

AI指向のデータガバナンスシステムを構築するにはどうすればよいでしょうか?


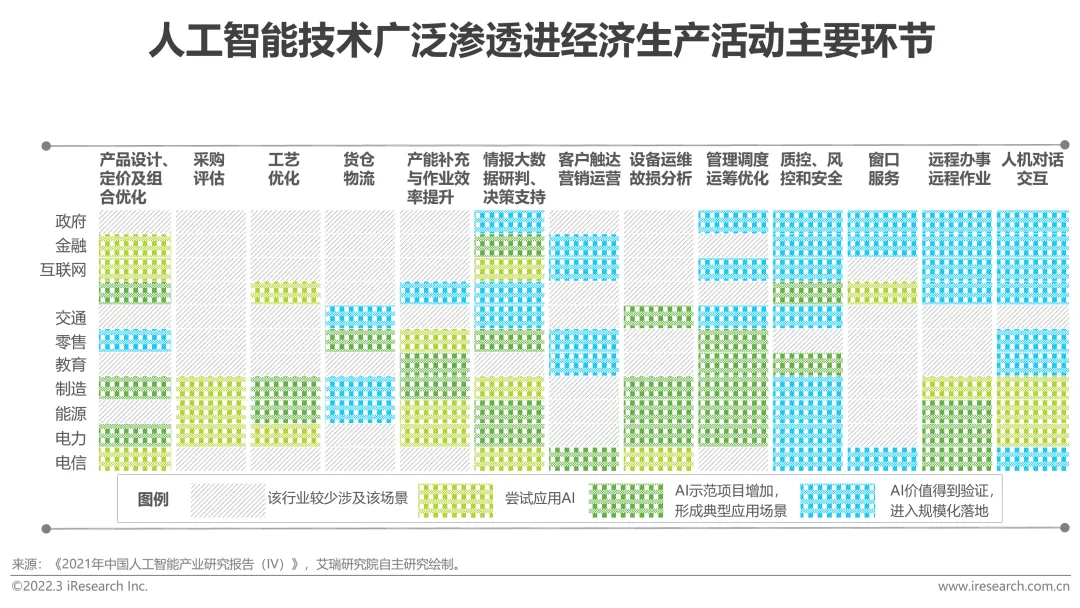
#近年、新たなテクノロジーモデルの登場により、さまざまな業界におけるアプリケーションシナリオの価値が磨き上げられ、それに基づいた製品効果の向上が図られています。大量のデータの蓄積、人工知能アプリケーションは消費、インターネット、その他の分野から発展し、製造、エネルギー、電力などの伝統的な産業に広がります。設計、調達、生産、管理、販売などの経済生産活動の主要なリンクにおけるさまざまな業界の企業における人工知能技術の成熟度と応用は常に向上しており、すべてのリンクでの人工知能の実装と適用が加速しています。産業地位の向上や経営効率の最適化を図るため、徐々に本業と融合させ、自社の優位性をさらに拡大していきます。
人工知能テクノロジーの革新的なアプリケーションの大規模実装により、ビッグデータ インテリジェンス市場の精力的な発展が促進され、基盤となるデータ ガバナンス サービスにも市場の活力が注入されました。 。
ビッグデータ、クラウド コンピューティング、アルゴリズムの発展に伴い、人工知能の流行が始まりました。数年前に誕生し、現在に至るまで多くの産業や分野で広く利用されており、現在進行中の技術革新をリードする技術となっています。そして、急成長を遂げているデータ ガバナンスの分野に人工知能が存在しないはずがありません。データガバナンスと人工知能という一見関係のない言葉ですが、これらを組み合わせるとどのようなストーリーが生まれるのでしょうか?
