

CVPR 2024 | すべてのモデルのセグメンテーションは SAM の汎化能力が低いですか?ドメイン適応戦略を解決

「Segment Anything」大規模モデルの最初のドメイン適応戦略はここにあります。関連論文が CVPR 2024 に受理されました。

## しかし、最近の研究によると、 SAM は、医療画像、カモフラージュされたオブジェクト、干渉が加わった自然画像などでのパフォーマンスの低下など、さまざまな下流タスクにおいてあまり堅牢ではなく、一般化可能ではありません。これは、トレーニング データ セットと下流のテスト データ セット間の大きな
事前トレーニング済み SAM を下流タスクに適応させるには、主に 3 つの課題があります。
- まず第一に、従来の教師なしドメイン適応パラダイムには
- ソース データセット
とターゲット データセットが必要ですが、これはプライバシーと計算コストの観点から比較的現実的ではありません。 第 2 に、ドメイン適応の場合、すべての重みを更新すると通常はパフォーマンスが向上しますが、 - 高価なメモリ コスト
によっても制限されます。 最後に、SAM は、さまざまなタイプや粒度のプロンプトに対して多様なセグメンテーション機能を示すことができるため、 - 下流タスクのプロンプト情報が欠如している場合には、教師なし適応が行われます。非常に挑戦的であること。
