

ユーザープロファイリングアルゴリズム: 歴史、現状、そして将来

1. ユーザー ポートレートの概要
ポートレートは、人間が理解でき、機械が読み書きできる構造化されたユーザーの説明です。パーソナライズされたサービスを提供するだけでなく、企業の戦略的意思決定やビジネス分析においても重要な役割を果たします。
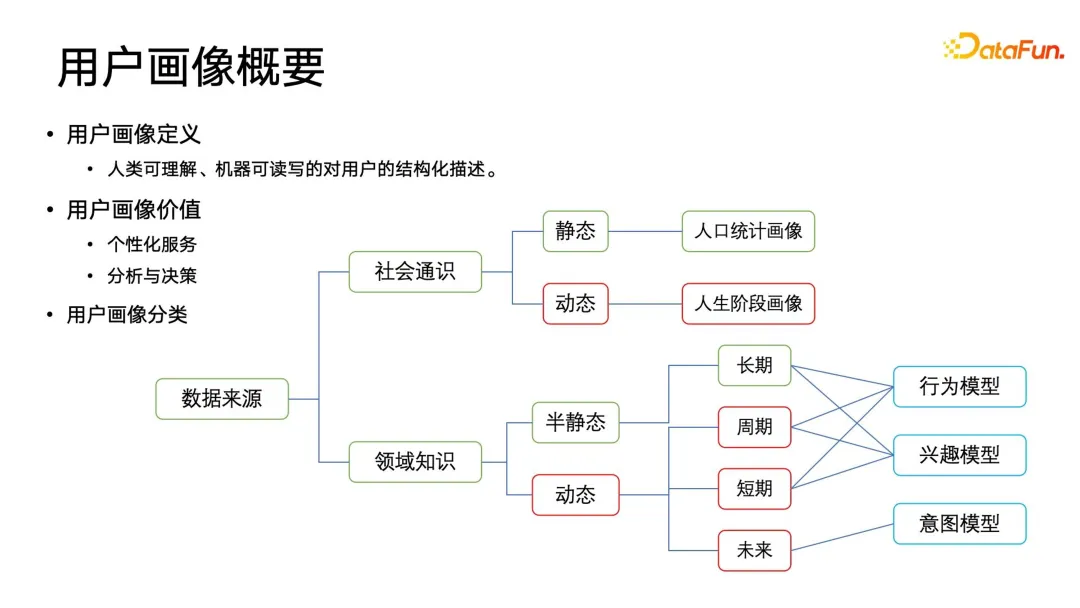
1. 肖像画の分類
データソースに応じて、社会一般知識カテゴリと分野知識カテゴリに分類されます。一般的な社会的ポートレートは、時間次元に応じて静的カテゴリーと動的カテゴリーに分類できます。最も一般的な静的一般的社会的ポートレートには、性別、戸籍、出身校などの人口統計的特徴が含まれます。これらのコンテンツは、比較的長期間にわたって表示されます。ウィンドウは比較的静的であるため、写真での使用に加えて、人口統計、人口統計学、社会学などでもよく使用されます。動的な社会全体のポートレートはより重要であり、ライフ ステージ ポートレートとも呼ばれます。たとえば、電子商取引、人々の収入はキャリアの発展とともに変化し続け、買い物の傾向も変化するため、これらのライフ ステージ ポートレートは非常に実用的です。価値。
上記の一般的なポートレートに加えて、企業はさらに多くのドメイン知識のポートレートを構築する場合があります。ドメイン知識のポートレートは、時間の次元から半静的と動的に分類でき、さらに長期、周期的、短期、将来の属性ポートレートに細分化できます。これらの時間次元のポートレートは、行動モデル、関心モデル、意図モデルなどの概念フィールドと絡み合っています。
行動モデルは主に、ユーザーが毎朝通勤中に何をするか、夕方仕事を終えてから何をするか、平日に何をするかなど、ユーザーの周期的な行動を追跡します。 、週末に何をするか、周期的な行動を待つべきか。インタレスト モデルは、ドメイン知識内のタグの特定の共同モデリングと並べ替えを実行します。たとえば、ユーザーは APP などのプラットフォーム製品と対話した後に操作ログを取得できます。ログは関連付けられ、解析されて、構造化およびラベル付けされたデータを抽出できます。それらはカテゴリに分割され、特定の重みが与えられ、最終的に特定の関心プロファイルを形成するために並べ替えられます。意図モデルはむしろ未来時制であり、ユーザーの将来の意図を予測するものであることに注意してください。しかし、新規ユーザーが対話する前に、そのユーザーの考えられる意図をどのように予測するのでしょうか?この問題は、リアルタイムおよび将来のポートレートにさらに偏っており、ポートレート データの全体的なインフラストラクチャ構造に対する要件も高くなります。
#2. ユーザー ポートレートの基本的なアプリケーション アーキテクチャ
画像の概念と一般的な分類を理解した後、次に、ユーザーポートレートの基本的なアプリケーションフレームワークを簡単に紹介します。全体のフレームワークは 4 つのレベルに分けることができます。1 つ目はデータ収集、2 つ目はデータの前処理、3 つ目はこれらの処理されたデータに基づくポートレートの構築と更新、そして最後にアプリケーション層です。使用プロトコルは、アプリケーション層により、下流のユーザーがさまざまなアプリケーションで画像をより便利に、迅速かつ効率的に使用できるようになります。
このフレームワークから、ユーザー プロファイリング アプリケーションとユーザー プロファイリング アルゴリズムは、特に広範かつ複雑な意味を理解する必要があることがわかります。なぜなら、私たちが直面しているのは単純なラベルだけではなく、さまざまな前処理が必要だからです。高品質のデータを取得し、より自信に満ちたポートレートを構築するための方法。これには、データマイニング、機械学習、ナレッジグラフ、統計学習などのさまざまな側面が関係します。ユーザー ポートレートと従来の検索推奨アルゴリズムの違いは、ドメインの専門家と緊密に連携して、反復とサイクルでより高品質のポートレートを継続的に構築する必要があることです。

2. オントロジーに基づく従来のユーザーのポートレート
#ユーザー ポートレートは、ユーザーの行動データと情報を徹底的に分析することで確立された概念です。ユーザーの興味、好み、行動パターンを理解することで、ユーザーにパーソナライズされたサービスとエクスペリエンスをより適切に提供できるようになります。
初期の頃、ユーザー ポートレートは主にオントロジーの概念に由来するナレッジ グラフに依存していました。一方、存在論は哲学のカテゴリーに属します。まず、オントロジーの定義は肖像画の定義と非常によく似ており、人間が理解でき、機械が読み書きできる概念システムです。もちろん、この概念システム自体は非常に複雑になる可能性があり、エンティティ、属性、関係、公理で構成されます。オントロジーに基づくユーザー ポートレートの利点は、ユーザーとコンテンツの分類が容易であり、人間が直感的に理解できるデータ レポートを作成し、レポートの関連する結論に基づいて意思決定を行うのに便利であることです。非ディープラーニング時代になぜこの手法が選ばれるのか 技術的な形式。
