

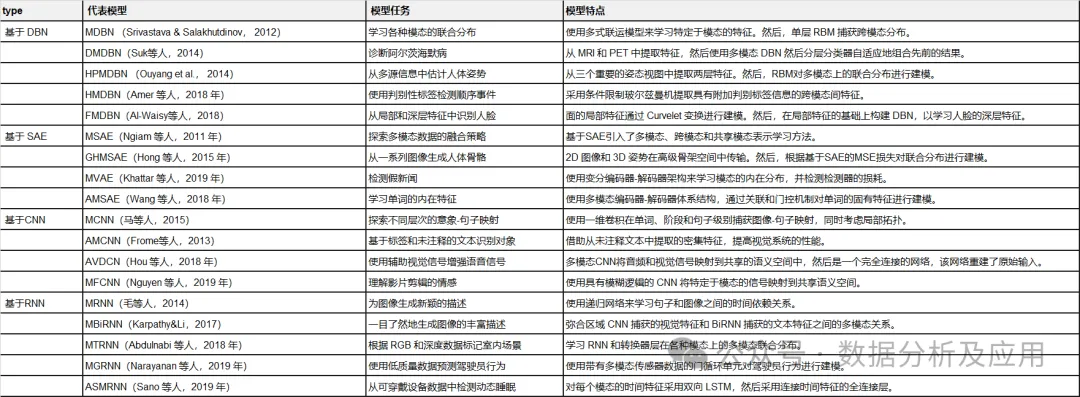
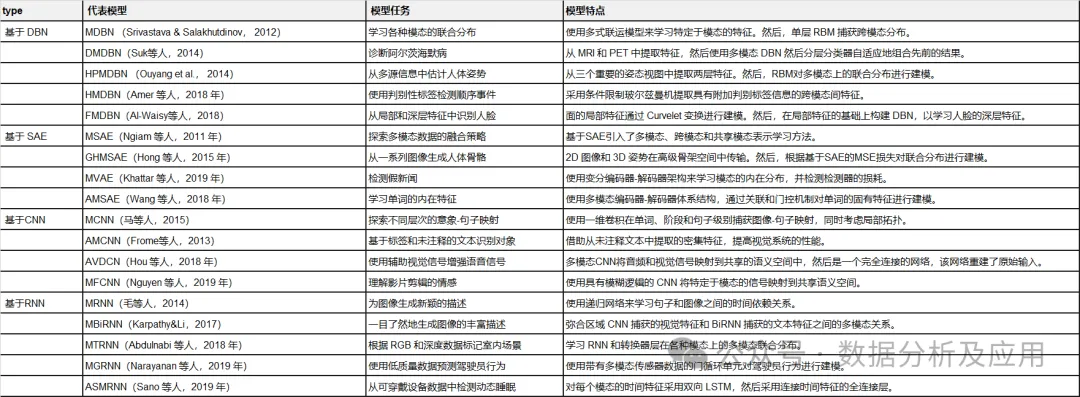
完成度高すぎ!マルチモーダルディープラーニングのレビュー!

1. はじめに
私たちの世界の経験はマルチモーダルです – 私たちは物を見たり、音を聞いたり、質感を感じたり、匂いを嗅いだり、味わったりします。モダリティとは、特定の状態が発生または経験される方法を指し、リサーチクエスチョンに複数のモダリティが含まれる場合、それはマルチモーダルとして特徴付けられます。 AI が私たちの周囲の世界の理解を進めるためには、これらのマルチモーダルな信号を同時に解釈できる必要があります。
たとえば、画像はタグやテキストの説明に関連付けられることが多く、テキストには記事の中心的なアイデアをより明確に表現するための画像が含まれています。モダリティが異なれば、統計的特性も大きく異なります。これらのデータはマルチモーダル ビッグ データと呼ばれ、豊富なマルチモーダルおよびクロスモーダル情報が含まれており、従来のデータ融合手法に大きな課題をもたらしています。
このレビューでは、これらのマルチモーダルなビッグデータを融合するための画期的な深層学習モデルをいくつか紹介します。マルチモーダルなビッグデータの研究がますます進んでいますが、対処する必要のある課題がまだいくつかあります。したがって、この記事 では、マルチモーダル データ フュージョンのためのディープ ラーニングのレビューを提供し、読者 (元のコミュニティに関係なく) にマルチモーダル ディープ ラーニング フュージョン手法の基本原理を提供し、ディープ ラーニングへの新しいマルチモーダル アプローチを刺激することを目的としています。融合技術。
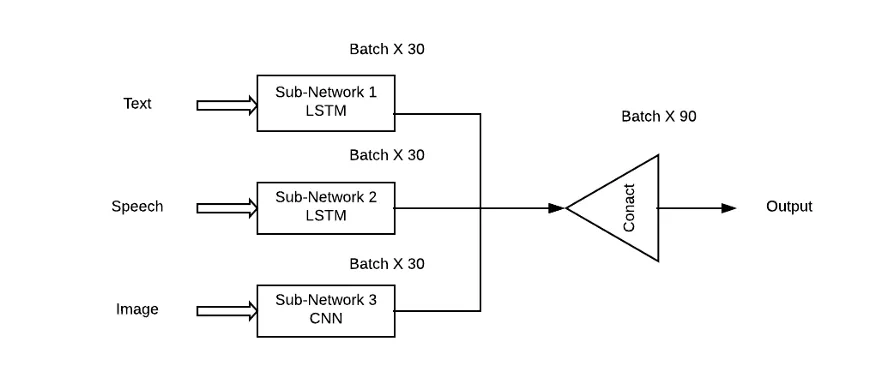
この アプローチの問題は、すべてのサブネットワーク/モードに同等の重要性を与えることですが、現実の状況ではこれはありそうもないことです。の。ここでは、各入力モダリティが出力予測に対して学習寄与 (シータ) を持つことができるように、サブネットワークの重み付けされた組み合わせが必要です。 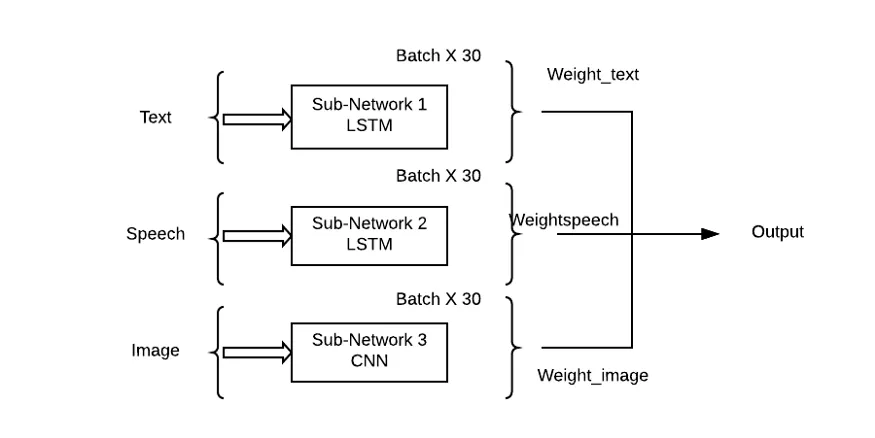
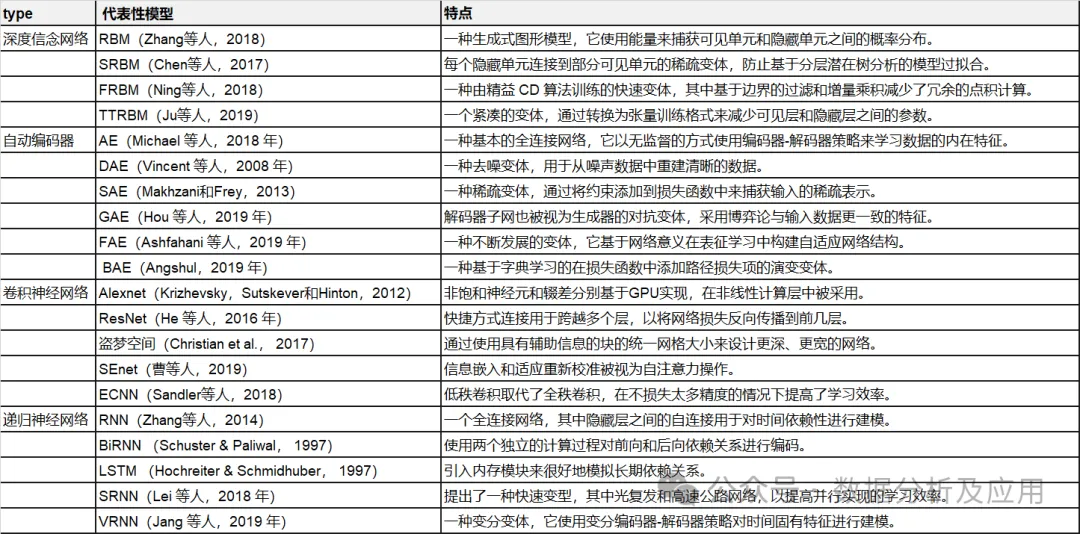
このセクションでは、代表的なディープ ラーニング アーキテクチャを紹介します。マルチモーダルデータ融合深層学習モデル向け。具体的には、ディープ アーキテクチャ、フィードフォワード計算、バックプロパゲーション計算の定義、および典型的なバリエーションが示されています。代表的な機種をまとめました。
表 1: 代表的な深層学習モデルの概要。
制限付きボルツマン マシン (RBM) は、次の基本ブロックです。深い信念ネットワーク (Zhang、Ding、Zhang、および Xue、2018; Bengio、2009)。 RBM はボルツマン マシンの特別な変形であり (図 1 を参照)、可視層と非表示層で構成されます。可視層と非表示層の間には完全な接続がありますが、同じ内部のユニット間には接続がありません。層。 RBM は、エネルギー関数を使用して可視ユニットと隠れユニット間の確率分布を取得する生成モデルでもあります。エネルギー関数の導関数を使用することにより、可視ユニットと隠れユニット間のユニットの確率分布を計算できます。 RBM は、個々の要素と隠れユニット間の確率分布をキャプチャできます。 RBM では、同じレイヤー内のセル間に接続がないことを除き、セル間に接続はなく、すべてのセルが完全な接続を通じて接続されます。 RBM はまた、エネルギー関数を使用して、可視ユニットと非表示ユニット間の確率分布を計算します。 RBM の確率関数を使用すると、ユニット間の確率分布を把握できます。
最近、パフォーマンスを向上させるためにいくつかの高度な RBM が提案されています。たとえば、ネットワークの過剰適合を回避するために、Chen、Zhang、Yeung、Chen (2017) は、階層型潜在ツリーに基づいてネットワーク構造を学習するスパース ボルツマン マシンを設計しました。 Ning、Pittman、Shen (2018) は、高速コントラスト発散アルゴリズムを RBM に導入しました。このアルゴリズムでは、境界ベースのフィルター処理とデルタ積を使用して、計算における冗長な内積計算を削減します。多次元データの内部構造を保護するために、Ju et al. (2019) は、多次元データに隠された高レベルの分布を学習するためのテンソル RBM を提案し、次元性の呪いを回避するためにテンソル分解が使用されます。
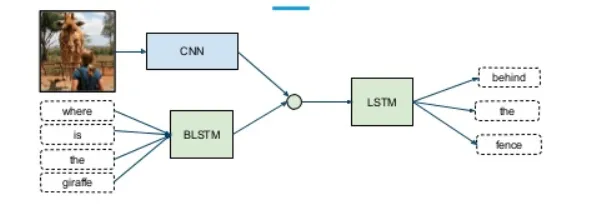
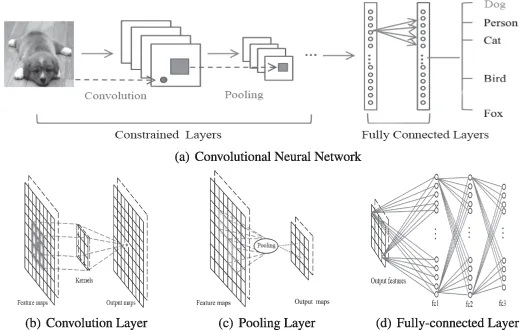
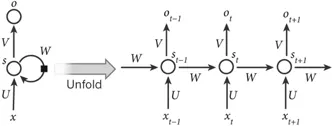
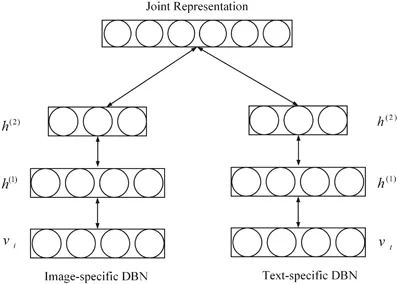
DBM — это типичная глубокая архитектура, состоящая из нескольких RBM (Хинтон и Салахутдинов, 2006). Это генеративная модель, основанная на стратегиях предварительного обучения и точной настройки, которая может использовать энергию для определения распределения соединений между видимыми объектами и соответствующими метками. При предварительном обучении каждый скрытый уровень жадно моделируется как RBM, обученный неконтролируемой политике. После этого каждый скрытый уровень дополнительно обучается с помощью различительной информации обучающих меток в контролируемой стратегии. DBN использовались для решения проблем во многих областях, таких как уменьшение