 ##—。弱い監視を使用して、さまざまな下流タスクに SAM を適応させます
##—。弱い監視を使用して、さまざまな下流タスクに SAM を適応させます
と
論文アドレス: https://arxiv.org/pdf/2312.03502.pdf プロジェクト アドレス: https://github.com/Zhang- Haojie/WeSAM 論文タイトル: 弱い教師あり適応による分布シフト下のセグメンテーション基盤モデルの一般化の改善
Segment Anything Model 自己トレーニングに基づく適応フレームワーク -
弱い監督が効果的な自己トレーニングの達成にどのように役立つか -
#低ランクの重みの更新
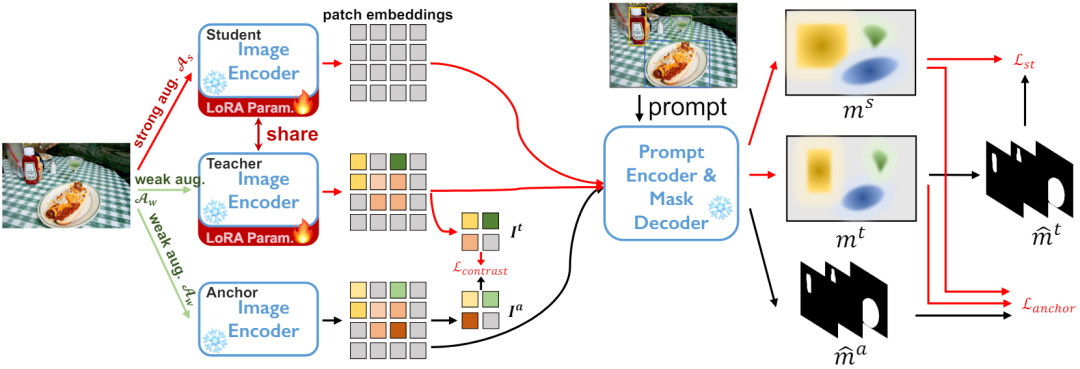
ラベルが提供されていないターゲット データセットの場合 DT={ xi} と事前トレーニングされたセグメンテーション モデル。私たちは、自己トレーニングのために
2) 堅牢な正則化のためのアンカー損失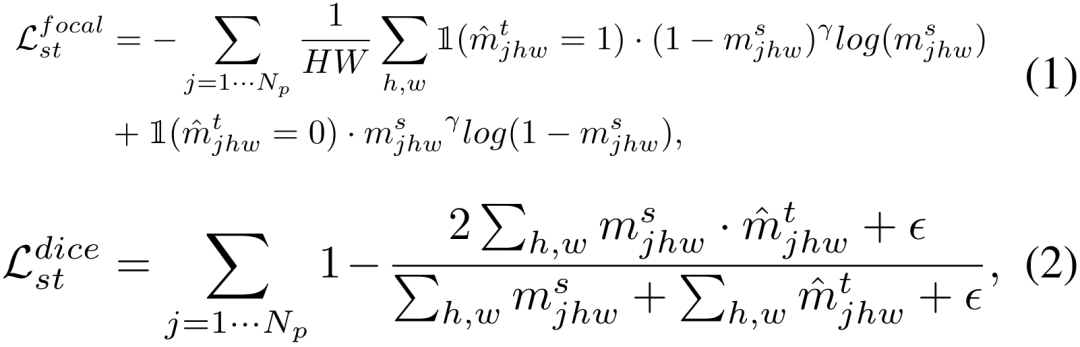
アンカー モデルと学生/教師モデルの間の Dice 損失をそれぞれ最小化します
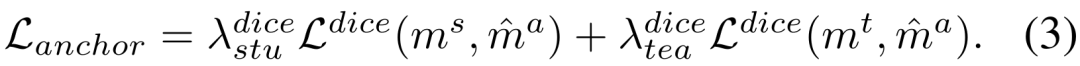
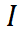
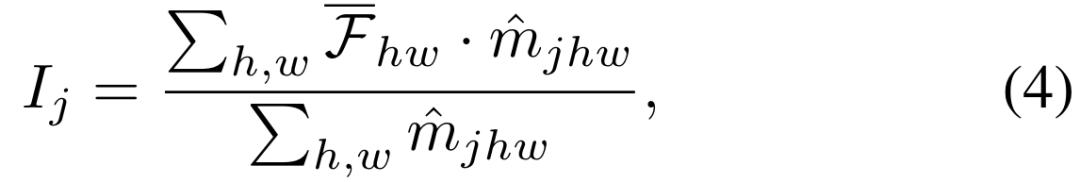
