

LLM 超ロングコンテキストクエリ - 実用的なパフォーマンス評価

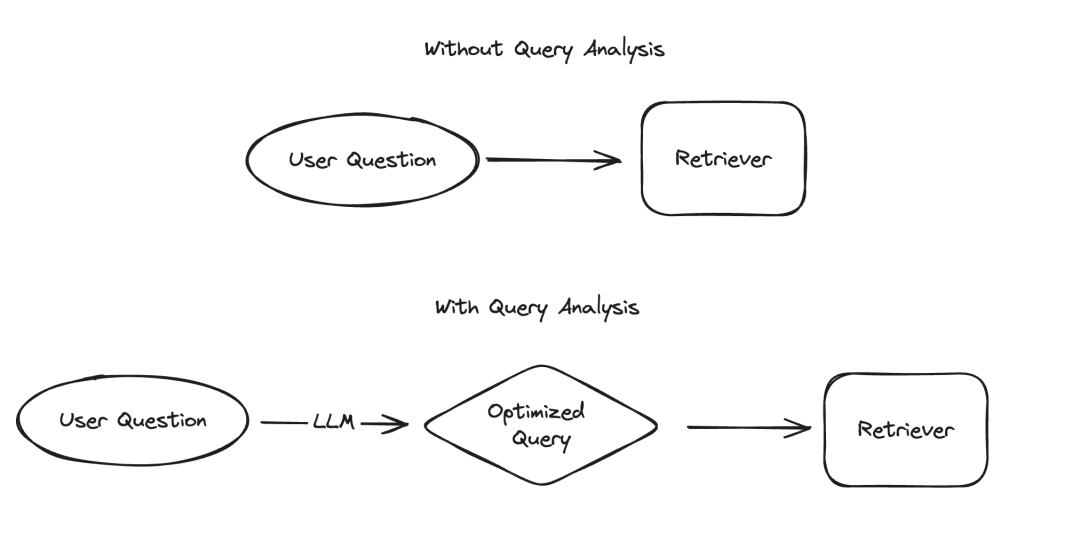
大規模言語モデル (LLM) のアプリケーションでは、構造化された方法でデータを提示する必要があるいくつかのシナリオがあり、その代表的な 2 つの例が情報抽出とクエリ分析です。私たちは最近、最新のドキュメントと専用のコード リポジトリによる情報抽出の重要性を強調しました。クエリ分析については、関連ドキュメントも更新しました。これらのシナリオでは、データ フィールドには文字列、ブール値、整数などが含まれる場合があります。これらの型の中で、カーディナリティの高いカテゴリ値 (つまり列挙型) を扱うのが最も困難です。
 図
図
いわゆる「高基数グループ化値」とは、限られたオプションから選択する必要がある値を指します。値は任意に指定できませんが、事前定義されたコレクションから取得する必要があります。このようなセットでは、非常に多数の有効な値が存在することがあります。これを「高カーディナリティ値」と呼びます。このような値の処理が難しい理由は、LLM 自体がこれらの実現可能な値が何であるかを知らないためです。したがって、これらの実現可能な値に関する情報を LLM に提供する必要があります。実現可能な値が少数しかない場合を無視しても、これらの可能な値をヒントに明示的にリストすることで、この問題を解決できます。ただし、考えられる値が非常に多いため、問題は複雑になります。
可能な値の数が増えると、LLM による値の選択の難しさも増します。一方で、可能な値が多すぎると、LLM のコンテキスト ウィンドウに収まらない可能性があります。一方で、考えられるすべての値がコンテキストに適合する場合でも、それらをすべて含めると、大量のコンテキストを処理するときに処理が遅くなり、コストが増加し、LLM 推論能力が低下します。 `可能な値の数が増えると、LLM が値を選択するのが難しくなります。一方で、可能な値が多すぎると、LLM のコンテキスト ウィンドウに収まらない可能性があります。一方で、考えられるすべての値がコンテキストに適合する場合でも、それらをすべて含めると、大量のコンテキストを処理するときに処理が遅くなり、コストが増加し、LLM 推論能力が低下します。 ` (注: 元のテキストは URL エンコードされているようです。エンコードを修正し、書き直したテキストを提供しました。)
最近、クエリ分析の徹底的な研究を実施し、特にその方法に関するページを追加しました。高い基数を扱うため。このブログでは、いくつかの実験的アプローチを詳しく説明し、そのパフォーマンス ベンチマーク結果を提供します。
結果の概要は、LangSmith https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d?ref=blog.langchain.dev でご覧いただけます。次に、詳しく紹介します。
 写真
写真
データセットの概要
詳細なデータセットを確認してください。ここ https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d?ref=blog.langchain.dev。
この問題をシミュレートするために、特定の著者によるエイリアンに関する本を見つけたいというシナリオを想定します。このシナリオでは、ライター フィールドはカーディナリティの高いカテゴリ変数です。多くの値が考えられますが、それらは特定の有効なライター名である必要があります。 これをテストするために、著者名と一般的な別名を含むデータセットを作成しました。たとえば、「Harry Chase」は「Harrison Chase」のエイリアスである可能性があります。私たちは、インテリジェントなシステムがこの種のエイリアシングを処理できるようにしたいと考えています。 このデータセットでは、作家の名前と別名のリストを含むデータセットを生成しました。 10,000 個のランダムな名前は多すぎるわけではないことに注意してください。エンタープライズ レベルのシステムでは、数百万単位のカーディナリティを処理する必要がある場合があります。