размерности данных, обучение представлению и семантическое хеширование. Типичный DBM показан на рисунке 1. Рисунок 1. Рисунок 2: DBN и SAE — полносвязные нейронные сети. В обеих сетях каждый нейрон скрытого слоя связан с каждым нейроном предыдущего слоя, и такая топология создает большое количество связей. Чтобы обучить веса этих связей, полностью связанным нейронным сетям требуется большое количество обучающих объектов, чтобы избежать переобучения и недостаточного подбора, что требует больших вычислительных ресурсов. Кроме того, полносвязная топология не учитывает информацию о положении объектов, содержащуюся между нейронами. Следовательно, полносвязные глубокие нейронные сети (DBN, SAE и их варианты) не могут обрабатывать многомерные данные, особенно большие изображения и большие аудиоданные. Сверточная нейронная сеть — это специальная глубокая сеть, которая учитывает локальную топологию данных (Li, Xia, Du, Lin, & Samat, 2017; Sze, Chen, Yang и Эмер, 2017). Сверточные нейронные сети включают в себя полностью связные сети и сети с ограничениями, содержащие сверточные слои и слои пула. Сети с ограничениями используют операции свертки и объединения для достижения локальных восприимчивых полей и уменьшения параметров. Подобно DBN и SAE, сверточные нейронные сети обучаются с помощью алгоритма стохастического градиентного спуска. Он добился большого прогресса в распознавании медицинских изображений (Maggiori, Tarabalka, Charpiat и Alliez, 2017) и семантическом анализе (Hu, Lu, Li и Chen, 2014). Репрезентативная CNN показана на рисунке 3. Рисунок 3. Рекуррентная нейронная сеть — это архитектура нейронных вычислений, которая обрабатывает последовательные данные (Martens & Sutskever, 2011; Sutskever, Martens & Hinton, 2011). В отличие от архитектур с глубоким перенаправлением (например, DBN, SAE и CNN), он не только сопоставляет входные шаблоны с выходными результатами, но также передает скрытые состояния на выходные данные, используя связи между скрытыми блоками (Graves & Schmidhuber, 2008). Используя эти скрытые связи, RNN моделируют временные зависимости, тем самым разделяя параметры между объектами во временном измерении. Он применялся в различных областях, таких как анализ речи (Mulder, Bethard & Moens, 2015), субтитров к изображениям (Xu et al., 2015) и языковой перевод (Graves & Jaitly, 2014), достигая превосходной производительности. Подобно архитектуре глубокого прямого распространения, его вычисления также включают этапы прямого прохождения и обратного распространения ошибки. При прямом вычислении RNN одновременно получает входные и скрытые состояния. При расчете обратного распространения ошибки используется временной алгоритм обратного распространения ошибки для временного шага. На рисунке 4 показан репрезентативный RNN. Рисунок 4: В этом разделе мы рассматриваем наиболее репрезентативные мультимодальные модели глубокого обучения слияния данных