

フェデレーテッド ラーニングでは、データ プライバシーを保護しながら、複数の当事者を使用してモデルをトレーニングします。ただし、サーバーは参加者がローカルで実行するトレーニング プロセスを監視できないため、参加者がローカル トレーニング モデルを改ざんする可能性があり、バックドア攻撃など、フェデレーテッド ラーニング モデル全体にセキュリティ リスクが生じる可能性があります。
この記事では、防御的に保護されたトレーニング フレームワークの下でフェデレーテッド ラーニングに対してバックドア攻撃を開始する方法に焦点を当てています。この論文では、バックドア攻撃の埋め込みがいくつかのニューラル ネットワーク層とより密接に関連していることを発見し、これらの層をバックドア攻撃の重要な層と呼んでいます。 フェデレーション ラーニングでは、トレーニングに参加するクライアントはさまざまなデバイスに分散されており、それぞれが独自のモデルをトレーニングし、更新されたモデル パラメーターをサーバーにアップロードして集約します。トレーニングに参加しているクライアントは信頼できず、一定のリスクがあるため、サーバー
はバックドアの重要な層の発見に基づいており、この記事では、サーバーを攻撃することで防御アルゴリズムの検出をバイパスすることを提案しています。これにより、少数の参加者を制御して効率的なバックドア攻撃を実行できます。

論文のタイトル: バックドアクリティカル層を汚染することによるバックドアフェデレーション学習
論文のリンク: https://openreview.net/pdf?id=AJBGSVSTT2
コードリンク: https://github.com/zhmzm/Poisoning_Backdoor-critical_Layers_ Attack
メソッド
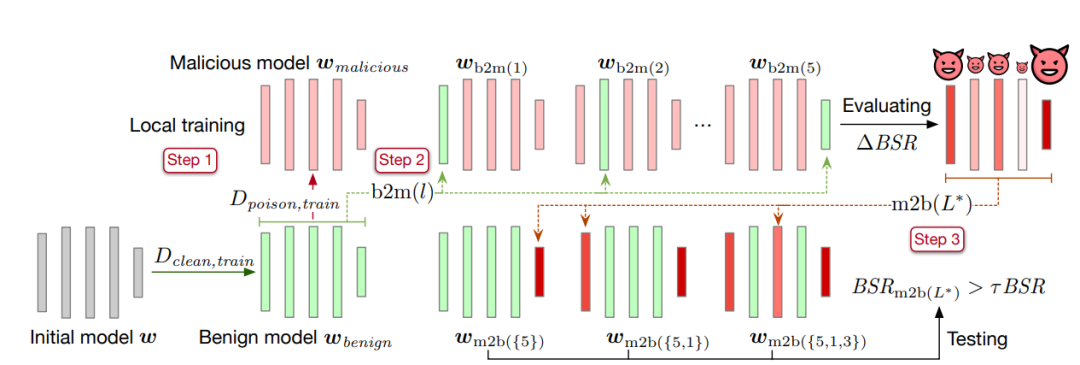
これ記事 バックドアの主要な層を特定するための層置換方法が提案されています。具体的な方法は次のとおりです。
最初のステップでは、収束するまでクリーンなデータ セットでモデルをトレーニングし、モデル パラメーターを無害なモデル 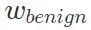 として保存します。次に、無害なモデルをコピーし、バックドアを含むデータ セットでトレーニングし、収束後、モデル パラメーターを保存し、悪意のあるモデル
