

AIGC について詳しく知りたい場合は、
にアクセスしてください: 51CTO AI.x Community
https://www.51cto.com/aigc/
"Llama-2 レベルで大規模なモデルをトレーニングするために使用できるのは、"$100,000 のみです。
サイズは小さくなりますが、パフォーマンスは低下しませんMoEモデルはここにあります:
それはJetMoE# と呼ばれます##、MIT やプリンストンなどの研究機関から。 同スケールのLlama-2よりもはるかに性能が優れています。
 △Jia Yangqing 氏転送
△Jia Yangqing 氏転送
後者には
数十億ドルの投資コストがかかることを知っておく必要があります。
 JetMoE はリリース時は完全に
JetMoE はリリース時は完全に
であり、学術界に優しいものです。公開データ セットとオープン ソース コードのみが使用され、コンシューマ グレードの GPU は微調整できます。 大規模モデルの構築コストは、人々が考えているよりも実際にははるかに安いと言わざるを得ません。
Stable Diffusion の元ボスである Ps. Emad 氏も気に入ってくれました:
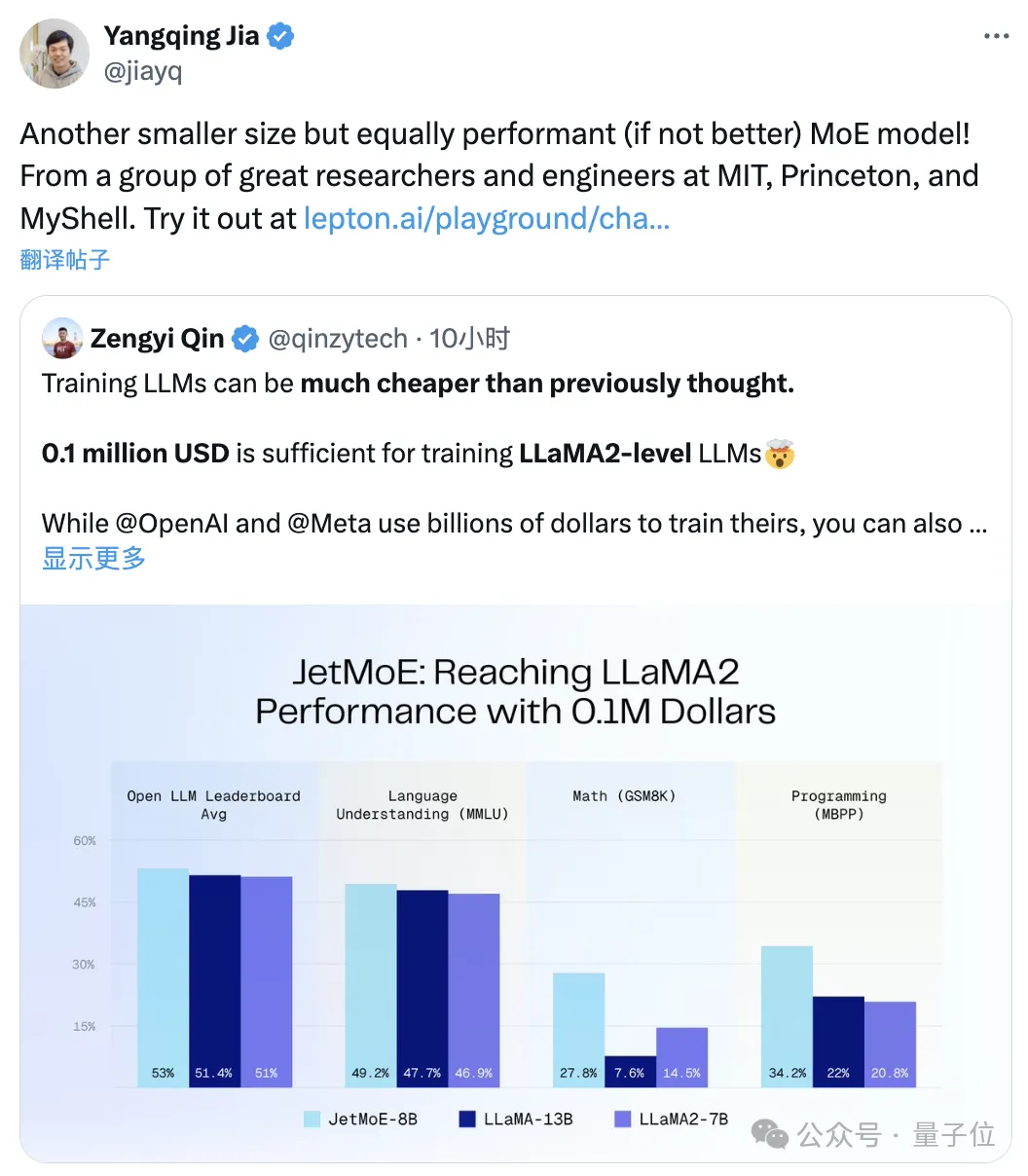
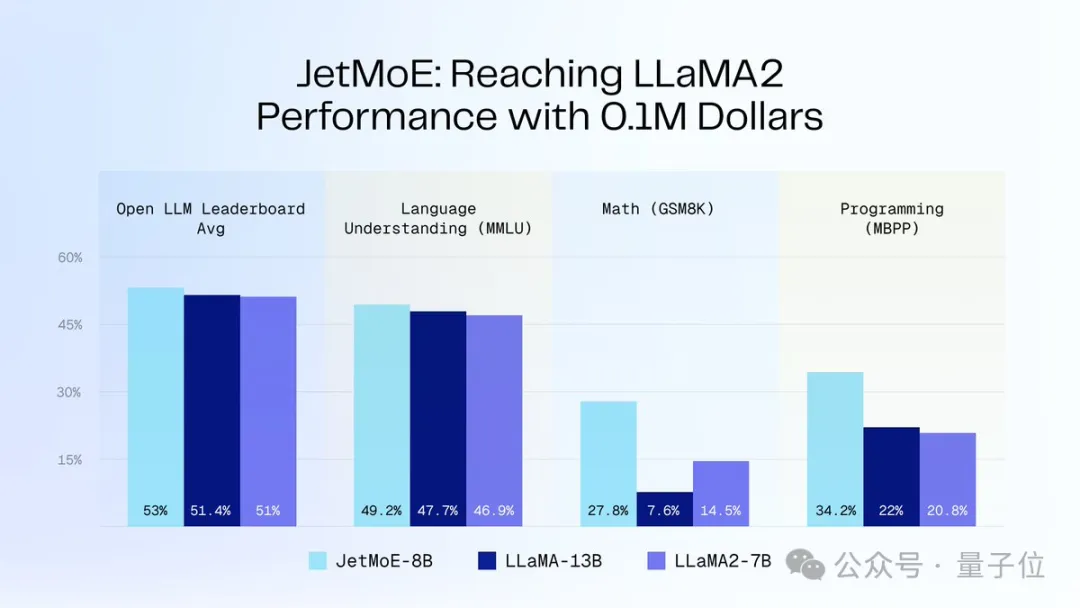
 Llama-2 のパフォーマンスを達成するために 100,000 米ドル
Llama-2 のパフォーマンスを達成するために 100,000 米ドル
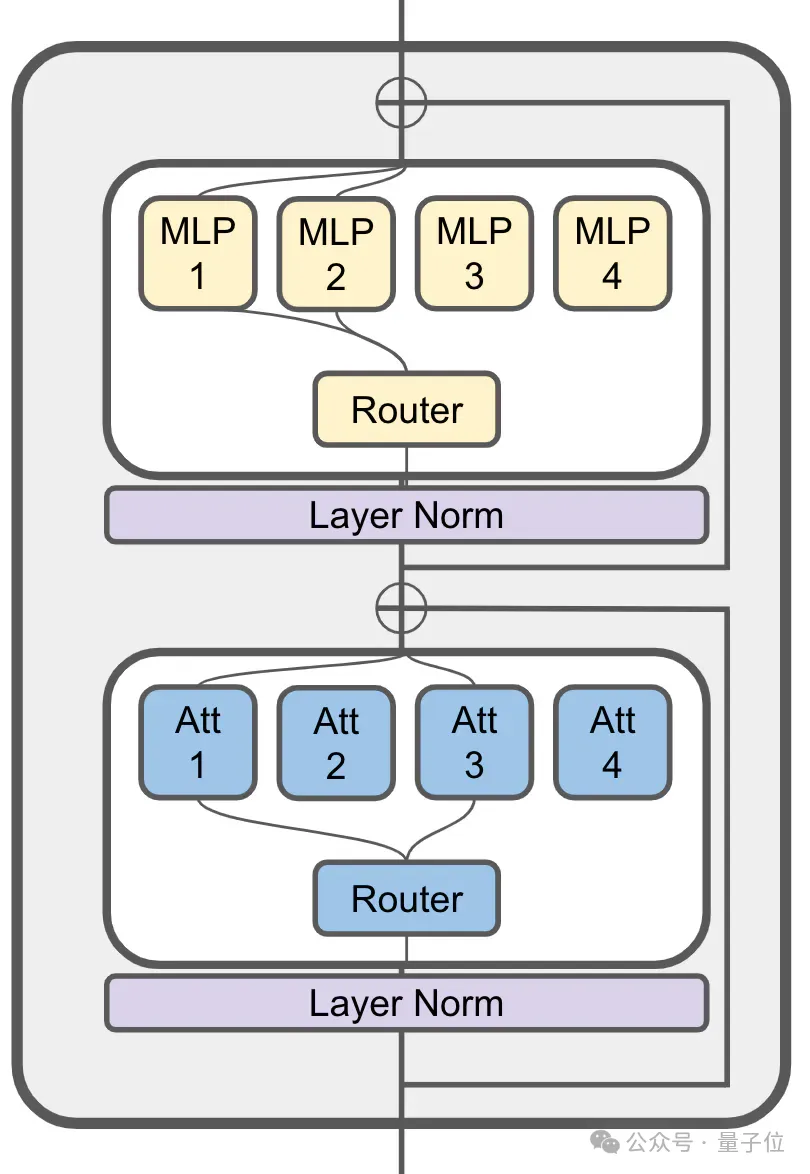
