

Transformer の通常の道をたどる代わりに、RNN の新しい国内アーキテクチャが修正され、RWKV となり、新たな進歩があります。
は 2 つの新しい RWKV アーキテクチャを提案します。 イーグル (RWKV-5) および フィンチ (RWKV-6)。
これら 2 つのシーケンス モデルは RWKV-4 アーキテクチャに基づいており、その後改良されました。
新しいアーキテクチャにおける設計の進歩には、多頭行列値状態(多頭行列値状態)および動的再帰メカニズム##が含まれます。 # (動的再帰メカニズム) 、これらの改善により、RNN の推論効率特性を維持しながら、RWKV モデルの表現能力が向上します。
同時に、新しいアーキテクチャでは、1 兆 1,200 億のトークンを含む新しい多言語コーパスが導入されています。 チームは、RWKV の多言語性を強化するために、貪欲マッチング(貪欲マッチング) に基づく高速単語セグメンターも開発しました。
現在、4 つの Eagle モデルと 2 つの Finch モデルが Huohuofian でリリースされています~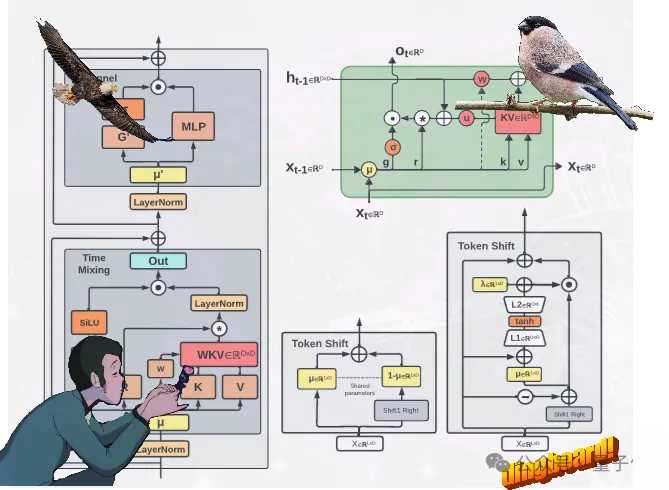
4 Eagle (RWKV-5) Model: 0.4B、1.5B、3B、それぞれ 7B パラメータ サイズ;
2 Finch (RWKV-6) Model: それぞれ 1.6B、3B パラメータ サイズ。
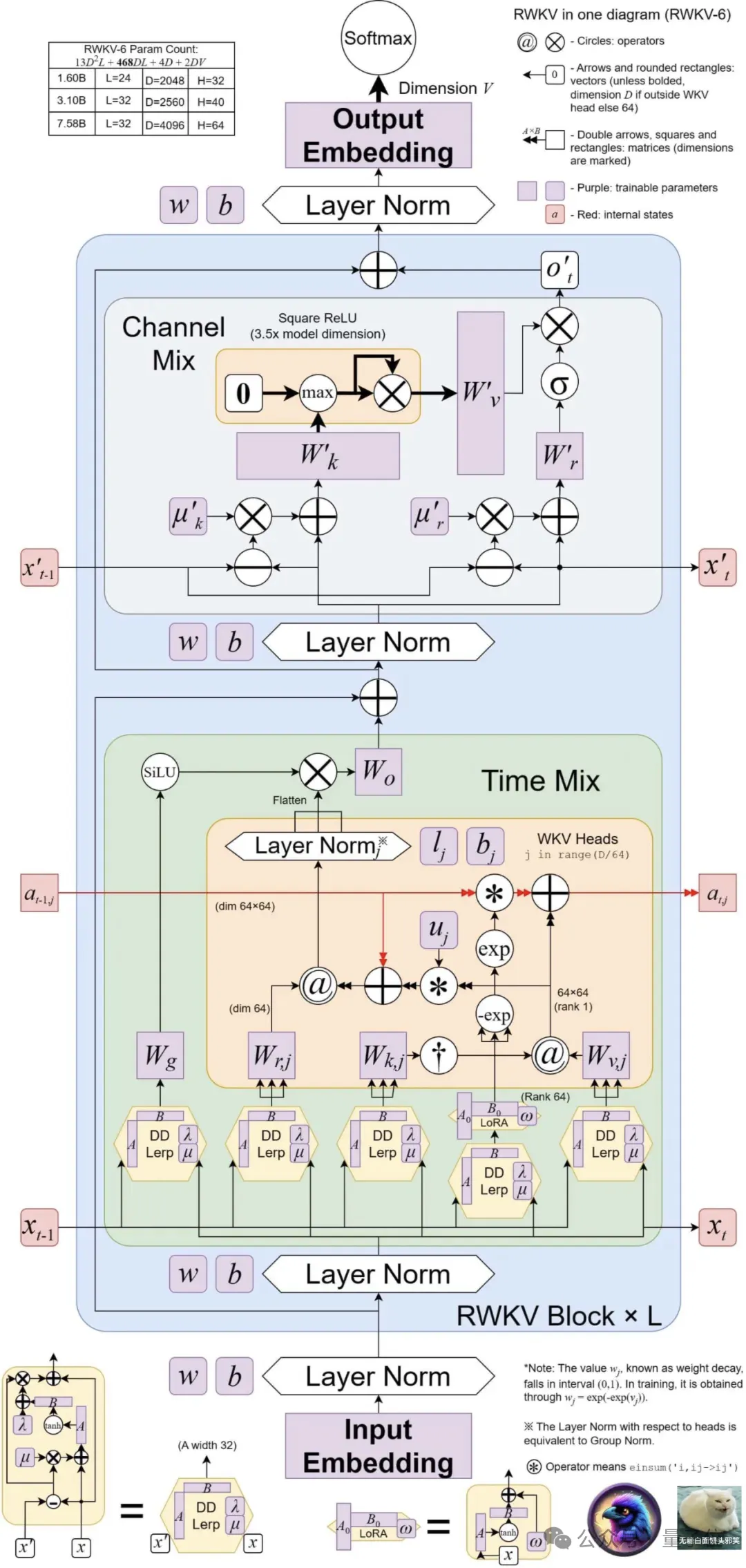
