

CVPR 2024 | 新しいフレームワーク CustomNeRF は、テキストまたは画像のプロンプトのみで 3D シーンを正確に編集します

Meitu Imaging Research Institute (MT Lab) は、中国科学院情報工学研究所、北京航空航天大学、中山大学と共同で 3D を提案しました。シーン編集方法 - CustomNeRF。研究結果はCVPR 2024に採択されました。 CustomNeRF は、3D シーンの編集ヒントとしてテキストの説明や参考画像をサポートするだけでなく、ユーザーが提供した情報に基づいて高品質の 3D シーンを生成します。
ニューラル ラディアンス フィールド (NeRF) ニューラル ラディアンス フィールド (NeRF) は 2020 年に提案されて以来、暗黙的な表現を新たなレベルに押し上げました。 NeRF は、現在最も最先端の技術の 1 つとして、コンピュータ ビジョン、コンピュータ グラフィックス、拡張現実、仮想現実などの分野で急速に一般化および応用され、広く注目され続けています。 NeRF は、シーン内の各点の放射線と密度をモデル化することにより高品質の画像合成を可能にし、コンピュータ ビジョン、コンピュータ グラフィックス、拡張現実、仮想現実などの分野のアプリケーションにとって広く魅力的です。 NeRF は、複雑な 3D スキャンや高密度の透視画像を必要とせずに、入力シーンから高品質の画像を生成できる機能がユニークです。この特徴により、NeRF はコンピュータ ビジョン、コンピュータ グラフィックス、拡張現実、仮想現実などの多くの分野で幅広い応用が期待されており、引き続き幅広い注目を集めています。 NeRF は、シーン内のすべての点の輝度と密度をモデル化することにより、高品質の画像合成を可能にします。 NeRF は高品質の 3D レンダリングの生成にも使用できるため、仮想現実や拡張現実などの分野のアプリケーションに非常に有望です。 NeRF の急速な開発と広範な応用は今後も広く注目を集め、将来的には NeRF に基づくさらに多くのイノベーションとアプリケーションが登場すると予想されます。
NeRF (Neural Radiation Field) は、最適化と連続表現に使用される機能で、3D シーンの再構築に多くの用途があります。 3D オブジェクトやシーンのテクスチャの再描画や様式化など、3D シーン編集の分野の研究も推進しました。 3D シーン編集の柔軟性をさらに向上させるために、NeRF の暗黙的な表現と 3D シーンの幾何学的特性により、テキスト プロンプトに準拠した編集結果が得られる、事前トレーニングされたモデルに基づく NeRF 編集方法も最近広く検討されています。これらは非常に簡単に実装できます。
テキスト駆動の 3D シーン編集で正確な制御を実現するために、Meitu Imaging Research Institute (MT Lab)、中国科学院情報工学研究所、北京航空航天大学、および中山大学は、テキスト記述と参照画像をエディターが提供する CustomNeRF フレームワークに統合する方法を共同で提案しました。このフレームワークには、パースペクティブ固有のサブジェクト V* が組み込まれており、一般およびカスタマイズされた 3D シーン編集要件を満たすためにハイブリッド表現に埋め込まれています。研究結果は CVPR 2024 に記録され、コードはオープンソースになりました。

論文リンク: https://arxiv.org/abs/2312.01663
コードリンク: https://github.com/hrz2000/customnerf

CustomNeRF によって解決された 2 つの大きな課題
現在は、事前学習済みの拡散モデルに基づく 3D シーン編集が主流です 手法は大きく分けられます2つのカテゴリーに分けられます。
