

無限の長さに直接拡張できる Google Infini-Transformer がコンテキスト長の議論に終止符を打つ

Gemini 1.5 Pro はこのテクノロジーを使用しているのだろうか。
Google はさらに大きな動きを見せ、次世代の Transformer モデル Infini-Transformer をリリースしました。
実践的な内容を紹介します。強力なアテンション 強制メカニズム Infini-attention - 長期圧縮メモリとローカル因果的アテンションを使用して、長期および短期のコンテキスト依存関係を効果的にモデル化できます。標準スケーリングドット積アテンション (標準スケーリングドット積アテンション) は最小限に変更されており、プラグアンドプレイの継続的な事前トレーニングと長いコンテキストの適応をサポートするように設計されています。このアプローチにより、Transformer LLM は、ストリーミング方式で非常に長い入力を処理し、限られたメモリとコンピューティング リソースで無限に長いコンテキストに拡張できるようになります。 論文リンク: https://arxiv.org/pdf/2404.07143.pdf

- 手法の紹介
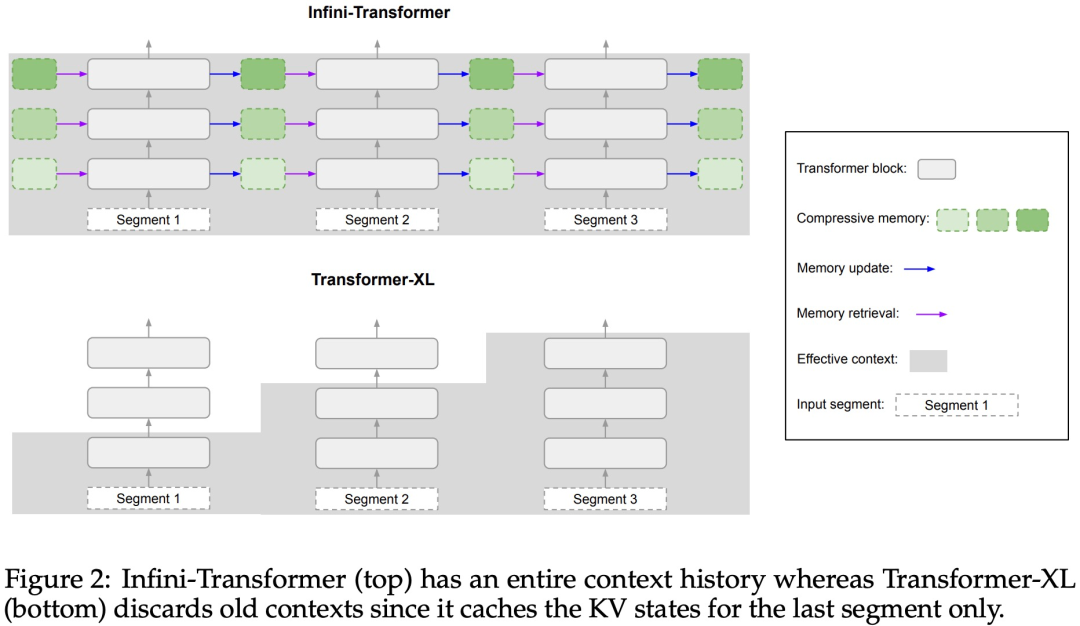

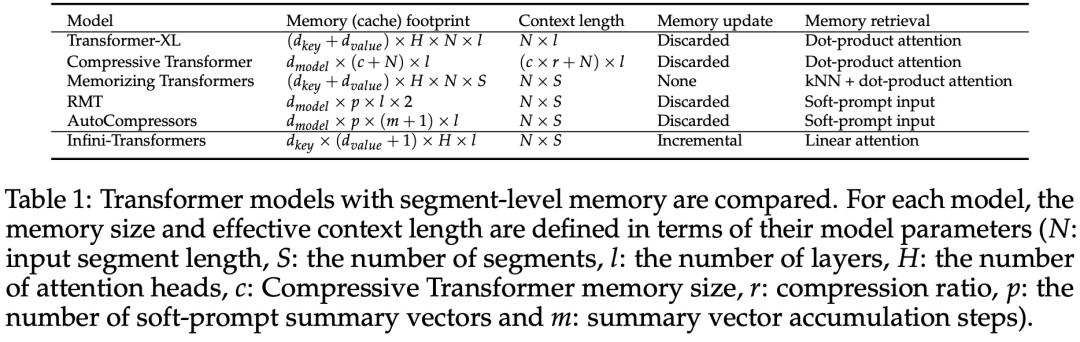
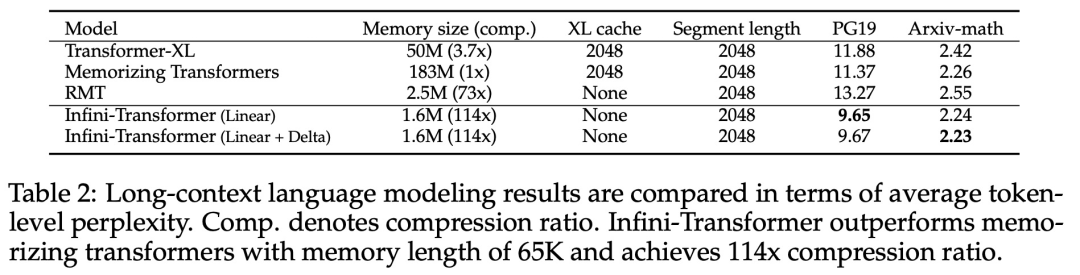
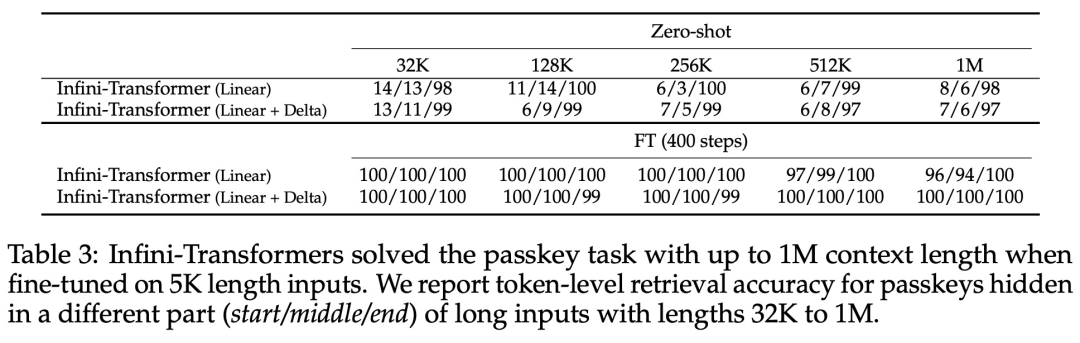
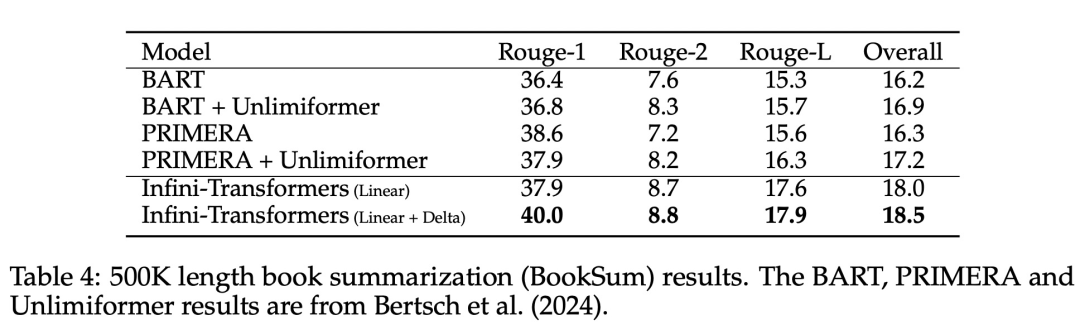

以上が無限の長さに直接拡張できる Google Infini-Transformer がコンテキスト長の議論に終止符を打つの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7449
7449
 15
1374
52
77
11
14
7
15
1374
52
77
11
14
7

