

Al Agent -- 大規模モデルの時代における重要な実装方向

1. LLM ベースのエージェントの全体的なアーキテクチャ
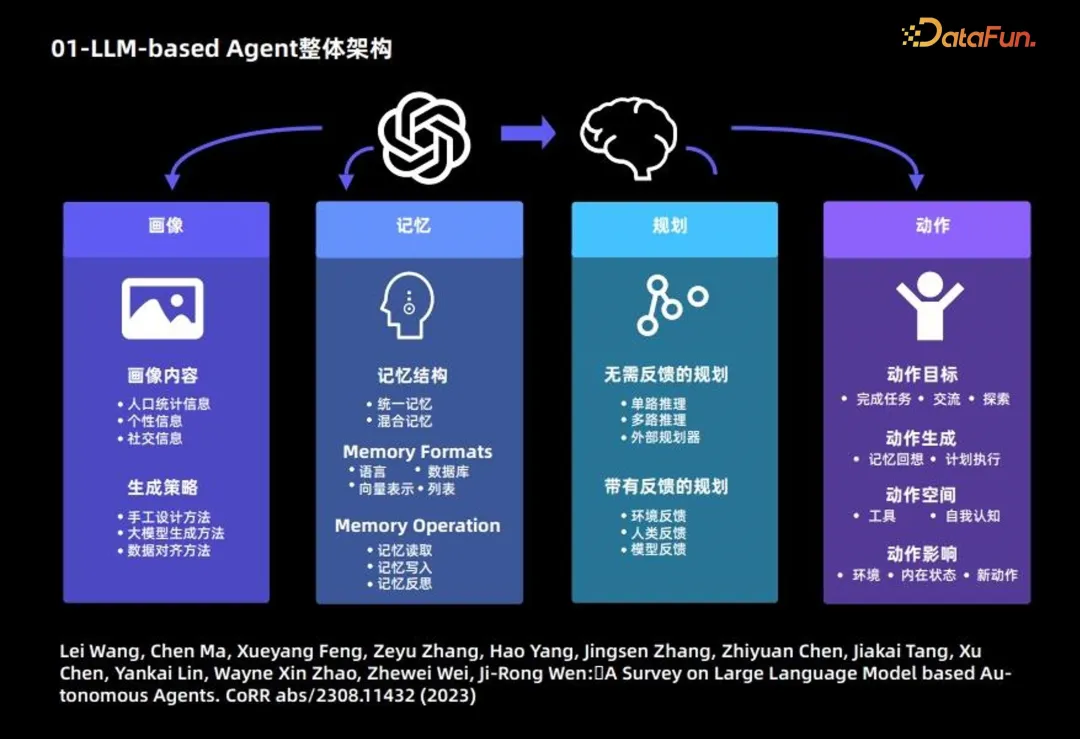
大規模な言語モデル エージェントの構成は主に次のとおりです。
1. ポートレート モジュール: 主にエージェントの背景情報を説明します。
以下では、主なコンテンツと生成戦略を紹介します。ポートレートモジュール。
ポートレートコンテンツは主に、人口統計情報、性格情報、社会情報の 3 種類の情報に基づいています。
生成戦略: ポートレート コンテンツの生成には主に 3 つの戦略が使用されます:
- 手動設計方法: 自分で指定します。メソッドでは、ユーザー ポートレートのコンテンツを大規模モデルのプロンプトに書き込みます。
- # エージェントの数が比較的少ない状況に適しています。方法: 最初に少数のポートレートを例として使用することを指定し、次に多数のエージェントが存在する状況に適した大規模な言語モデルを使用してより多くのポートレートを生成します。 データ配置方法: 必須 大規模言語モデルのプロンプトとして事前に指定されたデータセット内の文字の背景情報に基づいて、対応する予測が行われます。
- 2. メモリ モジュール: 主な目的は、エージェントの行動を記録し、将来のエージェントの決定をサポートすることです。記憶構造:
統合記憶: 短期記憶のみが考慮され、長期記憶は考慮されません。
ハイブリッド記憶: 長期記憶と短期記憶の組み合わせ。
- #記憶形式:主に以下の 4 つの形式に基づいています。
- #言語
##データベース
- ベクトル表現
- リスト
- メモリ内容:共通以下の3つ操作:
- #メモリ読み取り
メモリ書き込み
- 思い出の振り返り
- 3. 計画モジュール
- フィードバックなしの計画: 大規模な言語モデルでは、推論プロセス中に外部環境からのフィードバックを必要としません。このタイプの計画はさらに 3 つのタイプに細分されます。単一チャネルベースの推論は、大規模な言語モデルを 1 回だけ使用して、クラウドソーシングのアイデアを利用してマルチチャネルベースの推論のステップを完全に出力します。大規模な言語モデルが複数のパスを生成し、外部プランナーを借用して最適なパスを決定できるようにします。
フィードバックを伴う計画: この計画方法では外部環境からのフィードバックが必要ですが、大規模言語モデルでは次のステップとその後の計画のために環境からのフィードバックが必要です。 。このタイプの計画フィードバックの提供者は、環境フィードバック、人的フィードバック、モデル フィードバックの 3 つのソースから提供されます。
- 4. アクション モジュール
- アクション目標: 一部のエージェントの目標は次のとおりです。特定のタスクを完了する コミュニケーションや探索など、いくつかのタスクがあります。