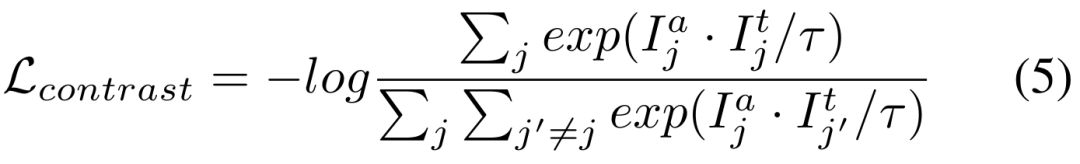
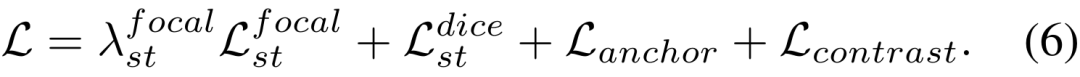

Segment-Anything モデル: メモリ制限のため、エンコーダーネットワークには当社ViT-Bを採用しています。標準のヒント エンコーダとマスク デコーダを使用します。
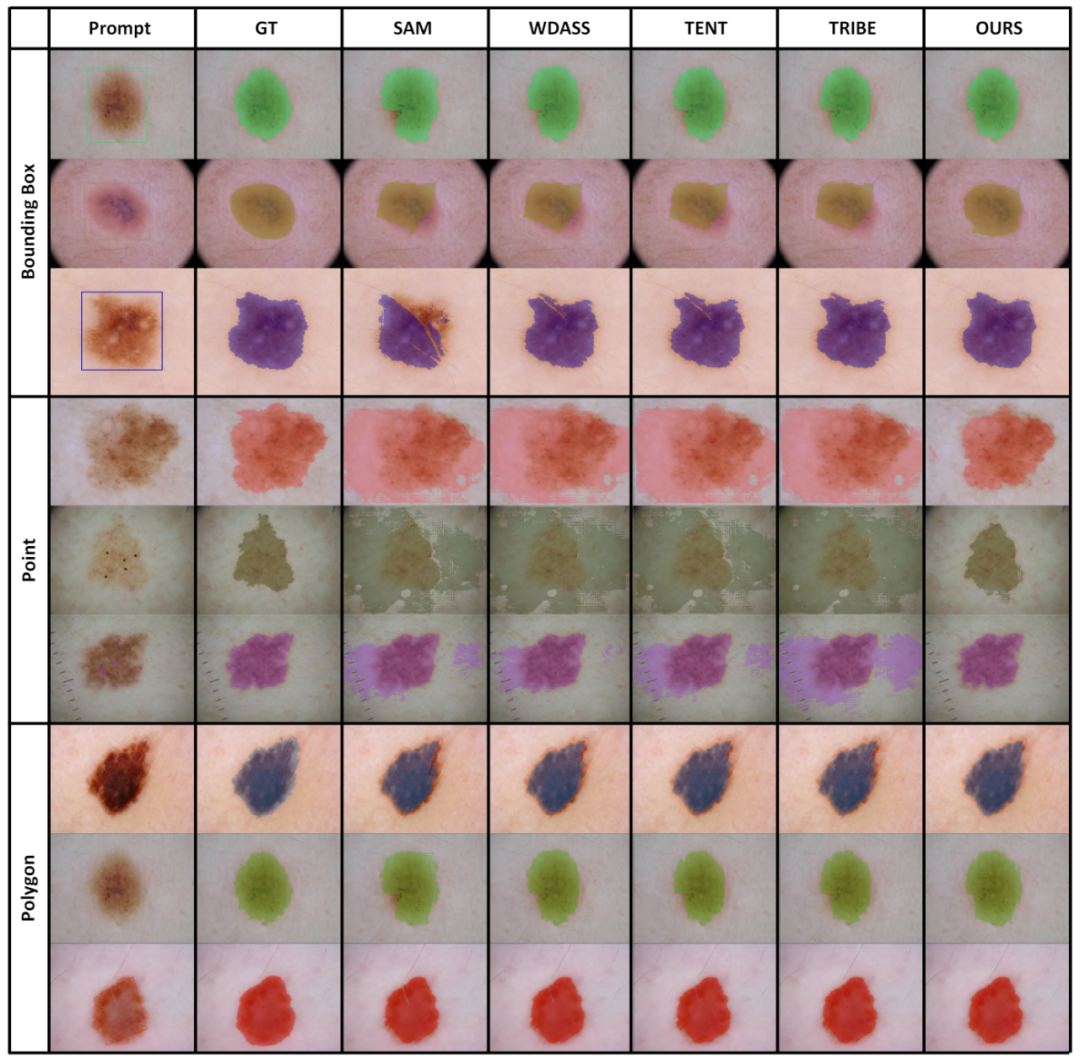
プロンプト生成: トレーニング フェーズと評価フェーズの両方のプロンプト入力は、インスタンス セグメンテーション GT マスクから計算され、弱い監視として人間の対話をシミュレートします。
#具体的には、GT マスク全体の最小境界ボックスからボックスを抽出します。ポイントは、GT マスク内の 5 つの正のサンプル ポイントとマスクの外側の 5 つの負のサンプル ポイントをランダムに選択することによって作成されます。粗いマスクは、ポリゴンを GT マスクに適合させることによってシミュレートされます。
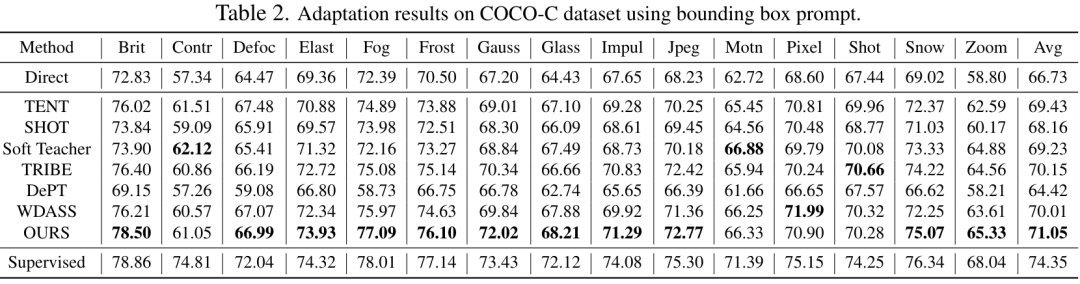
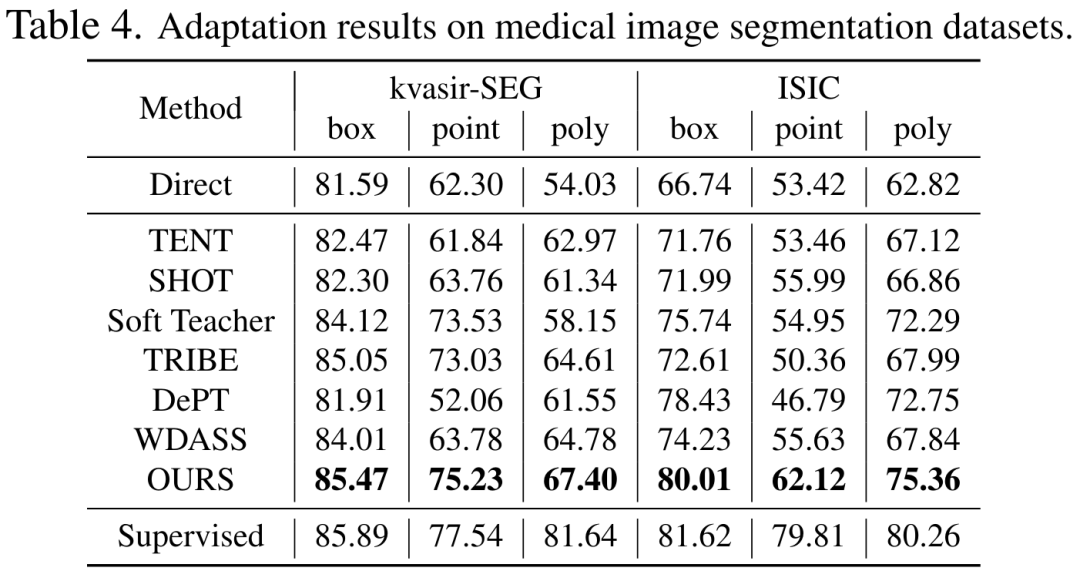
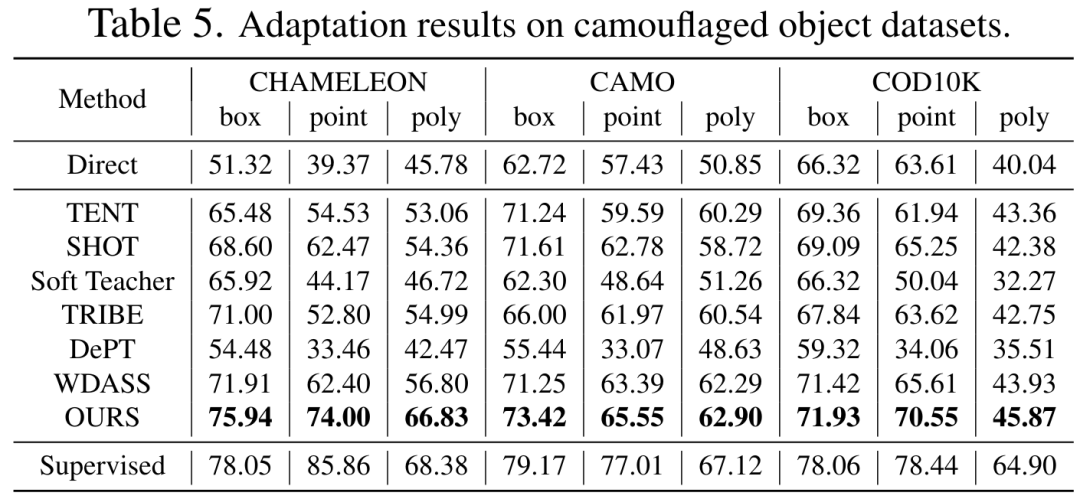