として保存します。次に、無害なモデルをコピーし、バックドアを含むデータ セットでトレーニングし、収束後、モデル パラメーターを保存し、悪意のあるモデル 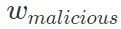 として記録します。
として記録します。
2 番目のステップは、無害なモデルのパラメーターのレイヤーをバックドアを含む悪意のあるモデルに置き換え、結果のモデルのバックドア攻撃の成功率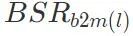 を計算することです。取得されたバックドア攻撃の成功率と悪意のあるモデルのバックドア攻撃成功率 BSR の差は ΔBSR であり、バックドア攻撃に対するこの層の影響を取得するために使用できます。ニューラル ネットワークの各層に対して同じ方法を使用すると、バックドア攻撃に対するすべての層の影響のリストを取得できます。
を計算することです。取得されたバックドア攻撃の成功率と悪意のあるモデルのバックドア攻撃成功率 BSR の差は ΔBSR であり、バックドア攻撃に対するこの層の影響を取得するために使用できます。ニューラル ネットワークの各層に対して同じ方法を使用すると、バックドア攻撃に対するすべての層の影響のリストを取得できます。
3 番目のステップは、バックドア攻撃への影響に従ってすべてのレイヤーを並べ替えることです。リストから最も大きな影響を持つレイヤーを選択し、それをバックドア攻撃キー レイヤー セット 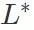 に追加し、悪意のあるモデルのバックドア攻撃キー レイヤー (セット
に追加し、悪意のあるモデルのバックドア攻撃キー レイヤー (セット  内のレイヤー) パラメーターを良性モデルに埋め込みます。取得したモデルのバックドア攻撃成功率
内のレイヤー) パラメーターを良性モデルに埋め込みます。取得したモデルのバックドア攻撃成功率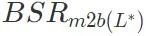 を計算します。バックドア攻撃の成功率が、設定されたしきい値 τ に悪意のあるモデルのバックドア攻撃成功率