с точки зрения модельных задач, структур моделей и наборов оценочных данных. Они разделены на четыре категории в зависимости от используемой архитектуры глубокого обучения. В таблице 2 приведены типичные модели мультимодального глубокого обучения. Таблица 2: Краткое описание репрезентативной мультимодальной модели глубокого обучения. Сривастава и Салахутдинов (2012) предложили мультимодальную генеративную модель, основанную на модели глубокого обучения Больцмана путем подгонки мультимодальных данных в различных модальностях (таких как изображения, текст и аудио) совместного распределения для изучения мультимодальных представлений. Каждый модуль предлагаемой мультимодальной ДБН инициализируется неконтролируемым послойным способом и использует метод аппроксимации на основе MCMC. Модельное обучение. Для оценки изученных мультимодальных представлений выполняется большое количество задач, таких как создание задач по созданию недостающих модальностей, выведение задач о совместном представлении и различительных задач. Эксперименты проверяют, удовлетворяет ли изученное мультимодальное представление требуемым свойствам. #Для эффективной диагностики болезни Альцгеймера на ранней стадии проведена нейровизуализация Сука, Ли, Шена и болезни Альцгеймера. Initiative (2014) предложила мультимодальную модель Больцмана, которая может объединять дополнительные знания из мультимодальных данных. В частности, чтобы устранить ограничения, вызванные методами мелкого изучения функций, DBN используется для изучения глубоких представлений каждой модальности путем перевода представлений, специфичных для предметной области, в иерархические абстрактные представления. Затем однослойный RBM строится на объединенных векторах, которые представляют собой линейные комбинации иерархических абстрактных представлений каждой модальности. Он используется для изучения мультимодальных представлений путем построения совместного распределения различных мультимодальных функций. Наконец, предложенная модель тщательно оценивается на наборе данных ADNI на основе трех типичных диагнозов, что обеспечивает высочайшую диагностическую точность. Чтобы точно оценить позу человека, Оуян, Чу и Ван (2014) разработали глубину с несколькими источниками Изучите модель, которая изучает мультимодальные представления на основе типов смесей, показателей внешнего вида и модальностей деформации путем извлечения совместного распределения моделей тела в пространстве высокого порядка. В глубокой модели с несколькими источниками позы человека три широко используемые модальности извлекаются из моделей структуры изображения, которые объединяют различные части тела на основе теории условного случайного поля. Для получения мультимодальных данных модель графической структуры обучается с помощью линейной машины опорных векторов. Затем каждый из трех признаков вводится в двухслойную ограниченную модель Больцмана, чтобы