

Llama アーキテクチャは GPT2 より劣っていますか?魔法のトークンで記憶力が10倍になる?

7B スケール言語モデル LLM はどれだけの人間の知識を保存できるでしょうか?この値を数値化するにはどうすればよいでしょうか?トレーニング時間とモデル アーキテクチャの違いはこの値にどのような影響を与えるでしょうか?浮動小数点圧縮の量子化、混合エキスパート モデルの MoE、およびデータ品質の違い (百科事典の知識とインターネットのゴミ) は、LLM の知識容量にどのような影響を及ぼしますか?
Zhu Zeyuan (Meta AI) と Li Yuanzhi (MBZUAI) による最新の研究「言語モデル物理学パート 3.3: 知識の法則のスケーリング」では、大規模な実験 (合計 50,000 のタスク、 4,200,000 GPU 時間 ) は 12 の法則を要約し、さまざまな文書に基づく LLM の知識容量のより正確な測定方法を提供します。

著者はまず、ベンチマーク データ セット (ベンチマーク) でのオープン ソース モデルのパフォーマンスを通じて LLM のスケーリング則を測定するのは非現実的であると指摘します。 )。たとえば、LLaMA-70B はナレッジ データ セットで LLaMA-7B より 30% 優れたパフォーマンスを示しますが、これはモデルを 10 倍に拡張しても容量が 30% しか増加しないという意味ではありません。モデルがネットワーク データを使用してトレーニングされた場合、モデルに含まれる知識の総量を推定することも困難になります。
別の例として、Mistral モデルと Llama モデルの品質を比較するとき、その違いはモデル アーキテクチャの違いによって引き起こされるのでしょうか、それともトレーニング データの準備の違いによって引き起こされるのでしょうか。 ?
上記の考察に基づいて、著者は、人工的に合成されたデータを作成し、その量と量を厳密に制御するという、論文「言語モデル物理学」シリーズの核となるアイデアを採用しています。データ内の知識の種類 データ内の知識ビットを調整します。同時に、著者はさまざまなサイズとアーキテクチャの LLM を使用して合成データでトレーニングし、トレーニングされたモデルがデータから学習した知識ビット数を正確に計算するための数学的定義を与えます。

- #論文アドレス: https://arxiv.org/pdf/2404.05405.pdf
- 論文のタイトル: 言語モデルの物理学: パート 3.3、知識能力のスケーリング法則
この研究については、誰か ITこの方向性を示すのが合理的だと思われます。スケーリングの法則を非常に科学的な方法で分析できます。
また、この研究がスケーリングの法則を異なるレベルに引き上げたと信じている人もいます。実務者必読の論文であることは間違いありません。
研究の概要