表 2、3、4、5 は次のとおりです。それぞれ、干渉を加えた自然画像、鮮明な自然画像、医療画像、およびカモフラージュされたオブジェクト データ セットに関するテスト結果です。完全な実験結果は論文に記載されています。実験では、私たちのスキームが、ほぼすべての下流セグメンテーション データセット上で、事前トレーニングされた SAM および最先端のドメイン適応スキームよりも優れたパフォーマンスを発揮することが実証されています。


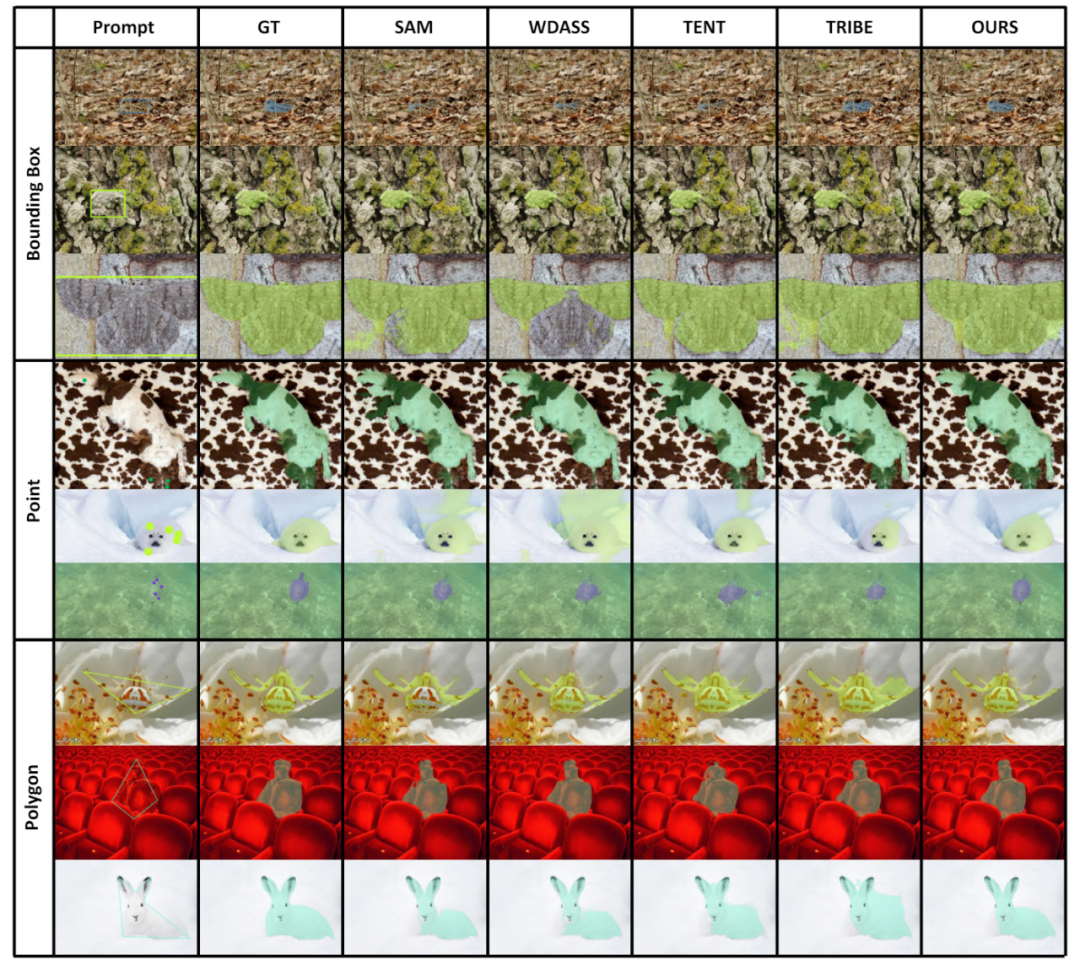
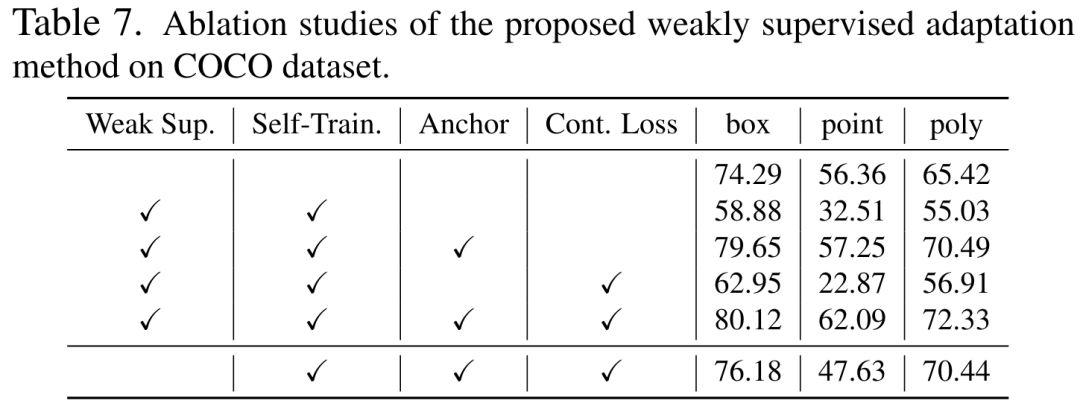
##5. アブレーション実験と追加の分析
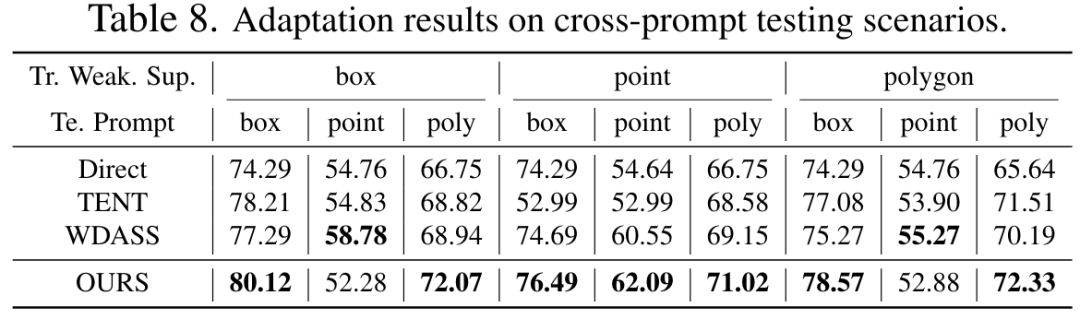
概要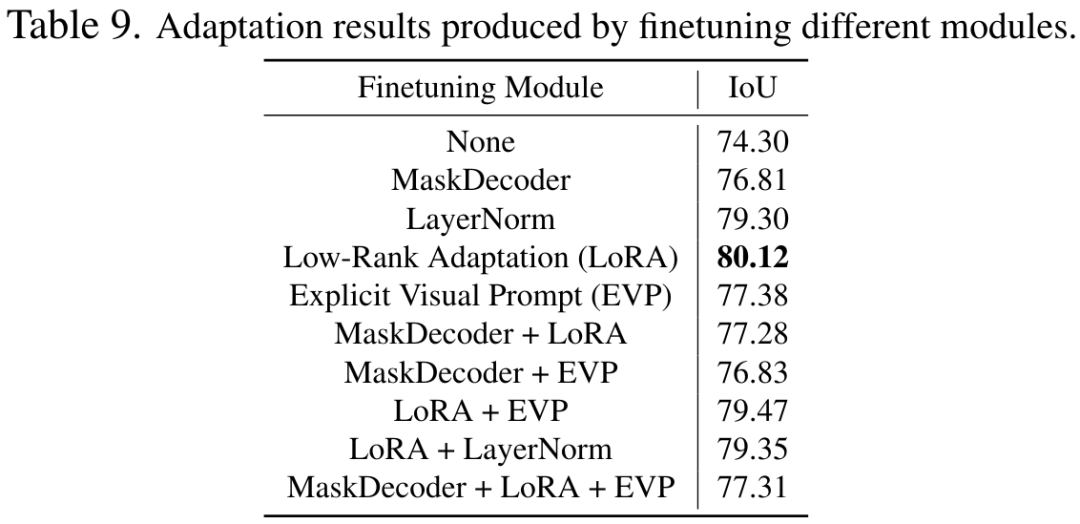
以上がCVPR 2024 | すべてのモデルのセグメンテーションは SAM の汎化能力が低いですか?ドメイン適応戦略を解決の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7542
7542
 15
1381
52
83
11
21
87
15
1381
52
83
11
21
87

 GITでリポジトリを削除する方法
Apr 17, 2025 pm 04:03 PM
GITでリポジトリを削除する方法
Apr 17, 2025 pm 04:03 PM