を計算します。バックドア攻撃の成功率が、設定されたしきい値 τ に悪意のあるモデルのバックドア攻撃成功率 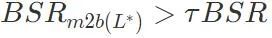 を掛けた値より大きい場合、アルゴリズムは停止します。満たされない場合は、条件が満たされるまで、リスト内の残りのレイヤーのうち最大のレイヤーをバックドア攻撃のキー レイヤー に追加し続けます。
を掛けた値より大きい場合、アルゴリズムは停止します。満たされない場合は、条件が満たされるまで、リスト内の残りのレイヤーのうち最大のレイヤーをバックドア攻撃のキー レイヤー に追加し続けます。
バックドア攻撃の主要な層のコレクションを取得した後、この記事では、バックドアの主要な層を攻撃することで防御方法の検出を回避する方法を提案します。さらに、このペーパーでは、他の良性モデルとの距離をさらに縮めるために、シミュレーション集約と良性モデル中心を導入します。 #########実験結果######
この記事では、CIFAR-10 および MNIST データ セットに対する複数の防御方法のバックドアに基づくキー層攻撃の有効性を検証します。実験では、攻撃の効果を測定する指標として、バックドア攻撃の成功率BSRと悪意のあるモデルの受け入れ率MAR(良性モデルの受け入れ率BAR)を使用します。
まず第一に、レイヤーベースの攻撃 LP 攻撃により、悪意のあるクライアントは高い選択率を得ることができます。以下の表に示すように、LP Attack は CIFAR-10 データセットで 90% の受信率を達成しました。これは、良性ユーザーの 34% よりもはるかに高い値です。
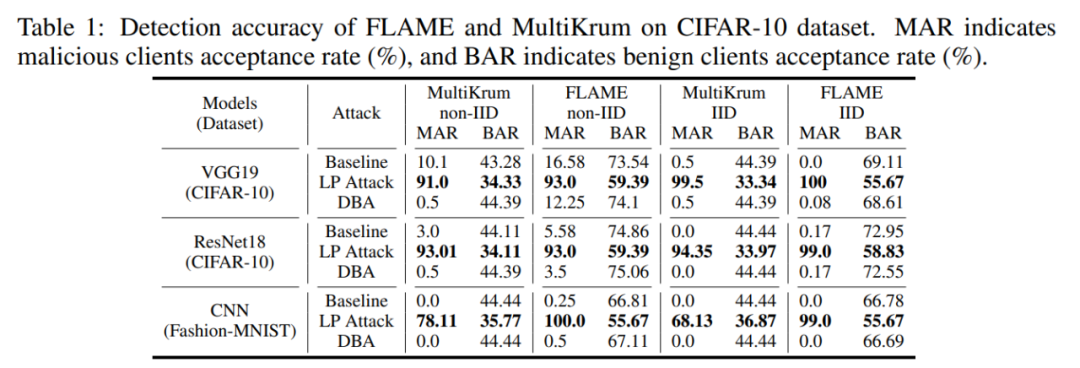
したがって、LP 攻撃は、悪意のあるクライアントが 10% しかない環境でも、高いバックドア攻撃の成功率を達成できます。以下の表に示すように、LP 攻撃は、さまざまなデータ セットとさまざまな防御方法の保護の下で、高いバックドア攻撃成功率の BSR を達成できます。