It MoE はまだアテンション レイヤーで使用されています:
80 億パラメータ JetMoE には合計 24 ブロックがあり、各ブロックには 2 つの MoE レイヤー、つまりアテンション ヘッド ミキシング
(MoA)mixed が含まれていますMLP 専門家 (MoE) と協力。 各 MoA 層と MoE 層には 8 人の専門家がおり、トークンが入力されるたびに 2 人がアクティブになります。
 JetMoE-8B は、学習率 5.0 x 10 で、公開データセット内の
JetMoE-8B は、学習率 5.0 x 10 で、公開データセット内の
1.25T トークン をトレーニング用に使用します。 -4、グローバル バッチ サイズは 4M トークンです。
具体的なトレーニング計画MiniCPMのアイデアに従います(壁に面したインテリジェンスから、2BモデルはMistral-7Bに追いつくことができます)、 ##2 つのステージ #:最初のステージでは、線形ウォームアップによる一定の学習率を使用し、大規模なトークンからの 1 兆個のトークンを使用してトレーニングされます。オープン ソースの事前トレーニング データ セット。これらのデータ セットには、RefinedWeb、Pile、Github データなどが含まれます。
第 2 段階では、指数関数的な学習率減衰を使用し、2,500 億のトークンを使用して、第 1 段階のデータセットと超高品質のオープンソース データセットからのトークンをトレーニングします。 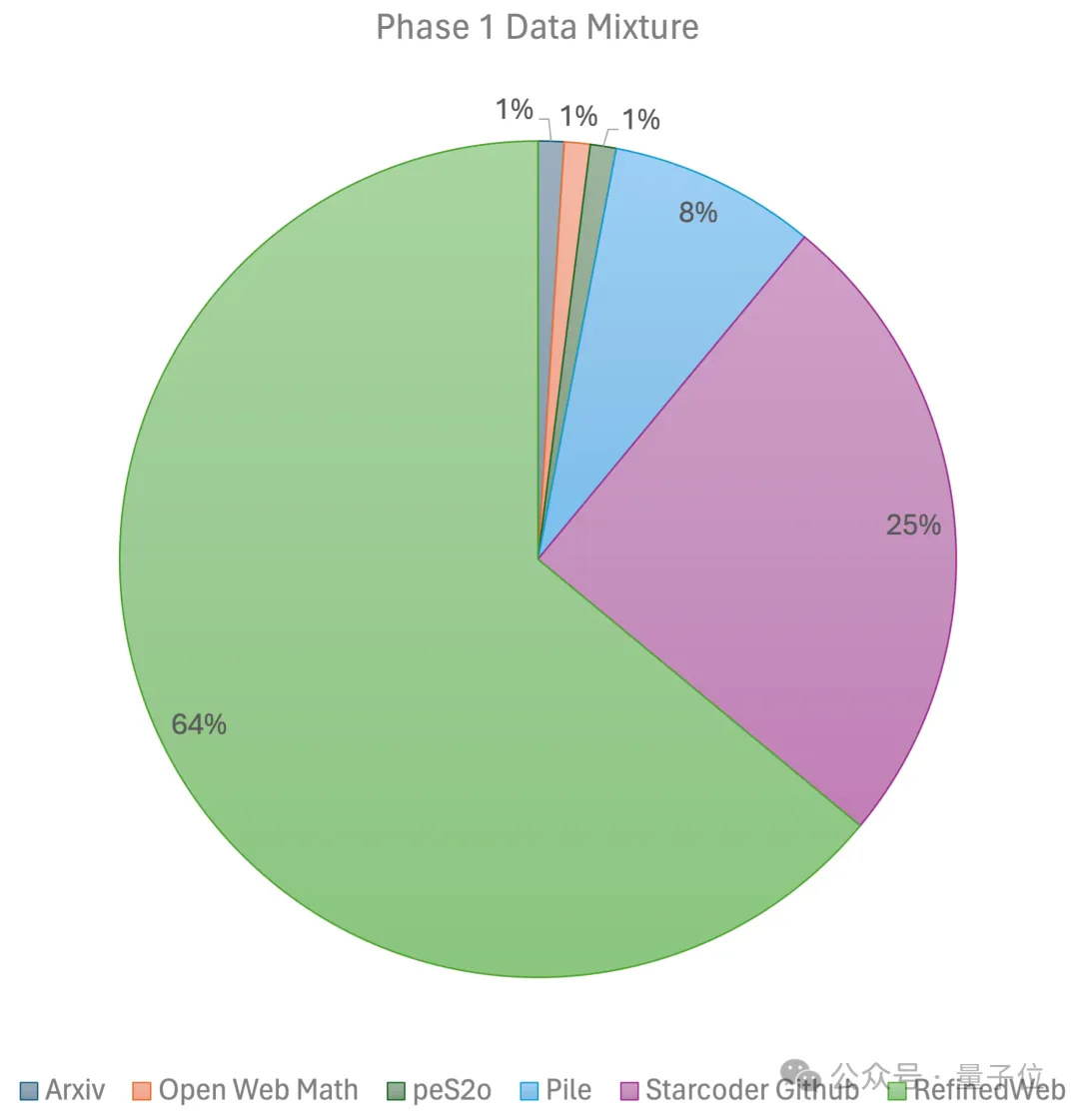