アクション生成: 一部のエージェントは記憶の想起に依存してアクションを生成し、一部のエージェントは元の計画に従って特定のアクションを実行します。
- アクション空間: いくつかのアクション空間はツールのコレクションであり、いくつかは視点からアクション空間全体を考慮した大規模な言語モデル自身の知識に基づいています。自己認識の。
- アクションの影響: 環境への影響、内部状態への影響、将来の新しいアクションへの影響を含みます。
- 上記はエージェントの全体的なフレームワークです。詳細については、次の論文を参照してください: Lei Wang、Chen Ma、Xueyang Feng、Zeyu Zhang、Hao Yang、Jingsen Zhang、Zhiyuan Chen、Jiakai Tang、Xu Chen、Yankai Lin、Wayne Xin Zhao、Zhewei Wei、Ji-Rong Wen: 大規模言語モデルに基づく自律言語に関する調査エージェント。CoRR abs /2308.11432 (2023)
2. LLM ベースのエージェントの重要な問題と困難な問題
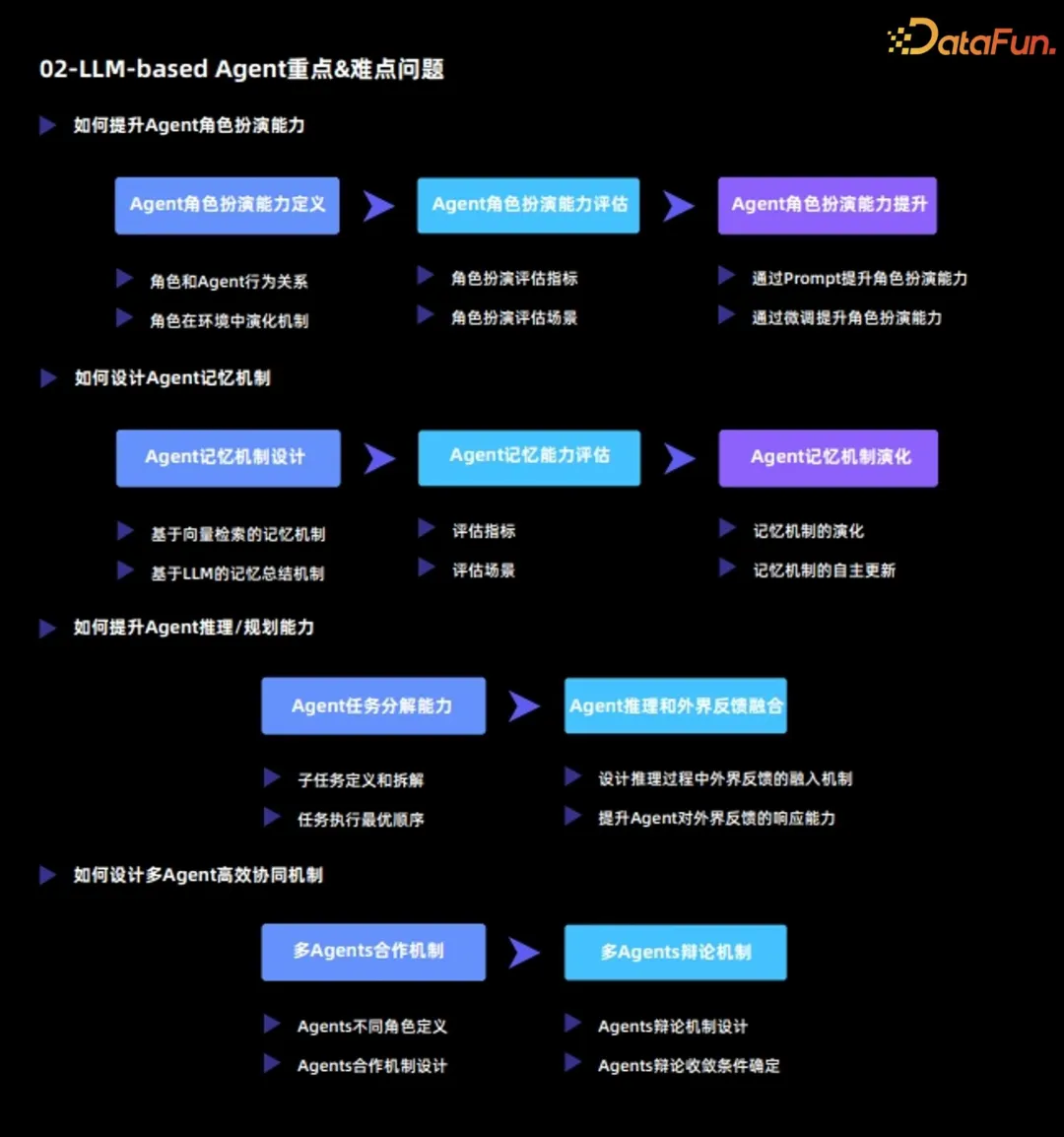
##現在の大規模言語モデル エージェントの重要な問題と困難な問題は主に次のとおりです。 :
1. エージェントのロールプレイング能力を向上させる方法
エージェントの最も重要な機能は、特定のタスクを実行して特定のタスクを完了することです。役割を果たしたり、さまざまなシミュレーションを完了したりするため、エージェントのロールプレイング能力が非常に重要です。
(1) エージェントのロールプレイング能力の定義
エージェントのロールプレイング能力は 2 つの側面に分けられます:
- ロールとエージェント間の動作関係
- ##環境におけるロールの進化メカニズム
ロールプレイング能力を定義したら、次のステップは次のとおりです。エージェントのロールプレイング能力を次の 2 つの側面から評価します。 :
- ロールプレイング評価指標
- #ロールプレイング評価シナリオ
On評価の基礎として、エージェントのロールプレイング能力をさらに向上させる必要があります。次の 2 つの方法があります。
- プロンプトを通じてロールプレイング能力を向上させる。 : この方法の本質は、プロンプトを設計することで元の大規模言語モデルの能力を刺激することです。
- 微調整を通じてロールプレイング能力を向上させます。このメソッドは通常、外部データに基づいており、ロールプレイング機能を向上させるために大規模な言語モデルを再微調整します。 #2. エージェントのメモリ メカニズムを設計する方法
エージェントと大規模言語モデルの最大の違いは次のとおりです。エージェントは、環境が常に自己進化と自己学習を行っているため、記憶メカニズムが非常に重要な役割を果たします。エージェントの記憶機構を 3 つの側面から分析します。
(1) エージェントの記憶機構の設計
#次の 2 つの一般的な記憶機構が共通です。