1. データ ガバナンスは人工知能の基盤を築く
ビッグデータは、継続的に蓄積、クリーニング、変換され、データ ガバナンスは、ビッグ データを表示するためのより標準化された管理モデルを提供します。現在のほとんどの形式の人工知能は大量のデータ計算を必要とするため、ビッグデータとデータ ガバナンスのサポートと切り離すことができません。人工知能は、ディープラーニングの進化を完了するために、ビッグデータのプラットフォームとテクノロジーに依存する必要があります。

#1. データ ガバナンスは人工知能に高品質のデータを提供します
大一部の人工知能は、トレーニングと予測という 2 つのリンクに分かれています。機械学習アルゴリズムの効果は入力データの品質に依存し、入力データに偏りがあると、出力アルゴリズムにも偏りが生じ、得られる結果が使いにくくなる可能性があります。データガバナンスは、データ品質の向上において重要な役割を果たします。データ品質要件を整理し、データ品質検査ルールを定義し、データ品質改善計画を策定し、データ品質管理ツールを設計および実装し、データ品質管理の運用手順とパフォーマンスを監視することにより、企業はクリーンで明確に構造化されたデータを取得し、信頼できるデータを提供できます。ディープラーニングなどの人工知能テクノロジーへの入力。

 2. 人工知能はデータ ガバナンスのインテリジェンス レベルを向上させます
2. 人工知能はデータ ガバナンスのインテリジェンス レベルを向上させます
#1 .メタデータ管理
 従来のメタデータ管理では、非構造化データのメタデータ収集は通常、非構造化データの検索インデックスを作成することによって行われます。 。音声認識、画像認識、テキスト分析などの人工知能テクノロジは、メタデータの初期ビジネス語彙の構築を実現するのに役立ち、さまざまな貴重な非構造化メタデータを抽出するためのリソース プールになります。
従来のメタデータ管理では、非構造化データのメタデータ収集は通常、非構造化データの検索インデックスを作成することによって行われます。 。音声認識、画像認識、テキスト分析などの人工知能テクノロジは、メタデータの初期ビジネス語彙の構築を実現するのに役立ち、さまざまな貴重な非構造化メタデータを抽出するためのリソース プールになります。
2. データ標準管理

データ標準実装の初期段階では、既存のシステムを管理するために必要です。 データ標準を確立するための基礎として、データベース フィールドの徹底的な調査を実施して、共通および再利用されるビジネス フィールドを特定します。すべて手作業で行う場合、さまざまな事業部門から多数の人員が連携する必要があり、作業量が膨大になり、ミスも発生しやすくなります。機械学習と自然言語処理技術の助けを借りて、現場の企業名に基づいて高頻度のルートを迅速に分類でき、数か月かかる作業を数日で完了できます。
データ標準管理のもう 1 つの重要な側面は、標準とメタデータのマッピングです。多くのビジネス システムでは、データ標準をビジネス システムのメタデータにマッピングすることは実装エンジニアにとって悪夢であることが多く、注意しないと間違いを犯しやすくなります。人工知能テクノロジーを使用すると、ビジネス分野名に対して自然言語処理を実行し、単語を正確にセグメント化し、ルートの類似性に基づいてデータ標準とメタデータを自動的にマッピングできます。
#3. データ品質管理
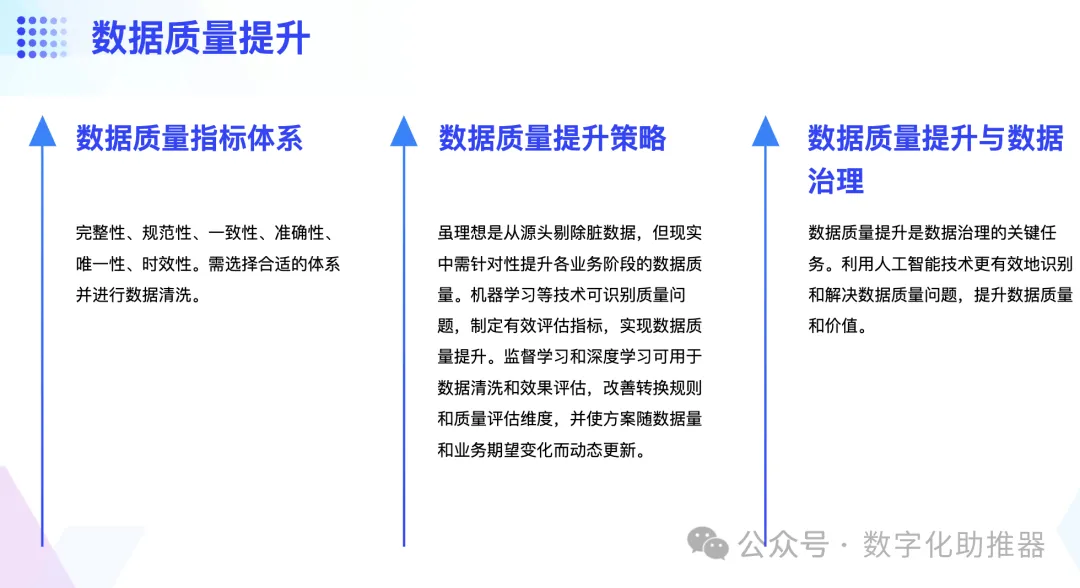
##データ品質とは、データの効率を確保することです。アプリケーションベース。データ品質を測定するための指標システムには、完全性、標準化、一貫性、正確さ、一意性、適時性が含まれます。データ品質改善計画を実行する前に、さまざまなビジネス ルールやビジネス上の期待に基づいて適切なデータ品質指標システムを選択し、データをクリーンアップする必要があります。