получить абстрактное представление пространства поз высокого порядка из представления, специфичного для конкретного признака. Благодаря неконтролируемой инициализации каждая ограниченная модель Больцмана, специфичная для конкретной модальности, отражает внутреннее представление глобального пространства. Затем RBM используется для дальнейшего изучения представления позы человека на основе конкатенированных векторов типов смешивания высокого уровня, оценок внешнего вида и представлений деформации. Для обучения предлагаемой модели глубокого обучения с несколькими источниками разработана целевая функция для конкретной задачи, учитывающая как положение тела, так и обнаружение человека. Предложенная модель проверена на LSP, PARSE и UIUC и дает улучшения до 8,6%. Недавно были предложены некоторые новые мультимодальные модели обучения функциям на основе DBN. Например, Амер, Шилдс, Сиддики и Тамракар (2018) предложили гибридный подход для последовательного обнаружения событий, в котором условный RBM использовался для извлечения модальных и кросс-модальных признаков с дополнительной информацией о различительных метках. Аль-Вайси, Кахваджи, Ипсон и Аль-Фахдави (2018) представили мультимодальный подход к распознаванию лиц. В этом подходе модель на основе DBN используется для моделирования мультимодального распределения локальных объектов, созданных вручную, полученных с помощью преобразования Curvelet, которое может объединить преимущества локальных объектов и глубоких объектов (Al-Waisy et al., 2018). Эти мультимодальные модели на основе DBN используют вероятностные графовые сети для преобразования представлений, специфичных для модальности, в общие семантические функции в пространстве . Затем совместное распределение модальностей моделируется на основе характеристик общего пространства. Эти мультимодальные модели на основе DBN являются более гибкими и надежными в стратегиях обучения без учителя, с полуконтролем и с учителем. Они идеально подходят для сбора информативных характеристик входных данных. Однако они игнорируют пространственную и временную топологию мультимодальных данных. Ngiam et al Мультимодальный глубокое обучение, предложенное (2011), является наиболее репрезентативной моделью глубокого обучения для мультимодального объединения данных на основе многослойных автокодировщиков (SAE). Эта модель глубокого обучения направлена на решение двух проблем объединения данных: обучение кросс-модальному и совместно-модальному представлению. Первый направлен на использование знаний из других модальностей для получения лучших одномодальных представлений, а второй изучает сложные корреляции между модальностями на промежуточном уровне. Для достижения этих целей разработаны три сценария обучения — мультимодальное, кросс-модальное и совместно-модальное обучение, как показано в Таблице 3 и Рисунке 6. Рис. 6. Таблица 3: Настройки для мультимодального обучения.
