

HiVT の進化版 (最初に HiVT を読まなくてもこの記事を直接読むことができます)、パフォーマンスと効率が大幅に向上しました。
記事も読みやすいです。
[軌道予測シリーズ][注意事項] HiVT: マルチエージェント動作予測のための階層型ベクトル変換器 - Zhihu (zhihu.com)
元のリンク:
https: / /openaccess.thecvf.com/content/CVPR2023/papers/Zhou_Query-Centric_Trajectory_Prediction_CVPR_2023_paper.pdf
エージェントが中心となるモデルには問題がありますウィンドウが移動されると、エージェント センターへの正規化を複数回繰り返してから、エンコード プロセスを繰り返す必要があり、オンボードで使用するには費用対効果が高くありません。したがって、シーン エンコードにはクエリ中心のフレームワークを使用します。これは、計算結果を再利用でき、グローバル時間座標系に依存しません。同時に、異なるエージェントがシーンの特徴を共有するため、エージェントの軌跡のデコード プロセスをより並行して処理できます。
シーンは複雑にエンコードされており、現在のデコード方法では、特に長期予測の場合、モード情報を捕捉することが依然として困難です。この問題を解決するために、まずアンカーフリー クエリを使用して軌道提案 (ステップバイステップの特徴抽出方法) を生成します。これにより、モデルがさまざまな時点でシーンの特徴をより適切に利用できるようになります。次に、調整モジュールがあり、前のステップで取得した提案を使用して軌道を最適化します (動的アンカーベース)。これらの高品質のアンカーを通じて、クエリベースのデコーダーはモードの特性をより適切に処理できます。
ランク付けに成功しました。この設計では、シナリオ機能のエンコードと並列マルチエージェント デコード パイプラインも実装されています。
現在の軌道予測論文には次の問題があります。
上記の問題を解決するために、私たちは QCNet を提案しました。
まず、強力な因数分解された注意をうまく活用しながら、オンボードの推論速度を向上させたいと考えています。これまでのエージェント中心のエンコード方法は明らかに機能しません。データの次のフレームが到着すると、ウィンドウは移動しますが、前のフレームとの重なり部分が依然として大きいため、これらの機能を再利用する機会があります。ただし、エージェント中心の方法はエージェント座標系に転送する必要があり、これによりシーンが再エンコードされます。この問題を解決するために、クエリ中心メソッドを使用しました。シーン要素は、グローバル座標系に関係なく、独自の時空間座標系内で特徴を抽出します(エゴがどこにあるかは関係ありません)。 。 (マップ要素は長期 ID を持つため、高精度マップを使用できます。高精度でないマップは使いにくい場合があります。マップ要素は前後のフレームで追跡する必要があります。)
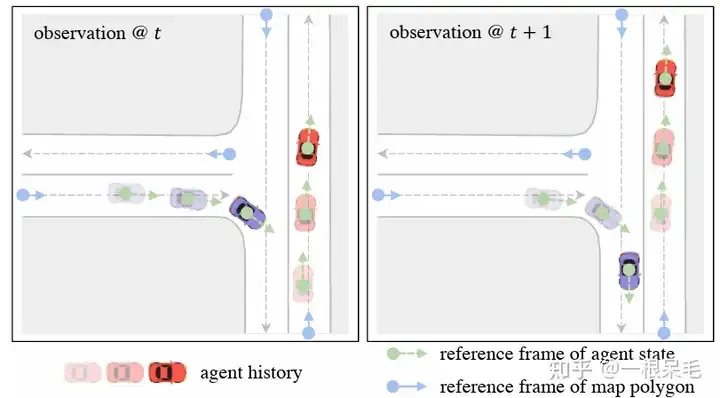
これにより、以前に処理されたエンコード結果を再利用できるため、エージェントではこれらのキャッシュ機能を直接使用できるため、待ち時間が節約されます。
第 2 に、これらのシーンのエンコード結果をマルチモードの長期予測に有効に使用するために、アンカーフリー クエリを使用してシーンの特徴を段階的に (前の位置で) 抽出します。毎回のデコードは非常に短いステップです。このアプローチにより、将来の複数の瞬間の位置を考慮するために遠くの特徴を抽出するのではなく、シーンの特徴抽出で将来のエージェントの特定の場所に焦点を当てることができます。こうして得られた高品質なアンカーは、次のリファインモジュールで微調整されます。このように、アンカーフリーとアンカーベースの 組み合わせは、2 つの方法の利点を最大限に活用して、マルチモード予測と長期予測を実現します。
このアプローチは、高速推論を実現するために軌道予測の連続性を探求する最初のアプローチです。同時に、デコーダ部分はマルチモードおよび長期予測タスクも考慮します。
同時prediction模組還可以從高精地圖獲得M個polygon,每個polygon都有多個點以及語意資訊(crosswalk,lane等類型)。
預測模組使用T個時刻的上述的agent state和地圖信息,要給出K個總共T'長度預測軌跡,同時還有其機率分佈。
#第一步自然是場景的encode。目前流行的factorized attention(時間和空間維度分別做attention)是這麼做的,具體來說一共有三步:
這個做法和之前的先在時間維度壓縮feature到當下時刻,再agent和agent,agent和地圖間交互的做法比起來,是對於過去每個時刻去做交互,因此可以獲取更多信息,比如agent和map間在每個時刻的交互演變。
但缺點是三次方的複雜度隨著場景變得複雜,元素變多,會變得很大。我們的目標就是既用好這個factorized attention,同時不讓時間複雜度這麼容易爆炸。
一個很容易想到的辦法是利用上一幀的結果,因為在時間維度上其實有T-1幀是完全重複的。但因為我們需要把這些feature旋轉平移到agent目前幀的位置和朝向,因此沒辦法就這樣使用上一幀運算得到的結果。
為了解決座標系的問題,採用了query-centric辦法,來學習場景元素的特徵,而不依賴它們的全局座標。這個做法對每個場景元素建立了局部的時空座標系,在這個座標系內提取特徵,即使ego到別處,這個局部提取出來的特徵也是不變的。這個局部時空座標係自然也有一個原點位置和方向,這位置資訊作為key,提取出來的特徵作為value,以便於之後的attention操作。整個做法分為下面幾步:
對於agent i在t時刻的feature來說,選擇這個時刻的位置和朝向作為參考系。對於map元素來說,則採用這個元素的起始點作為參考系。這樣的參考系選擇方法可以在ego移動後提取的feature保持不變。
對於每個元素內的別的向量特徵,都在上述參考系裡取得極座標表示表達。然後將它們轉成傅立葉特徵來獲取高頻訊號。 concat上語意特徵後再MLP取得特徵。對於map元素,為了確保內部點的順序不相關性,先做attention後pooling的操作。最後得到agent特徵為[A, T, D], map特徵為[M, D]. D是特徵維度,保持一致才可以方便attention的矩陣相乘。這樣提取出來的特徵可以使得ego在任何地方都能使用。
傅立葉embedding: 製造常態分佈的embedding,對應各種頻率的權重,乘輸入和2Π, 最後取cos和sin作為feature。直覺理解的話應該是把輸入當作一個訊號,把訊號解碼成多個基本訊號(多個頻率的訊號)。這樣可以更好的抓取高頻訊號,高頻訊號對於結果的精細程度很重要,一般的做法容易失去精細的高頻訊號。值得注意的是對於noisy資料不建議使用,因為會誤抓錯誤的高頻訊號。 (感覺有點像overfit,不能太general但又不能精準過頭)





