

Embedding サービスのローカル実行パフォーマンスは OpenAI Text-Embedding-Ada-002 を上回っており、とても便利です。

Ollama は、Llama 2、Mistral、Gemma などのオープンソース モデルをローカルで簡単に実行できるようにする非常に実用的なツールです。この記事では、Ollamaを使ってテキストをベクトル化する方法を紹介します。 Ollama をローカルにインストールしていない場合は、この記事を読むことができます。
この記事では、nomic-embed-text[2] モデルを使用します。これは、短いコンテキストおよび長いコンテキストのタスクにおいて OpenAI text-embedding-ada-002 および text-embedding-3-small よりも優れたパフォーマンスを発揮するテキスト エンコーダーです。
nomic-embed-text サービスを開始します
ollam が正常にインストールされたら、次のコマンドを使用して nomic-embed-text モデルをプルします:
ollama pull nomic-embed-text
モデルのプルに成功したら、ターミナルに次のコマンドを入力して ollam サービスを開始します:
ollama serve
その後、curl を使用して埋め込みサービスが実行できるかどうかを確認できます。通常通り実行します:
curl http://localhost:11434/api/embeddings -d '{"model": "nomic-embed-text","prompt": "The sky is blue because of Rayleigh scattering"}'nomic-embed-text サービスの使用
次に、langchainjs と nomic-embed-text サービスを使用して埋め込みを実行する方法を紹介します。ローカルの TXT ドキュメントに対する操作。対応するプロセスを次の図に示します。
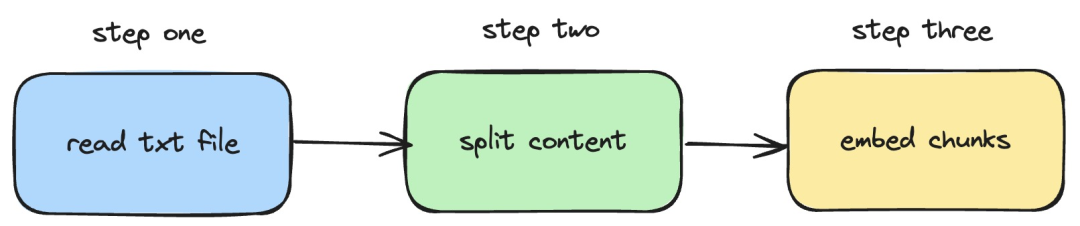 Picture
Picture
1. ローカル txt ファイルを読み取ります
import { TextLoader } from "langchain/document_loaders/fs/text";async function load(path: string) {const loader = new TextLoader(path);const docs = await loader.load();return docs;}上記のコードでは、langchainjs によって提供される TextLoader を内部的に使用してローカル txt ドキュメントを読み取るロード関数を定義します。
2. テキスト コンテンツをテキスト ブロックに分割します
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";import { Document } from "langchain/document";function split(documents: Document[]) {const splitter = new RecursiveCharacterTextSplitter({chunkSize: 500,chunkOverlap: 20,});return splitter.splitDocuments(documents);}上記のコードでは、RecursiveCharacterTextSplitter を使用して、読み取ったテキスト テキストを切り取り、各テキストを設定します。ブロック サイズは次のとおりです。 500。
3. テキスト ブロックで埋め込み操作を実行します
const EMBEDDINGS_URL = "http://127.0.0.1:11434/api/embeddings";async function embedding(path: string) {const docs = await load(path);const splittedDocs = await split(docs);for (let doc of splittedDocs) {const embedding = await sendRequest(EMBEDDINGS_URL, {model: "nomic-embed-text",prompt: doc.pageContent,});console.dir(embedding.embedding);}}上記のコードでは、前に定義したロードを呼び出して関数を分割する埋め込み関数を定義します。 。次に、生成されたテキスト ブロックを走査し、ローカルで開始された nomic-embed-text 埋め込みサービスを呼び出します。 sendRequest 関数は、埋め込みリクエストを送信するために使用されます。その実装コードは非常に単純で、フェッチ API を使用して既存の REST API を呼び出します。
async function sendRequest(url: string, data: Record<string, any>) {try {const response = await fetch(url, {method: "POST",body: JSON.stringify(data),headers: {"Content-Type": "application/json",},});if (!response.ok) {throw new Error(`HTTP error! status: ${response.status}`);}const responseData = await response.json();return responseData;} catch (error) {console.error("Error:", error);}}次に、引き続き embedTxtFile 関数の定義を行い、関数内の既存の埋め込み関数を直接呼び出し、対応する例外処理を追加します。