このデータ セットを使用して、「エイリアンに関するハリー チェイスの本は何ですか?」という質問をしました。クエリ分析システムは、この質問を解析して、件名と著者の 2 つのフィールドを含む構造化フォーマットに変換できるはずです。この例では、予期される出力は {"topic": "aliens", "author": "Harrison Chase"} になります。システムは Harry Chase という名前の著者が存在しないことを認識すると予想されますが、ユーザーが意図したのは Harrison Chase である可能性があります。
この設定を使用すると、作成したエイリアス データセットに対してテストして、実際の名前に正しくマッピングされているかどうかを確認できます。同時に、クエリのレイテンシとコストも記録します。この種のクエリ分析システムは通常、検索に使用されるため、これら 2 つの指標は非常に懸念されます。このため、すべてのメソッドを 1 つの LLM 呼び出しのみに制限します。今後の記事で、複数の LLM 呼び出しを使用したメソッドのベンチマークを行う可能性があります。
次に、いくつかの異なる方法とそのパフォーマンスを紹介します。
 写真
写真
完全な結果は LangSmith で確認できます。これらの結果を再現するコードはここにあります。
ベースライン テスト
まず、LLM でベースライン テストを実行しました。つまり、有効な名前情報を提供せずに、LLM にクエリ分析を実行するよう直接依頼しました。予想通り、正解した質問は 1 つもありませんでした。これは、エイリアスによる作成者へのクエリを必要とするデータセットを意図的に構築したためです。
コンテキスト入力方法
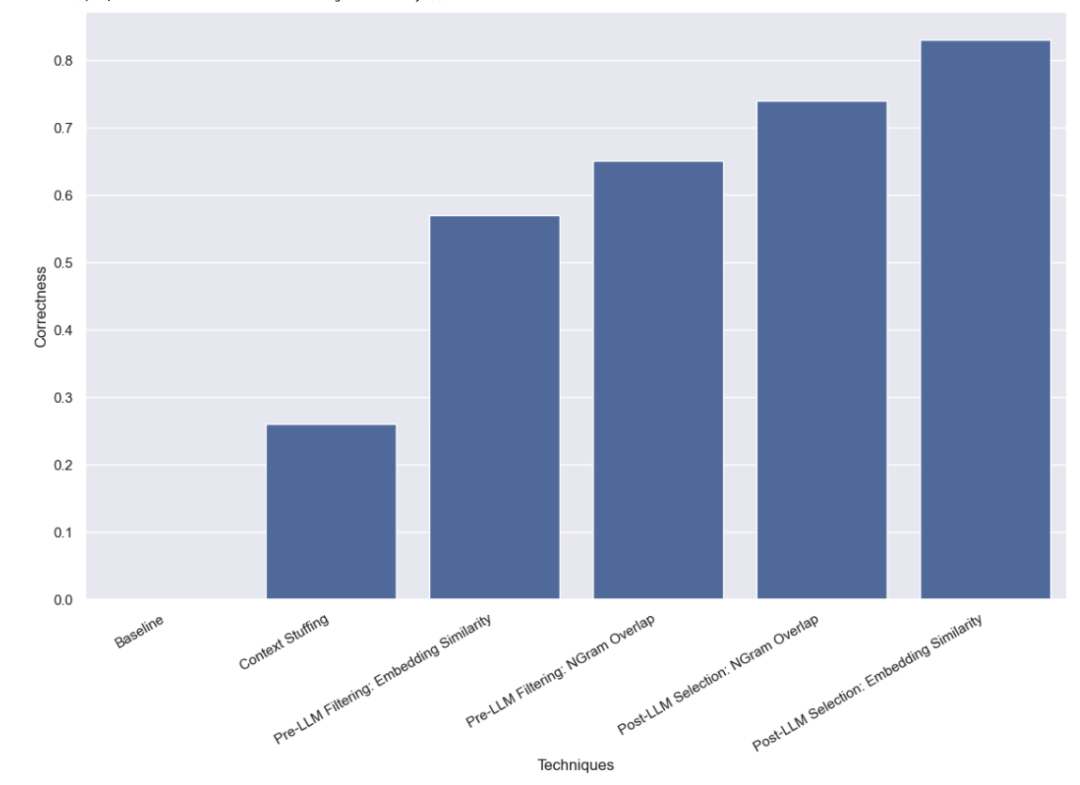
この方法では、10,000 件の正式な著者名をすべてプロンプトに入力し、LLM にクエリ分析を実行するよう依頼します。これらが正式な著者名であることを覚えておいてください。一部のモデル (GPT-3.5 など) は、コンテキスト ウィンドウの制限により、このタスクを実行できません。コンテキスト ウィンドウが長い他のモデルの場合も、正しい名前を正確に選択することが困難でした。 GPT-4 は、26% のケースでのみ正しい名前を選択しました。最も一般的なエラーは、名前を抽出しても修正しないことです。この方法は時間がかかるだけでなく、コストも高く、完了までに平均 5 秒かかり、合計 8.44 ドルかかります。
LLM 前のフィルタリング方法
次にテストした方法は、LLM に渡す前に、可能な値のリストをフィルタリングすることでした。この利点は、考えられる名前のサブセットのみを LLM に渡すため、LLM が考慮すべき名前がはるかに少なくなり、クエリ分析をより速く、より安く、より正確に完了できるようになることです。しかし、これにより、新たな潜在的な障害モードも追加されます。最初のフィルタリングが失敗した場合はどうなるでしょうか?
埋め込みベースのフィルタリング方法
最初に使用したフィルタリング方法は埋め込み方法で、クエリに最も類似した 10 個の名前が選択されました。クエリ全体と名前を比較していますが、これは理想的な比較ではないことに注意してください。
