

大規模な言語モデルがアクティベーション関数として SwiGLU を使用するのはなぜですか?

如果你一直在关注大型语言模型的架构,你可能会在最新的模型和研究论文中看到“SwiGLU”这个词。SwiGLU可以说是在大语言模型中最常用到的激活函数,我们本篇文章就来对它进行详细的介绍。SwiGLU其实是2020年谷歌提出的激活函数,它结合了SWISH和GLU两者的特点。 SwiGLU的中文全称是“双向门控线性单元”,它将SWISH和GLU两种激活函数进行了优化和结合,以提高模型的非线性表达能力。SWISH是一种非常普遍的激活函数,它在大语言模型中得到广泛应用,而GLU则在自然语言处理任务中表现出色。 SwiGLU的优点在于它能够同时获取SWISH的平滑特性和GLU的门控特性,从而在模型的非线性表达上更加

我们一个一个来介绍:
Swish
Swish是一个非线性激活函数,定义如下:
Swish(x) = x*sigmoid(ßx)
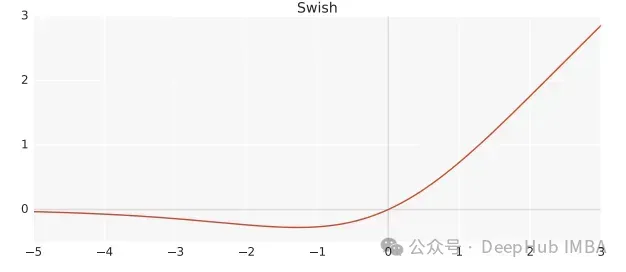
其中,ß 为可学习参数。Swish 可以比ReLU激活函数更好,因为它给予了更平滑的转换,这可以带来更好的优化。
Gated Linear Unit
GLU(Gated Linear Unit)定义为两个线性变换的分量积,其中一个线性变换由sigmoid激活。
GLU(x) = sigmoid(W1x+b)⊗(Vx+c)
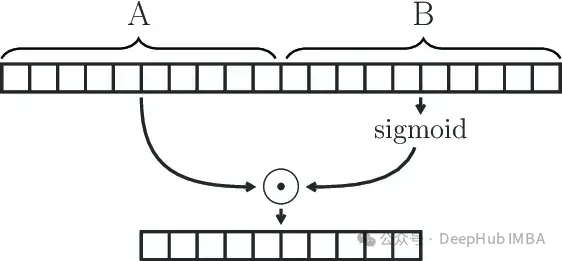
GLU模块可以有效地捕获序列中的远程依赖关系,同时避免了LSTM和GRU等其他门控机制相关的一些梯度消失问题。
SwiGLU
我们已经说过SwiGLU是两者的结合。它是一个GLU,但不是将sigmoid作为激活函数,而是使用ß=1的swish,因此我们最终得到以下公式:
SwiGLU(x) = Swish(W1x+b)⊗(Vx+c)
我们用SwiGLU函数构造一个前馈网络
FFNSwiGLU(x) = (Swish1(xW)⊗xV)W2
Pytorch的简单实现
如果上面的数学原理看着比较麻烦枯燥难懂,我们下面直接使用代码解释。
class SwiGLU(nn.Module): def __init__(self, w1, w2, w3) -> None:super().__init__()self.w1 = w1self.w2 = w2self.w3 = w3 def forward(self, x):x1 = F.linear(x, self.w1.weight)x2 = F.linear(x, self.w2.weight)hidden = F.silu(x1) * x2return F.linear(hidden, self.w3.weight)
コードで使用されている F.silu 関数は、ß=1 の場合の swish と同じであるため、それを直接使用します。
コードからわかるように、活性化関数にはトレーニング可能な 3 つの重みがあり、これらは GLU 式のパラメーターです。
SwiGLU の効果の比較
SwiGLU を他の GLU バリアントと比較すると、SwiGLU が両方の事前トレーニング期間で良好なパフォーマンスを発揮していることがわかります。より良い。
