
 テクノロジー周辺機器
AI
Siri をもう精神薄弱にさせません! Apple は、「GPT-4 よりもはるかに優れた新しいデバイス側モデルを定義しています。テキストを取り除き、画面情報を視覚的にシミュレートします。最小パラメータ モデルは、ベースライン システムよりも 5% 優れています。」
テクノロジー周辺機器
AI
Siri をもう精神薄弱にさせません! Apple は、「GPT-4 よりもはるかに優れた新しいデバイス側モデルを定義しています。テキストを取り除き、画面情報を視覚的にシミュレートします。最小パラメータ モデルは、ベースライン システムよりも 5% 優れています。」
Siri をもう精神薄弱にさせません! Apple は、「GPT-4 よりもはるかに優れた新しいデバイス側モデルを定義しています。テキストを取り除き、画面情報を視覚的にシミュレートします。最小パラメータ モデルは、ベースライン システムよりも 5% 優れています。」

執筆者: Noah
制作 | 51CTO テクノロジー スタック (WeChat ID: blog51cto)
Siri は常にユーザーから「少々精神的に不安定」であると批判されています。知恵遅れ「助けがあるよ!
Siri は誕生以来、インテリジェント音声アシスタントの分野を代表するものの 1 つですが、そのパフォーマンスは長い間満足のいくものではありませんでした。しかし、Appleの人工知能チームが発表した最新の研究結果は、現状を大きく変えると予想されている。これらの結果は刺激的であり、この分野の将来に大きな期待を抱かせます。
関連する研究論文の中で、Apple の AI 専門家は、Siri が画像内のコンテンツを識別するだけでなく、よりスマートで実用的になるシステムについて説明しています。この機能モデルは ReALM と呼ばれ、GPT 4.0 標準に基づいており、GPT 4.0 よりも優れたベンチマーク機能を備えています。これらの専門家は、自分たちが開発したモデルを使用して、開発した機能を実装することで、Siri をよりスマートに、より実用的に、さまざまなシナリオに適したものにすることができると考えています。
1. 動機: さまざまなエンティティの参照解決を解決する
Apple の研究チームによると、「会話アシスタントが、関連するコンテンツの指示を含むコンテキストを理解できるようにすることが非常に重要です。ユーザーが画面に表示されている内容に基づいて質問できるようにすることは、音声操作エクスペリエンスを確保するための重要なステップです。」
たとえば、人間とコンピューターの対話中に、ユーザーはよく次のように言及します。音声アシスタントに電話番号をダイヤルする、地図上の特定の場所に移動する、特定のアプリや Web ページを開くなどの指示など、画面上の要素またはコンテンツ。会話型アシスタントがユーザーの指示の背後にあるエンティティ参照を理解できない場合、それらのコマンドを正確に実行できません。
さらに、人間の会話ではファジー参照の現象がよく見られますが、人間とコンピュータの自然なインタラクションを実現し、ユーザーが音声アシスタントを使用して画面の内容について問い合わせるときにコンテキストを正確に理解するために、参照 世代分析機能は非常に重要です。
Apple が論文の中で言及した ReALM (Reference Resolution As Language Modeling) と呼ばれるモデルの利点は、ユーザーの画面上のコンテンツと進行中のコンテンツの両方を考慮できることです。タスクは次のとおりです。大規模な言語モデルを使用して、さまざまなタイプのエンティティ (会話エンティティと非会話エンティティを含む) の参照解決の問題を解決します。
従来のテキスト モダリティは画面に表示されるエンティティの処理には不便ですが、ReALM システムは参照解析を言語モデリングの問題に変換し、LLM を使用して画面に表示されるエンティティを処理することに成功しています。非会話的なエンティティを参照すると、この目標の達成が大幅に促進されます。これにより、高度にインテリジェントでより没入感のあるユーザーエクスペリエンスを実現することが期待されています。