最終的に、チームは 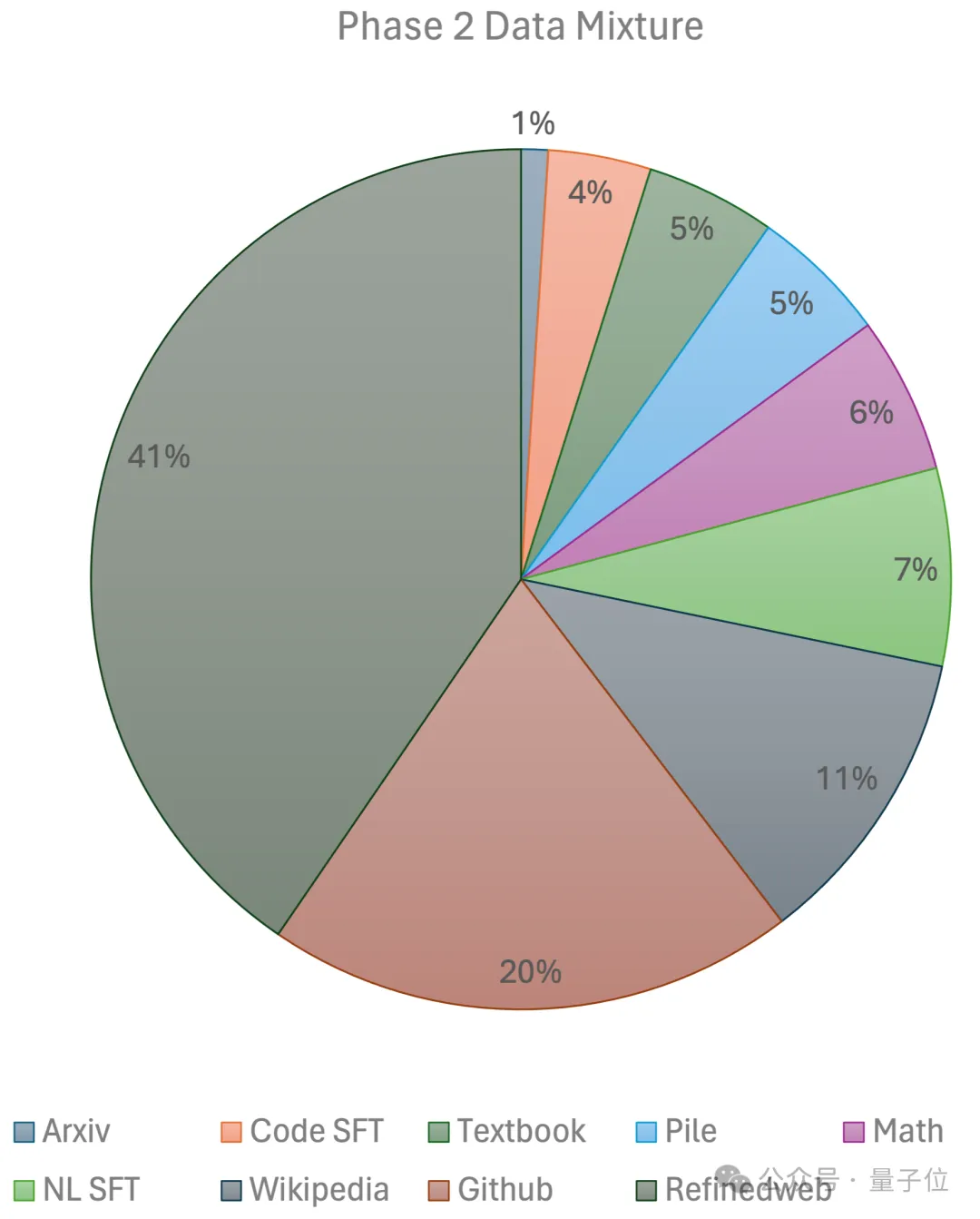
GPU クラスターを使用しました。 所要時間は 2 でした。数週間で約 80,000 ドルJetMoE-8B を入手します。 技術的な詳細については、近日公開される技術レポートで明らかにされる予定です。
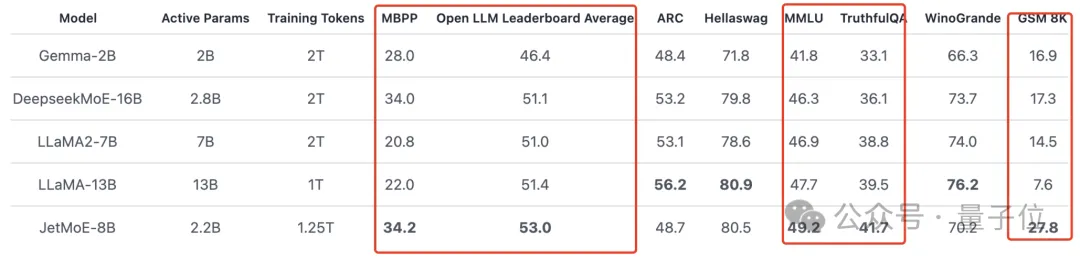
推論プロセス中、JetMoE-8B には 22 億の起動パラメータしかないため、計算コストが大幅に削減されます。同時に、良好なパフォーマンスも達成しました。 下の図に示すように:
JetMoE-8B は 8 つの評価ベンチマークで 5 つの sota(大規模モデル アリーナ Open LLM リーダーボードを含む)