async function embedTxtFile(path: string) {try {embedding(path);} catch (error) {console.dir(error);}}embedTxtFile("langchain.txt")最後に、npx esno src/index.ts コマンドを使用して、ローカル ts ファイルをすばやく実行します。 Index.ts 内のコードが正常に実行されると、次の結果がターミナルに出力されます。
 Picture
Picture
実際には、上記の方法では、@langchain/community モジュールの [OllamaEmbeddings](https://js.langchain.com/docs/integrations/text_embedding/ollama "OllamaEmbeddings") オブジェクトを直接使用することもできます。これにより、内部的にロジックがカプセル化されます。 ollame embedding サービスの呼び出し:
import { OllamaEmbeddings } from "@langchain/community/embeddings/ollama";const embeddings = new OllamaEmbeddings({model: "nomic-embed-text", baseUrl: "http://127.0.0.1:11434",requestOptions: {useMMap: true,numThread: 6,numGpu: 1,},});const documents = ["Hello World!", "Bye Bye"];const documentEmbeddings = await embeddings.embedDocuments(documents);console.log(documentEmbeddings);この記事では、RAG システムの開発時にナレッジ ベースのコンテンツ インデックスを確立するプロセスを紹介します。 RAG システムについて知らない場合は、関連記事を参照してください。
参考文献
[1]Ollama: https://ollama.com/
[2]nomic-embed-text: https://ollama.com/ library /nomic-embed-text
以上がEmbedding サービスのローカル実行パフォーマンスは OpenAI Text-Embedding-Ada-002 を上回っており、とても便利です。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7634
7634
 15
1390
52
90
11
32
147
15
1390
52
90
11
32
147

 OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
OpenAI Super Alignment チームの遺作: 2 つの大きなモデルがゲームをプレイし、出力がより理解しやすくなる
Jul 19, 2024 am 01:29 AM
AIモデルによって与えられた答えがまったく理解できない場合、あなたはそれをあえて使用しますか?機械学習システムがより重要な分野で使用されるにつれて、なぜその出力を信頼できるのか、またどのような場合に信頼してはいけないのかを実証することがますます重要になっています。複雑なシステムの出力に対する信頼を得る方法の 1 つは、人間または他の信頼できるシステムが読み取れる、つまり、考えられるエラーが発生する可能性がある点まで完全に理解できる、その出力の解釈を生成することをシステムに要求することです。見つかった。たとえば、司法制度に対する信頼を築くために、裁判所に対し、決定を説明し裏付ける明確で読みやすい書面による意見を提供することを求めています。大規模な言語モデルの場合も、同様のアプローチを採用できます。ただし、このアプローチを採用する場合は、言語モデルが
 OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
OpenAI データは必要ありません。大規模なコード モデルのリストに加わりましょう。 UIUC が StarCoder-15B-Instruct をリリース
Jun 13, 2024 pm 01:59 PM
ソフトウェア テクノロジの最前線に立つ UIUC Zhang Lingming のグループは、BigCode 組織の研究者とともに、最近 StarCoder2-15B-Instruct 大規模コード モデルを発表しました。この革新的な成果により、コード生成タスクにおいて大きな進歩が達成され、CodeLlama-70B-Instruct を上回り、コード生成パフォーマンス リストのトップに到達しました。 StarCoder2-15B-Instruct のユニークな特徴は、その純粋な自己調整戦略であり、トレーニング プロセス全体がオープンで透過的で、完全に自律的で制御可能です。このモデルは、高価な手動アノテーションに頼ることなく、StarCoder-15B 基本モデルの微調整に応じて、StarCoder2-15B を介して数千の命令を生成します。
 さまざまな Java フレームワークのパフォーマンスの比較
Jun 05, 2024 pm 07:14 PM
さまざまな Java フレームワークのパフォーマンスの比較
Jun 05, 2024 pm 07:14 PM