gitリポジトリを削除するには、次の手順に従ってください。削除するリポジトリを確認します。リポジトリのローカル削除:RM -RFコマンドを使用して、フォルダーを削除します。倉庫をリモートで削除する:倉庫の設定に移動し、「倉庫の削除」オプションを見つけて、操作を確認します。
 Gitサーバーのパブリックネットワークに接続する方法
Apr 17, 2025 pm 02:27 PM
Gitサーバーのパブリックネットワークに接続する方法
Apr 17, 2025 pm 02:27 PM
GITサーバーをパブリックネットワークに接続するには、5つのステップが含まれます。1。パブリックIPアドレスのセットアップ。 2。ファイアウォールポート(22、9418、80/443)を開きます。 3。SSHアクセスを構成します(キーペアを生成し、ユーザーを作成します)。 4。http/httpsアクセスを構成します(サーバーをインストールし、許可を構成); 5.接続をテストします(SSHクライアントまたはGITコマンドを使用)。
 GitでSSHキーを生成する方法
Apr 17, 2025 pm 01:36 PM
GitでSSHキーを生成する方法
Apr 17, 2025 pm 01:36 PM
リモートGitサーバーに安全に接続するには、パブリックキーとプライベートキーの両方を含むSSHキーを生成する必要があります。 SSHキーを生成する手順は次のとおりです。端子を開き、ssh -keygen -t rsa -b 4096を入力します。キー保存場所を選択します。秘密鍵を保護するには、パスワード句を入力します。公開キーをリモートサーバーにコピーします。アカウントにアクセスするための資格情報であるため、秘密鍵を適切に保存します。
 Gitアカウントにパブリックキーを追加する方法
Apr 17, 2025 pm 02:42 PM
Gitアカウントにパブリックキーを追加する方法
Apr 17, 2025 pm 02:42 PM
Gitアカウントに公開キーを追加する方法は?ステップ:SSHキーペアを生成します。公開キーをコピーします。 gitlabまたはgithubに公開キーを追加します。 SSH接続をテストします。
 GITコードの競合に対処する方法
Apr 17, 2025 pm 02:51 PM
GITコードの競合に対処する方法
Apr 17, 2025 pm 02:51 PM
コード競合とは、複数の開発者が同じコードを変更し、GITが変更を自動的に選択せずにマージすると発生する競合を指します。解決手順には、競合するファイルを開き、競合するコードを見つけます。コードを手動でマージし、競合マーカーに保持する変更をコピーします。競合マークを削除します。変更を保存して送信します。
 GitでSSHを検出する方法
Apr 17, 2025 pm 02:33 PM
GitでSSHを検出する方法