#附近的定義為agent周圍50m範圍內。一共會進行次。
值得注意的是,透過上述方法得到的feature具備了時空不變性,即不管ego在什麼時刻到什麼地方,上述feature都是不變的,因為都沒有針對當前的位置資訊進行平移旋轉。由於相較於上一幀只是多了新的一幀數據,並不需要計算之前的時刻的feature,所以總的計算複雜度除以了T。

整個網路結構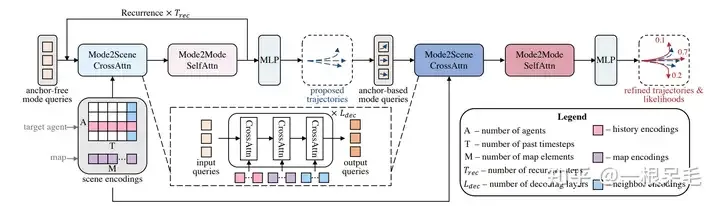
DETR結構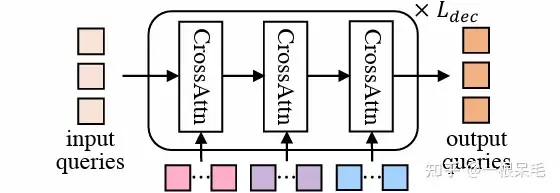