さまざまな Java フレームワークのパフォーマンス比較: REST API リクエスト処理: Vert.x が最高で、リクエスト レートは SpringBoot の 2 倍、Dropwizard の 3 倍です。データベース クエリ: SpringBoot の HibernateORM は Vert.x や Dropwizard の ORM よりも優れています。キャッシュ操作: Vert.x の Hazelcast クライアントは、SpringBoot や Dropwizard のキャッシュ メカニズムよりも優れています。適切なフレームワーク: アプリケーションの要件に応じて選択します。Vert.x は高パフォーマンスの Web サービスに適しており、SpringBoot はデータ集約型のアプリケーションに適しており、Dropwizard はマイクロサービス アーキテクチャに適しています。
 Yolov10: 詳細な説明、展開、アプリケーションがすべて 1 か所にまとめられています。
Jun 07, 2024 pm 12:05 PM
Yolov10: 詳細な説明、展開、アプリケーションがすべて 1 か所にまとめられています。
Jun 07, 2024 pm 12:05 PM
1. はじめに ここ数年、YOLO は、計算コストと検出パフォーマンスの効果的なバランスにより、リアルタイム物体検出の分野で主流のパラダイムとなっています。研究者たちは、YOLO のアーキテクチャ設計、最適化目標、データ拡張戦略などを調査し、大きな進歩を遂げました。同時に、後処理に非最大抑制 (NMS) に依存すると、YOLO のエンドツーエンドの展開が妨げられ、推論レイテンシに悪影響を及ぼします。 YOLO では、さまざまなコンポーネントの設計に包括的かつ徹底的な検査が欠けており、その結果、大幅な計算冗長性が生じ、モデルの機能が制限されます。効率は最適ではありませんが、パフォーマンス向上の可能性は比較的大きくなります。この作業の目標は、後処理とモデル アーキテクチャの両方から YOLO のパフォーマンス効率の境界をさらに改善することです。この目的を達成するために
 清華大学が引き継ぎ、YOLOv10 が登場しました。パフォーマンスが大幅に向上し、GitHub のホット リストに掲載されました。
Jun 06, 2024 pm 12:20 PM
清華大学が引き継ぎ、YOLOv10 が登場しました。パフォーマンスが大幅に向上し、GitHub のホット リストに掲載されました。
Jun 06, 2024 pm 12:20 PM
ターゲット検出システムのベンチマークである YOLO シリーズが再び大幅にアップグレードされました。今年 2 月の YOLOv9 のリリース以来、YOLO (YouOnlyLookOnce) シリーズのバトンは清華大学の研究者の手に渡されました。先週末、YOLOv10 のリリースのニュースが AI コミュニティの注目を集めました。これは、コンピュータ ビジョンの分野における画期的なフレームワークと考えられており、リアルタイムのエンドツーエンドの物体検出機能で知られており、効率と精度を組み合わせた強力なソリューションを提供することで YOLO シリーズの伝統を継承しています。論文アドレス: https://arxiv.org/pdf/2405.14458 プロジェクトアドレス: https://github.com/THU-MIG/yo
 Google Gemini 1.5 テクニカル レポート: 数学オリンピックの問題を簡単に証明、Flash バージョンは GPT-4 Turbo より 5 倍高速
Jun 13, 2024 pm 01:52 PM
Google Gemini 1.5 テクニカル レポート: 数学オリンピックの問題を簡単に証明、Flash バージョンは GPT-4 Turbo より 5 倍高速
Jun 13, 2024 pm 01:52 PM
今年 2 月、Google はマルチモーダル大型モデル Gemini 1.5 を発表しました。これは、エンジニアリングとインフラストラクチャの最適化、MoE アーキテクチャ、その他の戦略を通じてパフォーマンスと速度を大幅に向上させました。より長いコンテキスト、より強力な推論機能、およびクロスモーダル コンテンツのより適切な処理が可能になります。今週金曜日、Google DeepMind は Gemini 1.5 の技術レポートを正式にリリースしました。このレポートには Flash バージョンとその他の最近のアップグレードが含まれています。このドキュメントは 153 ページあります。技術レポートのリンク: https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf このレポートでは、Google が Gemini1 を紹介しています。
 C++ でマルチスレッド プログラムのパフォーマンスを最適化するにはどうすればよいですか?
Jun 05, 2024 pm 02:04 PM
C++ でマルチスレッド プログラムのパフォーマンスを最適化するにはどうすればよいですか?
Jun 05, 2024 pm 02:04 PM
C++ マルチスレッドのパフォーマンスを最適化するための効果的な手法には、リソースの競合を避けるためにスレッドの数を制限することが含まれます。競合を軽減するには、軽量のミューテックス ロックを使用します。ロックの範囲を最適化し、待ち時間を最小限に抑えます。ロックフリーのデータ構造を使用して同時実行性を向上させます。ビジー待機を回避し、イベントを通じてリソースの可用性をスレッドに通知します。
 専用アプリのリリースにより、ChatGPT が macOS で利用可能になりました
Jun 27, 2024 am 10:05 AM
専用アプリのリリースにより、ChatGPT が macOS で利用可能になりました
Jun 27, 2024 am 10:05 AM
Open AI の ChatGPT Mac アプリケーションは、ここ数か月間 ChatGPT Plus サブスクリプションを持つユーザーのみに限定されていましたが、現在は誰でも利用できるようになりました。最新の Apple S を持っている限り、アプリは他のネイティブ Mac アプリと同じようにインストールされます。
