

APISR、2次元専用の超解像度AIモデル:オンラインで入手可能、CVPRによって選択

「ドラゴンボール」「ポケモン」「新世紀エヴァンゲリオン」など、前世紀に放送されたアニメ作品は、多くの人々の幼少期の思い出の一部であり、私たちに情熱、友情、そして夢をもたらしてきました。 . ビジュアルジャーニー。ある時点で、私たちは突然これらの子供時代の思い出を再訪したいという衝動に駆られることがありますが、残念なことに、これらの子供時代の思い出の認識率は非常に低く、ワイドスクリーンテレビで良好な視覚体験を作り出すことは不可能であることに気づくかもしれません。これらの子供時代の思い出を、HD 解像度のデジタル世界で育った子供たちと共有してください。
このような悪質な競争(そして潜在的な市場)に対しては、アニメ会社にリメイクを制作してもらうのも一つの方法です。この作業は人的・経済的に多大な費用がかかりますが、問題を無視して市場シェアを失うよりは価値があるかもしれません。
マルチモーダル人工知能のパフォーマンスはますます強力になっており、AI ベースの超解像技術を使用してアニメーションの解像度を向上させることは、検討する価値のある方向性となっています。この技術は、少数の低解像度画像から高解像度画像を再構成し、アニメーション画像をより鮮明で詳細なものにすることができます。この手法は、多数のサンプル データをトレーニングすることによって深度を利用します。最近、ミシガン大学、イェール大学、浙江大学の共同チームは、アニメーション制作プロセスを分析することにより、アニメーション超解像度タスク用のツール セットを作成しました。非常に実用的です。新しい方法。これには、データセット、モデル、およびいくつかの改善が含まれます。この研究は CVPR 2024 カンファレンスに採択されました。チームはまた、関連コードをオープンソース化し、Huggingface で試用モデルを開始しました。

- 論文のタイトル: APISR: アニメ制作にインスピレーションを得た現実世界のアニメの超解像度
- 論文のアドレス:https://arxiv.org/pdf/2403.01598.pdf
- コードアドレス:https://github.com/Kiteretsu77/APISR
- 試作モデル: https://huggingface.co/spaces/HikariDawn/APISR
- 以下の画像は、「ドラゴン」の第 1 話のスクリーンショットを使用して当サイトが試行した結果です。効果は肉眼でも確認できます。視認性は良好です。
 さらに、このテクノロジを使用してビデオの解像度を向上させようとした人もいますが、素晴らしい結果が得られています。
さらに、このテクノロジを使用してビデオの解像度を向上させようとした人もいますが、素晴らしい結果が得られています。
#この新しい手法の革新性を理解するために、まずアニメーションが一般的にどのように制作されるかを見てみましょう。
まず、人間が紙にスケッチし、コンピュータ生成画像 (CGI) 処理を通じて色付けされ、強化されます。これらの処理されたスケッチが接続されてビデオが作成されます。
ただし、描画プロセスは非常に手間がかかり、人間の目は動きに敏感ではないため、ビデオを合成する場合、業界標準では複数の連続フレームで 1 つの画像を再利用します。
このプロセスを分析することで、共同チームは、アニメーション超解像度モデルをトレーニングするためにビデオ モデルとビデオ データセットを使用する必要があるかどうか疑問に思わずにはいられませんでした。画像に対して超解像度を実行することは完全に可能です。そしてこれらの画像を連結します。
そこで彼らは、画像ベースの手法とデータセットを使用して、画像とビデオに適した統一された超解像度と復元のフレームワークを作成することにしました。
新しい提案手法アニメーション制作用画像超解像(API SR)データセット
チーム APIここでは、SR データセットが提案され、その収集と編成方法が簡単に紹介されます。この方法では、アニメーション ビデオの特性 (図 2 を参照) を利用し、ビデオから最も圧縮率が低く、最も情報量の多いフレームを選択できます。
 I フレーム ベースの画像コレクション: ビデオ圧縮には、ビデオ品質とデータ サイズの間のトレードオフが関係します。現在、多くのビデオ圧縮標準があり、それぞれに独自の複雑なエンジニアリング システムがありますが、それらはすべて同様のバックボーン設計を持っています。
I フレーム ベースの画像コレクション: ビデオ圧縮には、ビデオ品質とデータ サイズの間のトレードオフが関係します。現在、多くのビデオ圧縮標準があり、それぞれに独自の複雑なエンジニアリング システムがありますが、それらはすべて同様のバックボーン設計を持っています。
これらの特性により、各フレームの圧縮品質が異なります。ビデオ圧縮プロセスでは、いくつかのキー フレーム (つまり、I フレーム) を個別の圧縮単位として指定します。実際には、I フレームはシーンが変わるときの最初のフレームです。これらの I フレームは大量のデータを占有する可能性があります。非 I フレーム (つまり、P フレームと B フレーム) は圧縮率が高く、時間の経過に伴う変化を導入するために、圧縮プロセス中に I フレームを参照として使用する必要があります。図 3a に示すように、チームが収集したアニメーション ビデオでは、一般に I フレームのデータ サイズが非 I フレームのデータ サイズよりも大きく、実際に I フレームの品質が高くなります。したがって、チームはビデオ処理ツール ffmpeg を使用してビデオ ソースからすべての I フレームを抽出し、それらを初期データ プールとして使用しました。
Отбор на основе сложности изображения: команда проверила первоначальный пул I-кадров на основе оценки сложности изображения (ICA), которая является более подходящим индикатором для анимации, см. рисунок 4.