一般的なデータ品質向上の理想的なモデルは、データ ソースからダーティ データを削除することですが、これは現実には不可能です。したがって、ビジネスの期待に応じて、ビジネスの各段階でのデータ品質を的を絞った方法で改善する必要があります。機械学習 (分類学習、クラスタリング、回帰など) は、既存の品質問題を抽出して特定することで、効果的なデータ品質評価指標を策定し、この指標に基づいてデータ品質を最大限に向上させることができます。同時に、教師あり学習とディープラーニングにより、データクリーニングとデータ品質の効果の評価も可能になり、それによって変換ルールとデータ品質の評価次元が改善され、データ量とビジネスの期待が徐々に変化するにつれてデータ品質の改善計画が動的に更新されます。
#4. データ セキュリティ ##データ セキュリティとは、情報またはプロセスを保持することを意味します。情報システムが不正なアクセス、使用、破壊、変更、破壊から保護されている状態。人工知能テクノロジーは、機密データを分類して分類できます。機械学習、自然言語処理、テキスト クラスタリング分類テクノロジを適用することで、コンテンツに基づいてデータをリアルタイムで正確に分類および分類できます。データの分類と分類は、データ セキュリティ ガバナンスの中心的なリンクです。たとえば、データ分類エンジンの使用により、電子メール コンテンツのフィルタリング、機密ファイル管理、インテリジェンス分析、不正行為防止、データ漏洩防止などの分野でのセキュリティが大幅に向上しました。
##データ セキュリティとは、情報またはプロセスを保持することを意味します。情報システムが不正なアクセス、使用、破壊、変更、破壊から保護されている状態。人工知能テクノロジーは、機密データを分類して分類できます。機械学習、自然言語処理、テキスト クラスタリング分類テクノロジを適用することで、コンテンツに基づいてデータをリアルタイムで正確に分類および分類できます。データの分類と分類は、データ セキュリティ ガバナンスの中心的なリンクです。たとえば、データ分類エンジンの使用により、電子メール コンテンツのフィルタリング、機密ファイル管理、インテリジェンス分析、不正行為防止、データ漏洩防止などの分野でのセキュリティが大幅に向上しました。
#5. マスター データ管理
##マスター データとは、中核となるビジネスを指します。エンティティデータはゴールデンデータとも呼ばれ、バリューチェーン全体で繰り返し共有され、複数のビジネスプロセスで利用され、さまざまな事業部門やシステム間で共有される情報交換の基盤となる基礎データです。しかし、企業はマスターデータを管理する過程で、膨大なデータの中からマスターデータをどのように特定するのか、統一したマスターデータ規格をどのように確立するのかなどの課題に直面することがあります。 
マスター データの決定は、企業のビジネス ニーズの理解と、対応する「ゴールデン データ」の定義に依存します。一般に、各マスターデータのサブジェクト領域には独自の専用の記録システムがあり、さまざまなビジネス システムに分散されています。人工知能関連テクノロジーは、すべてのデータから頻繁に出現するデータや流れてくるデータをフィルタリングすると同時に、マスター データの信頼できるデータ ソースを迅速に特定し、完全なマスター データ ビューを構築するのに役立ちます。 
6. 人工知能により、重複したデータが自動的に照合され、データが結合されます。