複数の行列値の状態 (ベクトル値の状態の代わりに) 、再構築された受け入れ状態を使用することでこれを実現します。 RWKV-4 から学んだ追加のゲート メカニズム、改善されたアーキテクチャ、および学習減衰の進行状況。
Finch は、パラメトリック線形補間を含むタイム ミキシングおよびトークン シフト モジュールのための新しいデータ関連関数 を導入することにより、アーキテクチャのパフォーマンス機能と柔軟性をさらに向上させます。
さらに、Finch は、学習可能な重み行列を有効にして、状況に応じて学習されたデータ減衰ベクトルを効果的に強化できる、低ランク適応関数の新しい使用法を提案しています。 最後に、RWKV の新しいアーキテクチャでは、新しいトークナイザーRWKV World Tokenizer、および 新しいデータ セット#RWKV World を導入します。 v2 は両方とも、多言語およびコード データに対する RWKV モデルのパフォーマンスを向上させるために使用されます。 新しいトークナイザー RWKV World Tokenizer には、一般的ではない言語の単語が含まれており、トライベースの貪欲マッチング
(貪欲マッチング)を通じて迅速な単語の分割を実行します。 新しいデータ セット RWKV World v2 は、厳選された公開されているさまざまなデータ ソースから取得された、新しい多言語 1.12T トークン データ セットです。
データ構成は、英語データが約70%、多言語データが約15%、コードデータが約15%となっています。
ベンチマーク結果は何ですか?