Набор данных API: команда вручную собрала 562 высококачественных аниме-видео. Затем на основе двух вышеуказанных шагов были собраны 10 кадров с наибольшим количеством очков из каждого видео. Затем была проведена некоторая фильтрация для удаления неподходящих изображений и в итоге был получен набор данных, содержащий 3740 изображений высокого качества. На рис. 5 показано несколько примеров изображений. Кроме того, на рисунке 3b мы также можем видеть преимущества набора данных API с точки зрения сложности изображения.

Вернемся к исходному разрешению 720P: Изучая процесс производства анимации, мы видим, что большая часть производства анимации использует формат 720P (то есть изображение имеет высоту 720 пикселей). ). Однако в реальных сценариях аниме часто ошибочно масштабируют до 1080P или других форматов в попытке стандартизировать мультимедийные форматы. Команда экспериментально обнаружила, что изменение размера всех аниме-изображений до исходного разрешения 720P обеспечивает плотность объектов, задуманную создателями, а также более четкие рисованные линии аниме и информацию CGI.
Практическая модель деградации для анимации
В реальных задачах со сверхвысоким разрешением разработка модели деградации очень важна. Основываясь на моделях деградации высокого порядка и недавней модели восстановления сжатия видео на основе изображений, команда предложила два улучшения, которые могут восстановить искаженные нарисованные от руки линии и различные артефакты сжатия, а также улучшить представление модели деградации. Рисунок 6а иллюстрирует эту модель деградации.
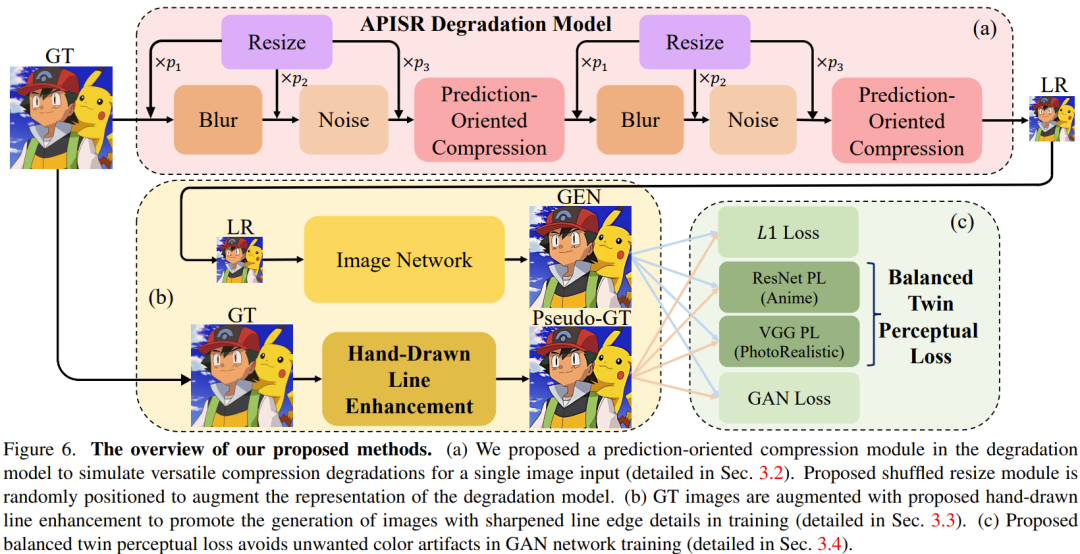
Сжатие, ориентированное на прогнозирование. Для задачи восстановления анимации артефактов сжатия видео использование моделей ухудшения качества изображения представляет собой сложную проблему. Это связано с тем, что метод сжатия формата изображения JPEG и принцип сжатия видео различны.