著者らは、bioS、bioR、bioD の 3 種類の合成データを研究しました。 bioS は英語のテンプレートを使用して書かれた伝記、bioR は LlaMA2 モデル (合計 22 GB) を利用して書かれた伝記、bioD は詳細をさらに制御できる一種の仮想知識データ (知識の長さや知識の長さなど)語彙は制御できます(詳細はお待ちください)。著者 は、GPT2、LlaMA、および Mistral に基づく言語モデル アーキテクチャに焦点を当てています。その中で、GPT2 は更新された Rotary Position Embedding (RoPE) テクノロジを使用しています。
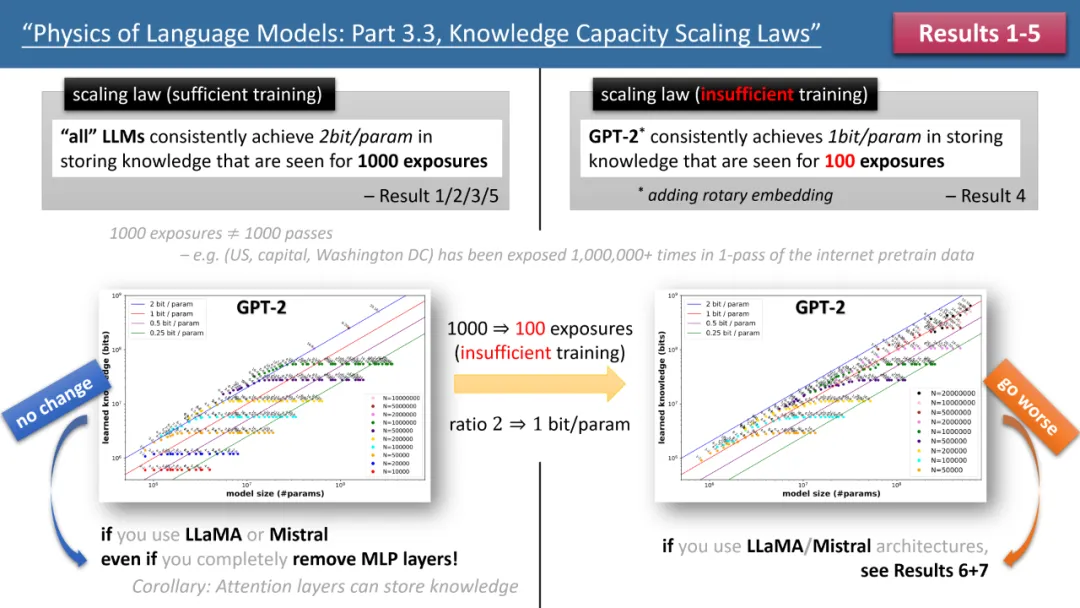 #左側の図は、十分なトレーニング時間が必要な場合のスケーリング則を示し、右側の図は、トレーニング時間が不十分な場合のスケーリング則を示します
#左側の図は、十分なトレーニング時間が必要な場合のスケーリング則を示し、右側の図は、トレーニング時間が不十分な場合のスケーリング則を示します
Top 図 1 は、著者が提案する最初の 5 つの法則を簡単にまとめたもので、左が「トレーニング時間が十分な場合」、右が「トレーニング時間が不十分な場合」の 2 つの状況に対応しています。一般的な知識 (中国の首都は北京であるなど) と、あまり新しい知識 (たとえば、清華大学の物理学科は 1926 年に設立されました) です。
トレーニング時間が十分であれば、GPT2 または LlaMA/Mistral のどのモデル アーキテクチャが使用されていても、モデルのストレージ効率が 2 ビット/パラメータに達する可能性があることを著者は発見しました。つまり、モデルごとの平均です。パラメータには 2 ビットの情報を保存できます。これはモデルの深さとは関係なく、モデルのサイズのみです。言い換えれば、7B モデルは、適切にトレーニングされていれば、140 億ビットの知識を保存できます。これは、ウィキペディアとすべての英語の教科書に記載されている人間の知識を合わせたものよりも多くなります。
さらに驚くべきことは、従来の理論では、変圧器モデルの知識は主に MLP 層に保存されているということですが、著者の研究はこの見解を否定しています。すべての MLP 層が削除されたとしても、 、モデルはまだ 2 ビット/パラメータのストレージ効率を達成できます。
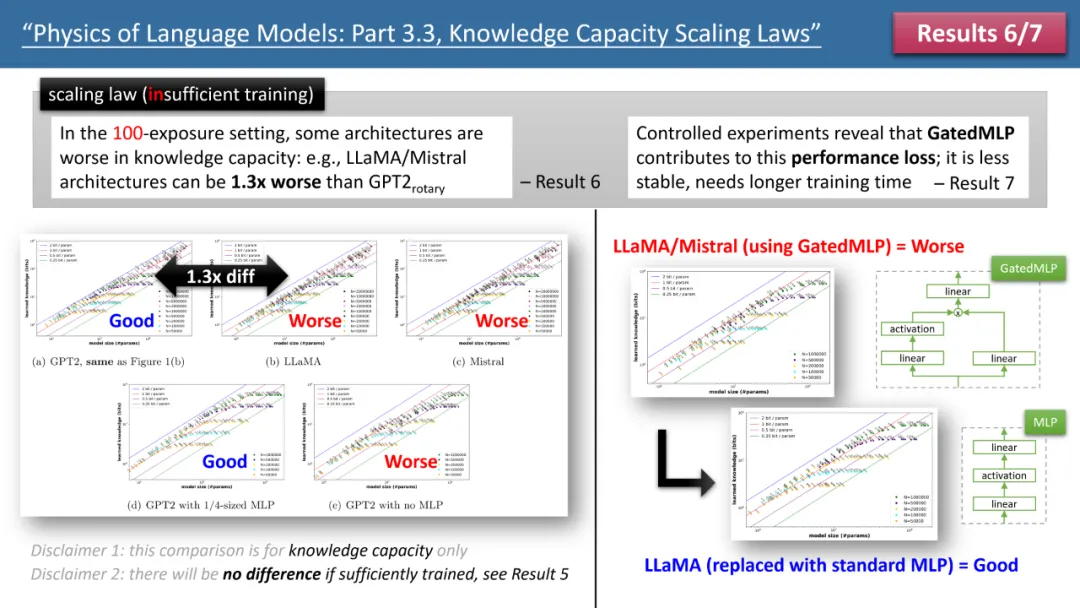
図 2: トレーニング時間が不十分な場合のスケーリング則
しかし、トレーニングを観察すると、時間が足りないと機種間の違いが顕著になってしまいます。上の図 2 に示すように、この場合、GPT2 モデルは LlaMA/Mistral よりも 30% 多くの知識を保存できます。これは、数年前のモデルがいくつかの点で今日のモデルを上回っていることを意味します。なぜこうなった?著者は、モデルと GPT2 の間の各差異を加算または減算して、LlaMA モデルのアーキテクチャを調整し、最終的に GatedMLP が 30% の損失の原因であることを発見しました。
