合わせの移動と回転のみとは対照的に、反射、回転、スケーリング、および平行移動が含まれます。非剛体レジストレーションは 2 つの主な理由で使用されます: (1) データ収集およびキャリブレーション誤差の非線形性により、剛体のスキャンで低周波歪みが発生する可能性がある; (2) レジストレーションは、形状が変化して移動するシーンまたはオブジェクトに対して実行されます。時間 。
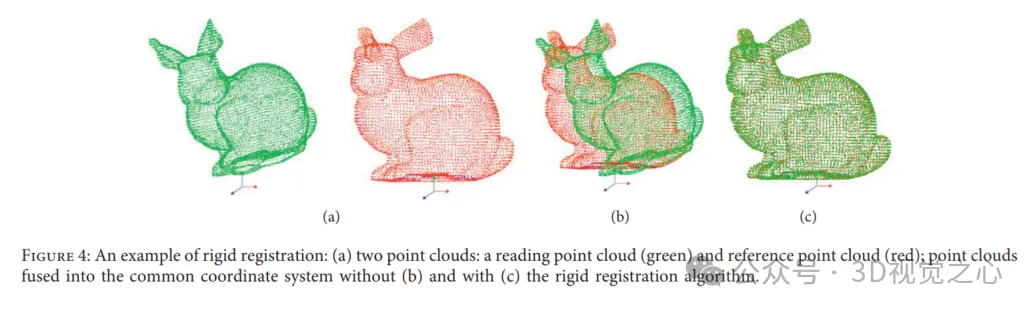
厳格な登録の例: (a) 2 つの点群: 読み取り点群 (緑) と参照点群 (赤); (b) なしと (c) を使用点群が共通の座標系に融合される、厳格な登録アルゴリズム。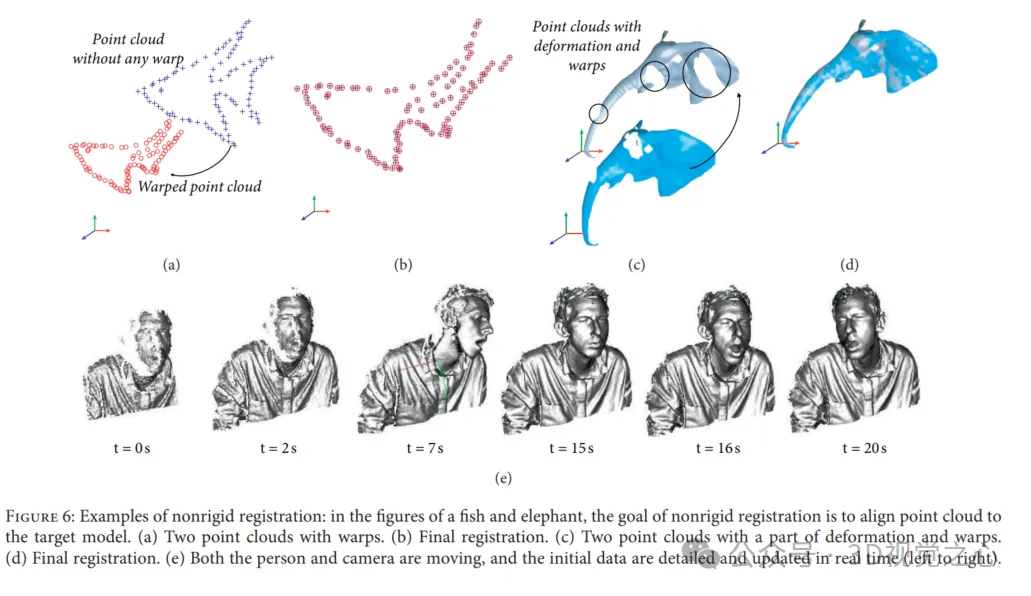
#ただし、点群登録のパフォーマンスは、バリアント オーバーラップ、ノイズと外れ値、高い計算コスト、および登録の成功を示すさまざまな指標によって制限されます。
 登録方法にはどのようなものがありますか?