主要な権威ある評価リストに載っている新しいモデルの結果を見てみましょう——
MQAR テスト結果
MQAR (複数クエリ連想記憶) このタスクは、言語モデルを評価するために使用されるタスクであり、複数のクエリの下でモデルの連想記憶能力をテストするように設計されています。 このタイプのタスクでは、モデルは複数のクエリを指定して関連情報を取得する必要があります。
MQAR タスクの目標は、複数のクエリで情報を取得するモデルの能力と、さまざまなクエリに対するモデルの適応性と精度を測定することです。
次の図は、RWKV-4、Eagle、Finch、およびその他の非 Transformer アーキテクチャの MQAR タスク テストの結果を示しています。
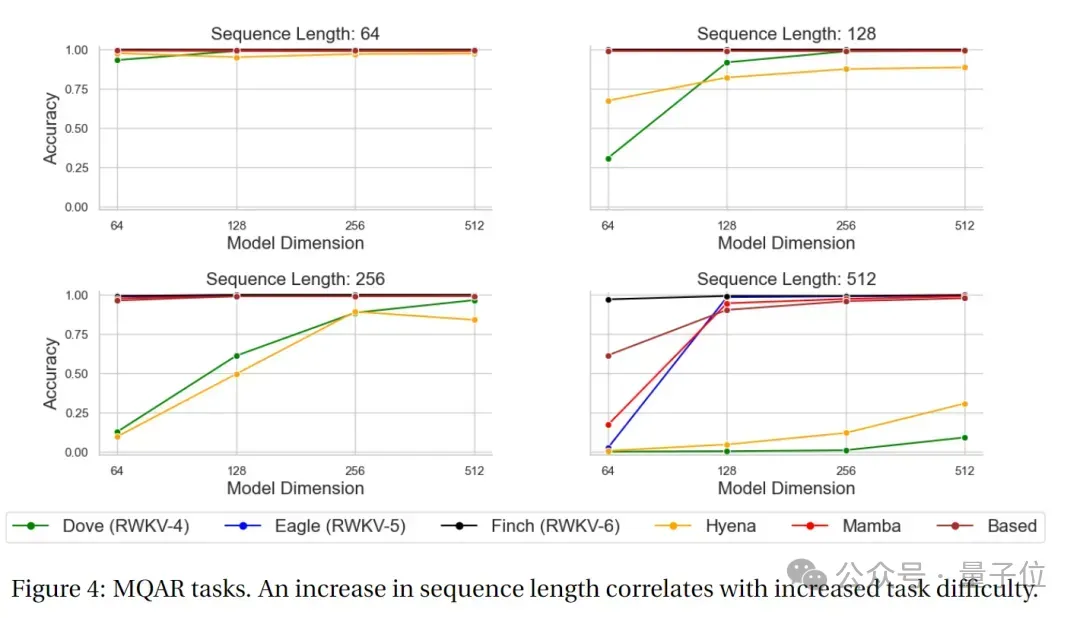 MQAR タスクの精度テストでは、さまざまなシーケンス長テストにおける Finch の精度パフォーマンスが RWKV-4 および RWKV -5 と比較して非常に安定していることがわかります。およびその他の非 Transformer アーキテクチャ モデルには、パフォーマンスに大きな利点があります。
MQAR タスクの精度テストでは、さまざまなシーケンス長テストにおける Finch の精度パフォーマンスが RWKV-4 および RWKV -5 と比較して非常に安定していることがわかります。およびその他の非 Transformer アーキテクチャ モデルには、パフォーマンスに大きな利点があります。
長いコンテキストの実験
。