次に、オントロジーの基本概念をいくつか紹介します。オントロジーを構築するには、まずドメイン知識を概念化し、エンティティ、属性、関係、公理を構築し、それらを RDF や OWL などの機械可読形式に処理する必要があります。もちろん、より単純なデータ形式を使用したり、オントロジーをデータの保存、読み取り、書き込み、分析ができるリレーショナル データベースやグラフ データベースに縮退したりすることもできます。この種のポートレートを取得する方法は、一般に、ドメインの専門家を通じて構築するか、既存の業界標準に基づいて強化および改良することです。たとえば、タオバオが採用している製品ラベル システムは、実際にはさまざまな製造品業界に対する国の公的基準を参考にしており、これに基づいて強化され、反復されています。

次の図は、3 つのノードを含む非常に単純なオントロジーの例です。図内のエンティティは、エンターテイメント分野の関心タグです。たとえば、Netflix などのプラットフォームには多くの映画があります。各映画には一意の ID があり、各映画にはタイトルや主演などの独自の属性があります。このエンティティは、犯罪をテーマにしたシリーズや犯罪シリーズにも属します。アクション映画のサブジャンルに属します。この視覚的な図に基づいて、下図の右側に示すように RDF テキスト文書を作成します。この文書では、直感的に理解できるエンティティの属性関係に加えて、制約などのいくつかの公理も定義されています。映画の基本的な概念領域に対してのみ作用できます。映画の監督をエンティティとして使用してオントロジーに組み込むなど、他の概念領域がある場合、映画監督は「」属性を持つことはできません。タイトルがある」。上記はオントロジーについての簡単な紹介です。

オントロジーに基づくユーザー プロファイリングの初期には、構築された構造化タグの重みを計算するために TF-IDF と同様の方法が使用されていました。 . . TF-IDFはこれまで主に検索フィールドやテキスト件名フィールドで使用されていました.主に特定の検索語や対象単語の重みを計算します.ユーザーのポートレートに適用する場合は,次のように少し制限して変形するだけで済みます.前の例では、TF は、このカテゴリのタグでユーザーが視聴した映画またはショート ビデオの数をカウントします。IDF は、まずユーザーがタグの各カテゴリで視聴した映画またはショート ビデオの数と、その合計数をカウントします。すべての履歴ビューを取得し、図の式 IDF および TF *IDF に従って計算します。 TF-IDF の計算方法は非常に単純で安定しており、解釈可能で使いやすいです。
しかし、その欠点も明らかです: TF-IDF はタグの粒度には非常に敏感ですが、オントロジー構造自体には鈍感です。たとえば、ユーザーが特定のタグの下で特定のビデオをたまにしか見ない場合、TF は非常に小さく、IDF は非常に大きくなり、TF-IDF はその人気に近い値になる可能性があります。さらに重要なのは、ユーザーのポートレートを時間の経過とともに更新および調整する必要があるため、従来の TF-IDF 手法はこの状況には適していません。したがって、研究者らは、動的な更新のニーズを満たすために、オントロジーの構造化表現に基づいて重み付けされたユーザー ポートレートを直接構築する新しい方法を提案しました。

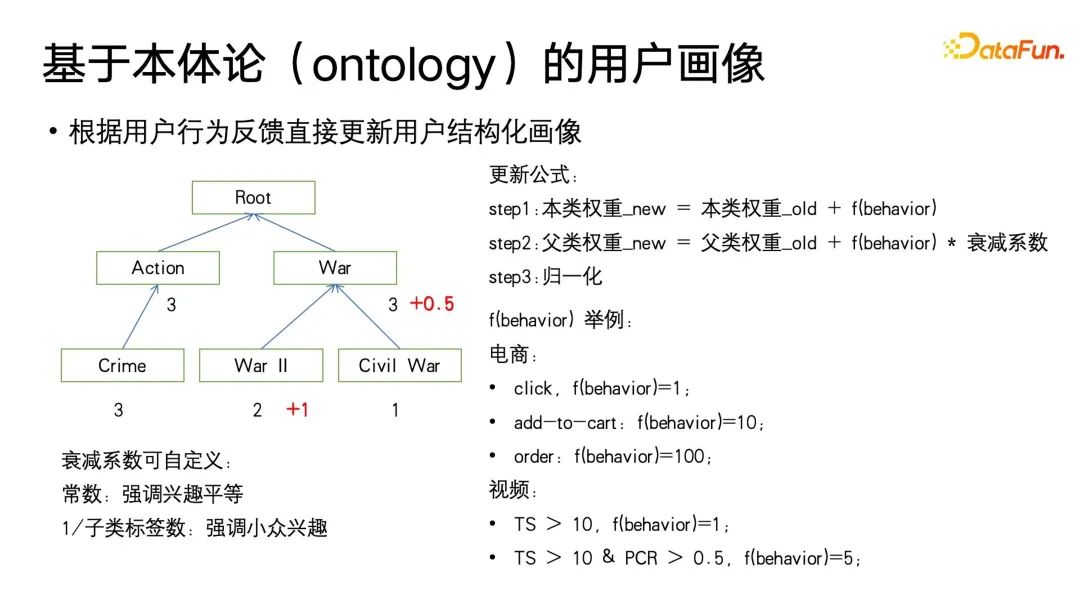
このアルゴリズムは、オントロジーのリーフ カテゴリから開始され、対応するラベルの下でユーザーのメディア消費行動を使用して重みを更新します。重みは 0 に初期化され、f行動に基づいて続行されます ユーザーの動作によって定義される関数。 fbehavior 関数は、電子商取引分野でのクリック、追加購入と注文、またはビデオ分野での再生と完了など、ユーザー消費のさまざまなレベルに基づいて、さまざまな暗黙的なフィードバック信号を提供します。同時に、電子商取引の消費行動では注文>購入>クリック、動画の消費では再生完了率の向上、再生時間の延長など、ユーザーの行動ごとに異なる強度のフィードバックシグナルを与えることになります。より強力な fbehavior 値も設定されます。