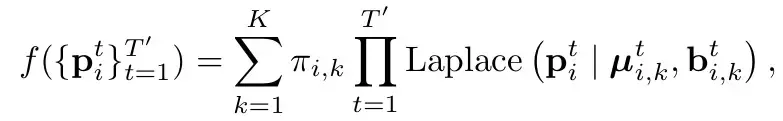
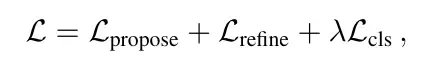
分類loss和回歸loss。
分類loss是指預測機率的loss,這個地方要注意的是需要打斷梯度回傳,不可以讓機率的引起的梯度傳到對於座標的預測(即在假設每個mode預測位置為合理的前提下)。 label則是最接近gt的為1,別的都是0。
回歸loss有兩個,一個是一階段的proposal的loss,一個是二階段的refine的loss。採用贏者全拿的辦法,也就是只計算最接近gt的mode的loss,兩個階段的迴歸loss都要算算出來。為了訓練的穩定性,這裡在兩個階段中也打斷了梯度回傳,使得proposal學習就專門學習proposal,refine就只學refine。
Argoverse2基本各項SOTA(* 表示使用了ensemble技巧)
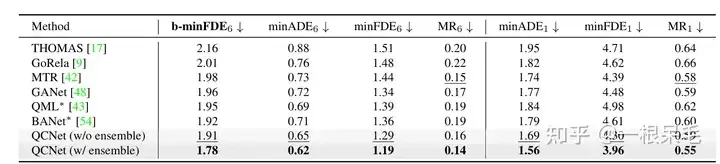
#b-minFDE相較於minFDE的差異在於額外乘上了與其機率相關的係數. 即目標希望FDE最小的那條軌跡的機率越高越好。
關於ensemble技巧,感覺是有點作弊的:可以參考BANet裡的介紹,以下簡單介紹一下。
生成軌蹟的最後一步同時連做好多遍結構一樣的submodel(decoder),會給出多組預測,例如有7個submodel,每個有6條預測,一共42條。然後用kmeans來進行聚類(以最後一個座標點為聚類標準),目標是6組,每組7條,然後每組裡面進行加權平均獲得新軌跡。
加權方法如下,為當前軌跡和gt的b-minFDE,c為當前軌蹟的機率,在每組裡面進行權重計算,然後對軌跡座標加權求和獲得一條新軌跡。 (感覺多少有些tricky,因為c其實是這個軌跡在submodel輸出裡的機率,拿來在聚類裡算有點不太符合預期)
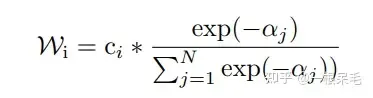
並且這麼操作後新軌蹟的機率也很難精準計算,不能用上述方法,否則總機率和就不一定是1了。似乎也只能等權重地算聚類裡的機率了。
Argoverse1也是遙遙領先
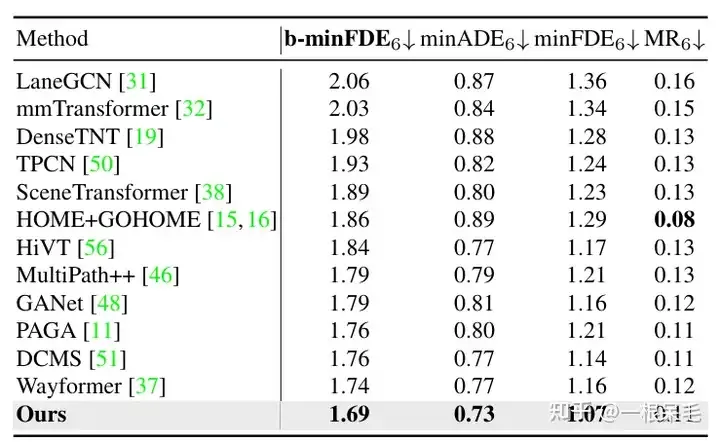
關於場景encode的研究:如果復用了先前的場景encode結果,infer的時間可以大幅減少。 agent與場景資訊的factorized attention互動次數變多,預測效果也會變好,只是latency也漲的很兇,需要權衡。

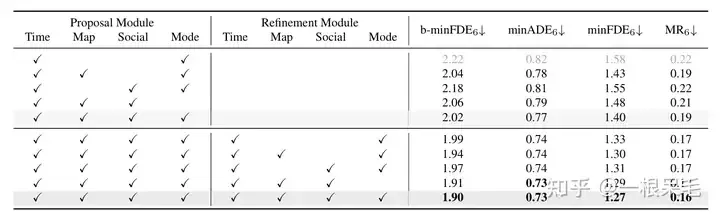
各種操作的研究:證明了refine的重要性,以及factorized attention在各種互動中的重要性,缺一不可。
以上が軌道予測シリーズ | 進化版HiVT QCNetは何を語る?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