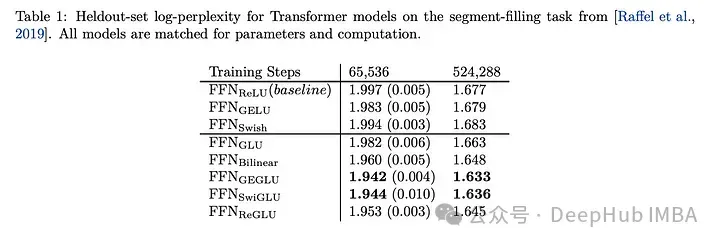
#下流タスク
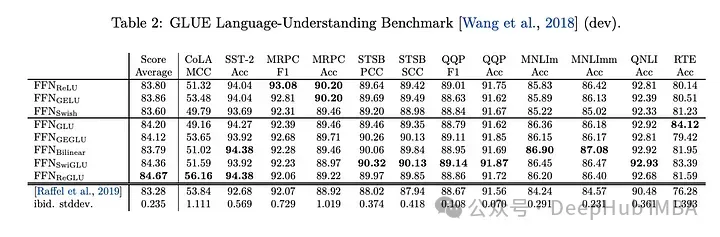
効果は最高です。そのため、現在、LLAMA、OLMO、PALM などの llm はすべて実装で SwiGLU を使用しています。しかし、なぜ SwiGLU が他のものよりも優れているのでしょうか?
この論文では、テスト結果のみが示されており、その理由については説明されていません。代わりに、次のように書かれています。なぜこれらのアーキテクチャが機能するように見えるのかについては、他のすべてと同様に、それらの成功も神の慈悲によるものだと考えています。
しかし、今は 2024 年なので、それを強く説明できます:著者は、錬金術は成功したと言いました。
#1. 負の値に対する Swish の反応は比較的小さいです。一部のニューロンの出力が常にゼロになるという ReLU の欠点を克服します
#2. GLU のゲート特性、つまりどの情報を通過させ、どの情報を通過させるかを決定できる入力状況に応じて情報をフィルタリングする必要があります。このメカニズムにより、ネットワークは有用な表現をより効果的に学習できるようになり、モデルの汎化能力の向上に役立ちます。大規模な言語モデルでは、これは長距離の依存関係を持つ長いテキスト シーケンスを処理する場合に特に役立ちます。
3. SwiGLU のパラメータ W1、W2、W3、b1、b2、b3 W1、W2、W3、b1、b2、b3 はトレーニングを通じて学習できるため、モデルはデータセットを使用してこれらのパラメータを動的に調整すると、モデルの柔軟性と適応性が向上します。
4. 計算効率は、より複雑な活性化関数 (GELU など) よりも高く、良好なパフォーマンスを維持します。これは、大規模な言語モデルのトレーニングと推論にとって重要な考慮事項です。
大規模言語モデルのアクティベーション関数として SwiGLU を選択します。主な理由は、SwiGLU が非線形機能、ゲート特性、勾配の安定性、学習可能なパラメーターの利点を組み合わせているからです。 SwiGLU は、言語モデルにおける複雑な意味関係や長い依存関係の問題を処理する上で優れたパフォーマンスを発揮し、トレーニングの安定性と計算効率を維持できるため、広く採用されています。
#紙のアドレス
#https://www.php.cn/link/86e33d550dc162366a02003089ab9894
以上が大規模な言語モデルがアクティベーション関数として SwiGLU を使用するのはなぜですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7543
7543
 15
1381
52
83
11
21
87
15
1381
52
83
11
21
87

 大規模な言語モデルがアクティベーション関数として SwiGLU を使用するのはなぜですか?
Apr 08, 2024 pm 09:31 PM
大規模な言語モデルがアクティベーション関数として SwiGLU を使用するのはなぜですか?