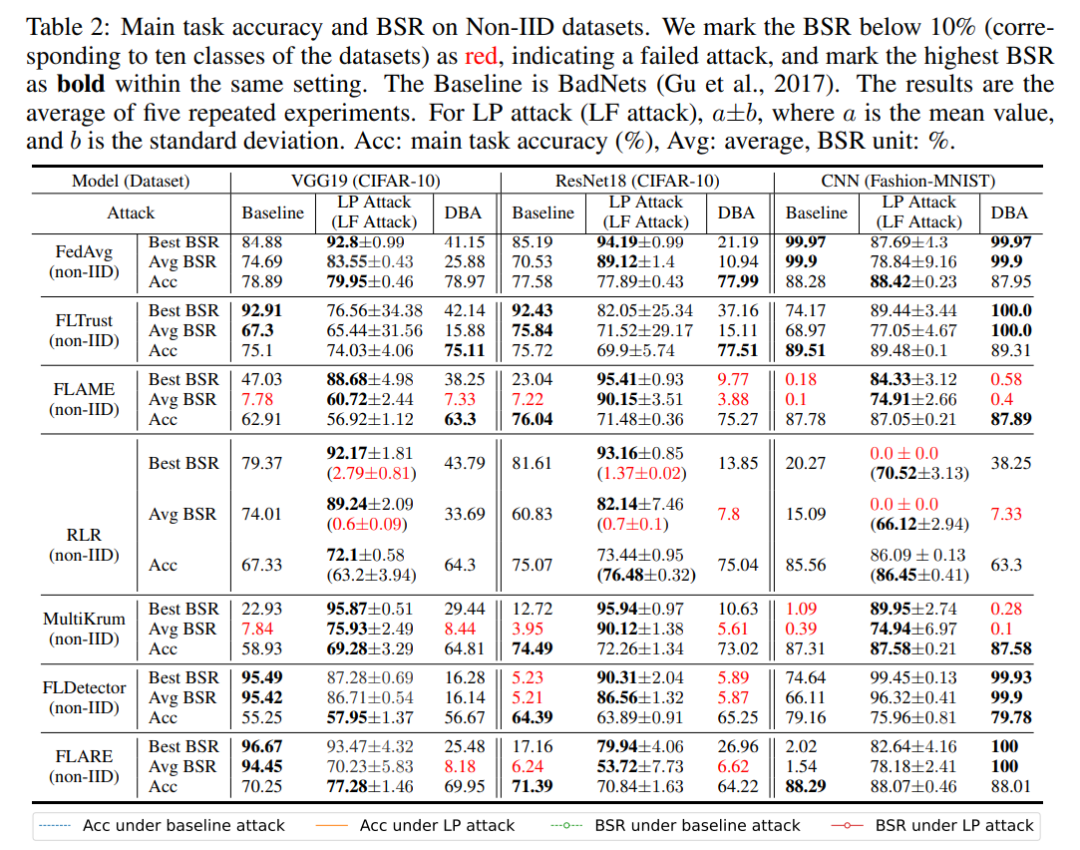
この記事では、アブレーション実験において、バックドア キー レイヤーと非バックドア キー レイヤーをそれぞれポイズニングし、2 つの実験のバックドア攻撃の成功率を測定しました。下図に示すように、同じ層数を攻撃した場合、非バックドア鍵層をポイズニングする成功率は、バックドア鍵層をポイズニングする成功率よりもはるかに低く、この記事のアルゴリズムが効果的なバックドア攻撃鍵を選択できることがわかります。層。
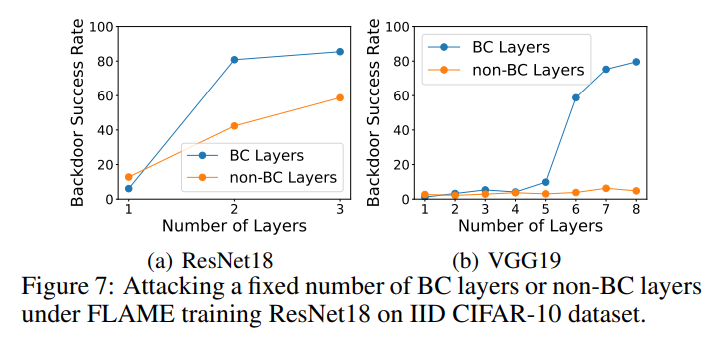
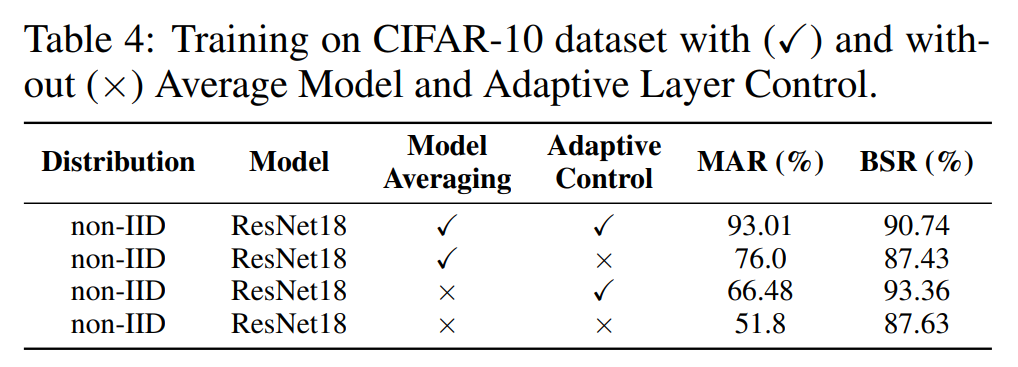
さらに、モデル集約モジュール Model Averaging と適応制御モジュール Adaptive Control によるアブレーション実験も行っています。以下の表に示すように、どちらのモジュールも選択率とバックドア攻撃の成功率を向上させており、これら 2 つのモジュールの有効性が証明されています。
概要
この記事では、バックドア攻撃がいくつかのレイヤーと密接に関連していることを発見し、主要なレイヤーを検索するアルゴリズムを提案しました。バックドア攻撃のこと。この論文では、バックドアを使用して主要なレイヤーを攻撃することにより、フェデレーテッド ラーニングの保護アルゴリズムに対するレイヤーごとの攻撃を提案します。提案された攻撃は、現在の 3 種類の防御方法の脆弱性を明らかにしており、将来的に Federated Learning のセキュリティを保護するには、より高度な防御アルゴリズムが必要になることを示しています。
著者紹介
Zhuang Haomin 華南理工大学を卒業し、学士号を取得し、ルイジアナ州立大学の IntelliSys 研究所で研究助手として働いていました。現在、ノートルダム大学で博士号取得に向けて勉強しています。主な研究方向は、バックドア攻撃と敵対的サンプル攻撃です。
以上がICLR 2024 | Federated Learning バックドア攻撃の重要なレイヤーをモデル化するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