このアプローチを使用すると、GPT-3.5 はケースの 57% を正しく処理できることがわかりました。この方法は以前の方法よりもはるかに高速かつ安価で、完了までにかかる時間は平均でわずか 0.76 秒、総コストはわずか 0.002 ドルです。
NGram 類似性に基づくフィルタリング方法
使用する 2 番目のフィルタリング方法は、すべての有効な名前の 3 グラム文字シーケンスの TF-IDF ベクトル化であり、コサインを使用します。ベクトル化された有効な名前とベクトル化されたユーザー入力の間の類似性を調べて、モデル プロンプトに追加する最も関連性の高い 10 個の有効な名前を選択します。また、クエリ全体と名前を比較していますが、これは理想的な比較ではないことにも注意してください。
このアプローチを使用すると、GPT-3.5 はケースの 65% を正しく処理できることがわかりました。また、この方法は以前の方法よりもはるかに高速かつ安価で、完了までにかかる時間は平均 0.57 秒だけで、総コストはわずか 0.002 ドルです。
LLM 後の選択方法
テストした最後の方法は、LLM が予備的なクエリ分析を完了した後にエラーを修正することです。まず、プロンプトに有効な作成者名に関する情報を何も提供せずに、ユーザー入力に対してクエリ分析を実行しました。これは最初に行ったベースライン テストと同じです。次に、著者フィールドの名前を取得し、最も類似した有効な名前を見つけるという後続のステップを実行しました。
埋め込み類似度による選択方法
まず、埋め込み方式による類似性チェックを行いました。
このアプローチを使用すると、GPT-3.5 はケースの 83% を正しく処理できることがわかりました。この方法は以前の方法よりもはるかに高速かつ安価で、完了までにかかる時間は平均 0.66 秒だけで、総コストはわずか 0.001 ドルです。
NGram 類似度に基づく選択方法
最後に、類似性チェックに 3 グラム ベクトル化器を使用してみます。
このアプローチを使用すると、GPT-3.5 はケースの 74% を正しく処理できることがわかりました。また、この方法は以前の方法よりもはるかに高速かつ安価で、完了までにかかる時間は平均 0.48 秒だけで、総コストはわずか 0.001 ドルです。
#結論
高カーディナリティのカテゴリ値を処理するためのクエリ分析手法について、さまざまなベンチマーク テストを実施しました。実際の遅延制約をシミュレートするために、LLM 呼び出しを 1 回だけ行うように制限しました。埋め込み類似性に基づく選択方法は、LLM を使用した後に最もよく機能することがわかりました。 さらにテストする価値のある方法は他にもあります。特に、LLM 呼び出しの前後で最も類似したカテゴリ値を見つける方法は数多くあります。さらに、このデータセットのカテゴリ ベースは、多くのエンタープライズ システムが直面しているほど高くありません。このデータセットには約 10,000 の値がありますが、現実世界の多くのシステムでは数百万のカーディナリティを処理する必要がある場合があります。したがって、より高いカーディナリティのデータでベンチマークを行うことは非常に価値があります。以上がLLM 超ロングコンテキストクエリ - 実用的なパフォーマンス評価の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7540
7540
 15
1380
52
83
11
21
86
15
1380
52
83
11
21
86

 Groq Llama 3 70B をローカルで使用するためのステップバイステップ ガイド
Jun 10, 2024 am 09:16 AM
Groq Llama 3 70B をローカルで使用するためのステップバイステップ ガイド
Jun 10, 2024 am 09:16 AM