Apr 08, 2024 pm 09:31 PM
大規模な言語モデルのアーキテクチャに注目している場合は、最新のモデルや研究論文で「SwiGLU」という用語を見たことがあるかもしれません。 SwiGLUは大規模言語モデルで最もよく使われるアクティベーション関数と言えますので、この記事で詳しく紹介します。実はSwiGLUとは、2020年にGoogleが提案したSWISHとGLUの特徴を組み合わせたアクティベーション関数です。 SwiGLU の正式な中国語名は「双方向ゲート線形ユニット」で、SWISH と GLU の 2 つの活性化関数を最適化して組み合わせ、モデルの非線形表現能力を向上させます。 SWISH は大規模な言語モデルで広く使用されている非常に一般的なアクティベーション関数ですが、GLU は自然言語処理タスクで優れたパフォーマンスを示しています。
 微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
大規模言語モデル (LLM) は巨大なテキスト データベースでトレーニングされ、そこで大量の現実世界の知識を取得します。この知識はパラメータに組み込まれており、必要なときに使用できます。これらのモデルの知識は、トレーニングの終了時に「具体化」されます。事前トレーニングの終了時に、モデルは実際に学習を停止します。モデルを調整または微調整して、この知識を活用し、ユーザーの質問により自然に応答する方法を学びます。ただし、モデルの知識だけでは不十分な場合があり、モデルは RAG を通じて外部コンテンツにアクセスできますが、微調整を通じてモデルを新しいドメインに適応させることが有益であると考えられます。この微調整は、ヒューマン アノテーターまたは他の LLM 作成物からの入力を使用して実行され、モデルは追加の実世界の知識に遭遇し、それを統合します。
 FAISS ベクトル空間を視覚化し、RAG パラメータを調整して結果の精度を向上させます
Mar 01, 2024 pm 09:16 PM
FAISS ベクトル空間を視覚化し、RAG パラメータを調整して結果の精度を向上させます
Mar 01, 2024 pm 09:16 PM
オープンソースの大規模言語モデルのパフォーマンスが向上し続けるにつれて、コードの作成と分析、推奨事項、テキストの要約、および質問と回答 (QA) ペアのパフォーマンスがすべて向上しました。しかし、QA に関しては、LLM はトレーニングされていないデータに関連する問題に対応していないことが多く、多くの内部文書はコンプライアンス、企業秘密、またはプライバシーを確保するために社内に保管されています。これらの文書がクエリされると、LLM は幻覚を起こし、無関係なコンテンツ、捏造されたコンテンツ、または矛盾したコンテンツを生成する可能性があります。この課題に対処するために考えられる手法の 1 つは、検索拡張生成 (RAG) です。これには、生成の品質と精度を向上させるために、トレーニング データ ソースを超えた信頼できるナレッジ ベースを参照して応答を強化するプロセスが含まれます。 RAG システムには、コーパスから関連する文書断片を取得するための検索システムが含まれています。
 セルフゲーム微調整トレーニングのための SPIN テクノロジーを使用した LLM の最適化
Jan 25, 2024 pm 12:21 PM
セルフゲーム微調整トレーニングのための SPIN テクノロジーを使用した LLM の最適化
Jan 25, 2024 pm 12:21 PM
2024 年は、大規模言語モデル (LLM) が急速に開発される年です。 LLM のトレーニングでは、教師あり微調整 (SFT) や人間の好みに依存する人間のフィードバックによる強化学習 (RLHF) などのアライメント手法が重要な技術手段です。これらの方法は LLM の開発において重要な役割を果たしてきましたが、位置合わせ方法には手動で注釈を付けた大量のデータが必要です。この課題に直面して、微調整は活発な研究分野となっており、研究者は人間のデータを効果的に活用できる方法の開発に積極的に取り組んでいます。したがって、位置合わせ方法の開発は、LLM 技術のさらなる進歩を促進するでしょう。カリフォルニア大学は最近、SPIN (SelfPlayfInetuNing) と呼ばれる新しいテクノロジーを導入する研究を実施しました。 S
 ナレッジ グラフを利用して RAG モデルの機能を強化し、大規模モデルの誤った印象を軽減する
Jan 14, 2024 pm 06:30 PM