デジタル ドラマ管理が直面する課題の 1 つは、企業の多数のシステムで同じデータ項目または重複するデータ項目を照合してマージすることです。この課題を解決する 1 つの方法は、さまざまなデータ マッチング ルールを構築することです。信頼レベル、一致の許容度。一部の一致には非常に高いレベルの信頼が必要で、複数のフィールドにわたる正確なデータ一致に基づくことができますが、一部の一致は単にデータ値が矛盾しているために、より低いレベルの信頼で達成される場合もあります。機械学習と自然言語処理は、重複データを識別するための一致ルールを確立するのに役立ちます。重複フィールドを持つマスター データを識別した後は、自動マージは実行されず、マスター データに関連するレコードを特定し、相互参照関係を確立できます。
3. データ ガバナンス プラットフォームのインテリジェンス
人工知能技術によってデータ ガバナンスの敷居を下げることは、データ ガバナンスの発展にとって重要な方向性になります。データ ガバナンスの高度な複雑性を十分に考慮して、データ ガバナンス プラットフォームは新しい AI テクノロジを統合し続け、インテリジェントな管理を通じてデータ ガバナンス実装プロセスの簡素化に努め、技術担当者を大幅に解放し、企業がより効率的なデータ ガバナンスを達成し、データ ガバナンスから遠ざかるのを支援します。 「データブラックホール」より。

1. インテリジェントなメタデータ サービス。 Ruizhi プラットフォームは、完全に自動化されたメタデータの収集と関連付けをサポートし、メタモデルのインテリジェントなアプリケーションを実現し、グラフィカルなメタデータ分析ビューを提供します。
#2. データ品質のインテリジェントな調査。 Ruizhi プラットフォームには、数学的統計アルゴリズムとバインドされた機械学習アルゴリズムが組み込まれており、データ品質を自動的に検出し、インテリジェントな修復をサポートします。
#3. データ標準のインテリジェントな構築。 Ruizhi プラットフォームは、インテリジェントなマッピングとマーキング、データ標準の形成、ビジネス データの双方向評価をサポートします。
#4. マスター データのインテリジェントな識別。 Ruizhi プラットフォームはマスター データを自動的に識別し、重複データの自動的な照合とマージを支援し、完全なマスター データ ビューを構築します。
データ ガバナンスと人工知能の急速な発展に伴い、この 2 つの統合により、より多くのシナリオとビジネス モデルが生まれるでしょう。
#4. データ ガバナンス AI の業界統合
AI テクノロジー イノベーションの大規模実装ビッグ データ インテリジェンス市場は活況を呈しています
企業が AI アプリケーションを導入する場合、データ リソースの品質が AI アプリケーションの有効性を大きく左右します。したがって、AI アプリケーションの高品質な実装を促進するには、対象を絞ったデータ ガバナンス作業を実行することが最初で必要なステップです。企業が構築してきた従来のデータガバナンスシステムは、現在、構造化データのガバナンスの最適化に重点が置かれており、データ品質、データフィールドの豊富さ、データ分散、データの各側面においてAIアプリケーションのニーズを満たすことは依然として困難です。リアルタイムのデータ品質要件。 AI アプリケーションの高品質な実装を保証するために、 企業は依然として人工知能アプリケーションの二次データ ガバナンスを実行する必要があります。 
人工知能指向のデータ ガバナンスは、AI アプリケーションの実装によって導かれる従来のデータ ガバナンス システムの「アップグレード」です。