##ベクトル検索に基づくメモリ メカニズム
- LLM の概要に基づくメモリ メカニズム
- # (2) エージェントの記憶能力評価
#エージェントの記憶能力を評価するには、主に以下の 2 つを判断する必要があります。ポイント:
評価指標
- ##評価シナリオ
- ##(3) エージェントの記憶メカニズムの進化 最後に、以下を含むエージェントの記憶メカニズムの進化を分析する必要があります。
- #記憶メカニズムの進化
- 記憶メカニズムの自律更新
- サブタスクの定義と逆アセンブリ
- タスク実行の最適な順序
- 推論プロセス中の外部フィードバックの統合メカニズムを設計します。エージェントと環境を形成させます。インタラクティブ全体;
- 外部フィードバックに応答するエージェントの能力を向上させる: 一方で、エージェントは外部環境に真に応答する必要があります。一方、エージェントは外部環境に対して質問し、解決策を模索できる必要があります。
- エージェントの異なる役割定義
- エージェントの連携メカニズムの設計
- エージェントの議論メカニズムの設計
- エージェントによる収束条件の決定についての議論
- #短期記憶の内容の保存時間は比較的短いです
- (3) 長期記憶
- 長期記憶内容の保存時間は比較的長いです。
- 長期記憶の内容は、既存の記憶が独立して反映、昇華、洗練されるに従って保存されます。
- #3. アクション モジュール
- #エージェントのソーシャルメディアへの投稿行動。
- シミュレーション プロセス全体を通じて、エージェントは外部からの干渉を受けることなく、アクションの各ラウンドで 3 つのアクションを自由に選択できます。異なるエージェントが互いに対話することがわかります。ソーシャルメディアやレコメンデーションシステムでさまざまな行動を自律的に生成し、複数回のシミュレーションを繰り返すと、いくつかの興味深い社会現象やインターネット上のユーザーの行動を観察することができます。
- 詳細については、次の文書を参照してください:
Lei Wang、Jingsen Zhang、Hao Yang、Zhiyuan Chen、Jiakai Tang、Zeyu Zhang、Xu Chen、Yankai Lin、Ruihua Song、Wayne Xin Zhao、Jun Xu、Zhicheng Dou、Jun Wang、Ji-Rong Wen :大規模言語モデルベースのエージェントとユーザー行動分析の出会い: 新しいユーザー シミュレーション パラダイム
4. ベース大規模な言語モデルのためのマルチエージェント ソフトウェア開発について