登録方法にはどのようなものがありますか? 
過去数十年にわたり、古典的な ICP アルゴリズムから深層学習テクノロジーと組み合わせたソリューションに至るまで、ますます多くの点群登録方法が提案されてきました。
1) ICP スキーム
ICP アルゴリズムは、理想的な条件下での位置合わせの精度、収束速度、安定性を保証できる反復アルゴリズムです。ある意味では、ICP は期待値最大化 (EM) 問題とみなすことができるため、対応関係に基づいて新しい変換を計算して更新し、エラー メトリックが収束するまで読み取りデータに適用されます。ただし、これは ICP が大域最適に達することを保証するものではなく、ICP アルゴリズムは、下図に示すように、ポイント選択、ポイント マッチング、ポイント拒否、エラー メトリック最小化の 4 つのステップに大別できます。
2) 特徴ベースの方法
ICP ベースのアルゴリズムで見てきたように、推定を変換する前に対応関係を確立することが重要です。 2 つの点群間の正しい関係を記述する適切な対応関係が得られれば、最終結果が保証されます。したがって、スキャンされたターゲットにランドマークを貼り付けるか、後処理で同等の点のペアを手動で選択して、関心のある点 (選択された点) の変換を計算し、最終的に点群の読み取りに適用できます。図 12(c) に示すように、点群は同じ座標系にロードされ、異なる色で描画されます。図 12(a) と図 12(b) は、異なる視点で撮影された 2 つの点群を示し、それぞれ参照データと読み取りデータから点ペアが選択され、位置合わせ結果が図 12(d) に示されています。しかし、これらの方法はランドマークを付けることができない測定対象物には適しておらず、自動登録が必要なアプリケーションには適用できません。同時に、対応関係の検索空間を最小限に抑え、ICP ベースのアルゴリズムでの初期変換の想定を回避するために、研究者によって設計されたキー ポイントが抽出される特徴ベースの登録が導入されます。通常、キーポイントの検出と対応関係の確立がこの方法の主なステップです。

キー ポイント抽出の一般的な方法には、PFH、SHOT などが含まれます。外れ値を除去し、内値に基づいて変換を効果的に推定するアルゴリズムを設計することも重要です。
3) 学習ベースの方法
点群を入力として使用するアプリケーションでは、特徴記述子を推定するための従来の戦略は点に大きく依存します。雲。ただし、実際のデータはターゲット固有であることが多く、平面、外れ値、ノイズが含まれる場合があります。さらに、除去された不一致には、学習に使用できる有用な情報が含まれていることがよくあります。学習ベースの技術は、セマンティック情報をエンコードするために適用でき、特定のタスクにわたって一般化できます。機械学習技術と統合されたほとんどの登録戦略は、従来の方法よりも高速かつ堅牢であり、物体の姿勢推定や物体分類などの他のタスクにも柔軟に拡張できます。同様に、学習ベースの点群登録における重要な課題は、点群の空間変動に対して不変で、ノイズや外れ値に対してより堅牢な特徴を抽出する方法です。
学習ベースの手法の代表的なものは、PointNet、PointNet、PCRNet、Deep Global Registration、Deep Closest Point、Partial Registration Network、Robust Point Matching、PointNetLK、3DRegNet です。
4) 確率密度関数を用いた方法
確率密度関数に基づく点群登録 (PDF) は、登録に統計モデルを使用する研究成果です。素晴らしい質問です。この方法の重要なアイデアは、混合ガウス モデル (GMM) や正規分布 (ND) などの特定の確率密度関数を使用してデータを表すことです。位置合わせタスクは、2 つの対応する分布を位置合わせする問題として再定式化され、その後にそれらの間の統計的差異を測定して最小化する目的関数が続きます。同時に、PDF の表現により、点群は多くの個々の点ではなく分布として見ることができるため、対応関係の推定が回避され、優れた耐ノイズ性能を備えていますが、一般に ICP ベースよりも遅くなります。メソッド。