リーフ クラスのターゲット シグネチャの重みを更新した後、親クラスの重みを更新する必要があります。親クラスを更新する場合、1 未満の減衰係数を更新する必要があることに注意してください。定義される。なぜなら、図に示すように、ユーザーは「戦争」のサブカテゴリ「第二次世界大戦」には興味があるかもしれないが、他の戦争テーマには興味がない可能性があるからです。この減衰係数は、ハイパーパラメータとしてカスタマイズできます。この定義は、親カテゴリに対する各サブカテゴリの関心の寄与が等しいことを強調しています。サブカテゴリ ラベルの数の逆数を減衰係数として使用することもできるため、より強調されます。ニッチな興味に関するものです。興味、たとえば、いくつかの大きな親カテゴリ ノードには、広範で密接に関連していないサブカテゴリ テーマが含まれています。それらの間の視聴者は作品の数によって決まります。通常、そのような作品の数は非常に多くなります。減衰速度は適切に設定して速くすることができます。小さいサブカテゴリのラベルはニッチな関心事である可能性があり、作品はそれほど多くありません。サブカテゴリのトピック間の関係は比較的密接であり、減衰速度はより小さくなるように適切に設定することができる。つまり、オントロジーで定義されたこれらのドメイン知識属性に基づいて減衰係数を設定できます。
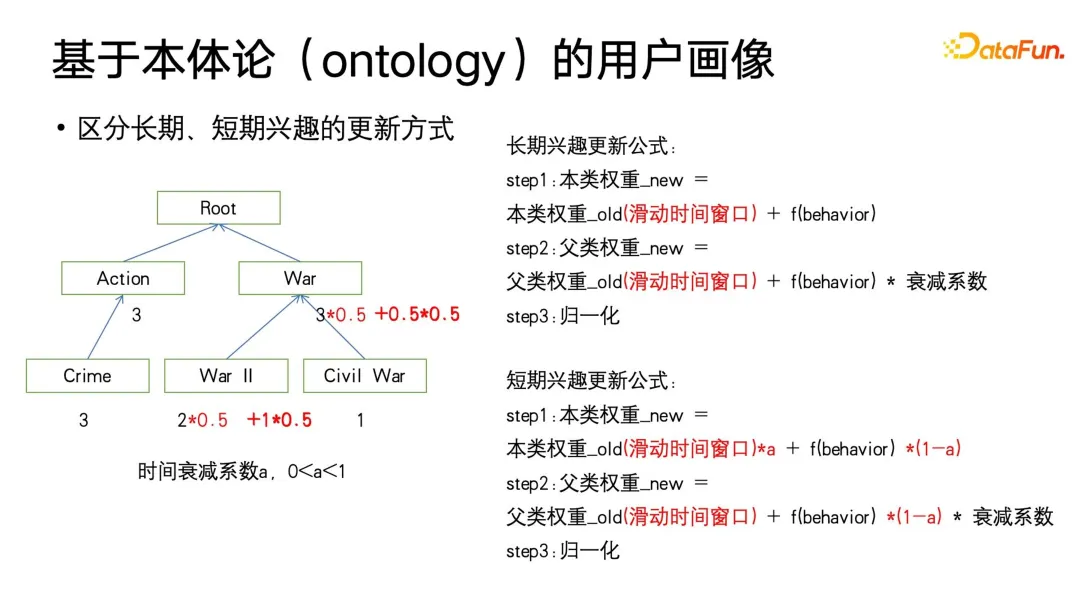
上記の方法は、構造化タグの更新効果を達成でき、基本的に TF-IDF 効果と同等か、それを超える効果がありますが、次の点が欠けています。 1 つのタイム スケール属性、つまり、タイム スケールに対してより敏感なポートレートを構築する方法。
私たちはまず、重み自体の更新をさらに調整できるのではないかと考えました。長期的なユーザー ポートレートと短期的なユーザー ポートレートを区別する必要がある場合、重みにスライディング ウィンドウを追加し、時間減衰係数 a (0 ~ 1 の間) を定義できます。スライディング ウィンドウの機能は、ユーザーのみに焦点を当てることです。ユーザーの長期的な興味もライフステージの変化とともに徐々に変化するため、ウィンドウ期間内の行動を重視し、ウィンドウ以前のユーザーの行動に焦点を当てないでください。 1、2年映画を観ましたが、その後は気に入らなくなりました。
さらに、この式が運動量を駆動する Adam 勾配更新メソッドに似ていることもわかります。重みの更新を特定の値に集中させるために、 a のサイズを調整します。歴史上または現在において。具体的には、より小さい a を与えると、より現在に焦点が当てられ、歴史的蓄積の減衰が大きくなります。
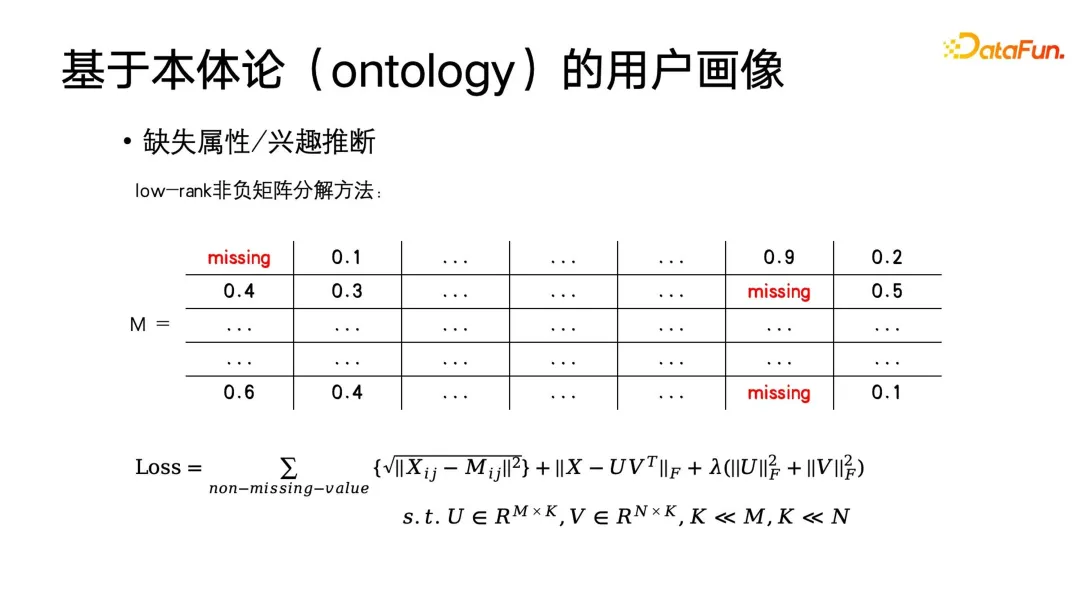
上記の方法論はユーザーが受け取った情報に限定されていますが、通常は大量のタグが失われることに遭遇します。これは、ユーザーのコールド スタートや、ユーザーがこの種のコンテンツにさらされない状況が考えられますが、ユーザーがそれを好まないという意味ではありません。このような場合、利息の完了と利息の推論が必要になります。
最も基本的な方法は、レコメンデーション システムで協調フィルタリングを使用してポートレートを完成させることです。ラベル マトリックスがあるとします。横軸はユーザー、縦軸は各ラベルです。これは非常に大きな行列です。内部の要素は、このタグに対するユーザーの関心を表します。これらの要素は 0 または 1、または関心の重みである可能性があります。もちろん、このマトリクスを人口統計のポートレートに合わせて変形することもでき、例えば、学生なのか、専門家なのか、どのような職業なのかといったラベルを表現することもできます。この行列を構築するためのコーディング手法を使用します。また、行列分解を適用して行列分解を取得し、欠落している固有値を補完することもできます。このときの最適化の目標は、次の図に示すとおりです。
この式からわかるように、元の行列は M で、完成行列は に近い可能性があり、X が低ランクの行列であることも期待されます。多数のユーザーの興味が似ていると仮定しているため. 似たユーザーの仮定の下では, ラベル行列は低ランクでなければなりません. 最後に, この行列を正則化します. 非負行列因数分解の目標を完了します.この方法は、実際には、私たちが最もよく知っている確率的勾配降下法を使用して解くことができます。
もちろん、行列分解を使用して欠落している属性や関心を推測することに加えて、従来の機械学習手法も使用できます。同様のユーザーは同様の興味を持っていると依然として想定されています。現時点では、KNN 分類または回帰を使用して興味を推測できます。具体的な方法は、ユーザーの最近傍関係マップを確立し、最も大きいタグを追加することです。ユーザーの k 個の最近傍のうちの近傍の数。加重平均は、ユーザーの欠損属性に割り当てられます。近隣関係グラフは自分で構築することも、ソーシャル ネットワークのユーザー ポートレートや B サイドのビジネス ポートレート (エンタープライズ マップ) などの既製の近隣グラフ構造にすることもできます。