2. 再構築: 従来のテキスト モーダルの限界を突破する
従来のテキスト モーダルは、画面上にエンティティが表示されるため、画面に表示されるエンティティを処理するには不便です。画面には通常、画像、アイコン、ボタン、それらの間の相対位置など、豊富な視覚情報とレイアウト構造が含まれています。この情報は、純粋なテキスト記述で完全に表現するのは困難です。
この課題に対処するために、ReALM システムは、画面上のエンティティとその位置情報を解析して画面を再構築することを創造的に提案し、画面を反映して視覚化できるプレーン テキスト表現を生成します。コンテンツ。
エンティティ パーツは、言語モデルがエンティティが表示される場所とその周囲にどのようなテキストがあるかを理解できるように特別にマークされているため、画面上の情報を「見る」ことをシミュレートし、必要なコンテキストを提供できます。画面上の参照対象を理解および解析する際の情報。このアプローチは、大規模な言語モデルを使用して画面コンテンツからコンテキストをエンコードする初めての試みであり、従来のテキスト モダリティでは処理が難しい画面エンティティの問題を克服します。
具体的には、ReALM システムは次の手順を使用して、大規模な言語モデルが画面に表示されたエンティティを「理解」し、処理できるようにします。
まず、上位層のデータ検出器を使用して、画面テキスト内のエンティティを抽出します。これらのエンティティには、タイプ、境界ボックス、およびエンティティの周囲の非エンティティ テキスト要素のリストが含まれます。これは、画面上のすべての視覚的エンティティについて、システムがその基本情報とそれが存在するコンテキストをキャプチャすることを意味します。
そこで、ReALM は、エンティティと周囲のオブジェクトの境界ボックスの中心点を垂直 (上から下) と水平 (左から右) に分割するアルゴリズムを革新的に提案します。整然と、安定して配置されています。エンティティ間の距離が近い場合、エンティティは同じ行上にありタブで区切られているとみなされ、距離が設定されたマージンを超える場合は、次の行に配置されます。このように、上記の方法を継続的に適用することにより、エンティティ間の相対的な空間的位置関係を効果的に保持しながら、画面コンテンツを左から右、上から下に平文形式でエンコードすることができます。
このようにして、本来LLMでは直接処理することが難しかった画面の視覚情報を、言語モデルの入力に適したテキスト形式に変換し、LLMがシーケンスから完全に処理できるようにします。 - シーケンス タスク: 画面エンティティの正確な識別と参照解像度を実現するために、画面エンティティの特定の場所とコンテキストが考慮されます。
これにより、ReALM システムは、対話エンティティを参照する問題を解決する際に優れたパフォーマンスを発揮するだけでなく、非対話エンティティ、つまり、画面のパフォーマンスが向上しました。
3. 詳細: タスク定義とデータセット
簡単に言えば、ReALM システムが直面するタスクは、ユーザーが実行したいタスクに応じて、指定されたエンティティ セット内で、現在のユーザー クエリに関連するエンティティを検索します。
このタスクは、大規模な言語モデルの多肢選択式の質問として構成されており、ユーザーの画面に表示されているエンティティから 1 つ以上の選択肢を回答として選択することが期待されます。もちろん、場合によっては、答えが「どちらでもない」ということもあります。
実際、研究論文では、タスクに関与するエンティティを 3 つのカテゴリに分類しています:
1. 画面エンティティ: 現在のエンティティを指します。ユーザーインターフェイスに表示されるエンティティ。
2. 対話エンティティ: 会話の内容に関連するエンティティ。ユーザーの以前の発言に由来する可能性があります (たとえば、ユーザーが「お母さんに電話する」と発言した場合、連絡先リストの「お母さん」のエントリは関連するエンティティ)、または会話中の仮想アシスタントによって提供される場合もあります(ユーザーが選択できる場所のリストなど)。