#次のエージェントの例は、マルチ エージェントを使用したソフトウェア開発です。この作業はマルチエージェント協力の初期の作業でもあり、その主な目的は、さまざまなエージェントを使用して完全なソフトウェアを開発することです。したがって、同社はソフトウェア会社とみなすことができ、さまざまなエージェントがさまざまな役割を果たします。CEO、CTO、CPO などの役割を含む設計を担当するエージェントもいれば、コーディングを担当するエージェントもいます。主にテストを担当するほか、ドキュメントの作成を担当するエージェントもいます。このようにして、異なるエージェントが異なるタスクを担当し、最終的にエージェント間の協力メカニズムが通信を通じて調整および更新され、最終的に完全なソフトウェア開発プロセスが完了します。
#5. LLM ベースのエージェントの今後の方向性
大規模な言語モデルのエージェントは現在 2 つの主な方向に分類できます:
- MetaGPT、ChatDev、Ghost、DESP などの特定のタスクを解決する
このタイプのエージェントは、最終的には人類の正しい価値観に沿った「スーパーマン」である必要があり、それには 2 つの「修飾子」があります:
正しく調整された人間の価値観;
#通常の人間の能力を超えています。 - 生成エージェント、ソーシャル シミュレーション、RecAgent など、現実世界をシミュレートします。
このタイプのエージェントに必要な能力は、これまでとはまったく逆です。最初のタイプ。
エージェントがさまざまな価値観を提示できるようにします。
エージェントが一般の人々に合わせようとすることを願っています。普通の人を超えるのではなく。
さらに、現在の大規模言語モデル エージェントには次の 2 つの問題点があります:
- 錯覚問題
エージェントは継続的に環境と対話する必要があるため、各ステップの幻覚が蓄積され、累積的な影響が生じ、問題がより深刻になるため、大規模モデルの幻覚問題はさらに解決する必要があります。ここに注意してください。ソリューションには次のものが含まれます:
人間とマシンの効率的なコラボレーション フレームワークを設計する;
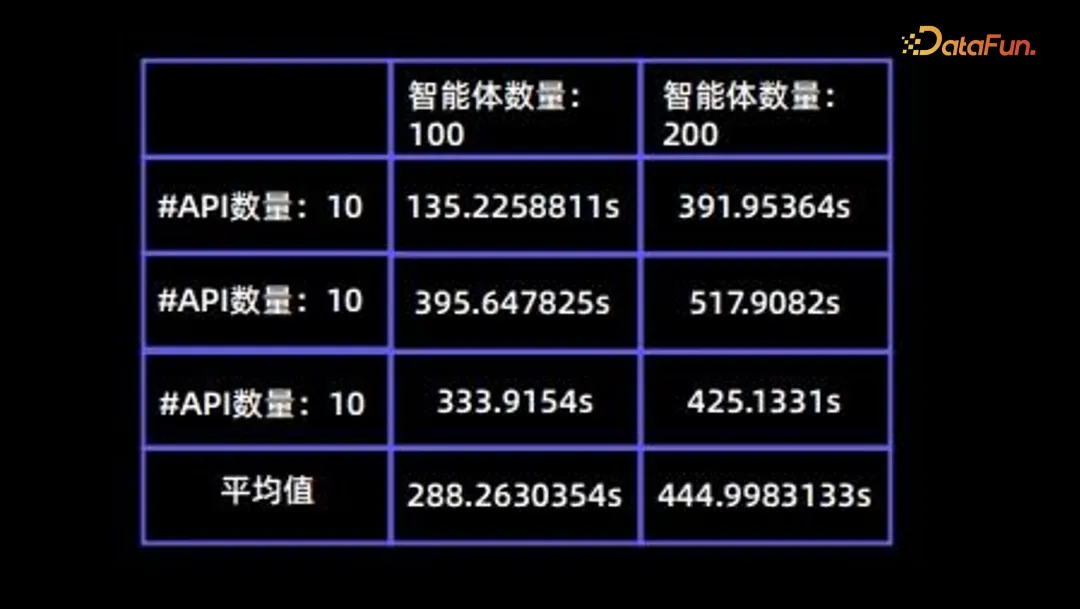
設計効率的な人間介入メカニズムを計画します。 - 効率の問題
シミュレーション プロセスでは、効率が非常に重要な問題になります。次の表は、さまざまな API 番号でのさまざまなエージェントの時間消費をまとめたものです。
以上が今回シェアした内容です、よろしくお願いします。
- MetaGPT、ChatDev、Ghost、DESP などの特定のタスクを解決する
3. エージェントの推論・計画能力を向上させる方法
# (1) エージェントのタスク分解能力
(1) マルチエージェントコラボレーションメカニズム
3. 言語モデルの大きなユーザー行動シミュレーション エージェントに基づく
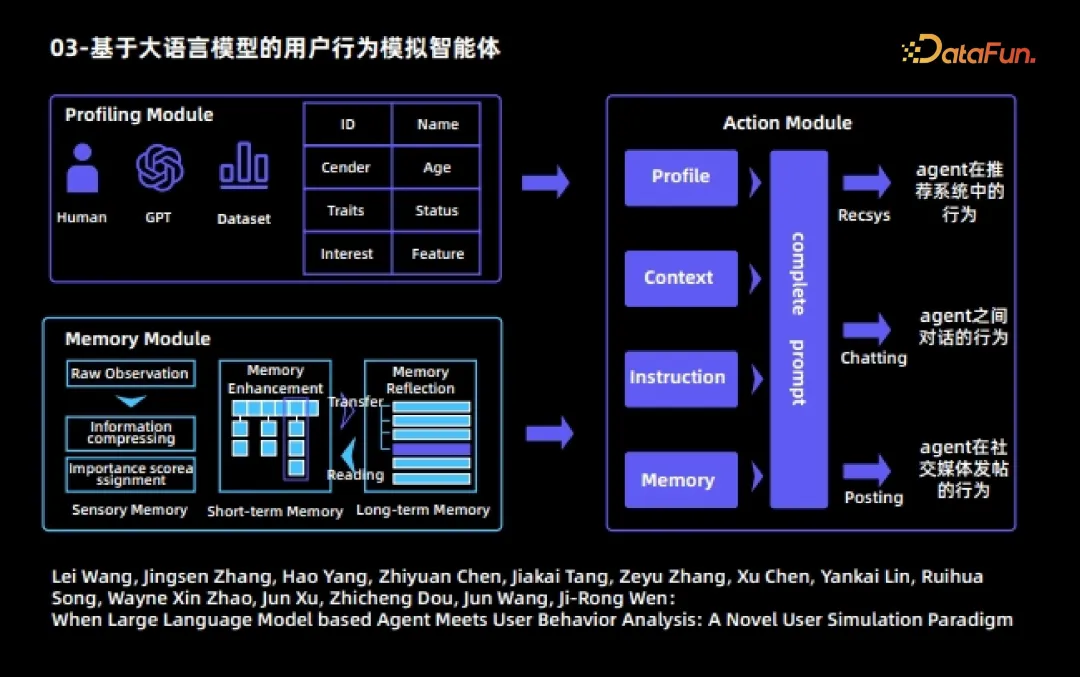 #以下、エージェントの実例をいくつか示します。 1 つ目は、大規模な言語モデルに基づくユーザー行動シミュレーション エージェントです。このエージェントは、大規模言語モデル エージェントとユーザー行動分析を組み合わせた初期の作品でもあります。この作業では、各エージェントは 3 つのモジュールに分割されています:
#以下、エージェントの実例をいくつか示します。 1 つ目は、大規模な言語モデルに基づくユーザー行動シミュレーション エージェントです。このエージェントは、大規模言語モデル エージェントとユーザー行動分析を組み合わせた初期の作品でもあります。この作業では、各エージェントは 3 つのモジュールに分割されています:
1。ポートレート モジュール
は、さまざまなエージェントに対してさまざまな属性を指定します。 ID、名前、職業、年齢、興味や特徴など
2. メモリ モジュール
メモリ モジュールには 3 つのサブモジュールが含まれています
(1 ) 感情記憶
(2) 短期記憶
- 客観的に観察された生の観察を処理した後の量より高い観測値は短期記憶に保存されます。
- #短期記憶の内容は自動的に転送されます
各エージェントは 3 つのアクションを実行できます:
映画の視聴、次のページの検索、推奨システムからの終了など、推奨システムにおけるエージェントの動作。 #エージェント間の会話

以上がAl Agent -- 大規模モデルの時代における重要な実装方向の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7563
7563
 15
1384
52
84
11
28
99
15
1384
52
84
11
28
99

 Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
Bytedance Cutting が SVIP スーパー メンバーシップを開始: 継続的な年間サブスクリプションは 499 元で、さまざまな AI 機能を提供
Jun 28, 2024 am 03:51 AM
このサイトは6月27日、JianyingはByteDanceの子会社であるFaceMeng Technologyによって開発されたビデオ編集ソフトウェアであり、Douyinプラットフォームに依存しており、基本的にプラットフォームのユーザー向けに短いビデオコンテンツを作成すると報告しました。 Windows、MacOS、その他のオペレーティング システム。 Jianyingは会員システムのアップグレードを正式に発表し、インテリジェント翻訳、インテリジェントハイライト、インテリジェントパッケージング、デジタルヒューマン合成などのさまざまなAIブラックテクノロジーを含む新しいSVIPを開始しました。価格的には、クリッピングSVIPの月額料金は79元、年会費は599元(当サイト注:月額49.9元に相当)、継続月額サブスクリプションは月額59元、継続年間サブスクリプションは、年間499元(月額41.6元に相当)です。さらに、カット担当者は、ユーザーエクスペリエンスを向上させるために、オリジナルのVIPに登録している人は、
 Groq Llama 3 70B をローカルで使用するためのステップバイステップ ガイド
Jun 10, 2024 am 09:16 AM