上記は、オントロジーによる従来のポートレートの構築の紹介です。従来のポートレート構築アルゴリズムの価値は、非常にシンプル、直接的、理解しやすく、実装が容易であると同時に、その効果が優れているため、特に高次のアルゴリズムに完全に置き換えられることはありません。ポートレートをデバッグする必要がある場合、従来のアルゴリズムのクラスの方が利便性が高くなります。
3. プロファイリング アルゴリズムとディープ ラーニング
##1 。プロファイリング アルゴリズムに対するディープ ラーニング アルゴリズムの価値
ディープ ラーニングの時代に入った後は、誰もがディープ ラーニング アルゴリズムを組み合わせてプロファイリング アルゴリズムの効果をさらに向上させることを望んでいます。プロファイリングアルゴリズムに対するディープラーニングの価値は何ですか?
まず第一に、より強力なユーザー表現機能が必要です。深層学習と機械学習の分野には、表現学習または計量学習という特別なカテゴリがあり、この学習方法はこれは、非常に強力なユーザー表現を構築するのに役立ちます。 2 つ目は、より単純なモデリング プロセスです。ディープ ラーニングのエンドツーエンド アプローチを使用して、モデリング プロセスを簡素化できます。多くの場合、必要なのは、特徴を構築し、いくつかの特徴エンジニアリングを行って、ニューラル ネットワークを次のように扱うことだけです。ブラック ボックス。詳細には注意を払わずに、特徴が入力され、ラベルやその他の監視情報が出力で定義されます。
繰り返しになりますが、ディープラーニングの強力な表現能力に基づいて、多くのタスクにおいても高い精度を実現しました。さらに、深層学習はマルチモーダル データを均一にモデル化することもできます。従来のアルゴリズムの時代では、データの前処理に多くのエネルギーを費やす必要がありました。たとえば、上記のビデオタイプのタグの抽出には、最初にビデオを切り取り、次に被写体を抽出し、次に被写体を識別するという非常に複雑な前処理が必要です。顔を 1 つずつ作成し、対応するタグを追加して、最後にポートレートを作成します。ディープ ラーニングを使用すると、統一されたユーザーまたはアイテムの式が必要な場合に、マルチモーダル データをエンドツーエンドで直接処理できます。
最後に、反復中にコストをできる限り削減したいと考えています。前の記事で述べたように、プロファイリング アルゴリズムの反復と、検索プロモーションなどの他のタイプのアルゴリズムの反復の違いは、多くの手動による参加が必要であることです。最も信頼できるデータは、人によって注釈が付けられたデータ、またはアンケートなどの方法で収集されたデータである場合がありますが、このデータを取得するコストは非常に高いため、より低いコストでより多くの注釈値を持つデータを取得するにはどうすればよいでしょうか?この問題にも、ディープラーニングの時代にはさらに多くのアイデアと解決策があります。

C-HMCNN はオントロジー構造です。はラベル予測のための古典的な深層学習手法であり、派手なネットワーク構造ではありませんが、ラベル、特に構造化されたラベルの分類または予測に適したアルゴリズム フレームワークを定義します。
核心は、階層構造ラベルを平坦化して予測することです。下図の右側に示すように、ネットワークは 3 つのラベル A/B の予測確率を直接与えます。 \C 、構造のレベル、深さなどを考慮する必要はありません。その損失数式の設計では、構造化タグに違反する結果を可能な限り罰することもできます。この数式では、最初に、リーフ カテゴリ B および C に対して古典的なクロスエントロピー損失が使用され、親カテゴリ p## に対して max(y
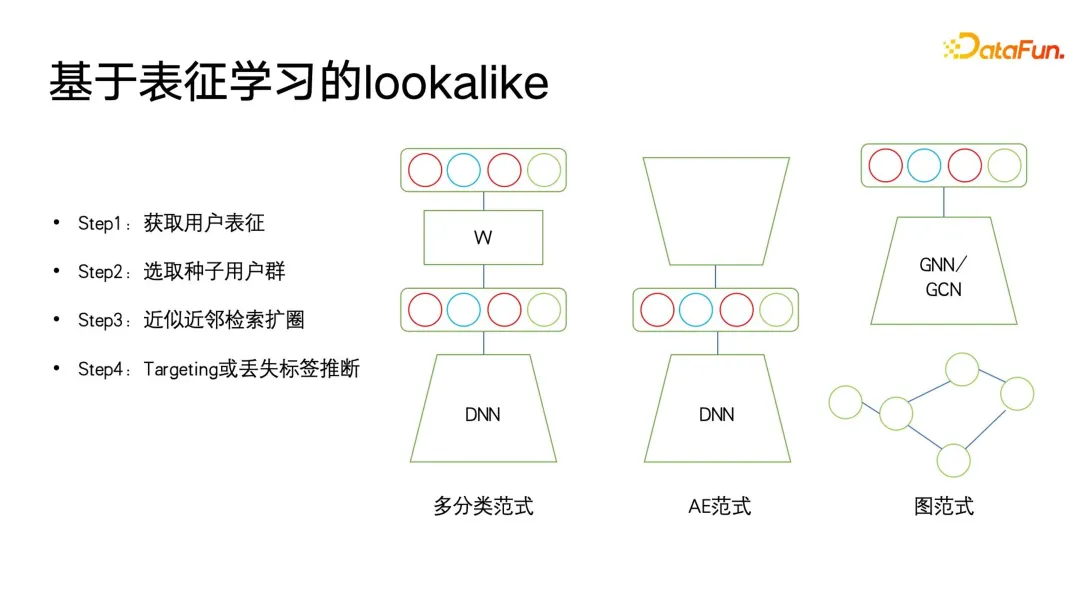
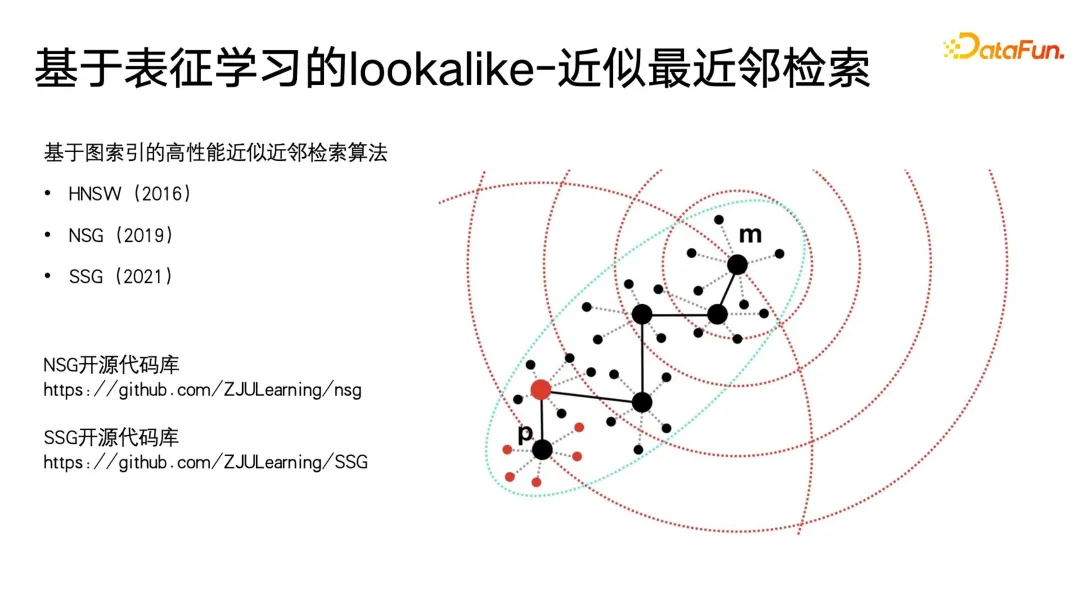
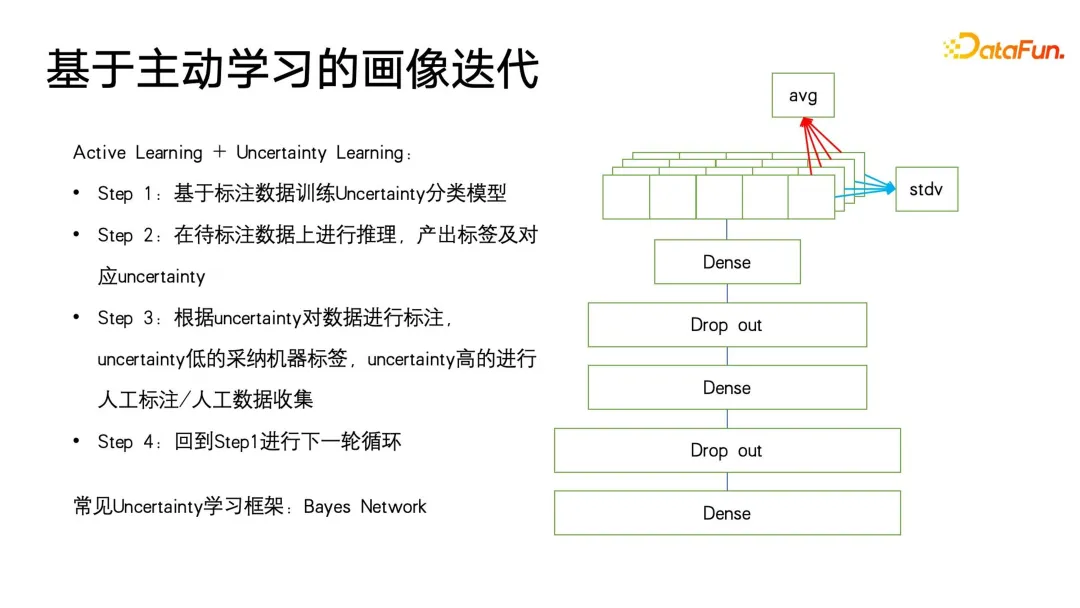
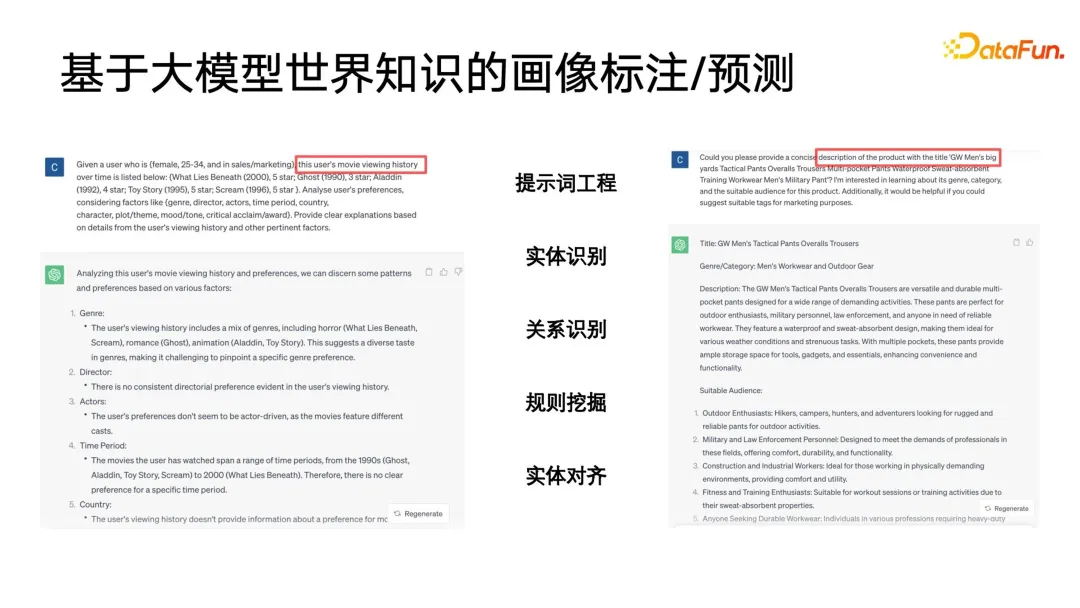
B が使用されます) #B, yCpC) を使用して構造情報を制約し、サブカテゴリが true と予測される場合にのみ、1- max(p##) を使用して親カテゴリ A を予測します。 #B, pC) を使用して、親クラスのターゲット ラベルが false の場合、サブカテゴリの予測が可能な限り 0 に近づくように強制され、それによって構造化されたラベル制約が実現されます。このモデリングの利点は、損失の計算が非常に簡単で、すべてのラベルを均等に予測し、ラベル ツリーの深さ情報をほとんど無視できることです。 最後に言及すべきことは、このメソッドでは各ラベルが 0 または 1 である必要があるということです。たとえば、PB はユーザーの好き嫌いを表すだけであり、複数のラベルを設定することはできません。