翻訳者 | Bugatti レビュー | Chonglou この記事では、GroqLPU 推論エンジンを使用して JanAI と VSCode で超高速応答を生成する方法について説明します。 Groq は AI のインフラストラクチャ側に焦点を当てているなど、誰もがより優れた大規模言語モデル (LLM) の構築に取り組んでいます。これらの大型モデルがより迅速に応答するためには、これらの大型モデルからの迅速な応答が鍵となります。このチュートリアルでは、GroqLPU 解析エンジンと、API と JanAI を使用してラップトップ上でローカルにアクセスする方法を紹介します。この記事では、これを VSCode に統合して、コードの生成、コードのリファクタリング、ドキュメントの入力、テスト ユニットの生成を支援します。この記事では、独自の人工知能プログラミングアシスタントを無料で作成します。 GroqLPU 推論エンジン Groq の概要
 カリフォルニア工科大学の中国人がAIを使って数学的証明を覆す!タオ・ゼシュアンの衝撃を5倍にスピードアップ、数学的ステップの80%が完全に自動化
Apr 23, 2024 pm 03:01 PM
カリフォルニア工科大学の中国人がAIを使って数学的証明を覆す!タオ・ゼシュアンの衝撃を5倍にスピードアップ、数学的ステップの80%が完全に自動化
Apr 23, 2024 pm 03:01 PM
テレンス・タオなど多くの数学者に賞賛されたこの正式な数学ツール、LeanCopilot が再び進化しました。ちょうど今、カリフォルニア工科大学のアニマ・アナンドクマール教授が、チームが LeanCopilot 論文の拡張版をリリースし、コードベースを更新したと発表しました。イメージペーパーのアドレス: https://arxiv.org/pdf/2404.12534.pdf 最新の実験では、この Copilot ツールが数学的証明ステップの 80% 以上を自動化できることが示されています。この記録は、以前のベースラインのイソップよりも 2.3 倍優れています。そして、以前と同様に、MIT ライセンスの下でオープンソースです。写真の彼は中国人の少年、ソン・ペイヤンです。
 Plaud、NotePin AI ウェアラブル レコーダーを 169 ドルで発売
Aug 29, 2024 pm 02:37 PM
Plaud、NotePin AI ウェアラブル レコーダーを 169 ドルで発売
Aug 29, 2024 pm 02:37 PM
Plaud Note AI ボイスレコーダー (Amazon で 159 ドルで購入可能) を開発した企業 Plaud が新製品を発表しました。 NotePin と呼ばれるこのデバイスは AI メモリ カプセルとして説明されており、Humane AI Pin と同様にウェアラブルです。ノートピンは
 GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
AIGC について詳しくは、51CTOAI.x コミュニティ https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou を参照してください。これらの質問は、インターネット上のどこでも見られる従来の質問バンクとは異なります。既成概念にとらわれずに考える必要があります。大規模言語モデル (LLM) は、データ サイエンス、生成人工知能 (GenAI)、および人工知能の分野でますます重要になっています。これらの複雑なアルゴリズムは人間のスキルを向上させ、多くの業界で効率とイノベーションを推進し、企業が競争力を維持するための鍵となります。 LLM は、自然言語処理、テキスト生成、音声認識、推奨システムなどの分野で幅広い用途に使用できます。 LLM は大量のデータから学習することでテキストを生成できます。