1 つは、画像編集モデルを使用してデータ セット内の画像を繰り返し更新する方法ですが、画像編集モデルの機能によって制限され、編集状況によっては失敗します。 2 番目に、分別蒸留サンプリング (SDS) 損失を使用してシーンを編集します。ただし、テキストとシーンの間の位置合わせの問題のため、この方法は実際のシーンに直接適用できず、非現実的なシーンで不必要な歪みが発生します。編集領域では、多くの場合、メッシュやボクセルなどの明示的な中間表現が必要になります。 さらに、現在の 2 種類の方法は、主にテキスト駆動の 3D シーン編集タスクに焦点を当てています。テキストによる説明では、ユーザーの編集ニーズを正確に表現することが困難であることが多く、画像内の特定の概念を 3D シーンに合わせてカスタマイズすることができません。 . では、オリジナルの 3D シーンに対して一般的な編集しか行うことができないため、ユーザーが期待する編集結果を得ることが困難です。 実際、望ましい編集結果を得る鍵は、画像の前景領域を正確に特定することです。これにより、画像の背景を維持しながら、幾何学的に一貫した画像の前景編集を促進できます。 したがって、画像の前景領域のみの正確な編集を実現するために、この論文では、画像の前景領域の編集と完全な編集を交互に行うローカル-グローバル反復編集 (LGIE) のトレーニング スキームを提案します。画像編集。このソリューションは、画像の前景領域を正確に特定し、画像の背景を保持したまま画像の前景のみを操作できます。さらに、画像駆動型 3D シーン編集では、微調整された拡散モデルが基準画像の視点にオーバーフィットすることによって、編集結果に幾何学的な不一致が生じるという問題があります。この点に関して、この論文は、ローカル編集段階で参照画像の主題を表すためにクラス単語のみを使用し、幾何学的に一貫した編集を促進するために事前トレーニングされた拡散モデルの一般的なクラス事前を活用する、クラスガイド付き正則化を設計します。
CustomNeRF の全体プロセス
図 2 に示すように、CustomNeRF は 3 つのステップを使用して、テキスト プロンプトまたは参照画像のガイドの下で 3D シーンを正確に編集および再構築します。この目標。
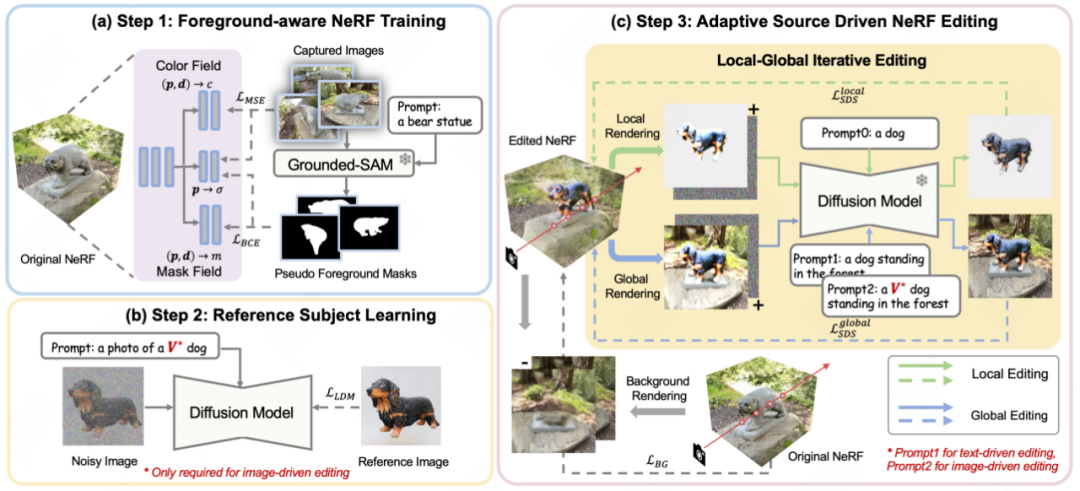
# 図 2 Customnerf の全体フローチャート
これは、最初に元の 3D シーンを再構築する場合です。 、、元の 3D シーンを再構築するときに、CustomNeRF は、通常の色と密度に加えて編集確率を推定する追加のマスク フィールドを導入します。図 2(a) に示すように、3D シーンを再構成する必要がある一連の画像について、論文ではまず Grouded SAM を使用して自然言語記述から画像編集領域のマスクを抽出し、元の画像セットを結合します。フォアグラウンドを意識した NeRF をトレーニングします。 NeRF 再構成後、編集確率を使用して編集対象の画像領域 (つまり、画像の前景領域) を無関係な画像領域 (つまり、画像の背景領域) から区別し、画像編集トレーニング中の分離レンダリングを容易にします。
第 2 に、図 2(b) に示すように、画像駆動型とテキスト駆動型の 3D シーン編集タスクを統合するために、この論文ではカスタム拡散法を使用して画像の下の参照画像を微調整します。特定のエージェントの主要な特性を学習するための駆動条件。トレーニング後、特別な単語 V* を通常の単語タグとして使用して、参照画像内の主題の概念を表現できるため、「V* 犬の写真」などのハイブリッド キューが形成されます。このようにして、CustomNeRF は、画像やテキストなどの適応型データの一貫した効率的な編集を可能にします。
最終編集段階では、NeRF の暗黙的な表現により、SDS 損失を使用して 3D 領域全体を最適化すると、編集後に元のシーンとの一貫性を保つ必要がある背景領域に大きな変化が生じます。図 2(c) に示すように、この論文では、分離された SDS トレーニング用のローカル-グローバル反復編集 (LGIE) スキームを提案しており、レイアウト領域の編集中に背景コンテンツを保持できるようになります。