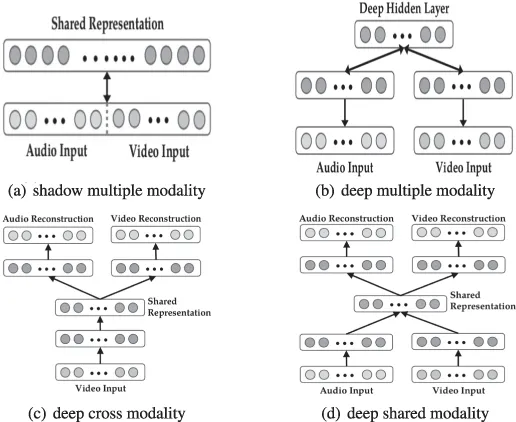
##В сценариях мультимодального обучения аудиоспектрограммы и видеокадры соединяются в векторы линейным образом. Объединенные векторы подаются в разреженную ограниченную машину Больцмана (SRBM) для изучения корреляции между аудио и видео. Эта модель может изучать только теневые совместные представления нескольких модальностей, поскольку корреляции неявны в многомерном представлении исходного уровня, и однослойный SRBM не может их моделировать. Вдохновленные этим, объединенные векторы представлений среднего уровня вводятся в SRBM для моделирования корреляции нескольких модальностей, тем самым демонстрируя лучшую производительность. В сценарии кросс-модального обучения предлагается многомодальный автокодировщик с глубоким стеком для явного изучения корреляции между модальностями. В частности, как аудио, так и видео представлены в качестве входных данных при обучении функций, и только один из них используется в модели при контролируемом обучении и тестировании. Модель инициализируется методом мультимодального обучения и может хорошо моделировать кросс-модальные отношения.
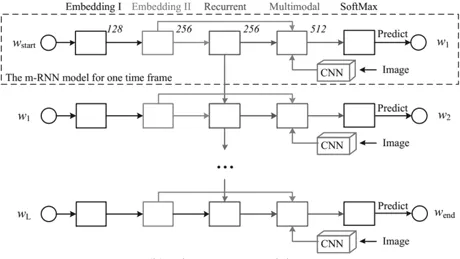
##########) В общем модальном представлении, мотивированном шумоподавлением автокодировщиков, вводятся мультимодальные автокодеры с глубоким стеком, специфичные для модальности, для изучения взаимосвязи между модальностями совместного представления, особенно когда одна модальность отсутствует. Набор обучающих данных, увеличенный за счет замены одной из модальностей на ноль, вводится в модель для обучения функциям. ############Наконец, подробные эксперименты проводятся с наборами данных CUAVE и AVLetters для оценки эффективности мультимодального глубокого обучения при обучении функций для конкретных задач. ############3.2.2 Пример 5 ############Чтобы генерировать визуально и семантически достоверные человеческие скелеты из последовательности изображений (особенно видео), Hong Ю, Ван, Тао и Ван (2015) предложили мультимодальный глубокий автокодировщик для фиксации взаимосвязей между изображениями и позами. В частности, предлагаемый мультимодальный глубокий автокодировщик обучается с помощью трехэтапной стратегии для построения нелинейного сопоставления между 2D-изображениями и 3D-позами. На этапе объединения функций низкоранговое представление многовидового гиперграфа используется для построения внутреннего 2D-представления из ряда функций изображения (таких как гистограммы ориентированного градиента и контекст формы) на основе многообразного обучения. На втором этапе однослойный автокодировщик обучается изучению абстрактного представления, которое используется для восстановления трехмерной позы путем реконструкции особенностей двухмерных промежуточных изображений. Между тем, однослойный автокодировщик аналогичным образом обучается изучению абстрактных представлений трехмерных поз. После получения абстрактного представления каждой отдельной модальности нейронная сеть используется для изучения мультимодальной корреляции между 2D-изображениями и 3D-позами путем минимизации квадрата евклидова расстояния между двумя модальными взаимными представлениями. Обучение предлагаемого мультимодального глубокого автоэнкодера состоит из этапов инициализации и тонкой настройки. При инициализации параметры каждой подчасти многомодального глубокого автокодировщика копируются из соответствующего автокодировщика и нейронной сети. Затем параметры всей модели дополнительно настраиваются с помощью алгоритма стохастического градиентного спуска для построения трехмерной позы из соответствующего двумерного изображения. ############3.2.3 Резюме ############Мультимодальная модель, основанная на SAE, использует архитектуру кодера-декодера и реконструирует ее неконтролируемым способом. Метод извлекает внутренние модальные характеристики и кросс-модальные характеристики. Поскольку