を獲得し、LLaMA -13B を上回りました。 LLaMA2-7B と DeepseekMoE-16B。MT-Bench ベンチマークで 6.681 のスコアを獲得し、LLaMA2、Vicuna、および 130 億のパラメータを持つその他のモデルも上回りました。
著者紹介
JetMoE には合計 4 名の著者がいます: 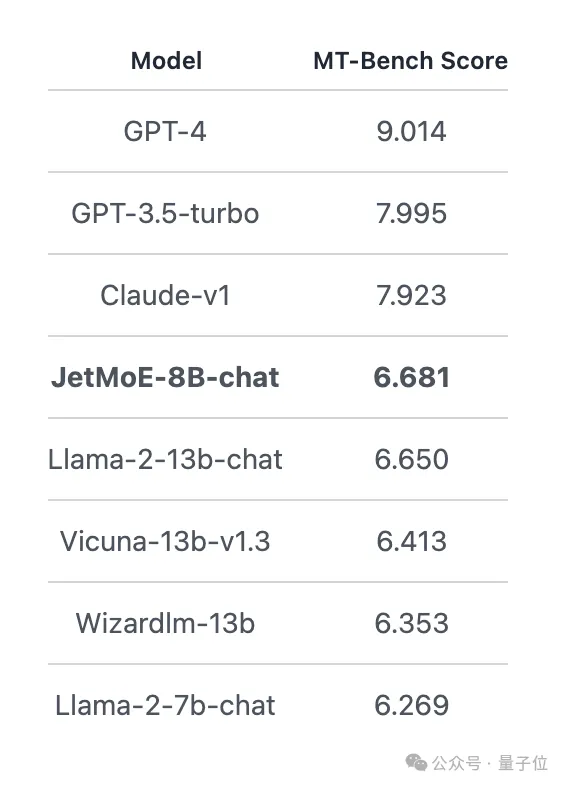
MIT-IBM ワトソン研究所の研究者、NLP の研究指導。
北杭大学を卒業し、学士号を取得し、ヨシュア・ベンジオが設立したミラ研究所で博士号を取得しました。
Ph.D . MIT 出身 現在勉強中の私の研究方向は、3D イメージングのためのデータ効率の高い機械学習です。