 ナレッジグラフ検索用に強化された GraphRAG (Neo4j コードに基づいて実装)
Jun 12, 2024 am 10:32 AM
ナレッジグラフ検索用に強化された GraphRAG (Neo4j コードに基づいて実装)
Jun 12, 2024 am 10:32 AM
Graph Retrieval Enhanced Generation (GraphRAG) は徐々に普及しており、従来のベクトル検索方法を強力に補完するものとなっています。この方法では、グラフ データベースの構造的特徴を利用してデータをノードと関係の形式で編成し、それによって取得された情報の深さと文脈の関連性が強化されます。グラフには、相互に関連する多様な情報を表現および保存するという自然な利点があり、異なるデータ型間の複雑な関係やプロパティを簡単に把握できます。ベクトル データベースはこの種の構造化情報を処理できず、高次元ベクトルで表される非構造化データの処理に重点を置いています。 RAG アプリケーションでは、構造化グラフ データと非構造化テキスト ベクトル検索を組み合わせることで、両方の利点を同時に享受できます。これについてこの記事で説明します。構造
 Google AI、開発者向けに Gemini 1.5 Pro と Gemma 2 を発表
Jul 01, 2024 am 07:22 AM
Google AI、開発者向けに Gemini 1.5 Pro と Gemma 2 を発表
Jul 01, 2024 am 07:22 AM
Google AI は、Gemini 1.5 Pro 大規模言語モデル (LLM) を皮切りに、拡張コンテキスト ウィンドウとコスト削減機能へのアクセスを開発者に提供し始めました。以前は待機リストを通じて利用可能でしたが、完全な 200 万トークンのコンテキストウィンドウが利用可能になりました
 PHP 配列キー値の反転: さまざまな方法のパフォーマンス比較分析
May 03, 2024 pm 09:03 PM
PHP 配列キー値の反転: さまざまな方法のパフォーマンス比較分析
May 03, 2024 pm 09:03 PM
PHP の配列キー値の反転メソッドのパフォーマンスを比較すると、array_flip() 関数は、大規模な配列 (100 万要素以上) では for ループよりもパフォーマンスが良く、所要時間が短いことがわかります。キー値を手動で反転する for ループ方式は、比較的長い時間がかかります。
 さまざまな Java フレームワークのパフォーマンスの比較
Jun 05, 2024 pm 07:14 PM
さまざまな Java フレームワークのパフォーマンスの比較
Jun 05, 2024 pm 07:14 PM
さまざまな Java フレームワークのパフォーマンス比較: REST API リクエスト処理: Vert.x が最高で、リクエスト レートは SpringBoot の 2 倍、Dropwizard の 3 倍です。データベース クエリ: SpringBoot の HibernateORM は Vert.x や Dropwizard の ORM よりも優れています。キャッシュ操作: Vert.x の Hazelcast クライアントは、SpringBoot や Dropwizard のキャッシュ メカニズムよりも優れています。適切なフレームワーク: アプリケーションの要件に応じて選択します。Vert.x は高パフォーマンスの Web サービスに適しており、SpringBoot はデータ集約型のアプリケーションに適しており、Dropwizard はマイクロサービス アーキテクチャに適しています。