強調しておきますが、GatedMLP はモデルの「最終的な」ストレージ レートに変化を引き起こしません。なぜなら、図 1 から、トレーニングが十分であれば変化しないことがわかるからです。ただし、GatedMLP では学習が不安定になるため、同じ知識でも学習時間が長くなり、学習セットにほとんど出現しない知識についてはモデルの保存効率が低下します。
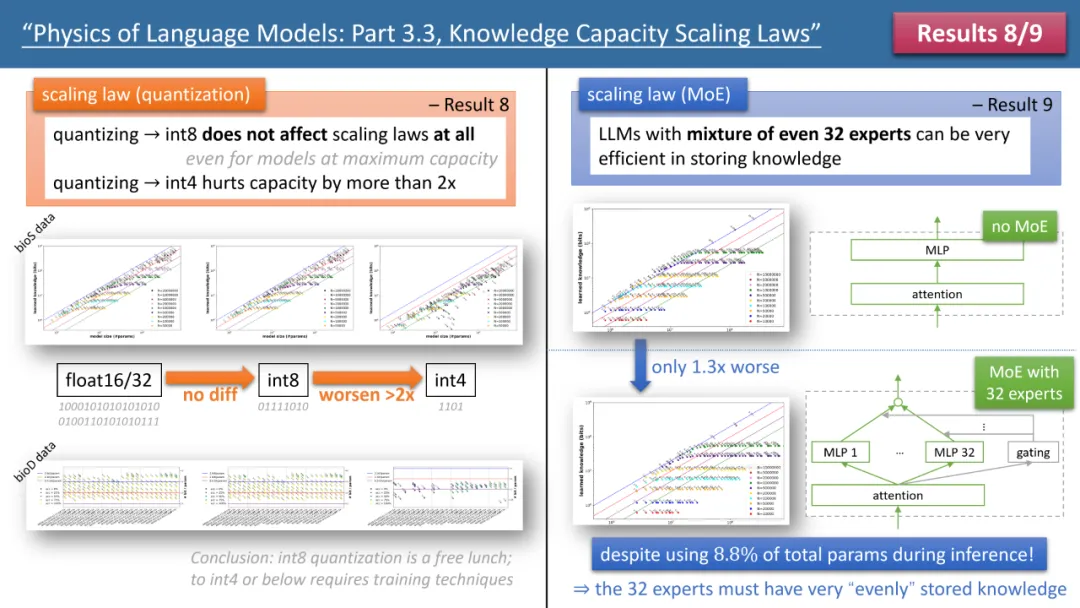
著者の法則 8法則 9 は、モデル スケーリング法則に対する量子化と MoE の影響を個別に研究し、その結論を上の図 3 に示します。 1 つの結果は、トレーニング済みモデルを float32/16 から int8 に圧縮しても、2 ビット/パラメーターのストレージ制限に達したモデルであっても、知識のストレージに影響を与えないことです。
これは、LLM が「情報理論の限界」の 1/4 に達する可能性があることを意味します。これは、int8 パラメーターはわずか 8 ビットですが、各パラメーターは平均して 2 ビットの知識を保存できるためです。著者は、これは普遍的な法則であり、知識表現の形式とは何の関係もない、と指摘する。
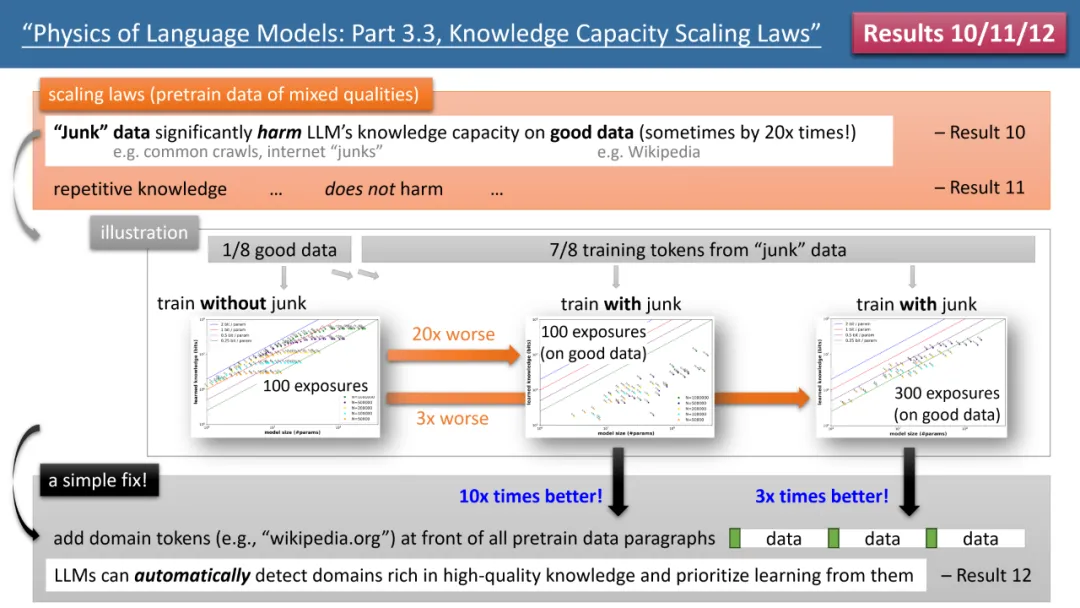
最も顕著な結果は、著者の法則 10 ~ 12 から得られます (図 4 を参照)。 (事前) トレーニング データの場合、1/8 は高品質の知識ベース (Baidu Encyclopedia など) から得られ、7/8 は低品質のデータ (一般的なクロールやフォーラムでの会話、さらには完全にランダムなゴミなど) から得られます。データ)。
では、
低品質のデータは、LLM による高品質の知識の吸収に影響を及ぼしますか?その結果は驚くべきもので、たとえ高品質データのトレーニング時間が一定であったとしても、低品質データの「存在自体」によって、モデルが高品質の知識を蓄積する量が 20 分の 1 に減少する可能性があります。高品質データの学習時間が 3 倍に延長されたとしても、知識の蓄えは 3 分の 1 に減少します。これは金を砂の中に投げ込むようなもので、高品質のデータが無駄にされています。
それを修正する方法はありますか?著者は、すべての (事前) トレーニング データに独自の Web サイトのドメイン名トークンを追加するだけの、シンプルだが非常に効果的な戦略を提案しました。たとえば、すべての Wikipedia データを wikipedia.org に追加します。このモデルでは、どの Web サイトに「ゴールド」ナレッジがあるかを特定するための事前知識は必要ありませんが、事前トレーニング プロセス中に、高品質のナレッジを持つWeb サイトを 自動的に検出し、 自動的に これを行うことができます。高品質のデータによりストレージ容量が解放されます。