カリフォルニア大学バークレー校を学士号を取得して卒業した彼は、昨年の夏に学生研究者として MIT-IBM ワトソン研究所に加わりました。彼の指導者は Yikang Shen らでした。
プーリンティス博士は、北大の数学と計算機科学の研究に携わっており、以前も一緒でした。 Tri Dao で働く AI の非常勤研究者。
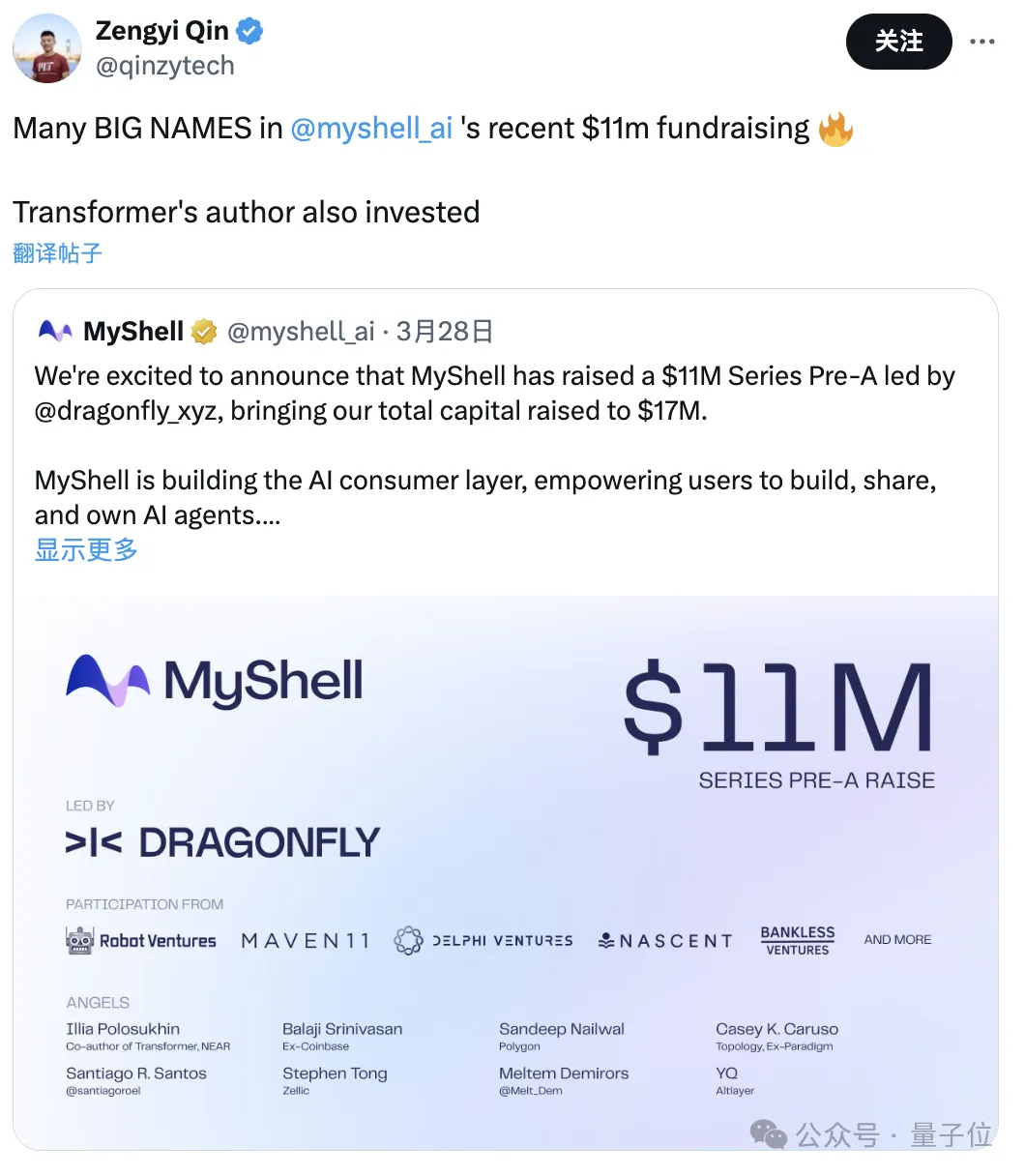
## の AI 研究開発ディレクター。 同社は、『Transformer』の著者を含む投資家から 1,100 万ドルを調達したところです。
以上がLlama-2大型モデルの訓練に10万ドル!すべての中国人が新たな環境省を構築、SDの元最高経営責任者賈陽青氏は見守るの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