5) その他の方法
高速グローバル登録。 Fast Global Registration (FGR) は、初期化を行わずに点群を高速に登録する戦略を提供します。具体的には, FGR はカバーされたサーフェスの候補一致に基づいて動作し, 対応関係の更新や最近接点のクエリは実行しません. このアプローチの特別な点は, サーフェス上に密に定義されたロバストな目的の 1 回の最適化によって直接生成できることです.登録。ただし、点群の位置合わせを解決するための既存の方法では、通常、2 つの点群間の対応関係の候補または複数が生成され、全体的な結果が計算されて更新されます。さらに、高速グローバル登録では、対応関係は最適化ですぐに確立され、次のステップで再度推定されることはありません。したがって、計算コストを低く抑えるために、高価な最近傍検索は回避されます。その結果、反復ステップでの各対応に対する線形処理と姿勢推定のための線形システムが効率的になります。 FGR は、UWA ベンチマークや Stanford Bunny などの複数のデータセットで評価され、ポイントツーポイントおよびポイントトップ ICP、および Go ICP などの ICP バリアントと比較されます。実験によると、FGR はノイズが存在する場合でも良好なパフォーマンスを発揮します。
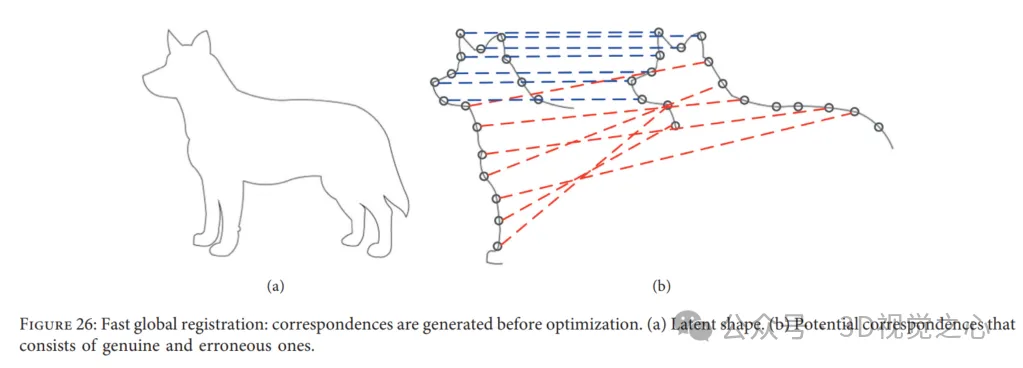
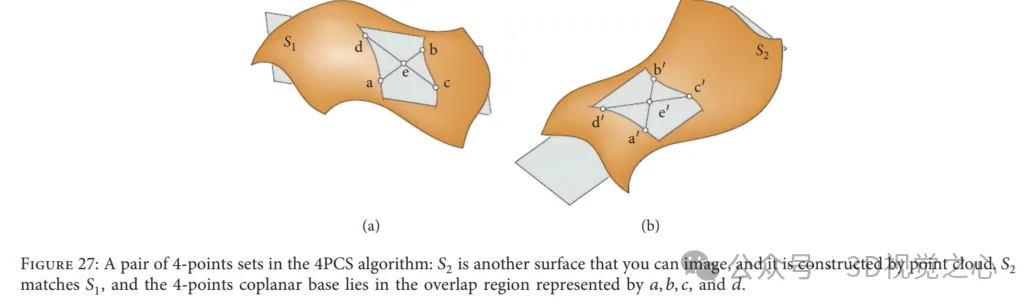
4 点合同集合アルゴリズム: 4 点合同集合 (4PCS) は、開始位置の仮定を必要とせずにデータを読み取るための初期変換を提供します。通常、2 つの点群間の剛体位置合わせ変換は、1 つは参照データから、もう 1 つは読み取りデータからのトリプルのペアによって一意に定義できます。ただし、この方法では、図 27 に示すように、小さなポテンシャル セット、つまり各点群内の 4 つの同一平面上の合同点を検索することによって、特別な 4 点の基底を探します。最大共通点集合 (LCP) 問題における最適な剛体変換を解きます。このアルゴリズムは、ペアになった点群の重なりが低く、外れ値が存在する場合にほぼ同等のパフォーマンスを実現します。さまざまなアプリケーションに適応するために、多くの研究者が古典的な 4PCS ソリューションに関連するより重要な研究を導入してきました。
以上が3D ビジョンには点群の登録が不可欠です。すべての主流のソリューションと課題を 1 つの記事で理解するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7526
7526
 15
1378
52
81
11
21
74
15
1378
52
81
11
21
74

 なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
上記と著者の個人的な理解 3 次元ガウシアンプラッティング (3DGS) は、近年、明示的な放射線フィールドとコンピューター グラフィックスの分野で出現した革新的なテクノロジーです。この革新的な方法は、数百万の 3D ガウスを使用することを特徴とし、主に暗黙的な座標ベースのモデルを使用して空間座標をピクセル値にマッピングする神経放射線場 (NeRF) 方法とは大きく異なります。明示的なシーン表現と微分可能なレンダリング アルゴリズムにより、3DGS はリアルタイム レンダリング機能を保証するだけでなく、前例のないレベルの制御とシーン編集も導入します。これにより、3DGS は、次世代の 3D 再構築と表現にとって大きな変革をもたらす可能性のあるものとして位置付けられます。この目的を達成するために、私たちは 3DGS 分野における最新の開発と懸念について初めて体系的な概要を提供します。