著者は、検証するための簡単な実験を提案しました。高品質のデータが特別なトークンで追加された場合 (特別なトークンであれば何でもよく、モデルはそれがどのトークンであるかを知る必要はありません)事前に) を実行すると、モデルの知識記憶容量が即座に 10 倍に増加します。すごいと思いませんか?したがって、ドメイン名トークンを事前トレーニング データに追加することは、非常に重要なデータ準備操作です。#図 4: スケーリングの法則、モデルの欠陥、および事前トレーニング データに「一貫性のない知識の品質」がある場合のそれらの修復方法
結論
著者は、データを合成することによって、トレーニング プロセス中にモデルが獲得した知識の総量を計算する方法を「」に使用できると考えています。モデルのアーキテクチャ、トレーニング方法を評価し、「データ準備」は体系的で正確なスコアリング システムを提供します。これは従来のベンチマーク比較とはまったく異なり、より信頼性が高くなります。彼らは、これが将来の LLM の設計者がより多くの情報に基づいた意思決定を行うのに役立つことを期待しています。
以上がLlama アーキテクチャは GPT2 より劣っていますか?魔法のトークンで記憶力が10倍になる?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7449
7449
 15
1374
52
77
11
14
7
15
1374
52
77
11
14
7

 オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
0.この記事は何をするのですか?私たちは、多用途かつ高速な最先端の生成単眼深度推定モデルである DepthFM を提案します。従来の深度推定タスクに加えて、DepthFM は深度修復などの下流タスクでも最先端の機能を実証します。 DepthFM は効率的で、いくつかの推論ステップ内で深度マップを合成できます。この作品について一緒に読みましょう〜 1. 論文情報タイトル: DepthFM: FastMonocularDepthEstimationwithFlowMatching 著者: MingGui、JohannesS.Fischer、UlrichPrestel、PingchuanMa、Dmytr
 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI は確かに数学を変えつつあります。最近、この問題に細心の注意を払っている陶哲軒氏が『米国数学協会会報』(米国数学協会会報)の最新号を送ってくれた。 「機械は数学を変えるのか?」というテーマを中心に、多くの数学者が意見を述べ、そのプロセス全体は火花に満ち、ハードコアで刺激的でした。著者には、フィールズ賞受賞者のアクシャイ・ベンカテシュ氏、中国の数学者鄭楽軍氏、ニューヨーク大学のコンピューター科学者アーネスト・デイビス氏、その他業界で著名な学者を含む強力な顔ぶれが揃っている。 AI の世界は劇的に変化しています。これらの記事の多くは 1 年前に投稿されたものです。
 iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhoneのセルラーデータインターネット速度が遅い:修正
May 03, 2024 pm 09:01 PM