Groq Llama 3 70B をローカルで使用するためのステップバイステップ ガイド
Jun 10, 2024 am 09:16 AM
翻訳者 | Bugatti レビュー | Chonglou この記事では、GroqLPU 推論エンジンを使用して JanAI と VSCode で超高速応答を生成する方法について説明します。 Groq は AI のインフラストラクチャ側に焦点を当てているなど、誰もがより優れた大規模言語モデル (LLM) の構築に取り組んでいます。これらの大型モデルがより迅速に応答するためには、これらの大型モデルからの迅速な応答が鍵となります。このチュートリアルでは、GroqLPU 解析エンジンと、API と JanAI を使用してラップトップ上でローカルにアクセスする方法を紹介します。この記事では、これを VSCode に統合して、コードの生成、コードのリファクタリング、ドキュメントの入力、テスト ユニットの生成を支援します。この記事では、独自の人工知能プログラミングアシスタントを無料で作成します。 GroqLPU 推論エンジン Groq の概要
 Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
Rag と Sem-Rag を使用したコンテキスト拡張 AI コーディング アシスタント
Jun 10, 2024 am 11:08 AM
検索強化生成およびセマンティック メモリを AI コーディング アシスタントに組み込むことで、開発者の生産性、効率、精度を向上させます。 JanakiramMSV 著者の EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG から翻訳。基本的な AI プログラミング アシスタントは当然役に立ちますが、ソフトウェア言語とソフトウェア作成の最も一般的なパターンに関する一般的な理解に依存しているため、最も適切で正しいコードの提案を提供できないことがよくあります。これらのコーディング アシスタントによって生成されたコードは、彼らが解決する責任を負っている問題の解決には適していますが、多くの場合、個々のチームのコーディング標準、規約、スタイルには準拠していません。これにより、コードがアプリケーションに受け入れられるように修正または調整する必要がある提案が得られることがよくあります。
 微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
微調整によって本当に LLM が新しいことを学習できるようになるのでしょうか: 新しい知識を導入すると、モデルがより多くの幻覚を生成する可能性があります
Jun 11, 2024 pm 03:57 PM