Apr 17, 2025 pm 02:33 PM
GITを介してSSHを検出するには、次の手順を実行する必要があります。SSHキーペアを生成します。 Gitサーバーに公開キーを追加します。 sshを使用するようにgitを構成します。 SSH接続をテストします。実際の条件に応じて可能な問題を解決します。
 gitコミットを分離する方法
Apr 17, 2025 pm 02:36 PM
gitコミットを分離する方法
Apr 17, 2025 pm 02:36 PM
GITを使用してコードを個別に送信して、詳細な変更追跡と独立した作業能力を提供します。手順は次のとおりです。1。変更されたファイルを追加します。 2。特定の変更を送信します。 3.上記の手順を繰り返します。 4.リモートリポジトリへの提出をプッシュします。
 gitマージの競合を解決する方法
Apr 17, 2025 pm 12:24 PM
gitマージの競合を解決する方法
Apr 17, 2025 pm 12:24 PM
同じコード行に異なるコミット変更がある場合、マージ競合が発生します。競合の解決には、競合ファイルの開き、競合ポイントのチェック、変更の選択とマージ、競合マーカーの削除、変更の送信とプッシュの変更が必要です。 Git Mergetoolツールを使用して、特定の競合を解決し、困難がある場合は助けを求め、頻繁に競合の数を減らすために支店をマージします。