3. バックグラウンド エンティティ: バックグラウンド プロセスから発生し、デフォルトで鳴る目覚まし時計やバックグラウンドで再生される音楽など、ユーザーの画面表示や仮想アシスタントとの対話に必ずしも直接反映されるわけではない関連エンティティ。
ReALM のトレーニングとテストに使用されるデータ セットは、合成データと手動で注釈が付けられたデータで構成されており、次の 3 つのカテゴリに分類できます。
まず、ダイアログ データ セット: ユーザーとエージェント間の対話に関連するエンティティのデータ ポイントが含まれています。これらのデータは、評価者に合成エンティティのリストを含むスクリーンショットを表示させ、リスト内で選択されたエンティティを明示的に指すクエリを提供するよう依頼することで収集されました。
2 番目の合成データ セット: テンプレート生成メソッドを使用してデータを取得します。このメソッドは、詳細な説明に依存せずにユーザー クエリとエンティティ タイプだけで参照を判断できる場合に特に便利です。 。合成データ セットには、同じクエリに対応する複数のエンティティを含めることもできます。
3 番目の画面データ セット: 主にユーザーの画面に現在表示されているエンティティのデータが含まれ、各データにはユーザー クエリ、エンティティ リスト、クエリに対応する正しいエンティティが含まれます。 (またはエンティティのコレクション)。各エンティティに関する情報には、エンティティ タイプと、エンティティに関連付けられた名前やその他のテキスト詳細 (目覚まし時計のラベルや時間など) などのその他のプロパティが含まれます。
画面関連のコンテキストを持つデータ ポイントの場合、コンテキスト情報は、エンティティの境界ボックスとエンティティを囲む他のオブジェクトのリストの形式で、タイプとテキストの内容とともに提供されます。これらの周囲の物体の位置情報や位置属性情報を取得します。データセット全体のサイズはカテゴリに応じてトレーニングセットとテストセットに分かれており、それぞれ一定のサイズがあります。
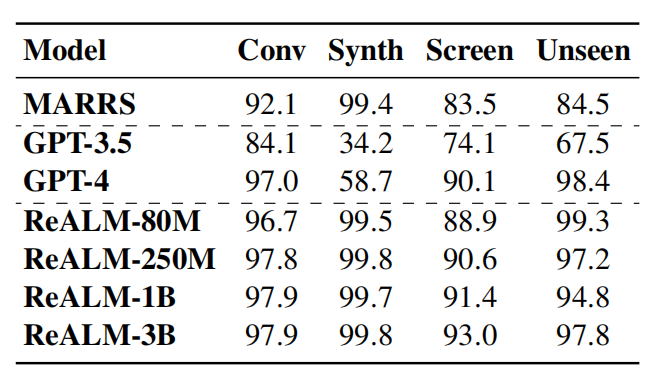
4. 結果: 最小モデルでも 5% のパフォーマンス向上を達成しました。
Apple はベンチマーク テストで、自社のシステムを GPT 3.5 および GPT 4.0 と比較しました。 ReALM モデルは、さまざまな種類の参照解析タスクを解決する際に優れた競争力を示します。
 写真
写真
論文によると、ReALM のパラメータが最も少ないバージョンでも、また、ベースライン システムと比較して 5% 以上のパフォーマンス向上も達成しました。より大きなモデルのバージョンでは、ReALM は GPT-4 よりも明らかに優れています。特に画面上に表示されるエンティティを処理する場合、モデル サイズが大きくなるにつれて、画面データ セット上の ReALM のパフォーマンス向上がより顕著になります。
さらに、ReALM モデルのパフォーマンスは、新しい分野のゼロサンプル学習シナリオでは GPT-4 のパフォーマンスに非常に近くなります。特定のフィールドでクエリを処理する場合、ReALM モデルはユーザーのリクエストに基づいて微調整されるため、GPT-4 よりも正確に実行されます。
たとえば、明るさを調整するというユーザー要求の場合、GPT-4 はその要求を設定に関連付けるだけで、バックグラウンドに存在するスマート ホーム デバイスも関連エンティティであることを無視します。 ReALM はドメイン固有のデータに基づいてトレーニングされるため、そのような特定のドメインの参照問題をよりよく理解し、正しく解析できます。