データ管理の観点から見ると、人工知能のデータ ガバナンス システムは、データ構造化フロー、データ資産管理のニーズ、データ セキュリティに基づいた要素の構築に引き続き適応します。データ管理、データ資産管理、マスターデータ管理、データライフサイクル管理、データセキュリティとプライバシー管理などのコンポーネントモジュール。データ ガバナンス プロセスでは、必要なデータの規模、品質、適時性を満たすために、マルチソース データの融合、データ収集頻度、データ標準の確立、およびデータ品質管理を実現するために、最下層にさらに重点が置かれます。 AI モデルのニーズに合わせて、AI アプリケーションのニーズを満たすため、データ要件を核として、対応するモジュールのシステム構築が最適化されます。
AI アプリケーション ドライブは、人工知能指向のデータ ガバナンス サービスの中核的な足場となっています
人工知能指向のデータ ガバナンス サービスには、多くの場合含まれていますin data 3 種類の調達形態には、サービス、プラットフォーム機能、データ製品があります。最初のカテゴリのデータ サービスは、個別のデータ ガバナンス製品の形で表示されます。2 番目のカテゴリのデータ プラットフォームには、主にビッグ データ プラットフォーム、データ ミドル プラットフォーム、データ ウェアハウス、AI 機能プラットフォームおよびその他のプロジェクトが含まれます。3 番目のカテゴリのデータ製品は、 AI アルゴリズムの適用に限定されたデータ製品は、機械学習製品、自然言語理解製品、ナレッジ グラフの 3 種類の AI 製品に分類できます。
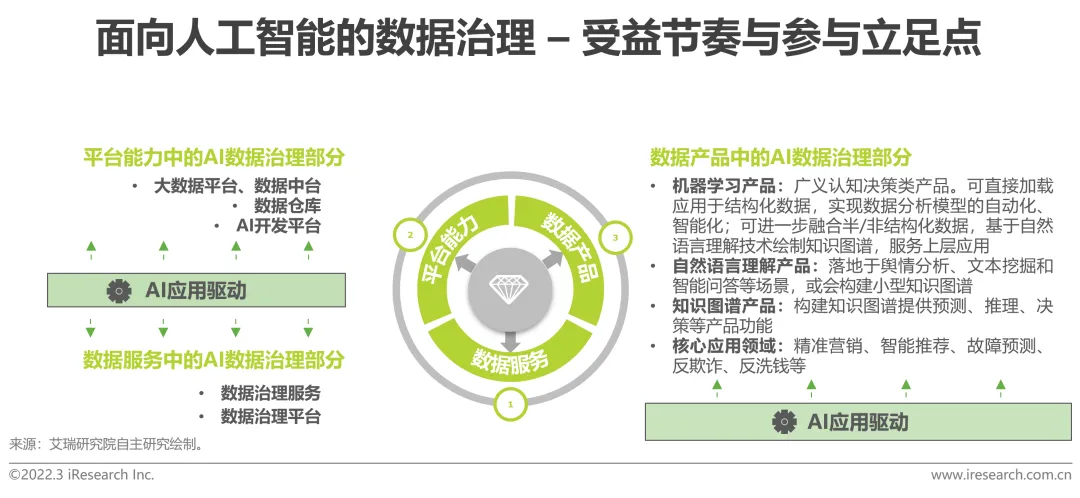
現在、AI 製品に対する需要は高く、AI 開発プラットフォームは次々と大規模な開発を推進してきました。 AI 製品の導入規模と AI データ ガバナンスの効果 最終的なプラットフォーム製品の提供効果と密接に関係しています。
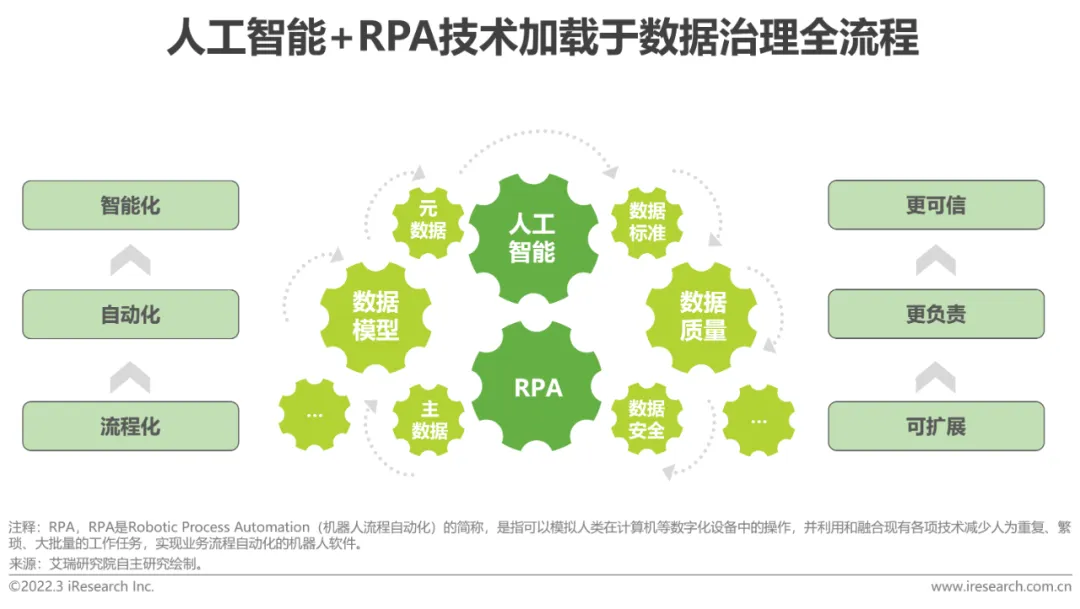
全体として、最先端のテクノロジーを適用することで、データ ガバナンスをより合理化、自動化、インテリジェントにしながら、データの拡張性、説明責任、追跡可能性を高めることができます。データ管理を将来的に発展させる唯一の方法となっています。
「ガバナンスAI」システムの好循環を生み出す
相互関連、相互に依存し、人工知能アプリケーションの内部および外部の開発を共同で促進します
人工知能指向のデータガバナンスは、機械学習テクノロジーを最大限に活用して自動化およびインテリジェント化しますデータ ガバナンス プロセスは、データ ガバナンスの効率を大幅に向上させると同時に、自然言語理解とナレッジ グラフに基づいて関連する非構造化データのアプリケーション価値を発掘し、データ品質管理の従来の問題を解決し、修復されたデータは、AI アプリケーションの要件により一致します。 効率と品質の観点から、AI モデルの実装を促進します。
同時に、AI アプリケーションの実装効果が大幅に最適化されることで、企業はインテリジェントな変革に対する自信をさらに深め、投資を増やすことができます。関連するガバナンス体制の構築をさらに推進し、「統治するAI」の好循環を創出するための予算投資を実施 
以上がAI指向のデータガバナンスシステムを構築するにはどうすればよいでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7442
7442
 15
1371
52
76
11
9
6
15
1371
52
76
11
9
6

 Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