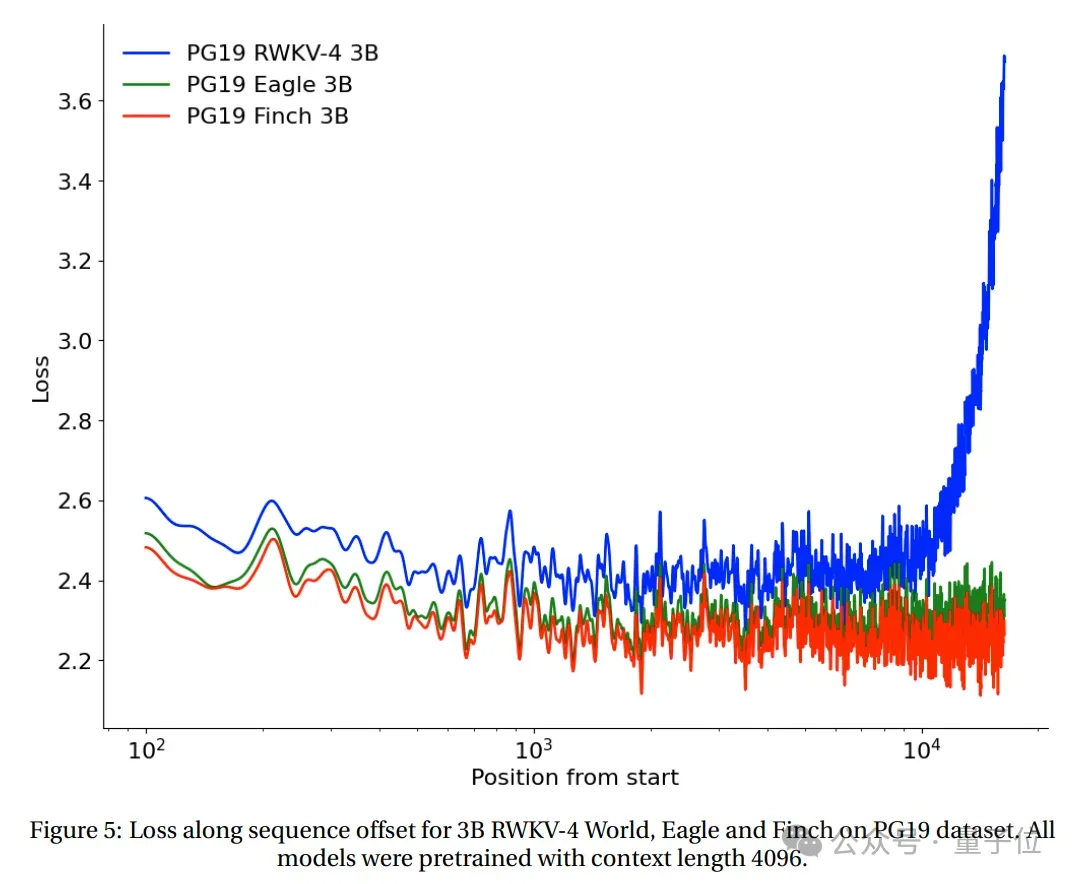 テスト結果は、Eagle は長いシーケンス タスクにおいて RWKV-4 よりも大幅に改善されており、コンテキスト長 4096 でトレーニングされた Finch は Eagle よりも優れたパフォーマンスを発揮し、自動的に適切に適応できることを示しています。コンテキストの長さが 20,000 を超える。
テスト結果は、Eagle は長いシーケンス タスクにおいて RWKV-4 よりも大幅に改善されており、コンテキスト長 4096 でトレーニングされた Finch は Eagle よりも優れたパフォーマンスを発揮し、自動的に適切に適応できることを示しています。コンテキストの長さが 20,000 を超える。
速度とメモリのベンチマーク テスト
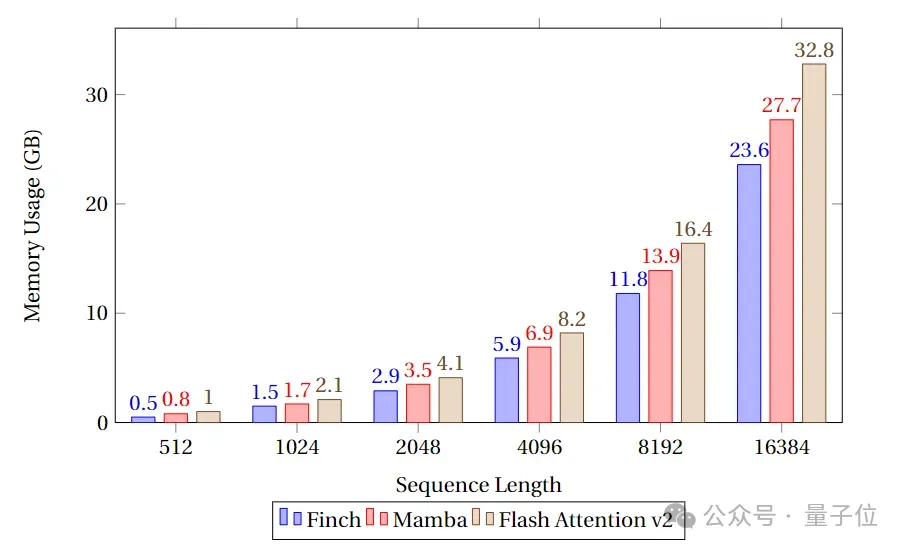
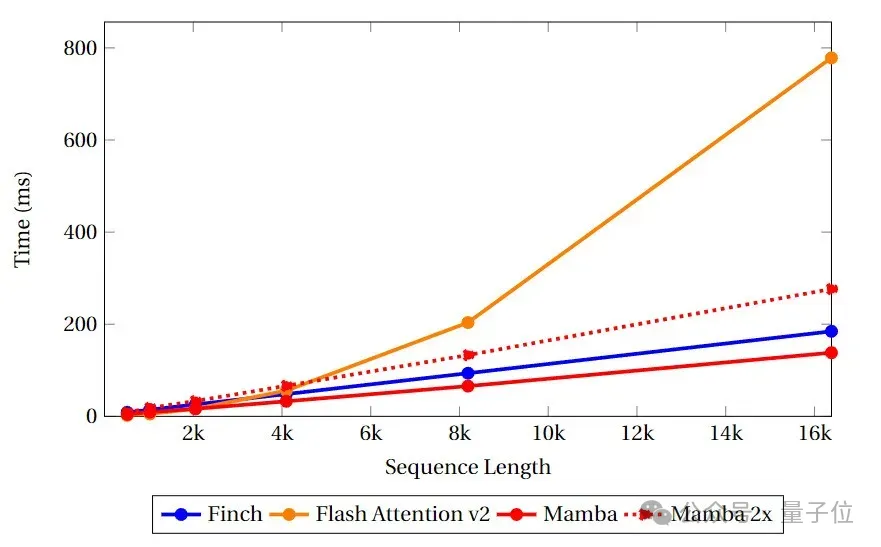
メモリ使用量の点では、Finch は常に Mamba および Flash Attend よりも優れており、メモリ使用量は Mamba および Flash Attend より 40%、17% 少ないことがわかります。それぞれフラッシュ アテンションとマンバ。




上記の研究内容は RWKV からのものです。 Foundation 最新の論文 「イーグルとフィンチ: 行列値状態と動的再帰を使用した RWKV」 がリリースされました。
この論文は、RWKV 創設者 Bo PENG (ブルームバーグ) と RWKV オープンソース コミュニティのメンバーによって共同で完成されました。