 Microsoft Teams の 3D Fluent 絵文字について学ぶ
Apr 24, 2023 pm 10:28 PM
Microsoft Teams の 3D Fluent 絵文字について学ぶ
Apr 24, 2023 pm 10:28 PM
特に Teams ユーザーの場合は、Microsoft が仕事中心のビデオ会議アプリに 3DFluent 絵文字の新しいバッチを追加したことを覚えておく必要があります。 Microsoft が昨年 Teams と Windows 向けの 3D 絵文字を発表した後、その過程で実際に 1,800 を超える既存の絵文字がプラットフォーム用に更新されました。この大きなアイデアと Teams 用の 3DFluent 絵文字アップデートの開始は、公式ブログ投稿を通じて最初に宣伝されました。 Teams の最新アップデートでアプリに FluentEmojis が追加 Microsoft は、更新された 1,800 個の絵文字を毎日利用できるようになると発表
 カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
0.前面に書かれています&& 自動運転システムは、さまざまなセンサー (カメラ、ライダー、レーダーなど) を使用して周囲の環境を認識し、アルゴリズムとモデルを使用することにより、高度な知覚、意思決定、および制御テクノロジーに依存しているという個人的な理解リアルタイムの分析と意思決定に。これにより、車両は道路標識の認識、他の車両の検出と追跡、歩行者の行動の予測などを行うことで、安全な運行と複雑な交通環境への適応が可能となり、現在広く注目を集めており、将来の交通分野における重要な開発分野と考えられています。 。 1つ。しかし、自動運転を難しくしているのは、周囲で何が起こっているかを車に理解させる方法を見つけることです。これには、自動運転システムの 3 次元物体検出アルゴリズムが、周囲環境にある物体 (位置を含む) を正確に認識し、記述することができる必要があります。
 ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
以前に書きましたが、今日は、深層学習テクノロジーが複雑な環境におけるビジョンベースの SLAM (同時ローカリゼーションとマッピング) のパフォーマンスをどのように向上させることができるかについて説明します。ここでは、深部特徴抽出と深度マッチング手法を組み合わせることで、低照度条件、動的照明、テクスチャの弱い領域、激しいセックスなどの困難なシナリオでの適応を改善するように設計された多用途のハイブリッド ビジュアル SLAM システムを紹介します。当社のシステムは、拡張単眼、ステレオ、単眼慣性、ステレオ慣性構成を含む複数のモードをサポートしています。さらに、他の研究にインスピレーションを与えるために、ビジュアル SLAM と深層学習手法を組み合わせる方法も分析します。公開データセットと自己サンプリングデータに関する広範な実験を通じて、測位精度と追跡堅牢性の点で SL-SLAM の優位性を実証しました。
 CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
上記および筆者の個人的な理解: 現在、自動運転システム全体において、認識モジュールが重要な役割を果たしている。道路を走行する自動運転車は、認識モジュールを通じてのみ正確な認識結果を得ることができる。下流の規制および制御モジュール自動運転システムでは、タイムリーかつ正確な判断と行動決定が行われます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。純粋な視覚に基づく BEV 認識アルゴリズムは、ハードウェア コストが低く導入が容易であるため、業界で好まれており、その出力結果はさまざまな下流タスクに簡単に適用できます。