マルチクラス LOSS 制約を確立するのはより難しいため、このモデルは、モデル化するときにすべてのラベルを平坦化し、0 と 1 を予測することと同じです。フラット化によって発生する可能性がある問題の 1 つは、ラベル ツリー構造内の親ラベルに多数のサブラベルがある場合、非常に大規模なマルチラベル分類問題に直面することです。これに対処する一般的な方法は次のとおりです。ユーザーが気づかない可能性があるものを事前にフィルタリングする何らかの手段を使用すること。 ユーザー ポートレートのアプリケーションでは、類似思考は次のようになります。頻繁に使用されます。ポートレートのダウンストリーム アプリケーションでは、類似機能を使用して、広告の潜在的なユーザー グループをターゲットにすることができます。また、類似機能を使用して、シード ユーザーに基づいてターゲット属性が欠落しているユーザーを検索し、これらのユーザーの対応する欠落属性を置換または表現することもできますシードユーザーと。 Lookalike のアプリケーションに最も必要なのは強力な表現学習器であり、以下の図に示すように、最も一般的に使用される表現モデリング手法には 3 種類あります。 1 つ目は、多分類法です。複数の分類ラベルのポートレート データがある場合、教師付き信号を使用して、必要なものをターゲットにして、よりターゲットを絞った表現を学習できます。特定のクラスのラベルは、方向ラベル欠落予測に非常に役立ちます。 2つ目は、AE(オートエンコーダ)パラダイムです。モデル構造は砂時計型です。監視情報に注意を払う必要はなく、エンコードを見つけるだけで済みます。このパラダイムは、監視データが十分でない場合に、より信頼性が高くなります。 3 番目のタイプはグラフ パラダイムです。現在、GNN や GCN などのグラフ ネットワークは、ポートレートなどの幅広いアプリケーションで使用されており、GNN は最大値に基づくことができます。この方法は教師なしトレーニングを実行し、ラベル情報を使用して教師ありトレーニングを実行することもでき、多分類パラダイムよりも優れています。ラベル情報を表現することに加えて、グラフ構造にはさらに多くのグラフ構造情報を埋め込むこともできるためです。グラフ構造が表示されない場合、グラフを構築する方法は数多くありますが、例えば、電子商取引分野で有名なレコメンデーションアルゴリズムであるswing i2iでは、ユーザーの共同購入や共同視聴履歴に基づいて2部グラフを構築します。このようなグラフ構造も非常に豊富であり、セマンティック情報はより適切なユーザー表現を学習するのに役立ちます。豊富な表現が得られたら、いくつかのシード ユーザーを選択して最近傍検索を使用して円を拡張し、拡張されたユーザーを使用して欠落しているタグまたはターゲットを推測できます。 最近傍検索は小規模なアプリケーションでは非常に簡単に実行できますが、数億個などの非常に大規模なデータでは実行できます。ライブユーザーが存在する大規模なプラットフォームでは、これらのユーザーに対するKNN検索は非常に時間がかかるタスクであるため、現在最も一般的に使用されている方法は、近似最近傍検索であり、その特徴は、精度を確保しながら効率性を犠牲にすることです。時間は、元の暴力的な捜索の 1/1000、1/10000、さらには 1/100000 にまで圧縮されます。 現在、近似最近傍検索の有効な手法はグラフインデックスに基づくベクトル検索アルゴリズムですが、これらの手法は現在の大規模モデルの時代において頂点に達しています。少し前に大規模モデルで最も人気のある概念の 1 つは RAG (検索拡張生成) です。テキスト検索の検索拡張で採用されている中心的な方法はベクトル検索です。最も一般的に使用される方法はグラフベースのベクトル検索です。最も広く使用されている方法は、メソッドには HNSW、NSG、SSG が含まれます。元のオープン ソース コードと後者 2 つの実装リンクも下の図に示されています。 ポートレートの反復のプロセスでは、まだそこにありますカバーできない盲点がいくつかあります。たとえば、消費行動が少ないユーザー プロファイルが適切に配置できない場合があり、最終的には、多くの方法が依然として手動収集に頼ることになります。しかし、アクティビティの低いユーザーが非常に多く、より価値のある代表的なユーザーをラベル付けに選択できれば、より価値のあるデータを収集できるため、アクティブ ラーニング フレームワークを導入しました。 。 まず、既存のアノテーション付きデータに基づいて、確率学習ベイジアン ネットワークの分野で古典的な手法である不確実性予測を備えた分類モデルをトレーニングします。ベイジアンネットワークの特徴は、予測する際に確率を与えるだけでなく、予測結果の不確実性も予測できることです。 ベイジアン ネットワークは、下の図の右側に示すように、実装が非常に簡単です。