ブルームバーグとの共著者、香港大学物理学科卒業、20年のプログラミング経験があり、1999年にOrtus Capitalで働いていました。世界最大の外国為替ヘッジファンドの一員であり、高頻度の定量取引を担当しています。
は、深層畳み込みネットワークに関する書籍『Deep Convolutional Networks · Principles and Practice』も出版しました。
彼の主な焦点と関心はソフトウェアとハードウェアの開発であり、これまでの公開インタビューで、AIGC、特に新しい世代に興味があることを明らかにしました。
現在、Bloomberg には Github 上に 210 万人のフォロワーがいます。
しかし、彼の最も重要な公のアイデンティティは、主に太陽光ランプ、天井ランプ、ポータブルデスクランプなどを製造する照明会社、リンリンテクノロジーの共同創設者です。
そして、彼は上級の猫愛好家であるはずです。Github、Zhihu、WeChat のアバターだけでなく、照明会社の公式 Web サイトのホームページや Weibo にもオレンジ色の猫がいます。

Qubit は、RWKV の現在のマルチモーダルな作業に RWKV Music (音楽ディレクション) と VisualRWKV (画像ディレクション) が含まれていることを知りました。
次に、RWKV は次の方向に焦点を当てます:
https://arxiv.org/pdf/2404.05892.pdf
以上が魔法のように修正された RNN が Transformer に挑戦、RWKV は新しい: 2 つの新しいアーキテクチャ モデルを発表の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