 Windows 11 のペイント 3D: ダウンロード、インストール、および使用ガイド
Apr 26, 2023 am 11:28 AM
Windows 11 のペイント 3D: ダウンロード、インストール、および使用ガイド
Apr 26, 2023 am 11:28 AM
新しい Windows 11 が開発中であるというゴシップが広まり始めたとき、すべての Microsoft ユーザーは、新しいオペレーティング システムがどのようなもので、何をもたらすのかに興味を持ちました。憶測を経て、Windows 11が登場しました。オペレーティング システムには新しい設計と機能の変更が加えられています。いくつかの追加に加えて、機能の非推奨と削除が行われます。 Windows 11 に存在しない機能の 1 つは Paint3D です。描画、落書き、落書きに適したクラシックなペイントは引き続き提供していますが、3D クリエイターに最適な追加機能を提供する Paint3D は廃止されています。追加機能をお探しの場合は、最高の 3D デザイン ソフトウェアとして Autodesk Maya をお勧めします。のように
 カード1枚で30秒でバーチャル3D嫁をゲット! Text to 3D は、毛穴の詳細が明確な高精度のデジタル ヒューマンを生成し、Maya、Unity、その他の制作ツールとシームレスに接続します
May 23, 2023 pm 02:34 PM
カード1枚で30秒でバーチャル3D嫁をゲット! Text to 3D は、毛穴の詳細が明確な高精度のデジタル ヒューマンを生成し、Maya、Unity、その他の制作ツールとシームレスに接続します
May 23, 2023 pm 02:34 PM
ChatGPT は AI 業界に鶏の血を注入し、かつては考えられなかったすべてのことが今日では基本的な慣行になりました。進化を続ける Text-to-3D は、AIGC 分野において Diffusion(画像)、GPT(テキスト)に次ぐホットスポットとされ、前例のない注目を集めています。いいえ、ChatAvatar と呼ばれる製品が控えめなパブリック ベータ版として公開され、すぐに 700,000 回を超えるビューと注目を集め、Spacesoftheweek で特集されました。 △ChatAvatarは、AIが生成した単一視点/多視点の原画から3Dの様式化されたキャラクターを生成するImageto3D技術にも対応しており、現在のベータ版で生成された3Dモデルは広く注目を集めています。
 NeRFとは何ですか? NeRF ベースの 3D 再構成はボクセルベースですか?
Oct 16, 2023 am 11:33 AM
NeRFとは何ですか? NeRF ベースの 3D 再構成はボクセルベースですか?
Oct 16, 2023 am 11:33 AM
1 はじめに Neural Radiation Fields (NeRF) は、深層学習とコンピューター ビジョンの分野におけるかなり新しいパラダイムです。この技術は、ECCV2020 の論文「NeRF: Representing Scenes as Neural Radiation Fields for View Synthesis」(最優秀論文賞を受賞) で紹介され、それ以来非常に人気となり、現在までに 800 件近く引用されています [1]。このアプローチは、機械学習による 3D データの従来の処理方法に大きな変化をもたらします。神経放射線場のシーン表現と微分可能なレンダリング プロセス: カメラ光線に沿って 5D 座標 (位置と視線方向) をサンプリングして画像を合成し、これらの位置を MLP に入力して色と体積密度を生成し、体積レンダリング技術を使用してこれらの値を合成します。 ; レンダリング関数は微分可能であるため、渡すことができます。