具体的には、この論文では NeRF の編集トレーニング プロセスをより細分化して説明します。 CustomNeRF は、前景を認識する NeRF を使用して、トレーニング中に NeRF のレンダリング プロセスを柔軟に制御できます。つまり、固定カメラの視点の下で、前景、背景、および前景と背景を含む通常の画像をレンダリングすることを選択できます。トレーニング中に、対応する前景または背景のキューと組み合わせて、前景と背景を繰り返しレンダリングすることで、SDS 損失を使用して、現在の NeRF シーンをさまざまなレベルで編集できます。その中で、ローカル フォアグラウンド トレーニングでは、編集プロセス中に編集が必要な領域のみに焦点を当てることができるため、複雑なシーンでの編集作業の困難さが簡素化されます。一方、グローバル トレーニングではシーン全体が考慮され、シーンの調整が維持されます。前景と背景。非編集領域をさらに変更しないようにするために、この論文では、編集トレーニング前の背景監視トレーニング プロセス中に新しくレンダリングされた背景も使用して、背景ピクセルの一貫性を維持します。
さらに、画像主導の 3D シーン編集では幾何学的不一致が悪化しています。参照画像を使用して微調整された拡散モデルは、推論プロセス中に参照画像と同様の遠近感を持つ画像を生成する傾向があり、編集された 3D シーンの複数の視点が正面図の幾何学的な問題となるためです。この目的を達成するために、この論文では、グローバル キューでは特別な記述子 V* を使用し、ローカル キューではクラス ワードのみを使用して、事前トレーニングされた拡散モデルに含まれるクラス事前分布を利用し、より多くの新しい概念を注入するクラスガイド付き正則化戦略を設計します。幾何学的に一貫した方法でシーンに取り込みます。
実験結果
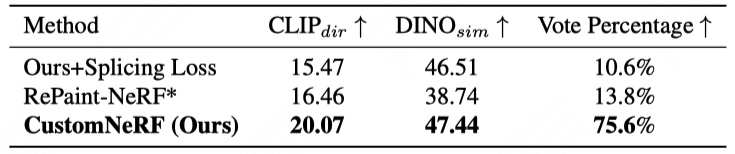
図 3 と図 4 は、参照画像とテキスト駆動の 3D シーンにおける CustomNeRF とベースライン手法の 3D シーン再構成結果の比較を示しています。編集タスクでは、CustomNeRF は良好な編集結果を達成し、編集プロンプトとの適切な調整を実現するだけでなく、背景領域と元のシーンの一貫性を維持します。さらに、表 1 と表 2 は、画像とテキストによって駆動された場合の CustomNeRF とベースライン手法の定量的な比較を示しています。その結果は、CustomNeRF がテキスト配置メトリクス、画像配置メトリクス、人間による評価においてベースライン手法を上回っていることを示しています。

# with Text-driven Editing# table 1画像ドライバー ## 2 2 Text Drive Edit ベースラインとの定量的比較 ##概要 この論文CustomNeRF モデルを革新的に提案し、テキスト説明または参照画像の編集プロンプトをサポートし、前景のみの正確な編集と、単一ビューの参照画像を使用する場合の複数のビューにわたる一貫性という 2 つの重要な課題を解決します。このスキームには、背景を変更せずに編集操作を前景に集中できるようにするローカル-グローバル反復編集 (LGIE) トレーニング スキームと、画像駆動型編集におけるビューの不一致を軽減するクラスガイド付き正則化が含まれており、検証されています。 CustomNeRF は、広範な実験を通じて、現実世界のさまざまなシナリオでテキストによる説明と参照画像に基づいて 3D シーンを正確に編集できるようにします。 
 ##の編集
##の編集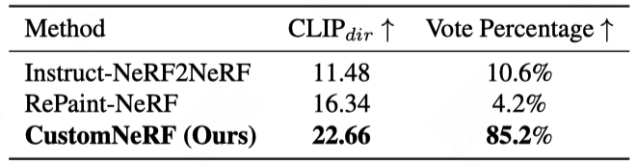
以上がCVPR 2024 | 新しいフレームワーク CustomNeRF は、テキストまたは画像のプロンプトのみで 3D シーンを正確に編集しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7470
7470
 15
1377
52
77
11
19
29
15
1377
52
77
11
19
29