このサイトは6月27日、JianyingはByteDanceの子会社であるFaceMeng Technologyによって開発されたビデオ編集ソフトウェアであり、Douyinプラットフォームに依存しており、基本的にプラットフォームのユーザー向けに短いビデオコンテンツを作成すると報告しました。 Windows、MacOS、その他のオペレーティング システム。 Jianyingは会員システムのアップグレードを正式に発表し、インテリジェント翻訳、インテリジェントハイライト、インテリジェントパッケージング、デジタルヒューマン合成などのさまざまなAIブラックテクノロジーを含む新しいSVIPを開始しました。価格的には、クリッピングSVIPの月額料金は79元、年会費は599元(当サイト注:月額49.9元に相当)、継続月額サブスクリプションは月額59元、継続年間サブスクリプションは、年間499元(月額41.6元に相当)です。さらに、カット担当者は、ユーザーエクスペリエンスを向上させるために、オリジナルのVIPに登録している人は、
 微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
大規模言語モデル (LLM) は巨大なテキスト データベースでトレーニングされ、そこで大量の現実世界の知識を取得します。この知識はパラメータに組み込まれており、必要なときに使用できます。これらのモデルの知識は、トレーニングの終了時に「具体化」されます。事前トレーニングの終了時に、モデルは実際に学習を停止します。モデルを調整または微調整して、この知識を活用し、ユーザーの質問により自然に応答する方法を学びます。ただし、モデルの知識だけでは不十分な場合があり、モデルは RAG を通じて外部コンテンツにアクセスできますが、微調整を通じてモデルを新しいドメインに適応させることが有益であると考えられます。この微調整は、ヒューマン アノテーターまたは他の LLM 作成物からの入力を使用して実行され、モデルは追加の実世界の知識に遭遇し、それを統合します。
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
SOTA パフォーマンス、厦門マルチモーダルタンパク質-リガンド親和性予測 AI 手法、初めて分子表面情報を結合
Jul 17, 2024 pm 06:37 PM
編集者 | KX 医薬品の研究開発の分野では、タンパク質とリガンドの結合親和性を正確かつ効果的に予測することが、医薬品のスクリーニングと最適化にとって重要です。しかし、現在の研究では、タンパク質とリガンドの相互作用における分子表面情報の重要な役割が考慮されていません。これに基づいて、アモイ大学の研究者らは、初めてタンパク質の表面、3D 構造、配列に関する情報を組み合わせ、クロスアテンション メカニズムを使用して異なるモダリティの特徴を比較する、新しいマルチモーダル特徴抽出 (MFE) フレームワークを提案しました。アライメント。実験結果は、この方法がタンパク質-リガンド結合親和性の予測において最先端の性能を達成することを実証しています。さらに、アブレーション研究は、この枠組み内でのタンパク質表面情報と多峰性特徴の位置合わせの有効性と必要性を実証しています。 「S」で始まる関連研究
 AIなどの市場を開拓するグローバルファウンドリーズがタゴール・テクノロジーの窒化ガリウム技術と関連チームを買収
Jul 15, 2024 pm 12:21 PM
AIなどの市場を開拓するグローバルファウンドリーズがタゴール・テクノロジーの窒化ガリウム技術と関連チームを買収
Jul 15, 2024 pm 12:21 PM
7月5日のこのウェブサイトのニュースによると、グローバルファウンドリーズは今年7月1日にプレスリリースを発行し、自動車とインターネットでの市場シェア拡大を目指してタゴール・テクノロジーのパワー窒化ガリウム(GaN)技術と知的財産ポートフォリオを買収したことを発表した。モノと人工知能データセンターのアプリケーション分野で、より高い効率とより優れたパフォーマンスを探求します。生成 AI などのテクノロジーがデジタル世界で発展を続ける中、窒化ガリウム (GaN) は、特にデータセンターにおいて、持続可能で効率的な電力管理のための重要なソリューションとなっています。このウェブサイトは、この買収中にタゴール・テクノロジーのエンジニアリングチームがGLOBALFOUNDRIESに加わり、窒化ガリウム技術をさらに開発するという公式発表を引用した。 G