они основаны на SAE, которая представляет собой полностью связанную модель, необходимо обучить многие параметры. Более того, они игнорируют пространственную и временную топологию мультимодальных данных. ###### В целях моделирования изображений и распределения семантического отображения между предложениями Ма, Лу, Шан и Ли (2015) предложили мультимодальную сверточную нейронную сеть. Чтобы полностью уловить семантическую релевантность, в сквозной архитектуре разработана трехуровневая стратегия объединения — уровень слова, уровень сцены и уровень предложения. Архитектура состоит из подсети обработки изображений, соответствующей подсети и мультимодальной подсети. Подсеть изображений представляет собой репрезентативную глубокую сверточную нейронную сеть, такую как Alexnet и Inception, которая эффективно кодирует входные изображения в краткие представления. Соответствующая подсеть моделирует совместные представления, которые связывают содержимое изображения с фрагментами слов предложений в семантическом пространстве. Чтобы расширить систему визуального распознавания на неограниченное количество дискретных категорий, Фром и др. (2013) Предлагается мультимодальная сверточная нейронная сеть для обработки семантической информации в текстовых данных. Сеть состоит из языковой подмодели и визуальной подмодели. Подмодель языка основана на модели пропуска грамм, которая может переводить текстовую информацию в плотное представление семантического пространства. Визуальная подмодель представляет собой репрезентативную сверточную нейронную сеть, такую как Alexnet, которая предварительно обучена на наборе данных ImageNet класса 1000 для захвата визуальных функций. Для моделирования семантических отношений между изображениями и текстом языковые и визуальные подмодели объединяются с помощью слоев линейной проекции. Каждая подмодель инициализируется параметрами для каждой модальности. После этого для обучения этой визуально-семантической мультимодальной модели предлагается новая функция потерь, которая может обеспечить высокие оценки сходства для правильных пар изображений и меток путем объединения сходства скалярного произведения и потери ранга шарнира. Модель обеспечивает высочайшую производительность в наборе данных ImageNet, избегая семантически неправдоподобных результатов. Мультимодальные модели на основе CNN могут изучать взаимосвязи между модальностями через локальные поля и операции объединения. Они явно моделируют пространственную топологию мультимодальных данных. И это не полноценные модели со значительно уменьшенным количеством параметров. Для создания подписей к изображениям Мао и др. (2014) предложили мультимодальную рекуррентную нейронную архитектуру. Эта мультимодальная рекуррентная нейронная сеть может соединять вероятностные корреляции между изображениями и предложениями. Он устраняет ограничение предыдущих работ, которые не могут генерировать новые подписи к изображениям, поскольку они извлекают соответствующие подписи в базе данных предложений на основе изученных сопоставлений изображения и текста. В отличие от предыдущей работы, мультимодальные рекуррентные нейронные модели (MRNN) изучают совместные распределения в семантическом пространстве по заданным словам и изображениям. Когда изображение представлено, оно дословно генерирует предложения на основе захваченного совместного распределения. В частности, мультимодальная рекуррентная нейронная сеть состоит из языковой подсети, визуальной подсети и мультимодальной подсети, как показано на рисунке 7. Языковая подсеть состоит из двухслойной части встраивания слов, которая фиксирует эффективные представления для конкретных задач, и однослойной рекуррентной нейронной части, которая моделирует временную зависимость предложений. Подсеть Vision — это, по сути, глубокая сверточная нейронная сеть, такая как Alexnet, Resnet или Inception, которая кодирует