大規模言語モデル (LLM) は巨大なテキスト データベースでトレーニングされ、そこで大量の現実世界の知識を取得します。この知識はパラメータに組み込まれており、必要なときに使用できます。これらのモデルの知識は、トレーニングの終了時に「具体化」されます。事前トレーニングの終了時に、モデルは実際に学習を停止します。モデルを調整または微調整して、この知識を活用し、ユーザーの質問により自然に応答する方法を学びます。ただし、モデルの知識だけでは不十分な場合があり、モデルは RAG を通じて外部コンテンツにアクセスできますが、微調整を通じてモデルを新しいドメインに適応させることが有益であると考えられます。この微調整は、ヒューマン アノテーターまたは他の LLM 作成物からの入力を使用して実行され、モデルは追加の実世界の知識に遭遇し、それを統合します。
 GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
GenAI および LLM の技術面接に関する 7 つのクールな質問
Jun 07, 2024 am 10:06 AM
AIGC について詳しくは、51CTOAI.x コミュニティ https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou を参照してください。これらの質問は、インターネット上のどこでも見られる従来の質問バンクとは異なります。既成概念にとらわれずに考える必要があります。大規模言語モデル (LLM) は、データ サイエンス、生成人工知能 (GenAI)、および人工知能の分野でますます重要になっています。これらの複雑なアルゴリズムは人間のスキルを向上させ、多くの業界で効率とイノベーションを推進し、企業が競争力を維持するための鍵となります。 LLM は、自然言語処理、テキスト生成、音声認識、推奨システムなどの分野で幅広い用途に使用できます。 LLM は大量のデータから学習することでテキストを生成できます。
 OpenHarmony で大規模な言語モデルをローカルにデプロイする
Jun 07, 2024 am 10:02 AM
OpenHarmony で大規模な言語モデルをローカルにデプロイする
Jun 07, 2024 am 10:02 AM
この記事は、第 2 回 OpenHarmony テクノロジー カンファレンスで実証された「OpenHarmony での大規模言語モデルのローカル デプロイメント」の結果をオープンソース化します。オープンソースのアドレス: https://gitee.com/openharmony-sig/tpc_c_cplusplus/blob/master/thirdparty。 /InferLLM/docs/hap_integrate.md。実装のアイデアと手順は、軽量 LLM モデル推論フレームワーク InferLLM を OpenHarmony 標準システムに移植し、OpenHarmony 上で実行できるバイナリ製品をコンパイルすることです。 InferLLM はシンプルで効率的な L
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