元のネットワーク構造にいくつかの特別な層を追加するだけです。途中にいくつかのドロップアウトを追加します。これらのネットワークのレイヤーを使用して、フィードフォワード ネットワークの一部のパラメーターをランダムに破棄します。ベイジアン ネットワークには複数のサブネットワークが含まれており、それぞれのサブネットワークはまったく同じネットワーク パラメーターを持ちますが、ドロップアウト層の特性により、各ネットワーク パラメーターがランダムにドロップされる確率は、ランダムにドロップされる場合と異なります。他のフィールドでのドロップアウトの使用方法とは異なり、ドロップアウトを使用する場合もドロップアウトは保持されます。他の分野では、ドロップアウトはトレーニング中にのみ実行され、すべてのパラメータは推論中に適用され、最終的にロジット値と確率値が計算されたときにのみ、ドロップアウトによって引き起こされた予測値のスケール2倍が復元されます。 ベイジアン ネットワークの違いは、すべてのドロップアウトのランダム性がフィードフォワード推論中に保持される必要があるため、各ネットワークはこのラベルの異なる確率を与え、このラベルの平均を求めることになります。確率のセット。この平均は、実際には投票の結果であり、予測したい確率値です。同時に、この確率値のセットの分散を計算して、予測の不確実性を表します。サンプルに異なるドロップアウト パラメータ式が適用されると、最終的に得られる確率値も異なり、確率値の分散が大きくなるほど、学習プロセスにおける確率の確実性は小さくなります。最後に、不確実性の高いラベル予測サンプルは手動でラベル付けでき、確実性の高いラベルの場合は機械ラベル付けの結果を直接使用できます。そしてアクティブ・ラーニングのフレームワークの最初のステップに戻って循環する 以上がアクティブ・ラーニングの基本的なフレームワークです。 大規模モデルの時代にモデル、大きなモデルの世界の知識もポートレートの注釈に導入できます。次の図は 2 つの簡単な例を示しています。左側では、大きなモデルがユーザーのポートレートに注釈を付けるために使用されており、ユーザーの閲覧履歴が特定の順序で編成されてプロンプトが形成されています。大きなモデルでは非常に詳細な情報を提供できることがわかります。ユーザーが好むジャンル、監督、俳優などの分析。右側は、製品のタイトルを分析し、その製品がどのカテゴリに属するかを推測するために大きなモデルに製品タイトルを与える大きなモデルです。 ここで、大きな問題は、大規模モデルの出力が構造化されておらず、比較的原始的なテキスト表現であり、何らかの後処理が必要であることであることがわかりました。例えば、大規模なモデルの出力に対してエンティティ認識、関係性認識、ルールマイニング、エンティティアライメントなどを実行する必要があり、これらの後処理はナレッジグラフやオントロジーのカテゴリーにおける基本的なアプリケーションルールに属します。 大きなモデルに関する世界の知識を肖像画の注釈に使用すると、より良い結果が得られ、労働力の一部を置き換えることができるのはなぜでしょうか?大規模なモデルはオープン ネットワークの幅広い知識に基づいてトレーニングされるのに対し、レコメンデーション システムや検索エンジンなどは、独自のクローズド プラットフォーム内のユーザーと製品ライブラリ間の一部の履歴データしか持たないため、これらのデータは実際には ID ベースです。それらの多くは相互に関連しており、既存のプラットフォームの閉じた知識を通して解釈するのは困難ですが、大規模なモデルの世界の知識は、閉じられたシステムに欠けている知識を埋めるのに役立ち、それによってより良いモデルを描くのに役立ちます。肖像画のラベル付けまたは予測。大きなモデルは、世界そのものの概念体系を高品質に抽象的に表現したものであるとさえ理解でき、これらの概念体系はポートレートやラベリングシステムに非常に適しています。
最後に、ユーザーポートレートの現在の制限と今後の開発の方向性を簡単にまとめておきます。 最初の質問は、既存のポートレートの精度をさらに向上させる方法です。精度向上を阻害する要因としては、仮想IDから自然人への統一が挙げられますが、実際にはユーザーは同一アカウントに複数の端末を持ち、複数のポートや複数のチャネルを持っている可能性があります。たとえば、ユーザーが別の APP にログインしていますが、これらの APP は同じグループに属しています。グループ内の自然人を接続し、すべての仮想 ID を同じ人にマッピングして、それを識別することはできますか? 2つ目は、家族共有アカウントの主体特定の問題です。この問題はビデオ分野、特に長いビデオの分野では非常に一般的であり、ユーザーは明らかに 40 歳前後の大人であるにもかかわらず、レコメンデーションがすべて漫画であるなど、悪質なケースによく遭遇します。家族はアカウントを共有しており、全員が個人的な興味を持っています。