 Giteeページ静的なWebサイトの展開に失敗しました:単一のファイル404エラーをトラブルシューティングと解決する方法
Apr 04, 2025 pm 11:54 PM
Giteeページ静的なWebサイトの展開に失敗しました:単一のファイル404エラーをトラブルシューティングと解決する方法
Apr 04, 2025 pm 11:54 PM
GiteEpages静的Webサイトの展開が失敗しました:404エラーのトラブルシューティングと解像度Giteeを使用する
 H5プロジェクトの実行方法
Apr 06, 2025 pm 12:21 PM
H5プロジェクトの実行方法
Apr 06, 2025 pm 12:21 PM
H5プロジェクトを実行するには、次の手順が必要です。Webサーバー、node.js、開発ツールなどの必要なツールのインストール。開発環境の構築、プロジェクトフォルダーの作成、プロジェクトの初期化、コードの書き込み。開発サーバーを起動し、コマンドラインを使用してコマンドを実行します。ブラウザでプロジェクトをプレビューし、開発サーバーURLを入力します。プロジェクトの公開、コードの最適化、プロジェクトの展開、Webサーバーの構成のセットアップ。
 GOのどのライブラリが大企業によって開発されていますか、それとも有名なオープンソースプロジェクトによって提供されていますか?
Apr 02, 2025 pm 04:12 PM
GOのどのライブラリが大企業によって開発されていますか、それとも有名なオープンソースプロジェクトによって提供されていますか?
Apr 02, 2025 pm 04:12 PM
大企業または有名なオープンソースプロジェクトによって開発されたGOのどのライブラリが開発されていますか? GOでプログラミングするとき、開発者はしばしばいくつかの一般的なニーズに遭遇します...
 Beego ormのモデルに関連付けられているデータベースを指定する方法は?
Apr 02, 2025 pm 03:54 PM
Beego ormのモデルに関連付けられているデータベースを指定する方法は?
Apr 02, 2025 pm 03:54 PM
Beegoormフレームワークでは、モデルに関連付けられているデータベースを指定する方法は?多くのBEEGOプロジェクトでは、複数のデータベースを同時に操作する必要があります。 Beegoを使用する場合...
 H5ページの生産には継続的なメンテナンスが必要ですか?
Apr 05, 2025 pm 11:27 PM
H5ページの生産には継続的なメンテナンスが必要ですか?
Apr 05, 2025 pm 11:27 PM
H5ページは、コードの脆弱性、ブラウザー互換性、パフォーマンスの最適化、セキュリティの更新、ユーザーエクスペリエンスの改善などの要因のため、継続的に維持する必要があります。効果的なメンテナンス方法には、完全なテストシステムの確立、バージョン制御ツールの使用、定期的にページのパフォーマンスの監視、ユーザーフィードバックの収集、メンテナンス計画の策定が含まれます。
 Redisストリームを使用してGO言語でメッセージキューを実装する場合、user_idタイプの変換の問題を解決する方法は?
Apr 02, 2025 pm 04:54 PM
Redisストリームを使用してGO言語でメッセージキューを実装する場合、user_idタイプの変換の問題を解決する方法は?
Apr 02, 2025 pm 04:54 PM
redisstreamを使用してGo言語でメッセージキューを実装する問題は、GO言語とRedisを使用することです...
 Python hourglassグラフ図面:可変未定義エラーを避ける方法は?
Apr 01, 2025 pm 06:27 PM
Python hourglassグラフ図面:可変未定義エラーを避ける方法は?
Apr 01, 2025 pm 06:27 PM
Python:Hourglassグラフィック図面と入力検証この記事では、Python NoviceがHourglass Graphic Drawingプログラムで遭遇する可変定義の問題を解決します。コード...