многомерные изображения в компактные представления. Наконец, мультимодальная подсеть представляет собой скрытую сеть, которая моделирует совместное семантическое распределение изученного языка и визуальных представлений. Рисунок 7: Чтобы устранить ограничения существующих систем визуального распознавания, которые не могут с первого взгляда генерировать подробные описания изображений, предлагается модель мультимодального выравнивания, соединяющая интермодальные отношения между визуальными и текстовыми данными (Karpathy & Li, 2017). Для этого была предложена двойная схема. Во-первых, модель визуального семантического внедрения предназначена для создания мультимодальных наборов обучающих данных. Затем на этом наборе данных мультимодальная RNN обучается для создания подробных описаний изображений. В модели визуального семантического внедрения региональные сверточные нейронные сети используются для получения богатых представлений изображений, содержащих достаточную информацию для контента, соответствующего предложениям. Затем двунаправленная RNN используется для кодирования каждого предложения в плотный вектор с теми же размерами, что и представление изображения. Кроме того, представлена мультимодальная функция оценки для измерения семантического сходства между изображениями и предложениями. Наконец, метод случайного поля Маркова используется для генерации мультимодальных наборов данных. В мультимодальной RNN предлагается более эффективная расширенная модель, основанная на вводе текстового контента и изображений. Мультимодальная модель состоит из сверточной нейронной сети, которая кодирует входные изображения, и RNN, которая кодирует функции и предложения изображений. Модель также обучается с помощью алгоритма стохастического градиентного спуска. Обе мультимодальные модели тщательно оцениваются в наборах данных Flickr и Mscoco и демонстрируют самые современные характеристики. Мультимодальная модель на основе RNN может анализировать скрытое состояние с помощью явной передачи состояния в скрытом расчет единиц Временная зависимость в мультимодальных данных. Они используют алгоритм временного обратного распространения ошибки для обучения параметров. Поскольку вычисления выполняются скрытой передачей состояний, их распараллеливание на высокопроизводительных устройствах затруднительно. Мы суммируем модель в четыре набора мультимодальной глубины данных на основе DBN, SAE, CNN и Модель обучения RNN. Эти новаторские модели уже привели к некоторому прогрессу. Однако эти модели все еще находятся на предварительной стадии, поэтому проблемы остаются. Прежде всего, в модели глубокого обучения мультимодального слияния данных имеется большое количество свободных весов, особенно избыточных параметров, которые мало влияют на целевую задачу. Чтобы обучить эти параметры, которые отражают характерную структуру данных, большой объем данных вводится в модель глубокого обучения мультимодального объединения данных, основанную на алгоритме обратного распространения ошибки, который требует больших вычислительных ресурсов и отнимает много времени. Поэтому разработка новых мультимодальных методов сжатия глубокого обучения в сочетании с существующими стратегиями сжатия также является потенциальным направлением исследований. 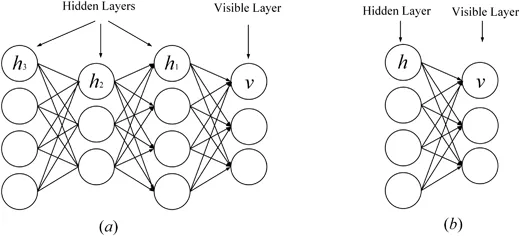
#2.2 Стековый автоэнкодер (SAE)
##2.3 Сверточная нейронная сеть (CNN)
#2.4 Рекуррентная нейронная сеть (RNN)
#3. Глубокое обучение для мультимодального объединения данных
#3.1 Сетевое мультимодальное объединение данных с глубоким доверием
#3.1.1 Пример 1
3.1.2 Пример 2
3.1.3 Пример 3
3.1.4 Резюме
3.2 Мультимодальное объединение данных на основе составных автоэнкодеров
3.2.1 Пример 4
3.3 Мультимодальное объединение данных на основе сверточной нейронной сети
3.3.1 Пример 6
3.3.2 Пример 7
3.3.3 Резюме
3.4 Мультимодальное объединение данных на основе рекуррентной нейронной сети