「現在の最先端の LLM である GPT-4 よりもパラメーターがはるかに少ないにもかかわらず、RealLM が以前の方法よりも優れたパフォーマンスを発揮し、純粋にテキスト フィールドに基づいた画面を処理できることを実証しました。引用すると、ReaLMも同等の性能を実現できており、また特定分野のユーザー発話においてはGPT-4よりも優れた性能を発揮するため、性能を確保しつつ開発向けのアプリケーションに適していると言える。 「これは、実用的なアプリケーション環境にとって推奨されるソリューションであり、デバイス上でローカルに効率的に実行できる参照解像度システムです。」
さらに、研究者らは、リソースが損なわれると、限られた低遅延の応答が必要である、または複数のプロセスが関与している API 呼び出しなどのステージ統合などの実際のアプリケーション シナリオでは、単一の大規模なエンドツーエンド モデルが適用できないことがよくあります。
これに関連して、モジュール式に設計された ReALM システムには、より優れた最適化の可能性と解釈可能性を提供しながら、アーキテクチャ全体に影響を与えることなく、元の基準解像度モジュールを簡単に交換およびアップグレードできるという、より多くの利点があります。 。
将来に向けて、研究の方向性は、画面領域をグリッドに分割したり、相対的な空間位置をテキスト形式でエンコードしたりするなど、より複雑な方法を指しています。これは非常に困難ではありますが、これは探究すべき有望な手段です。
5.最後に記載
人工知能の分野では、Apple は常に慎重ですが、静かに投資も行っています。マルチモーダル大型モデル MM1 であれ、AI 主導のアニメーション生成ツール Keyframer であれ、今日の ReALM であれ、Apple の研究チームは技術的なブレークスルーを達成し続けています。
Google、Microsoft、Amazon などの競合他社は、検索、クラウド サービス、オフィス ソフトウェアに AI を追加し、次々と力を入れています。 Apple が取り残されないように努めているのは明らかだ。生成 AI 実装の成果が次々と現れる中、Apple は追いつくペースを加速させています。関係者らは以前から、Appleが6月の世界開発者会議で人工知能分野に注力することを明らかにしており、新たな人工知能戦略がiOS 18アップグレードの中核となる内容となる可能性が高い。その頃には、あなたに驚きが訪れるかもしれません。
参考リンク:
https://apple.slashdot.org/story/24/04/01/1959205/apple-ai-researchers-boast-useful -on-device-model-that-substantially-outperforms-gpt-4
https://arxiv.org/pdf/2403.20329.pdf
以上がSiri をもう精神薄弱にさせません! Apple は、「GPT-4 よりもはるかに優れた新しいデバイス側モデルを定義しています。テキストを取り除き、画面情報を視覚的にシミュレートします。最小パラメータ モデルは、ベースライン システムよりも 5% 優れています。」の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7518
7518
 15
1378
52
80
11
21
67
15
1378
52
80
11
21
67

 ゴマのオープンエクスチェンジを中国語に調整する方法
Mar 04, 2025 pm 11:51 PM
ゴマのオープンエクスチェンジを中国語に調整する方法
Mar 04, 2025 pm 11:51 PM
ゴマのオープンエクスチェンジを中国語に調整する方法は?このチュートリアルでは、コンピューターとAndroidの携帯電話の詳細な手順、予備的な準備から運用プロセスまで、そして一般的な問題を解決するために、セサミのオープン交換インターフェイスを中国に簡単に切り替え、取引プラットフォームをすばやく開始するのに役立ちます。
 ブートストラップ画像の中央でFlexBoxを使用する必要がありますか?
Apr 07, 2025 am 09:06 AM
ブートストラップ画像の中央でFlexBoxを使用する必要がありますか?