Чтобы справиться с такими трудностями, команда разработала модель сжатия, ориентированную на прогнозирование, используемую в модели ухудшения качества изображения. Для этого модуля требуется алгоритм сжатия видео для сжатия одного входного кадра.
При таком подходе модель деградации изображения способна синтезировать артефакты сжатия, аналогичные тем, которые наблюдаются при типичном многокадровом сжатии видео, как показано на рисунке 7. Затем, подавая эти синтезированные изображения в сеть изображений сверхвысокого разрешения, система может эффективно изучить закономерности различных артефактов сжатия и восстановить их.

Перетасуйте порядок изменения размера модулей: вырожденные модели в реальных областях сверхвысокого разрешения должны учитывать модули размытия, изменения размера, шума и сжатия. Размытие, шум и сжатие — это реальные артефакты, которые можно синтезировать с помощью четких математических моделей или алгоритмов. Однако логика модуля изменения размера совершенно другая. Изменение размера не является частью естественной генерации изображений, а введено специально для сверхразрешения парных наборов данных. Поэтому предыдущий модуль изменения размера фиксированного размера был не очень подходящим. Команда предложила более надежное и эффективное решение, которое предполагает случайное размещение операций изменения размера в разном порядке в вырожденной модели.
Улучшить нарисованные от руки линии для анимации
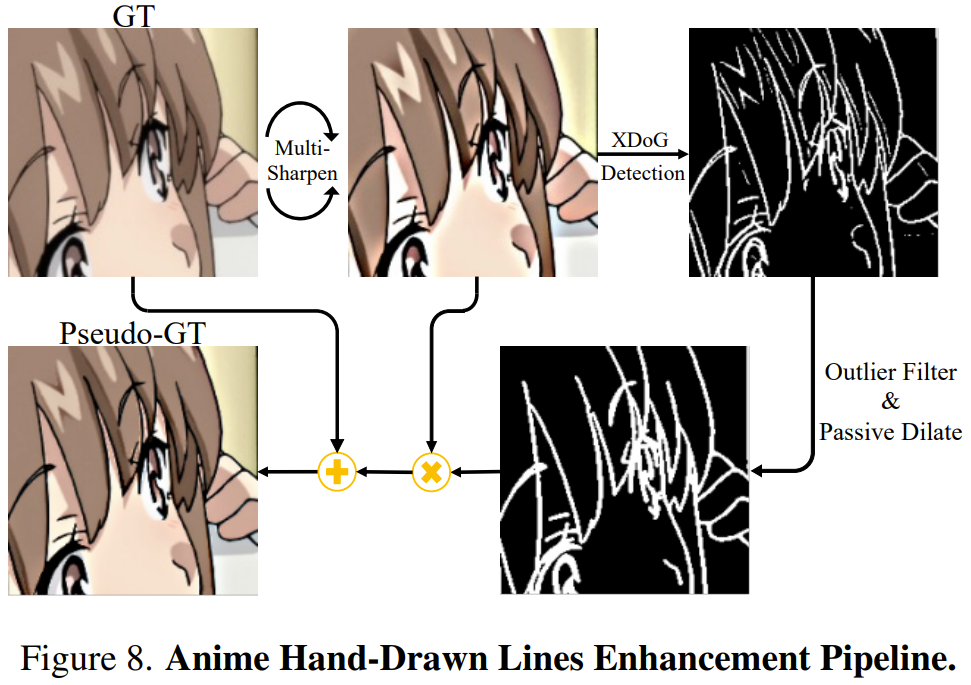
Команда решила напрямую извлечь информацию об уточненных нарисованных от руки линиях и сравнить ее с реальными данными (GT/ground -истина) слияния, образуя таким образом псевдо GT. Внедряя этот специально предназначенный улучшенный псевдо-GT в процесс обучения со сверхвысоким разрешением, сеть может генерировать четкие нарисованные от руки линии без введения дополнительных модулей нейронной сети или отдельных сетей постобработки.