3.4.1 Пример 8
##3.4.2 Пример 9
3.4.3 Резюме
#4. Резюме и перспективы
以上が完成度高すぎ!マルチモーダルディープラーニングのレビュー!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7752
7752
 15
1643
14
1398
52
1293
25
1234
29
15
1643
14
1398
52
1293
25
1234
29

 Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
このサイトは6月27日、JianyingはByteDanceの子会社であるFaceMeng Technologyによって開発されたビデオ編集ソフトウェアであり、Douyinプラットフォームに依存しており、基本的にプラットフォームのユーザー向けに短いビデオコンテンツを作成すると報告しました。 Windows、MacOS、その他のオペレーティング システム。 Jianyingは会員システムのアップグレードを正式に発表し、インテリジェント翻訳、インテリジェントハイライト、インテリジェントパッケージング、デジタルヒューマン合成などのさまざまなAIブラックテクノロジーを含む新しいSVIPを開始しました。価格的には、クリッピングSVIPの月額料金は79元、年会費は599元(当サイト注:月額49.9元に相当)、継続月額サブスクリプションは月額59元、継続年間サブスクリプションは、年間499元(月額41.6元に相当)です。さらに、カット担当者は、ユーザーエクスペリエンスを向上させるために、オリジナルのVIPに登録している人は、
 AlphaFold 3 が発売され、タンパク質とすべての生体分子の相互作用と構造をこれまでよりもはるかに高い精度で包括的に予測します。
Jul 16, 2024 am 12:08 AM
AlphaFold 3 が発売され、タンパク質とすべての生体分子の相互作用と構造をこれまでよりもはるかに高い精度で包括的に予測します。
Jul 16, 2024 am 12:08 AM
エディター | Radish Skin 2021 年の強力な AlphaFold2 のリリース以来、科学者はタンパク質構造予測モデルを使用して、細胞内のさまざまなタンパク質構造をマッピングし、薬剤を発見し、既知のあらゆるタンパク質相互作用の「宇宙地図」を描いてきました。ちょうど今、Google DeepMind が AlphaFold3 モデルをリリースしました。このモデルは、タンパク質、核酸、小分子、イオン、修飾残基を含む複合体の結合構造予測を実行できます。 AlphaFold3 の精度は、これまでの多くの専用ツール (タンパク質-リガンド相互作用、タンパク質-核酸相互作用、抗体-抗原予測) と比較して大幅に向上しました。これは、単一の統合された深層学習フレームワーク内で、次のことを達成できることを示しています。
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
編集者 | KX 医薬品の研究開発の分野では、タンパク質とリガンドの結合親和性を正確かつ効果的に予測することが、医薬品のスクリーニングと最適化にとって重要です。しかし、現在の研究では、タンパク質とリガンドの相互作用における分子表面情報の重要な役割が考慮されていません。これに基づいて、アモイ大学の研究者らは、初めてタンパク質の表面、3D 構造、配列に関する情報を組み合わせ、クロスアテンション メカニズムを使用して異なるモダリティの特徴を比較する、新しいマルチモーダル特徴抽出 (MFE) フレームワークを提案しました。アライメント。実験結果は、この方法がタンパク質-リガンド結合親和性の予測において最先端の性能を達成することを実証しています。さらに、アブレーション研究は、この枠組み内でのタンパク質表面情報と多峰性特徴の位置合わせの有効性と必要性を実証しています。 「S」で始まる関連研究
 SKハイニックスは8月6日に12層HBM3E、321層NANDなどのAI関連新製品を展示する。
Aug 01, 2024 pm 09:40 PM
SKハイニックスは8月6日に12層HBM3E、321層NANDなどのAI関連新製品を展示する。
Aug 01, 2024 pm 09:40 PM
8月1日の本サイトのニュースによると、SKハイニックスは本日(8月1日)ブログ投稿を発表し、8月6日から8日まで米国カリフォルニア州サンタクララで開催されるグローバル半導体メモリサミットFMS2024に参加すると発表し、多くの新世代の製品。フューチャー メモリおよびストレージ サミット (FutureMemoryandStorage) の紹介。以前は主に NAND サプライヤー向けのフラッシュ メモリ サミット (FlashMemorySummit) でしたが、人工知能技術への注目の高まりを背景に、今年はフューチャー メモリおよびストレージ サミット (FutureMemoryandStorage) に名前が変更されました。 DRAM およびストレージ ベンダー、さらに多くのプレーヤーを招待します。昨年発売された新製品SKハイニックス
 AIなどの市場を開拓するグローバルファウンドリーズがタゴール・テクノロジーの窒化ガリウム技術と関連チームを買収
Jul 15, 2024 pm 12:21 PM
AIなどの市場を開拓するグローバルファウンドリーズがタゴール・テクノロジーの窒化ガリウム技術と関連チームを買収
Jul 15, 2024 pm 12:21 PM
7月5日のこのウェブサイトのニュースによると、グローバルファウンドリーズは今年7月1日にプレスリリースを発行し、自動車とインターネットでの市場シェア拡大を目指してタゴール・テクノロジーのパワー窒化ガリウム(GaN)技術と知的財産ポートフォリオを買収したことを発表した。モノと人工知能データセンターのアプリケーション分野で、より高い効率とより優れたパフォーマンスを探求します。生成 AI などのテクノロジーがデジタル世界で発展を続ける中、窒化ガリウム (GaN) は、特にデータセンターにおいて、持続可能で効率的な電力管理のための重要なソリューションとなっています。このウェブサイトは、この買収中にタゴール・テクノロジーのエンジニアリングチームがGLOBALFOUNDRIESに加わり、窒化ガリウム技術をさらに開発するという公式発表を引用した。 G
 中国科学技術大学ヒューマノイドロボット研究所が公開され、長江デルタヒューマノイドロボット同盟の設立を発表
Jun 19, 2024 pm 12:59 PM
中国科学技術大学ヒューマノイドロボット研究所が公開され、長江デルタヒューマノイドロボット同盟の設立を発表
Jun 19, 2024 pm 12:59 PM
本サイトは6月18日、今朝、中国科学技術大学の人工知能・ヒューマノイドロボットフロンティアフォーラムが同校のハイテクパークで開催されたと報じた。中国科学技術大学の人工知能・データサイエンス学部とヒューマノイドロボット研究所が相次いで発表され、中国科学院院士の丁漢氏が科学・研究部長に任命された。ヒューマノイドロボット研究所の技術委員会は、長江デルタヒューマノイドロボットアライアンスの設立を発表した。 USTC のヒューマノイド ロボット研究所は、USTC の学際的な利点を活用し、インテリジェント分野における USTC の開発を促進するために、材料センシング、構造作動、運動制御、および身体化インテリジェンスの方向における技術的ブレークスルーに努めることに取り組んでいます。ロボット。当研究所は、今後も技術革新を踏まえ、サービス、医療、教育等の分野への人型ロボットの活用を積極的に推進していきます。
 Iyo One: 一部ヘッドフォン、一部オーディオコンピュータ
Aug 08, 2024 am 01:03 AM
Iyo One: 一部ヘッドフォン、一部オーディオコンピュータ
Aug 08, 2024 am 01:03 AM
どんな時でも集中力は美徳です。著者 | 編集者 Tang Yitao | 人工知能の復活により、ハードウェア革新の新たな波が起きています。最も人気のある AIPin は前例のない否定的なレビューに遭遇しました。マーケス・ブラウンリー氏(MKBHD)はこれを、これまでレビューした中で最悪の製品だと評したが、ザ・ヴァージの編集者デイビッド・ピアース氏は、誰にもこのデバイスの購入を勧めないと述べた。競合製品である RabbitR1 はそれほど優れていません。この AI デバイスに関する最大の疑問は、これが明らかに単なるアプリであるのに、Rabbit は 200 ドルのハードウェアを構築したということです。多くの人がAIハードウェアのイノベーションをスマートフォン時代を打破するチャンスと捉え、スマートフォン時代に全力を注ぐ。