この状況に対応して、何らかの手段を使用して現在の時刻と行動パターンを特定し、ポートレートを迅速かつリアルタイムで更新し、現在の被写体が誰であるかを判断し、ターゲットを絞ったパーソナライズされたサービスを提供できないか。 3つ目は、マルチシナリオ連携におけるリアルタイムの意図予測です。プラットフォームが一定の段階まで発展しても、検索やプロモーションの画像はまだ比較的断片化されていることがわかりました。たとえば、ユーザーがおすすめのシーンに足を踏み入れたばかりで、検索の準備ができている場合があります。たった今のおすすめシーンのリアルタイムの意図について?おすすめの単語を検索する場合、または何かを検索したばかりの場合、この意図を使用して、ユーザーが見たい可能性のある他のカテゴリーのコンテンツを広めたり予測したりできますか?意図予測を行います。 クローズドオントロジーからオープンオントロジーへの移行は、イメージングの分野でも早急に解決する必要がある問題です。長い間、オントロジーの定義には比較的堅実な業界標準が使用されてきましたが、現在では、多くのシステムのオントロジーが、ショートビデオ プラットフォームやショートビデオ自体のさまざまなタグなどの増分更新に完全にオープンになっています。共創のもとに自然発生的に成長・爆発するなど、時代を経ても生まれ続けるホットワードやホットタグが数多く存在します。オープン オントロジーで画像の適時性を向上させ、ノイズを除去し、さらに探索して画像の精度を向上させるためにいくつかの方法を使用する方法も、研究する価値のある問題です。 最後に、ディープ ラーニングの時代において、プロファイリング アルゴリズム、特にディープ ラーニングを適用するプロファイリング アルゴリズムの解釈可能性を向上させる方法と、実装されたプロファイリングで大規模なモデルをより適切に使用できるようにする方法について説明します。アルゴリズムに関しては、これらが将来の研究の方向性となります。 以上が今回シェアした内容です、皆さんありがとうございました! A1: ポートレート用のアプリケーションのリンクは確かに比較的長いです。ポートレートが主にアルゴリズムを提供している場合、ポートレートの精度から下流モデルまでの精度損失には実際にギャップが存在します。実はポートレートABテストは特に推奨しているわけではなく、事業者に相談して、ユーザーの選定や設備投資の宣伝など、より運用性の高いアプリケーションシナリオに活用するのが良い方法だと思います。ビッグセールのクーポンとしてターゲットを絞った配信などのシナリオでABテストを実施します。効果はポートレートに直接基づいているため、比較的短いリンクでこの種のアプリケーション側の共同オンライン AB テストを検討できます。さらに、AB テストに加えて、最適化前後の画像に基づいて並べ替え結果をユーザーに推奨し、どちらが正しいかをユーザーに評価してもらう、別のテスト方法である相互検証も検討してはいかがでしょうか。より良い。たとえば、一部の大規模モデル メーカーでは、モデルに 2 つの結果を出力させ、どの大規模モデルがより良いテキストを生成するかをユーザーに決定させていることがわかります。実際、このような照合の方が効果的ではないかと思いますし、それはポートレートそのものにも直結します。 A2: テスト セットにドロップアウトがあるという意味ではありませんが、推論をテストするときに、ネットワーク内でドロップアウトのランダムな特性が依然として保持されることを意味します。ランダムな推論のため。 A3: 率直に言って、現時点では業界に非常に優れたソリューションはありません。ただし、方法は 2 つあります。1 つは、ローカライズされた大規模モデルの推論展開を行うために、相互に信頼できるサードパーティを検討することです。もう 1 つの、これも最近の新しい概念はフェデレーテッド ネットワークと呼ばれるものですが、これはフェデレーテッド ラーニングではありません。フェデレーテッド ネットワークに含まれる可能性のいくつかを見てみましょう。 A4: 注釈に加えて、ユーザーからの分析と推論もあります。既存のポートレートに基づいて、ユーザーの次の意図を推測したり、大量のユーザー データを収集して大規模なモデルを使用して、制約の下で一部の地域またはその他のユーザー パターンを分析したりできます。実際、これに関するオープンソースのデモがいくつかあり、この方向性を探ることができます。 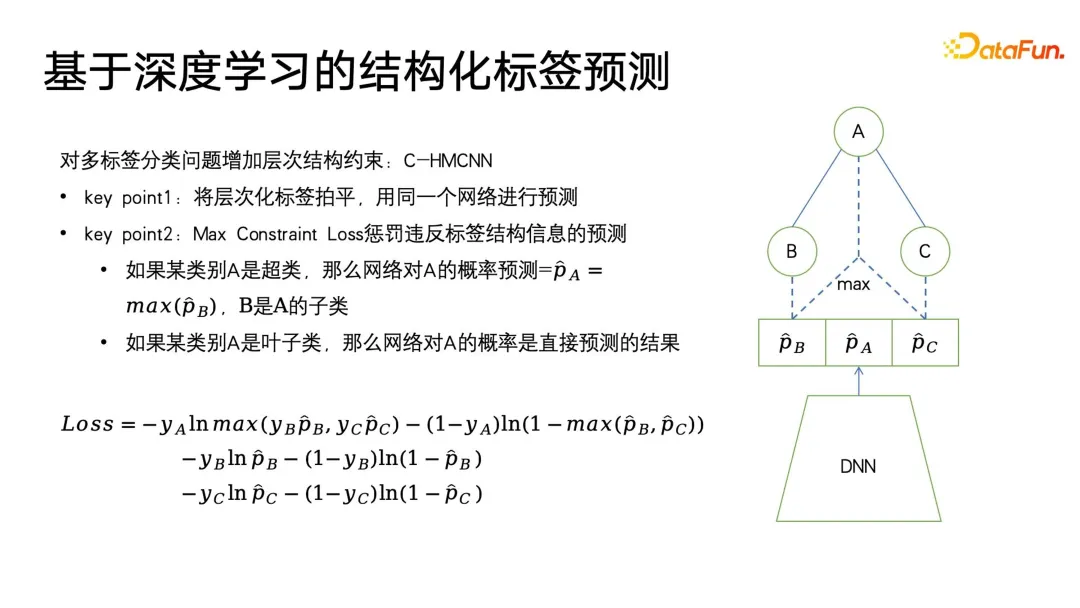
3. 表現学習に基づく類似機能
4. アクティブラーニングに基づくポートレートの反復
5. 大規模モデルの世界知識に基づくポートレートの注釈/予測
#4. 概要と展望

5. Q & A
#Q1: ポートレート処理と実用化の間のリンクは非常に長いです。実際のビジネスについて たくさんの質問があると思いますが、Fu Cong さんは肖像画の AB テストに参加した経験はありますか?