Чтобы лучше извлекать нарисованные от руки линии, команда использовала XDoG — алгоритм извлечения эскизов, основанный на попиксельном ядре Гаусса, который может извлекать карты GT с острыми краями.
Однако карты ребер XDoG страдают от чрезмерного шума, содержат посторонние пиксели и изображения ломаных линий. Чтобы решить эту проблему, команда предложила метод фильтрации выбросов в сочетании со специально разработанным методом пассивного расширения. Таким образом, получается более связное и ненарушенное представление нарисованных от руки линий.
Команда экспериментально обнаружила, что чрезмерная резкость предварительно обработанного GT может сделать нарисованные от руки края линий более заметными, чем другие несущественные детали краев теней, что облегчает фильтру выбросов их различие. Для этого команда предложила сначала выполнить три раунда операций маскировки резкости на GT. Рисунок 8 дает простую иллюстрацию этого процесса.
Сбалансированная двойная потеря восприятия для анимации
Существует также проблема нежелательных цветовых артефактов, в основном из-за данных во время обучения несоответствие домена между генератором и потерей восприятия.
Чтобы решить эту проблему и компенсировать недостатки предыдущих методов, команда использовала предварительно обученный ResNet, который был обучен решению задачи классификации целей анимации на наборе данных Danbooru. Набор данных Danbooru — это база данных иллюстраций аниме, содержащая большие и насыщенные аннотации. Поскольку эта предварительно обученная сеть представляет собой ResNet50, а не VGG, команда также предложила аналогичное сравнение среднего уровня.
Однако, если вы используете только потери на основе ResNet, вы можете пострадать от плохих визуальных результатов. Это вызвано присущей набору данных Danbooru предвзятостью: большинство изображений в этом наборе данных представляют собой лица или относительно простые. , иллюстрация. Поэтому команда взвесила свое мнение и решила использовать реальные функции в качестве вспомогательного средства для управления потерей восприятия на основе ResNet во время обучения. Этот метод позволяет получить визуально приятное изображение, а также решить проблему нежелательных цветов.
Эксперимент
Детали реализации
В эксперименте команда использовала новый предложенный набор данных API в качестве сети изображений. набор обучающих данных. Что касается сети изображений, используется крошечная версия GRL с ближайшим модулем сверточной повышающей дискретизации.
Более подробную информацию и параметры см. в оригинальной статье.
Сравнение с лучшими на данный момент методами
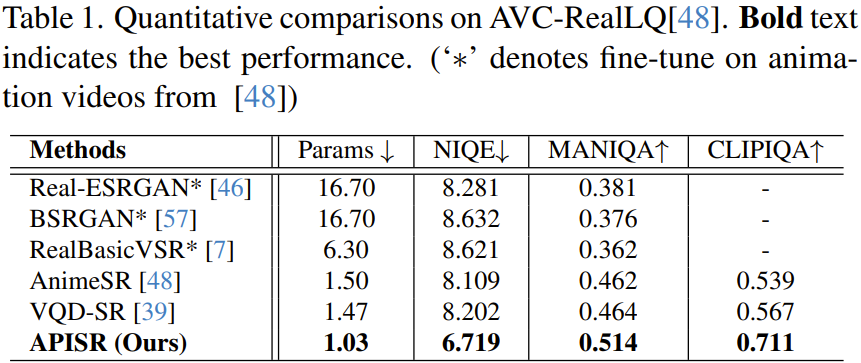
Команда количественно и качественно сравнила недавно предложенный APISR с некоторыми другими передовыми методами, включая Real-ESRGAN, BSRGAN, RealBasicVSR, AnimeSR. и ВКД-СР.
Количественное сравнение
Как показано в таблице 1, новая модель имеет наименьший размер сети, всего 1,03 млн параметров, но ее производительность по всем показателям превосходит все остальные. , метод.
Команда особо подчеркнула роль моделей сжатия, ориентированных на прогнозирование.