iPhone のモバイル データ接続に遅延や遅い問題が発生していませんか?通常、携帯電話の携帯インターネットの強度は、地域、携帯ネットワークの種類、ローミングの種類などのいくつかの要因によって異なります。より高速で信頼性の高いセルラー インターネット接続を実現するためにできることがいくつかあります。解決策 1 – iPhone を強制的に再起動する 場合によっては、デバイスを強制的に再起動すると、携帯電話接続を含む多くの機能がリセットされるだけです。ステップ 1 – 音量を上げるキーを 1 回押して放します。次に、音量小キーを押して、もう一度放します。ステップ 2 – プロセスの次の部分は、右側のボタンを押し続けることです。 iPhone の再起動が完了するまで待ちます。セルラーデータを有効にし、ネットワーク速度を確認します。もう一度確認してください 修正 2 – データ モードを変更する 5G はより優れたネットワーク速度を提供しますが、信号が弱い場合はより適切に機能します
 超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
世界は狂ったように大きなモデルを構築していますが、インターネット上のデータだけではまったく不十分です。このトレーニング モデルは「ハンガー ゲーム」のようであり、世界中の AI 研究者は、データを貪欲に食べる人たちにどのように餌を与えるかを心配しています。この問題は、マルチモーダル タスクで特に顕著です。何もできなかった当時、中国人民大学学部のスタートアップチームは、独自の新しいモデルを使用して、中国で初めて「モデル生成データフィード自体」を実現しました。さらに、これは理解側と生成側の 2 つの側面からのアプローチであり、両方の側で高品質のマルチモーダルな新しいデータを生成し、モデル自体にデータのフィードバックを提供できます。モデルとは何ですか? Awaker 1.0 は、中関村フォーラムに登場したばかりの大型マルチモーダル モデルです。チームは誰ですか?ソフォンエンジン。人民大学ヒルハウス人工知能大学院の博士課程学生、ガオ・イージャオ氏によって設立されました。
 アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
最近、軍事界は、米軍戦闘機が AI を使用して完全自動空戦を完了できるようになったというニュースに圧倒されました。そう、つい最近、米軍のAI戦闘機が初めて公開され、その謎が明らかになりました。この戦闘機の正式名称は可変安定性飛行シミュレーター試験機(VISTA)で、アメリカ空軍長官が自ら飛行させ、一対一の空戦をシミュレートした。 5 月 2 日、フランク ケンダル米国空軍長官は X-62AVISTA でエドワーズ空軍基地を離陸しました。1 時間の飛行中、すべての飛行動作が AI によって自律的に完了されたことに注目してください。ケンダル氏は「過去数十年にわたり、私たちは自律型空対空戦闘の無限の可能性について考えてきたが、それは常に手の届かないものだと思われてきた」と語った。しかし今では、