 SKハイニックスは8月6日に12層HBM3E、321層NANDなどのAI関連新製品を展示する。
Aug 01, 2024 pm 09:40 PM
SKハイニックスは8月6日に12層HBM3E、321層NANDなどのAI関連新製品を展示する。
Aug 01, 2024 pm 09:40 PM
8月1日の本サイトのニュースによると、SKハイニックスは本日(8月1日)ブログ投稿を発表し、8月6日から8日まで米国カリフォルニア州サンタクララで開催されるグローバル半導体メモリサミットFMS2024に参加すると発表し、多くの新世代の製品。フューチャー メモリおよびストレージ サミット (FutureMemoryandStorage) の紹介。以前は主に NAND サプライヤー向けのフラッシュ メモリ サミット (FlashMemorySummit) でしたが、人工知能技術への注目の高まりを背景に、今年はフューチャー メモリおよびストレージ サミット (FutureMemoryandStorage) に名前が変更されました。 DRAM およびストレージ ベンダー、さらに多くのプレーヤーを招待します。昨年発売された新製品SKハイニックス
 VSCode フロントエンド開発の新時代: 強く推奨される 12 の AI コード アシスタント
Jun 11, 2024 pm 07:47 PM
VSCode フロントエンド開発の新時代: 強く推奨される 12 の AI コード アシスタント
Jun 11, 2024 pm 07:47 PM
フロントエンド開発の世界では、VSCode はその強力な機能と豊富なプラグイン エコシステムにより、数多くの開発者に選ばれるツールとなっています。近年、人工知能技術の急速な発展に伴い、VSCode 上の AI コード アシスタントが登場し、開発者のコーディング効率が大幅に向上しました。 VSCode 上の AI コード アシスタントは雨後のキノコのように出現し、開発者のコーディング効率を大幅に向上させました。人工知能テクノロジーを使用してコードをインテリジェントに分析し、正確なコード補完、自動エラー修正、文法チェックなどの機能を提供することで、コーディング プロセス中の開発者のエラーや退屈な手作業を大幅に削減します。今日は、プログラミングの旅に役立つ 12 個の VSCode フロントエンド開発 AI コード アシスタントをお勧めします。
 Iyo One: 一部ヘッドフォン、一部オーディオコンピュータ
Aug 08, 2024 am 01:03 AM
Iyo One: 一部ヘッドフォン、一部オーディオコンピュータ
Aug 08, 2024 am 01:03 AM
どんな時でも集中力は美徳です。著者 | 編集者 Tang Yitao | 人工知能の復活により、ハードウェア革新の新たな波が起きています。最も人気のある AIPin は前例のない否定的なレビューに遭遇しました。マーケス・ブラウンリー氏(MKBHD)はこれを、これまでレビューした中で最悪の製品だと評したが、ザ・ヴァージの編集者デイビッド・ピアース氏は、誰にもこのデバイスの購入を勧めないと述べた。競合製品である RabbitR1 はそれほど優れていません。この AI デバイスに関する最大の疑問は、これが明らかに単なるアプリであるのに、Rabbit は 200 ドルのハードウェアを構築したということです。多くの人がAIハードウェアのイノベーションをスマートフォン時代を打破するチャンスと捉え、スマートフォン時代に全力を注ぐ。