Кроме того, следует отметить, что новый метод достигает таких результатов только при сложности обучающей выборки 13,3% и 25% для AnimeSR и VQDSR соответственно. В основном это связано с введением оценки сложности изображения в процесс сортировки набора данных, что может улучшить эффект обучения представлению анимационных изображений путем выбора насыщенных информацией изображений. Более того, благодаря новой модели явной деградации обучение модели деградации не требуется.
Качественное сравнение
Как показано на рисунке 10, визуальное качество, полученное с помощью APISR, намного лучше, чем другие методы.

Команда также провела исследование абляции, чтобы проверить эффективность нового набора данных, модели деградации и расчета потерь. Подробности см. в исходном документе.
以上がAPISR、2次元専用の超解像度AIモデル:オンラインで入手可能、CVPRによって選択の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7461
7461
 15
1376
52
77
11
17
17
15
1376
52
77
11
17
17

 ControlNet の作者がまたヒット作を出しました!写真から絵画を生成し、2 日間で 1.4,000 個のスターを獲得する全プロセス
Jul 17, 2024 am 01:56 AM
ControlNet の作者がまたヒット作を出しました!写真から絵画を生成し、2 日間で 1.4,000 個のスターを獲得する全プロセス
Jul 17, 2024 am 01:56 AM
これも Tusheng のビデオですが、PaintsUndo は別の道を歩んでいます。 ControlNet 作者 LvminZhang が再び生き始めました!今回は絵画の分野を目指します。新しいプロジェクト PaintsUndo は、開始されて間もなく 1.4kstar を獲得しました (まだ異常なほど上昇しています)。プロジェクトアドレス: https://github.com/lllyasviel/Paints-UNDO このプロジェクトを通じて、ユーザーが静止画像を入力すると、PaintsUndo が線画から完成品までのペイントプロセス全体のビデオを自動的に生成するのに役立ちます。 。描画プロセス中の線の変化は驚くべきもので、最終的なビデオ結果は元の画像と非常によく似ています。完成した描画を見てみましょう。
 RLHF から DPO、TDPO に至るまで、大規模なモデル アライメント アルゴリズムはすでに「トークンレベル」になっています
Jun 24, 2024 pm 03:04 PM
RLHF から DPO、TDPO に至るまで、大規模なモデル アライメント アルゴリズムはすでに「トークンレベル」になっています
Jun 24, 2024 pm 03:04 PM
AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com 人工知能の開発プロセスにおいて、大規模言語モデル (LLM) の制御とガイダンスは常に中心的な課題の 1 つであり、これらのモデルが両方とも確実に機能することを目指しています。強力かつ安全に人類社会に貢献します。初期の取り組みは人間のフィードバックによる強化学習手法に焦点を当てていました (RL
 オープンソース AI ソフトウェア エンジニアのリストのトップに立つ UIUC のエージェントレス ソリューションは、SWE ベンチの実際のプログラミングの問題を簡単に解決します
Jul 17, 2024 pm 10:02 PM
オープンソース AI ソフトウェア エンジニアのリストのトップに立つ UIUC のエージェントレス ソリューションは、SWE ベンチの実際のプログラミングの問題を簡単に解決します
Jul 17, 2024 pm 10:02 PM
AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出電子メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com この論文の著者は全員、イリノイ大学アーバナ シャンペーン校 (UIUC) の Zhang Lingming 教師のチームのメンバーです。博士課程4年、研究者
 OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