Q2: ベイジアン ネットワーク テスト セットでドロップアウトはありますか?
Q3: プライバシーとセキュリティの問題を考慮し、顧客データをエクスポートできない場合に大規模モデルの結果をどのように使用するか。
Q4: ラベル付け以外に、大規模モデルと組み合わせる場合に挙げられる組み合わせはありますか?
以上がユーザープロファイリングアルゴリズム: 歴史、現状、そして将来の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
19
22
15
1376
52
77
11
19
22


 Giteeページ静的なWebサイトの展開に失敗しました:単一のファイル404エラーをトラブルシューティングと解決する方法
Apr 04, 2025 pm 11:54 PM
Giteeページ静的なWebサイトの展開に失敗しました:単一のファイル404エラーをトラブルシューティングと解決する方法
Apr 04, 2025 pm 11:54 PM
GiteEpages静的Webサイトの展開が失敗しました:404エラーのトラブルシューティングと解像度Giteeを使用する
 H5プロジェクトの実行方法
Apr 06, 2025 pm 12:21 PM
H5プロジェクトの実行方法
Apr 06, 2025 pm 12:21 PM
H5プロジェクトを実行するには、次の手順が必要です。Webサーバー、node.js、開発ツールなどの必要なツールのインストール。開発環境の構築、プロジェクトフォルダーの作成、プロジェクトの初期化、コードの書き込み。開発サーバーを起動し、コマンドラインを使用してコマンドを実行します。ブラウザでプロジェクトをプレビューし、開発サーバーURLを入力します。プロジェクトの公開、コードの最適化、プロジェクトの展開、Webサーバーの構成のセットアップ。
 GOのどのライブラリが大企業によって開発されていますか、それとも有名なオープンソースプロジェクトによって提供されていますか?
Apr 02, 2025 pm 04:12 PM
GOのどのライブラリが大企業によって開発されていますか、それとも有名なオープンソースプロジェクトによって提供されていますか?
Apr 02, 2025 pm 04:12 PM
大企業または有名なオープンソースプロジェクトによって開発されたGOのどのライブラリが開発されていますか? GOでプログラミングするとき、開発者はしばしばいくつかの一般的なニーズに遭遇します...
 Beego ormのモデルに関連付けられているデータベースを指定する方法は?
Apr 02, 2025 pm 03:54 PM
Beego ormのモデルに関連付けられているデータベースを指定する方法は?
Apr 02, 2025 pm 03:54 PM
Beegoormフレームワークでは、モデルに関連付けられているデータベースを指定する方法は?多くのBEEGOプロジェクトでは、複数のデータベースを同時に操作する必要があります。 Beegoを使用する場合...
 Redisストリームを使用してGO言語でメッセージキューを実装する場合、user_idタイプの変換の問題を解決する方法は?
Apr 02, 2025 pm 04:54 PM
Redisストリームを使用してGO言語でメッセージキューを実装する場合、user_idタイプの変換の問題を解決する方法は?
Apr 02, 2025 pm 04:54 PM
redisstreamを使用してGo言語でメッセージキューを実装する問題は、GO言語とRedisを使用することです...
 H5ページの生産には継続的なメンテナンスが必要ですか?
Apr 05, 2025 pm 11:27 PM
H5ページの生産には継続的なメンテナンスが必要ですか?
Apr 05, 2025 pm 11:27 PM
H5ページは、コードの脆弱性、ブラウザー互換性、パフォーマンスの最適化、セキュリティの更新、ユーザーエクスペリエンスの改善などの要因のため、継続的に維持する必要があります。効果的なメンテナンス方法には、完全なテストシステムの確立、バージョン制御ツールの使用、定期的にページのパフォーマンスの監視、ユーザーフィードバックの収集、メンテナンス計画の策定が含まれます。
 Python hourglassグラフ図面:可変未定義エラーを避ける方法は?
Apr 01, 2025 pm 06:27 PM
Python hourglassグラフ図面:可変未定義エラーを避ける方法は?
Apr 01, 2025 pm 06:27 PM
Python:Hourglassグラフィック図面と入力検証この記事では、Python NoviceがHourglass Graphic Drawingプログラムで遭遇する可変定義の問題を解決します。コード...