ナレッジ グラフを利用して RAG モデルの機能を強化し、大規模モデルの誤った印象を軽減する
Jan 14, 2024 pm 06:30 PM
幻覚は、大規模言語モデル (LLM) を扱う場合によくある問題です。 LLM は滑らかで一貫性のあるテキストを生成できますが、生成される情報は不正確または一貫性がないことがよくあります。 LLM の幻覚を防ぐために、データベースやナレッジ グラフなどの外部知識ソースを使用して事実情報を提供できます。このようにして、LLM はこれらの信頼できるデータ ソースに依存できるため、より正確で信頼性の高いテキスト コンテンツが得られます。ベクトル データベースとナレッジ グラフ ベクトル データベース ベクトル データベースは、エンティティまたは概念を表す高次元ベクトルのセットです。これらは、ベクトル表現を通じて計算された、異なるエンティティまたは概念間の類似性または相関関係を測定するために使用できます。ベクトル データベースは、ベクトル距離に基づいて、「パリ」と「フランス」の方が「パリ」よりも近いことを示します。
 RoSA: 大規模なモデルパラメータを効率的に微調整するための新しい方法
Jan 18, 2024 pm 05:27 PM
RoSA: 大規模なモデルパラメータを効率的に微調整するための新しい方法
Jan 18, 2024 pm 05:27 PM
言語モデルが前例のない規模に拡大するにつれて、下流タスクの包括的な微調整には法外なコストがかかります。この問題を解決するために、研究者はPEFT法に注目し、採用し始めました。 PEFT 手法の主なアイデアは、微調整の範囲を少数のパラメータ セットに制限して、自然言語理解タスクで最先端のパフォーマンスを達成しながら計算コストを削減することです。このようにして、研究者は高いパフォーマンスを維持しながらコンピューティング リソースを節約でき、自然言語処理の分野に新たな研究のホットスポットをもたらします。 RoSA は、一連のベンチマークでの実験を通じて、同じパラメーター バジェットを使用した以前の低ランク適応 (LoRA) および純粋なスパース微調整手法よりも優れたパフォーマンスを発揮することが判明した新しい PEFT 手法です。この記事ではさらに詳しく説明します
 GQA、大規模モデルで一般的に使用されるアテンション メカニズム、および Pytorch コードの実装の詳細な説明
Apr 03, 2024 pm 05:40 PM
GQA、大規模モデルで一般的に使用されるアテンション メカニズム、および Pytorch コードの実装の詳細な説明
Apr 03, 2024 pm 05:40 PM
グループ化クエリ アテンション (GroupedQueryAttendant) は、大規模言語モデルにおけるマルチクエリ アテンション メソッドであり、その目標は、MQA の速度を維持しながら MHA の品質を達成することです。 GroupedQueryAttendant はクエリをグループ化し、各グループ内のクエリは同じアテンションの重みを共有するため、計算の複雑さが軽減され、推論速度が向上します。この記事では、GQAの考え方とそれをコードに変換する方法について説明します。 GQA は論文「GQA:TrainingGeneralizedMulti-QueryTransformerModelsfromMulti-HeadCheckpoint」に掲載されています
 LLMLingua: LlamaIndex を統合し、ヒントを圧縮し、効率的な大規模言語モデル推論サービスを提供します
Nov 27, 2023 pm 05:13 PM
LLMLingua: LlamaIndex を統合し、ヒントを圧縮し、効率的な大規模言語モデル推論サービスを提供します
Nov 27, 2023 pm 05:13 PM
大規模言語モデル (LLM) の出現により、複数の分野でイノベーションが刺激されました。しかし、思考連鎖 (CoT) プロンプトや文脈学習 (ICL) などの戦略によってプロンプトの複雑さが増大し、計算上の課題が生じています。このような長いプロンプトには推論に多くのリソースが必要なため、効率的な解決策が必要です。この記事では、効率的な推論を実行するための LLMLingua と独自の LlamaIndex の統合について紹介します。LLMLingua は、EMNLP2023 でマイクロソフトの研究者によって発表された論文です。LongLLMLingua は、高速圧縮を通じて、長いコンテキストのシナリオで重要な情報を認識する llm の能力を強化する方法です。 LLMLingua と llamindex