AIモデルによって与えられた答えがまったく理解できない場合、あなたはそれをあえて使用しますか?機械学習システムがより重要な分野で使用されるにつれて、なぜその出力を信頼できるのか、またどのような場合に信頼してはいけないのかを実証することがますます重要になっています。複雑なシステムの出力に対する信頼を得る方法の 1 つは、人間または他の信頼できるシステムが読み取れる、つまり、考えられるエラーが発生する可能性がある点まで完全に理解できる、その出力の解釈を生成することをシステムに要求することです。見つかった。たとえば、司法制度に対する信頼を築くために、裁判所に対し、決定を説明し裏付ける明確で読みやすい書面による意見を提供することを求めています。大規模な言語モデルの場合も、同様のアプローチを採用できます。ただし、このアプローチを採用する場合は、言語モデルが
 公理的トレーニングにより、LLM は因果推論を学習できます。6,700 万個のパラメータ モデルは、1 兆個のパラメータ レベル GPT-4 に匹敵します。
Jul 17, 2024 am 10:14 AM
公理的トレーニングにより、LLM は因果推論を学習できます。6,700 万個のパラメータ モデルは、1 兆個のパラメータ レベル GPT-4 に匹敵します。
Jul 17, 2024 am 10:14 AM
LLM に因果連鎖を示すと、LLM は公理を学習します。 AI はすでに数学者や科学者の研究を支援しています。たとえば、有名な数学者のテレンス タオは、GPT などの AI ツールを活用した研究や探索の経験を繰り返し共有しています。 AI がこれらの分野で競争するには、強力で信頼性の高い因果推論能力が不可欠です。この記事で紹介する研究では、小さなグラフでの因果的推移性公理の実証でトレーニングされた Transformer モデルが、大きなグラフでの推移性公理に一般化できることがわかりました。言い換えれば、Transformer が単純な因果推論の実行を学習すると、より複雑な因果推論に使用できる可能性があります。チームが提案した公理的トレーニング フレームワークは、デモンストレーションのみで受動的データに基づいて因果推論を学習するための新しいパラダイムです。
 リーマン予想の大きな進歩!陶哲軒氏はMITとオックスフォードの新しい論文を強く推薦し、37歳のフィールズ賞受賞者も参加した
Aug 05, 2024 pm 03:32 PM
リーマン予想の大きな進歩!陶哲軒氏はMITとオックスフォードの新しい論文を強く推薦し、37歳のフィールズ賞受賞者も参加した
Aug 05, 2024 pm 03:32 PM
最近、2000年代の7大問題の一つとして知られるリーマン予想が新たなブレークスルーを達成した。リーマン予想は、数学における非常に重要な未解決の問題であり、素数の分布の正確な性質に関連しています (素数とは、1 とそれ自身でのみ割り切れる数であり、整数論において基本的な役割を果たします)。今日の数学文献には、リーマン予想 (またはその一般化された形式) の確立に基づいた 1,000 を超える数学的命題があります。言い換えれば、リーマン予想とその一般化された形式が証明されれば、これらの 1,000 を超える命題が定理として確立され、数学の分野に重大な影響を与えることになります。これらの命題の一部も有効性を失います。 MIT数学教授ラリー・ガスとオックスフォード大学から新たな進歩がもたらされる
 arXiv 論文は「弾幕」として投稿可能、スタンフォード alphaXiv ディスカッション プラットフォームはオンライン、LeCun は気に入っています
Aug 01, 2024 pm 05:18 PM
arXiv 論文は「弾幕」として投稿可能、スタンフォード alphaXiv ディスカッション プラットフォームはオンライン、LeCun は気に入っています
Aug 01, 2024 pm 05:18 PM
乾杯!紙面でのディスカッションが言葉だけになると、どんな感じになるでしょうか?最近、スタンフォード大学の学生が、arXiv 論文のオープン ディスカッション フォーラムである alphaXiv を作成しました。このフォーラムでは、arXiv 論文に直接質問やコメントを投稿できます。 Web サイトのリンク: https://alphaxiv.org/ 実際、URL の arXiv を alphaXiv に変更するだけで、alphaXiv フォーラムの対応する論文を直接開くことができます。この Web サイトにアクセスする必要はありません。その中の段落を正確に見つけることができます。論文、文: 右側のディスカッション エリアでは、ユーザーは論文のアイデアや詳細について著者に尋ねる質問を投稿できます。たとえば、次のような論文の内容についてコメントすることもできます。
 無制限のビデオ生成、計画と意思決定、次のトークン予測とフルシーケンス拡散の拡散強制統合
Jul 23, 2024 pm 02:05 PM
無制限のビデオ生成、計画と意思決定、次のトークン予測とフルシーケンス拡散の拡散強制統合
Jul 23, 2024 pm 02:05 PM
現在、次のトークン予測パラダイムを使用した自己回帰大規模言語モデルが世界中で普及していると同時に、インターネット上の多数の合成画像やビデオがすでに拡散モデルの威力を示しています。最近、MITCSAIL の研究チーム (そのうちの 1 人は MIT の博士課程学生、Chen Boyuan です) は、全系列拡散モデルとネクスト トークン モデルの強力な機能を統合することに成功し、トレーニングおよびサンプリング パラダイムである拡散強制 (DF) を提案しました。 )。論文タイトル:DiffusionForcing:Next-tokenPredictionMeetsFull-SequenceDiffusion 論文アドレス:https:/