Apr 07, 2025 am 09:06 AM
ブートストラップの写真を集中させる方法はたくさんあり、FlexBoxを使用する必要はありません。水平にのみ中心にする必要がある場合、テキスト中心のクラスで十分です。垂直または複数の要素を中央に配置する必要がある場合、FlexBoxまたはグリッドがより適しています。 FlexBoxは互換性が低く、複雑さを高める可能性がありますが、グリッドはより強力で、学習コストが高くなります。メソッドを選択するときは、長所と短所を比較検討し、ニーズと好みに応じて最も適切な方法を選択する必要があります。
 c-subscript 3 subscript 5 c-subscript 3 subscript 5アルゴリズムチュートリアルを計算する方法
Apr 03, 2025 pm 10:33 PM
c-subscript 3 subscript 5 c-subscript 3 subscript 5アルゴリズムチュートリアルを計算する方法
Apr 03, 2025 pm 10:33 PM
C35の計算は、本質的に組み合わせ数学であり、5つの要素のうち3つから選択された組み合わせの数を表します。計算式はC53 = 5です! /(3! * 2!)。これは、ループで直接計算して効率を向上させ、オーバーフローを避けることができます。さらに、組み合わせの性質を理解し、効率的な計算方法をマスターすることは、確率統計、暗号化、アルゴリズム設計などの分野で多くの問題を解決するために重要です。
 トップ10仮想通貨取引プラットフォーム2025暗号通貨取引アプリランキングトップ10
Mar 17, 2025 pm 05:54 PM
トップ10仮想通貨取引プラットフォーム2025暗号通貨取引アプリランキングトップ10
Mar 17, 2025 pm 05:54 PM
トップ10仮想通貨取引プラットフォーム2025:1。OKX、2。BINANCE、3。GATE.IO、4。Kraken、5。Huobi、6。Coinbase、7。Kucoin、8。Crypto.com、9。Bitfinex、10。Gemini。プラットフォームを選択する際には、セキュリティ、流動性、処理料、通貨選択、ユーザーインターフェイス、カスタマーサポートを考慮する必要があります。
 トップ10の暗号通貨取引プラットフォーム、トップ10の推奨される通貨取引プラットフォームアプリ
Mar 17, 2025 pm 06:03 PM
トップ10の暗号通貨取引プラットフォーム、トップ10の推奨される通貨取引プラットフォームアプリ
Mar 17, 2025 pm 06:03 PM
上位10の暗号通貨取引プラットフォームには、1。Okx、2。Binance、3。Gate.io、4。Kraken、5。Huobi、6。Coinbase、7。Kucoin、8。Crypto.com、9。Bitfinex、10。Gemini。プラットフォームを選択する際には、セキュリティ、流動性、処理料、通貨選択、ユーザーインターフェイス、カスタマーサポートを考慮する必要があります。
 安全で信頼できるデジタル通貨プラットフォームは何ですか?
Mar 17, 2025 pm 05:42 PM
安全で信頼できるデジタル通貨プラットフォームは何ですか?
Mar 17, 2025 pm 05:42 PM
安全で信頼できるデジタル通貨プラットフォーム:1。OKX、2。Binance、3。Gate.io、4。Kraken、5。Huobi、6。Coinbase、7。Kucoin、8。Crypto.com、9。Bitfinex、10。Gemini。プラットフォームを選択する際には、セキュリティ、流動性、処理料、通貨選択、ユーザーインターフェイス、カスタマーサポートを考慮する必要があります。
 個別の関数使用距離関数C使用チュートリアル
Apr 03, 2025 pm 10:27 PM
個別の関数使用距離関数C使用チュートリアル
Apr 03, 2025 pm 10:27 PM
std :: uniqueは、コンテナ内の隣接する複製要素を削除し、最後まで動かし、最初の複製要素を指すイテレーターを返します。 STD ::距離は、2つの反復器間の距離、つまり、指す要素の数を計算します。これらの2つの機能は、コードを最適化して効率を改善するのに役立ちますが、隣接する複製要素をstd ::のみ取引するというような、注意すべき落とし穴もあります。 STD ::非ランダムアクセスイテレーターを扱う場合、距離は効率が低くなります。これらの機能とベストプラクティスを習得することにより、これら2つの機能の力を完全に活用できます。
 WebアノテーションにY軸位置の適応レイアウトを実装する方法は?
Apr 04, 2025 pm 11:30 PM
WebアノテーションにY軸位置の適応レイアウトを実装する方法は?
Apr 04, 2025 pm 11:30 PM
Y軸位置Webアノテーション機能の適応アルゴリズムこの記事では、単語文書と同様の注釈関数、特に注釈間の間隔を扱う方法を実装する方法を探ります...