 セサミオープンドア交換Webページ登録リンクゲートトレーディングアプリ登録Webサイト最新
Feb 28, 2025 am 11:06 AM
セサミオープンドア交換Webページ登録リンクゲートトレーディングアプリ登録Webサイト最新
Feb 28, 2025 am 11:06 AM
この記事では、SESAME Open Exchange(gate.io)Webバージョンの登録プロセスとGate Tradingアプリを詳細に紹介します。 Web登録であろうとアプリの登録であろうと、公式Webサイトまたはアプリストアにアクセスして、本物のアプリをダウンロードし、ユーザー名、パスワード、電子メール、携帯電話番号、その他の情報を入力し、電子メールまたは携帯電話の確認を完了する必要があります。
 セサミオープンドアトレーディングプラットフォームダウンロードモバイルバージョンgateioトレーディングプラットフォームのダウンロードアドレス
Feb 28, 2025 am 10:51 AM
セサミオープンドアトレーディングプラットフォームダウンロードモバイルバージョンgateioトレーディングプラットフォームのダウンロードアドレス
Feb 28, 2025 am 10:51 AM
アプリをダウンロードしてアカウントの安全を確保するために、正式なチャネルを選択することが重要です。
 Crypto Digital Asset Trading App(2025グローバルランキング)に推奨されるトップ10
Mar 18, 2025 pm 12:15 PM
Crypto Digital Asset Trading App(2025グローバルランキング)に推奨されるトップ10
Mar 18, 2025 pm 12:15 PM
この記事では、Binance、Okx、Gate.io、Bitflyer、Kucoin、Bybit、Coinbase Pro、Kraken、Bydfi、Xbit分散化された交換など、注意を払う価値のある上位10の暗号通貨取引プラットフォームを推奨しています。これらのプラットフォームには、トランザクションの数量、トランザクションの種類、セキュリティ、コンプライアンス、特別な機能の点で独自の利点があります。適切なプラットフォームを選択するには、あなた自身の取引体験、リスク許容度、投資の好みに基づいて包括的な検討が必要です。 この記事があなたがあなた自身に最適なスーツを見つけるのに役立つことを願っています
 セサミオープンドアエクスチェンジウェブページログイン最新バージョンgateio公式ウェブサイトの入り口
Mar 04, 2025 pm 11:48 PM
セサミオープンドアエクスチェンジウェブページログイン最新バージョンgateio公式ウェブサイトの入り口
Mar 04, 2025 pm 11:48 PM
ログインステップやパスワード回復プロセスなど、セサミオープンエクスチェンジWebバージョンのログイン操作の詳細な紹介も、ログイン障害、ページを開くことができず、プラットフォームにスムーズにログインするのに役立つ検証コードを受信できません。
 なぜビテンサーはAIトラックの「ビットコイン」と言われているのですか?
Mar 04, 2025 pm 04:06 PM
なぜビテンサーはAIトラックの「ビットコイン」と言われているのですか?
Mar 04, 2025 pm 04:06 PM
元のタイトル:Bittensor = Aibitcoin:S4MMYETH、分散型AI研究元の翻訳:Zhouzhou、BlockBeats編集者注:この記事では、Bockchain Technologyを通じて中央集権的なAI企業の独占を破り、オープンおよび共同AI Ecosemsytemを促進することを望んでいます。 Bittensorは、さまざまなAIソリューションの出現を可能にし、Tao Tokensを通じてイノベーションを刺激するサブネットモデルを採用しています。 AI市場は成熟していますが、両節は競争リスクに直面し、他のオープンソースの対象となる場合があります
 Bitget公式Webサイトで最新のアプリを登録およびダウンロードする方法
Mar 05, 2025 am 07:54 AM
Bitget公式Webサイトで最新のアプリを登録およびダウンロードする方法
Mar 05, 2025 am 07:54 AM
このガイドは、AndroidおよびiOSシステムに適した公式Bitget Exchangeアプリの詳細なダウンロードとインストール手順を提供します。このガイドは、公式ウェブサイト、App Store、Google Playなど、複数の権威ある情報源からの情報を統合し、ダウンロードおよびアカウント管理中の考慮事項を強調しています。ユーザーは、App Store、公式WebサイトAPKダウンロード、公式Webサイトジャンプ、完全な登録、ID検証、セキュリティ設定など、公式チャネルからアプリをダウンロードできます。さらに、ガイドはよくある質問や考慮事項をカバーします。
 OUYI OKX公式バージョンダウンロードアプリの入り口
Mar 04, 2025 pm 11:24 PM
OUYI OKX公式バージョンダウンロードアプリの入り口
Mar 04, 2025 pm 11:24 PM
この記事では、OUYI OKXの公式バージョンに関する最新のダウンロード情報を提供します。この記事では、ExchangeのAndroidおよびiOSアプリに安全かつ便利にアクセスする方法について読者を導きます。この記事には、読者がOUYI OKXアプリを簡単にダウンロードしてインストールするのに役立つように設計された段階的な指示と重要なヒントが含まれています。
 OUYI OKEXアカウントを登録、使用、キャンセルする方法に関するチュートリアル
Mar 31, 2025 pm 04:21 PM
OUYI OKEXアカウントを登録、使用、キャンセルする方法に関するチュートリアル
Mar 31, 2025 pm 04:21 PM
この記事では、OUYI OKEXアカウントの登録、使用、キャンセル手順を詳細に紹介します。登録するには、アプリをダウンロードし、携帯電話番号または電子メールアドレスを入力して登録する必要があります。使用法は、ログイン、リチャージ、引き出し、取引、セキュリティ設定などの操作手順をカバーします。アカウントをキャンセルするには、OUYI Okexカスタマーサービスに連絡し、必要な情報を提供し、処理を待つ必要があり、最後にアカウントキャンセルの確認を取得する必要があります。 この記事を通じて、ユーザーはOUYI OKEXアカウントの完全なライフサイクル管理を簡単に習得し、デジタルアセットトランザクションを安全かつ便利に実施できます。
